
Data Warehouse, Data Lake, Lakehouse. Wenn Ihnen keines dieser Wörter auch nur ein bisschen bekannt vorkommt, dann hat Ihr Job eindeutig nichts mit Daten zu tun. 👨💻
Das wäre allerdings eine ziemlich unrealistische Annahme, denn heutzutage hat alles mit Daten zu tun, so scheint es. Oder wie die Unternehmensführer es gerne beschreiben:
- Datenzentriertes und datengesteuertes Geschäft.
- Daten überall, zu jeder Zeit, in jeder Form.
Das wichtigste Gut
Es scheint, dass Daten für immer mehr Unternehmen zum wertvollsten Kapital geworden sind. Ich erinnere mich noch daran, dass große Unternehmen immer eine große Menge an Daten erzeugten, man denke an Terabytes neuer Daten pro Monat. Das war noch vor 10-15 Jahren. Aber heute können Sie diese Datenmenge innerhalb weniger Tage erzeugen. Man könnte sich fragen, ob das wirklich notwendig ist, selbst wenn es sich um Inhalte handelt, die irgendjemand nutzen wird. Und ja, das ist es definitiv nicht 😃.
Nicht alle Inhalte werden von Nutzen sein, und einige Teile nicht einmal ein einziges Mal. Oft habe ich an vorderster Front miterlebt, wie Unternehmen eine enorme Menge an Daten generierten, die nach erfolgreichem Laden nur noch nutzlos waren.

Aber das ist nicht mehr relevant. Die Datenspeicherung – jetzt in der Cloud – ist billig, die Datenquellen wachsen exponentiell, und niemand kann heute vorhersagen, was er in einem Jahr brauchen wird, wenn neue Dienste in das System eingebunden werden. Zu diesem Zeitpunkt können sogar die alten Daten wertvoll werden.
Daher besteht die Strategie darin, so viele Daten wie möglich zu speichern. Aber auch in einer möglichst effektiven Form. Damit die Daten nicht nur effektiv gespeichert, sondern auch abgefragt, wiederverwendet oder umgewandelt und weiter verteilt werden können.
Lassen Sie uns einen Blick auf drei native Möglichkeiten werfen, wie Sie dies innerhalb von AWS erreichen können:
- Athena Database – eine preiswerte und effektive, wenn auch einfache Möglichkeit, einen Data Lake in der Cloud zu erstellen.
- Redshift Database – eine ernstzunehmende Cloud-Version eines Data Warehouse, die das Potenzial hat, die meisten der aktuellen On-Premise-Lösungen zu ersetzen, die mit dem exponentiellen Datenwachstum nicht mithalten können.
- Databricks – eine Kombination aus einem Data Lake und einem Data Warehouse in einer einzigen Lösung, mit einem gewissen Bonus obendrauf.
Data Lake von AWS Athena
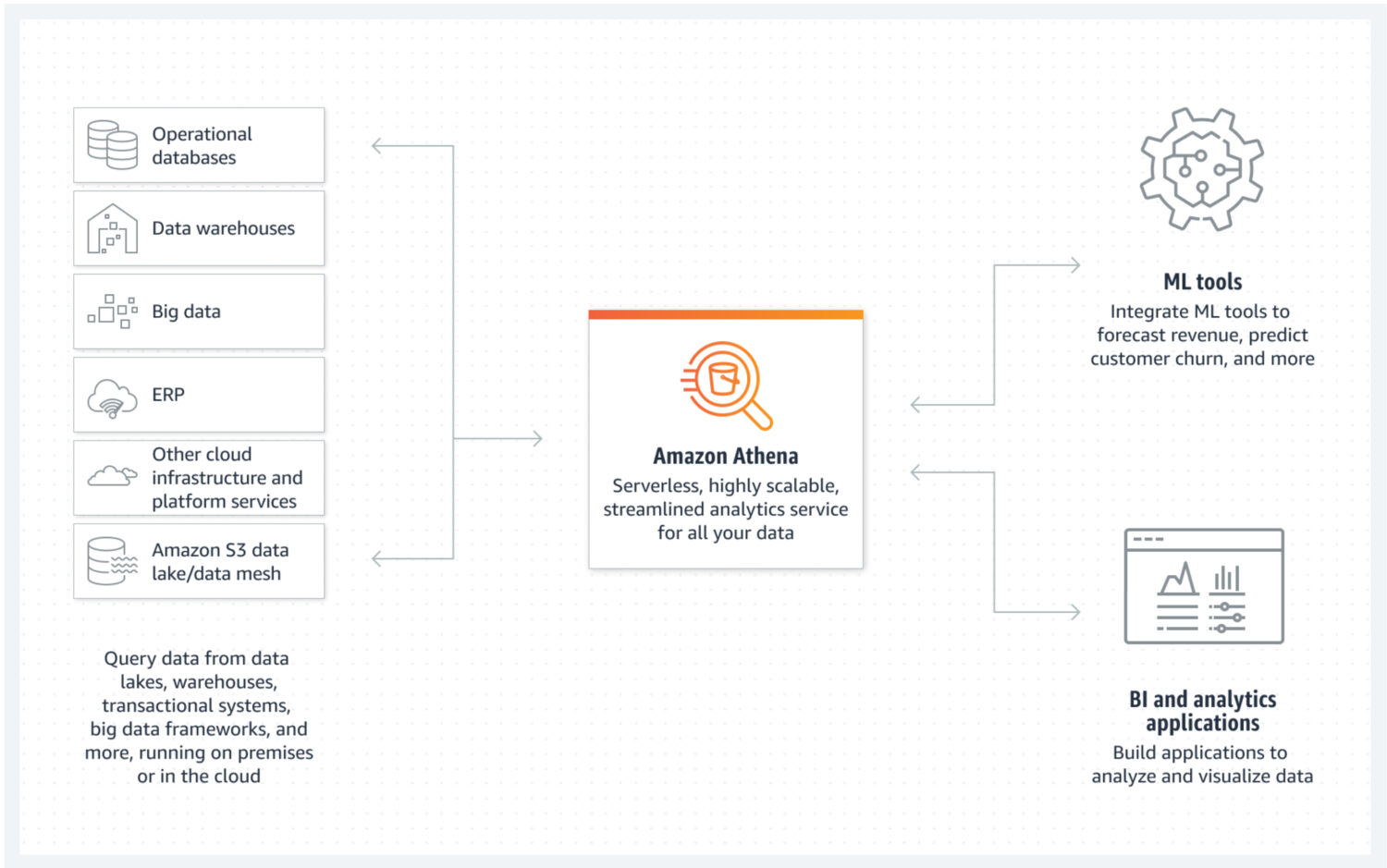
Der Data Lake ist ein Ort, an dem Sie eingehende Daten in unstrukturierter, halbstrukturierter oder strukturierter Form schnell speichern können. Gleichzeitig erwarten Sie nicht, dass diese Daten geändert werden, sobald sie gespeichert sind. Stattdessen möchten Sie, dass sie so atomar und unveränderlich wie möglich sind. Nur so ist das größte Potenzial für die Wiederverwendung in späteren Phasen gewährleistet. Wenn Sie diese atomare Eigenschaft der Daten gleich nach dem ersten Laden in einen Data Lake verlieren würden, gibt es keine Möglichkeit, diese verlorenen Informationen wieder zurückzubekommen.
AWS Athena ist eine Datenbank mit Speicherung direkt auf S3-Buckets und ohne im Hintergrund laufende Servercluster. Das bedeutet, dass es sich um einen wirklich günstigen Data Lake Service handelt. Strukturierte Dateiformate wie Parquet- oder Comma-Separated Value(CSV)-Dateien sorgen für die Datenorganisation. Der S3-Bucket enthält die Dateien, und Athena verweist auf sie, wenn Prozesse die Daten aus der Datenbank auswählen.
Athena unterstützt verschiedene Funktionen nicht, die sonst als Standard gelten, wie z.B. Aktualisierungsanweisungen. Deshalb müssen Sie Athena als eine sehr einfache Option betrachten. Andererseits hilft es Ihnen, Änderungen an Ihrem atomaren Datensee zu verhindern, einfach weil Sie es nicht können 😐.
Es unterstützt Indizierung und Partitionierung, was es für die effektive Ausführung von Select-Anweisungen und die Erstellung logisch getrennter Datenblöcke (z.B. nach Datum oder Schlüsselspalten getrennt) nutzbar macht. Sie kann auch sehr einfach horizontal skaliert werden, da dies so komplex ist wie das Hinzufügen neuer Buckets zur Infrastruktur.
Vor- und Nachteile
Die zu berücksichtigenden Vorteile:
- Die Tatsache, dass Athena billig ist (es besteht nur aus S3-Buckets und Kosten für die SQL-Nutzung pro Nutzung), ist der wichtigste Vorteil. Wenn Sie einen erschwinglichen Data Lake in AWS aufbauen möchten, ist dies die richtige Lösung.
- Als nativer Service lässt sich Athena problemlos mit anderen nützlichen AWS-Services wie Amazon QuickSight für die Datenvisualisierung oder AWS Glue Data Catalog zur Erstellung persistenter strukturierter Metadaten integrieren.
- Am besten geeignet, um Ad-hoc-Abfragen über eine große Menge strukturierter oder unstrukturierter Daten durchzuführen, ohne eine ganze Infrastruktur dafür zu unterhalten.
Die Nachteile, die Sie beachten sollten:
- Athena ist nicht besonders effektiv, wenn es darum geht, komplexe Select-Abfragen schnell zurückzugeben, insbesondere wenn die Abfragen nicht den Annahmen des Datenmodells folgen, wie Sie die Daten aus dem Data Lake abfragen wollen.
- Dies macht es auch weniger flexibel im Hinblick auf mögliche zukünftige Änderungen des Datenmodells.
- Athena unterstützt von Haus aus keine zusätzlichen erweiterten Funktionen. Wenn Sie etwas Bestimmtes als Teil des Dienstes wünschen, müssen Sie es zusätzlich implementieren.
- Wenn Sie erwarten, dass die Data Lake-Daten in einer fortgeschrittenen Präsentationsschicht verwendet werden, bleibt Ihnen oft nur die Möglichkeit, den Service mit einem anderen Datenbankservice zu kombinieren, der für diesen Zweck besser geeignet ist, wie AWS Aurora oder AWS Dynamo DB.
Zweck und Anwendungsfall in der realen Welt
Wählen Sie Athena, wenn das Ziel die Erstellung eines einfachen Data Lake ohne fortgeschrittene Data Warehouse-ähnliche Funktionalitäten ist. Zum Beispiel, wenn Sie keine ernsthaften, hochleistungsfähigen Analyseabfragen erwarten, die regelmäßig über den Data Lake laufen. Stattdessen steht ein Pool unveränderlicher Daten mit einfacher Datenspeichererweiterung im Vordergrund.
Sie müssen sich nicht mehr allzu viele Gedanken über mangelnden Speicherplatz machen. Sogar die Kosten für die Speicherung in S3-Buckets lassen sich weiter senken, wenn Sie eine Richtlinie für den Lebenszyklus der Daten einführen. Das bedeutet im Grunde, dass die Daten auf verschiedene Arten von S3-Buckets verteilt werden, die eher für Archivierungszwecke gedacht sind und langsamere Ingestion-Rückkehrzeiten, aber geringere Kosten aufweisen.
Eine großartige Funktion von Athena ist, dass es automatisch eine Datei mit Daten erstellt, die Teil eines Ergebnisses Ihrer SQL-Abfrage sind. Sie können diese Datei dann für jeden beliebigen Zweck verwenden. Es ist also eine gute Option, wenn Sie viele Lambda-Dienste haben, die die Daten in mehreren Schritten weiterverarbeiten. Jedes Lambda-Ergebnis wird automatisch in einem strukturierten Dateiformat als Eingabe für die nachfolgende Verarbeitung zur Verfügung gestellt.
Athena ist eine gute Option in Situationen, in denen eine große Menge an Rohdaten in Ihrer Cloud-Infrastruktur ankommt und Sie diese nicht zum Zeitpunkt des Ladens verarbeiten müssen. Das bedeutet, dass Sie nur eine schnelle Speicherung in der Cloud in einer leicht verständlichen Struktur benötigen.
Ein weiterer Anwendungsfall wäre die Schaffung eines dedizierten Speicherplatzes für die Datenarchivierung für einen anderen Dienst. In einem solchen Fall würde Athena DB zu einem billigen Speicherplatz für all die Daten werden, die Sie im Moment nicht benötigen, aber das könnte sich in Zukunft ändern. Zu diesem Zeitpunkt nehmen Sie die Daten einfach auf und senden sie weiter.
Data Warehouse von AWS Redshift
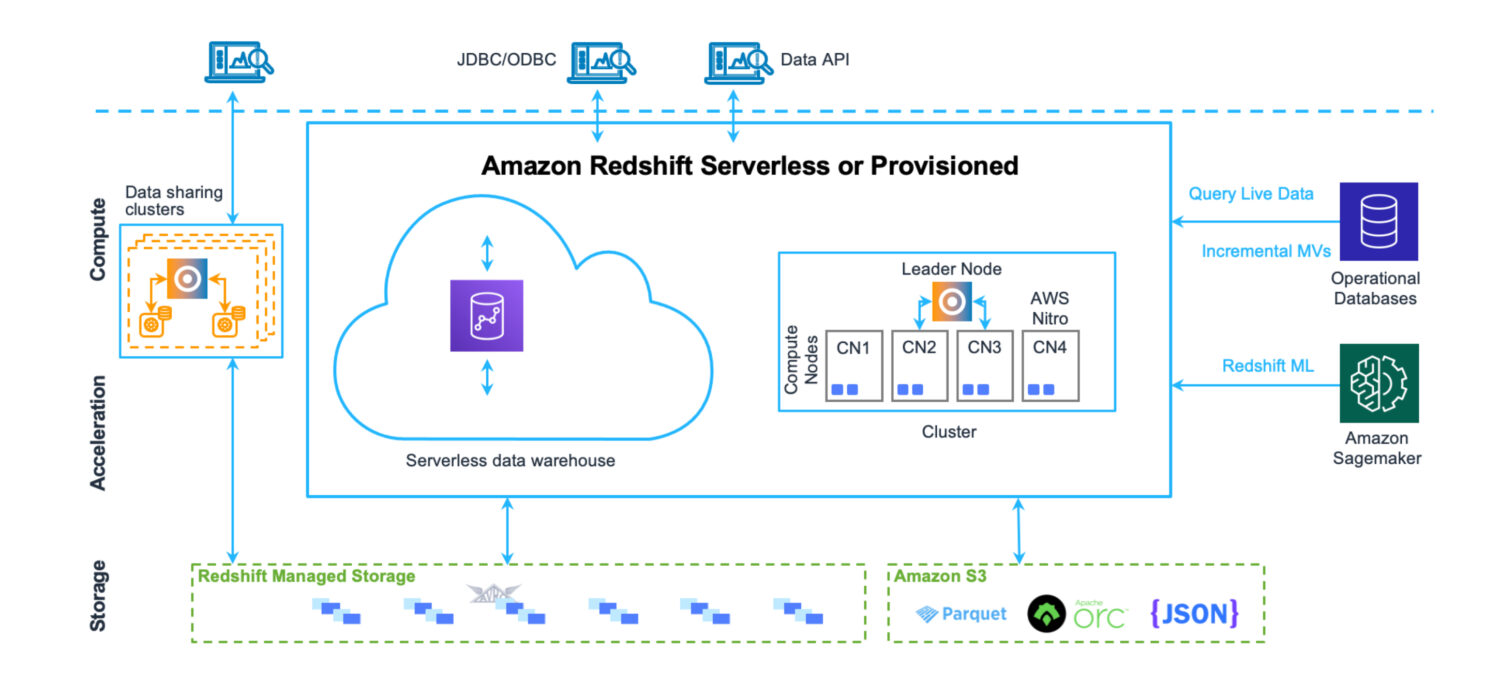
Ein Data Warehouse ist ein Ort, an dem Daten in einer sehr strukturierten Weise gespeichert werden. Einfach zu laden und zu extrahieren. Die Absicht ist, eine große Anzahl sehr komplexer Abfragen auszuführen und viele Tabellen über komplexe Joins zu verbinden. Es gibt verschiedene analytische Funktionen, die verschiedene Statistiken über die vorhandenen Daten berechnen. Das ultimative Ziel ist es, aus den vorhandenen Daten Zukunftsprognosen und Fakten zu extrahieren, die in Zukunft für das Unternehmen genutzt werden können.
Redshift ist ein vollwertiges Data Warehouse-System. Mit Cluster-Servern zum Abstimmen und Skalieren – horizontal und vertikal – und einem Datenbankspeichersystem, das für schnelle, komplexe Abfragen optimiert ist. Allerdings können Sie Redshift heute auch im serverlosen Modus betreiben. Es gibt keine Dateien auf S3 oder etwas Ähnlichem. Es handelt sich um einen Standard-Datenbank-Cluster-Server mit einem eigenen Speicherformat.
Er verfügt über Tools zur Leistungsüberwachung sowie über anpassbare Dashboard-Metriken, die Sie zur Feinabstimmung der Leistung für Ihren Anwendungsfall verwenden und beobachten können. Die Verwaltung ist auch über separate Dashboards zugänglich. Es ist etwas mühsam, alle möglichen Funktionen und Einstellungen zu verstehen und wie sie sich auf den Cluster auswirken. Dennoch ist es bei weitem nicht so komplex wie die Verwaltung von Oracle-Servern im Falle der On-Premise-Lösungen.
Auch wenn es verschiedene AWS-Limits in Redshift gibt, die der täglichen Nutzung Grenzen setzen (z.B. harte Limits für die Anzahl der gleichzeitig aktiven Benutzer oder Sitzungen in einem Datenbank-Cluster), hilft die Tatsache, dass die Operationen wirklich schnell ausgeführt werden, diese Limits bis zu einem gewissen Grad zu umgehen.
Vor- und Nachteile
Die zu berücksichtigenden Vorteile:
- Nativer AWS-Cloud-Data-Warehouse-Service, der sich leicht mit anderen Services integrieren lässt.
- Ein zentraler Ort zum Speichern, Überwachen und Einlesen verschiedener Arten von Datenquellen aus sehr unterschiedlichen Quellsystemen.
- Wenn Sie schon immer ein serverloses Data Warehouse haben wollten, ohne die Infrastruktur zu pflegen, können Sie das jetzt.
- Optimiert für Hochleistungsanalysen und -berichte. Im Gegensatz zu einer Data Lake-Lösung gibt es ein starkes relationales Datenmodell für die Speicherung aller eingehenden Daten.
- Die Redshift-Datenbank-Engine hat ihren Ursprung in PostgreSQL, was eine hohe Kompatibilität mit anderen Datenbanksystemen gewährleistet.
- Sehr nützliche COPY- und UNLOAD-Anweisungen zum Laden und Entladen der Daten aus und in S3-Buckets.
Die zu berücksichtigenden Nachteile:
- Redshift unterstützt keine große Anzahl von gleichzeitig aktiven Sitzungen. Die Sitzungen werden in der Warteschleife gehalten und sequentiell verarbeitet. Während dies in den meisten Fällen kein Problem darstellt, da die Vorgänge sehr schnell sind, ist dies ein einschränkender Faktor in Systemen mit vielen aktiven Benutzern.
- Auch wenn Redshift viele Funktionen unterstützt, die man von ausgereiften Oracle-Systemen kennt, ist es noch nicht auf dem gleichen Stand. Einige der erwarteten Funktionen sind einfach nicht vorhanden (wie DB-Trigger). Oder Redshift unterstützt sie in recht eingeschränkter Form (wie materialisierte Ansichten).
- Wenn Sie einen fortgeschrittenen benutzerdefinierten Datenverarbeitungsauftrag benötigen, müssen Sie ihn von Grund auf neu erstellen. Meistens verwenden Sie Python oder Javascript als Programmiersprache. Sie ist nicht so natürlich wie PL/SQL im Falle des Oracle-Systems, wo sogar die Funktionen und Prozeduren eine Sprache verwenden, die den SQL-Abfragen sehr ähnlich ist.
Zweck und Anwendungsfall in der realen Welt
Redshift kann Ihr zentraler Speicher für all die verschiedenen Datenquellen sein, die bisher außerhalb der Cloud lagen. Es ist ein vollwertiger Ersatz für frühere Oracle Data Warehouse-Lösungen. Da es sich auch um eine relationale Datenbank handelt, ist die Migration von Oracle sogar recht einfach.
Wenn Sie an vielen Stellen bestehende Data Warehouse-Lösungen haben, die in Bezug auf Ansatz, Struktur oder eine vordefinierte Reihe gemeinsamer Prozesse, die über die Daten laufen sollen, nicht wirklich einheitlich sind, ist Redshift eine gute Wahl.
Es bietet Ihnen die Möglichkeit, die verschiedenen Data Warehouse-Systeme aus verschiedenen Orten und Ländern unter einem Dach zu vereinen. Sie können sie immer noch nach Ländern trennen, damit die Daten sicher und nur für diejenigen zugänglich bleiben, die sie benötigen. Aber gleichzeitig können Sie so eine einheitliche Data Warehouse-Lösung aufbauen, die alle Unternehmensdaten abdeckt.
Ein anderer Fall wäre, wenn das Ziel darin besteht, eine Data Warehouse-Plattform mit umfassender Unterstützung von Self-Services aufzubauen. Sie können dies als eine Reihe von Verarbeitungen verstehen, die einzelne Systembenutzer erstellen können. Gleichzeitig sind sie aber nie Teil der gemeinsamen Plattformlösung. Das bedeutet, dass solche Dienste nur für den Ersteller oder die vom Ersteller definierte Gruppe von Personen zugänglich sind. Sie wirken sich in keiner Weise auf die übrigen Benutzer aus.
Sehen Sie sich unseren Vergleich zwischen Datalake und Datawarehouse an.
Lakehouse von Databricks auf AWS
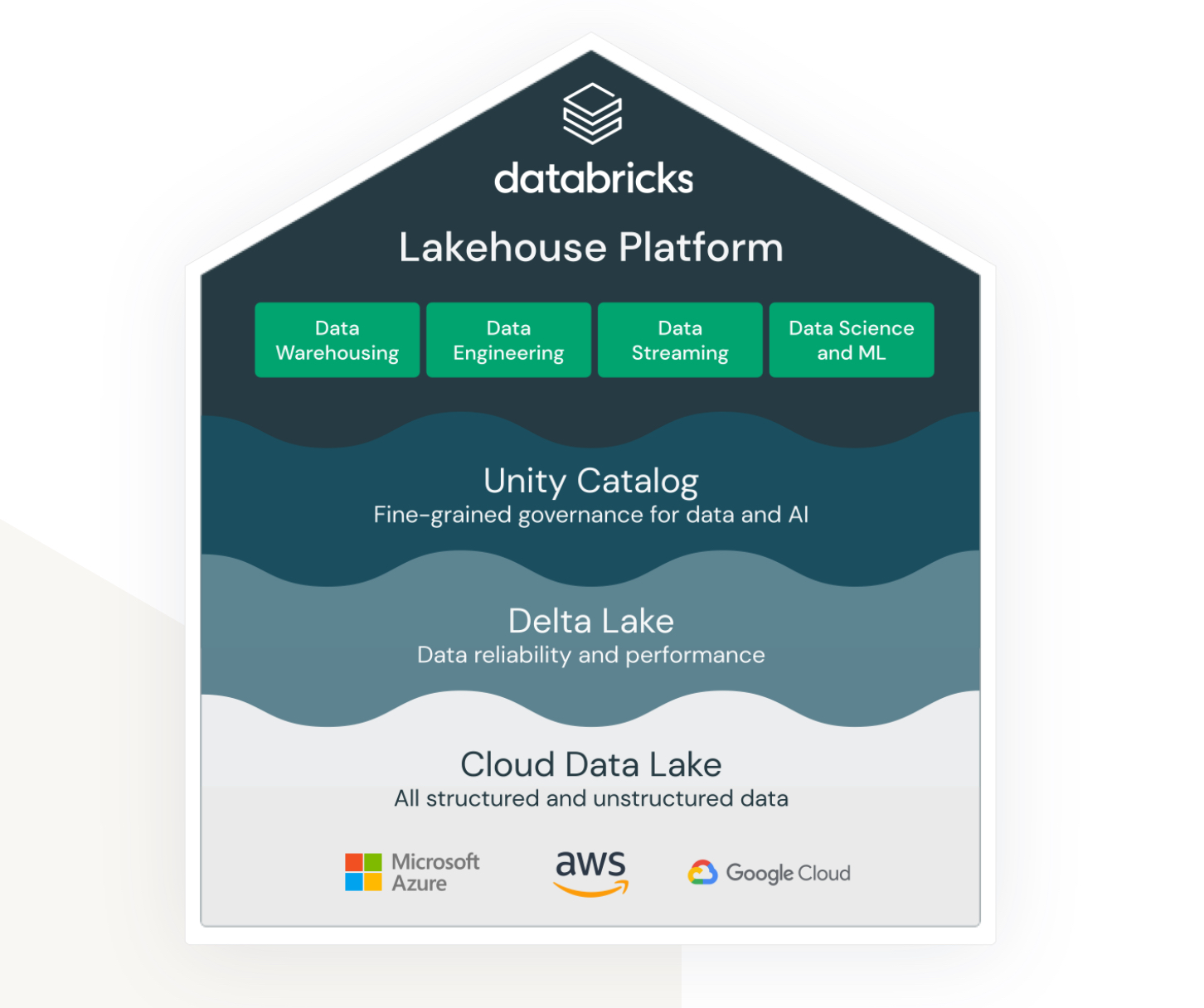
Lakehouse ist ein Begriff, der wirklich an den Databricks-Service gebunden ist. Auch wenn es sich nicht um einen nativen AWS-Service handelt, lebt und funktioniert er sehr gut innerhalb des AWS-Ökosystems und bietet verschiedene Optionen für die Verbindung und Integration mit anderen AWS-Services.
Databricks zielt darauf ab, (bisher) sehr unterschiedliche Bereiche miteinander zu verbinden:
- Eine Lösung für die Speicherung von unstrukturierten, halbstrukturierten und strukturierten Daten im Data Lake.
- Eine Lösung für Data Warehouse strukturierte und schnell zugängliche Abfragedaten (auch Delta Lake genannt).
- Eine Lösung zur Unterstützung von Analysen und maschinellen Lernverfahren über den Data Lake.
- Data Governance für alle oben genannten Bereiche mit zentraler Verwaltung und sofort einsatzbereiten Tools zur Unterstützung der Produktivität verschiedener Arten von Entwicklern und Benutzern.
Es handelt sich um eine gemeinsame Plattform, die Dateningenieure, SQL-Entwickler und Data Scientists für maschinelles Lernen gleichzeitig nutzen können. Jede dieser Gruppen verfügt außerdem über eine Reihe von Tools, die sie zur Erfüllung ihrer Aufgaben verwenden können.
Databricks zielt also auf eine Tausendsassa-Lösung ab und versucht, die Vorteile von Data Lake und Data Warehouse in einer einzigen Lösung zu vereinen. Darüber hinaus bietet es die Tools zum Testen und Ausführen von Modellen für maschinelles Lernen direkt über bereits erstellte Datenspeicher.
Vor- und Nachteile
Die Vorteile, die Sie berücksichtigen sollten:
- Databricks ist eine hoch skalierbare Datenplattform. Sie skaliert je nach Größe der Arbeitslast, und zwar sogar automatisch.
- Es ist eine kollaborative Umgebung für Datenwissenschaftler, Dateningenieure und Business-Analysten. Die Möglichkeit, all dies im selben Raum und gemeinsam zu tun, ist ein großer Vorteil. Nicht nur aus organisatorischer Sicht, sondern es hilft auch, weitere Kosten zu sparen, die sonst für separate Umgebungen anfallen würden.
- AWS Databricks lässt sich nahtlos in andere AWS-Services wie Amazon S3, Amazon Redshift und Amazon EMR integrieren. So können Benutzer problemlos Daten zwischen den Diensten übertragen und die gesamte Palette der AWS-Cloud-Services nutzen.
Die zu berücksichtigenden Nachteile:
- Die Einrichtung und Verwaltung von Databricks kann komplex sein, insbesondere für Benutzer, die neu in der Big Data-Verarbeitung sind. Es erfordert ein hohes Maß an technischem Know-how, um die Plattform optimal zu nutzen.
- Databricks ist zwar durch sein Pay-as-you-go-Preismodell kosteneffizient, kann aber für große Datenverarbeitungsprojekte dennoch teuer sein. Die Kosten für die Nutzung der Plattform können sich schnell summieren, insbesondere wenn die Benutzer ihre Ressourcen aufstocken müssen.
- Databricks bietet eine Reihe von vorgefertigten Tools und Vorlagen, aber das kann auch eine Einschränkung für Benutzer sein, die mehr Anpassungsmöglichkeiten benötigen. Die Plattform ist möglicherweise nicht für Benutzer geeignet, die mehr Flexibilität und Kontrolle über ihre Big Data-Verarbeitungsabläufe benötigen.
Zweck und Anwendungsfall in der Praxis
AWS Databricks eignet sich am besten für große Unternehmen mit einer sehr großen Datenmenge. Hier kann es die Anforderung abdecken, verschiedene Datenquellen aus unterschiedlichen externen Systemen zu laden und zu kontextualisieren.
Oft besteht die Anforderung, Daten in Echtzeit bereitzustellen. Das bedeutet, dass die Prozesse ab dem Zeitpunkt, zu dem die Daten im Quellsystem erscheinen, sofort anspringen und die Daten sofort oder mit nur minimaler Verzögerung verarbeiten und in Databricks speichern sollen. Wenn die Verzögerung mehr als eine Minute beträgt, spricht man von einer Fast-Echtzeit-Verarbeitung. In jedem Fall sind beide Szenarien mit der Databricks-Plattform oft realisierbar. Das liegt vor allem an den zahlreichen Adaptern und Echtzeit-Schnittstellen, die eine Verbindung zu verschiedenen anderen nativen AWS-Services herstellen.
Databricks lässt sich auch problemlos mit Informatica ETL-Systemen integrieren. Wenn das Unternehmenssystem das Informatica-Ökosystem bereits ausgiebig nutzt, scheint Databricks eine gute kompatible Ergänzung der Plattform zu sein.
Abschließende Worte
Da das Datenvolumen weiterhin exponentiell wächst, ist es gut zu wissen, dass es Lösungen gibt, die dies effektiv bewältigen können. Was früher ein Alptraum für die Verwaltung und Pflege war, erfordert jetzt nur noch sehr wenig Verwaltungsaufwand. Das Team kann sich auf die Wertschöpfung aus den Daten konzentrieren.
Wählen Sie je nach Ihren Bedürfnissen einfach den Service, der damit umgehen kann. Während AWS Databricks etwas ist, an das Sie sich nach der Entscheidung wahrscheinlich halten müssen, sind die anderen Alternativen deutlich flexibler, wenn auch weniger leistungsfähig, insbesondere ihre serverlosen Modi. Es ist ganz einfach, später zu einer anderen Lösung zu migrieren.