Graphdatenbanken speichern hoch vernetzte, dichte Daten und verarbeiten Abfragen effizient. Aber wissen Sie auch, wann Sie welche Graphdatenbank verwenden sollten? Lesen Sie, um mehr zu erfahren.
“Daten sind das neue Öl.” Das Wachstum eines jeden Unternehmens hängt davon ab, wie effektiv es Daten speichert und nutzt. 2.jeden Tag werden 5 Quintillionen Bytes an Daten erzeugt. Wir brauchen also fehlertolerante Systeme und Lager, in denen Daten effektiv gespeichert und verwaltet werden können. Ursprünglich wurden relationale Datenbanken verwendet.
Doch im Laufe der Zeit änderten sich Menge und Art der Daten rapide. So entstand der Bedarf, Video, Audio, Bilder usw. zu speichern. Dies war der Auslöser für die Entwicklung von SQL, NoSQL-Datenbanken, Hadoop, Graphdatenbanken usw. Jede hat ihre eigenen Anwendungsfälle und arbeitet mit unterschiedlichen Datenformaten. Graphdatenbanken wurden entwickelt, um die Bearbeitung von Daten zu vereinfachen und um sie effektiv zu speichern.
Graph-Datenbanken
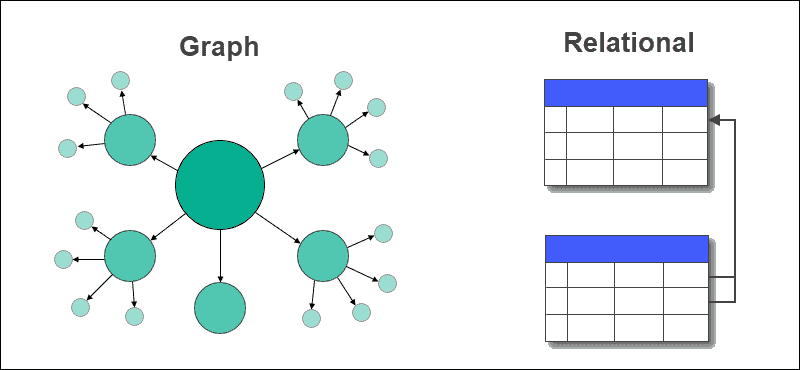
Ein Graph ist eine Datenstruktur, die in Form von Knoten und Kanten dargestellt wird. Eine Datenbank ist eine Sammlung von Tabellen, in denen Daten und die Beziehungen zwischen den Daten gespeichert werden. Eine Graphdatenbank ist eine Datenbank, die Daten in Knoten und die Beziehungen, die zwischen den Daten bestehen, in Form von Kanten speichert. Graphdatenbanken helfen bei der Bearbeitung von Echtzeitabfragen und bei der effektiven Verwaltung von Many-to-Many-Beziehungen zwischen Entitäten.
Beliebte Graphdatenmodelle sind Eigenschaftsgraphen und RDF-Graphen. Analysen und Abfragen werden meist mit Eigenschaftsdiagrammen durchgeführt. Die Datenintegration erfolgt über RDF-Graphen. Der Unterschied zwischen Eigenschafts- und RDF-Graphen besteht darin, dass RDF-Graphen in Form von Tripeln dargestellt werden, d.h. Subjekt, Prädikat und Objekt.
Graphdatenbanken speichern Daten in Knoten und die Beziehung zwischen den Daten in Form von Kanten zwischen den Knoten. Die Kanten im Graphen können gerichtet (uni-direktional) oder ungerichtet (bi-direktional) sein.
Die Abfrageverarbeitung erfolgt durch Traversierung des Graphen. Zur effektiven Beantwortung von Abfragen werden Algorithmen zur Durchquerung des Graphen verwendet, die den Pfad von einem Knoten zum anderen, den Abstand zwischen den Knoten, Muster, Schleifen innerhalb des Graphen und die Möglichkeit zur Bildung von Clustern usw. ermitteln.

Anwendungen von Graphdatenbanken
Graphdatenbanken werden bei der Aufdeckung von Betrug eingesetzt. Bei den Knoten/Entitäten könnte es sich um Namen, Adressen, Geburtsdaten usw. von Personen und um einige betrügerische IP-Adressen, Gerätenummern usw. handeln. Wenn ein betrügerischer Knoten mit einem nicht-betrügerischen Knoten interagiert, werden Verbindungen zwischen ihnen hergestellt und als verdächtig markiert.
Social Media-Websites verwenden Graphdatenbanken, um Empfehlungen für Personen, mit denen wir in Kontakt treten möchten, und für Inhalte, die wir uns ansehen möchten, anzuzeigen. Dies geschieht mit Hilfe von Graph-Traversalen in der Datenbank.
Auch Netzwerkzuordnung und Infrastrukturmanagement, Konfigurationselemente usw. werden mit Graphdatenbanken effektiv gespeichert und verwaltet.
Graphdatenbank vs. Relationale Datenbank
In einer Graphdatenbank werden Tabellen mit Zeilen und Spalten durch Knoten und Kanten ersetzt. Die Beziehungen zwischen den Daten werden in einer Graphdatenbank an den Kanten gespeichert.
Eine relationale Datenbank speichert Beziehungen zwischen Tabellen unter Verwendung von Fremdschlüsseln und anderen Tabellen. Das Extrahieren von Daten oder die Abfrage von Daten ist in einer Graphdatenbank einfach und erfordert keine komplexen Verknüpfungen, was bei relationalen Datenbanken nicht der Fall ist.
Relationale Datenbanken eignen sich am besten für Anwendungsfälle, die Transaktionen beinhalten, während Graphdatenbanken für beziehungslastige und datenintensive Anwendungen geeignet sind.
Graphdatenbanken unterstützen strukturierte, halbstrukturierte und unstrukturierte Daten, während relationale Datenbanken ein festes Schema haben müssen.
Graphdatenbanken erfüllen dynamische Anforderungen, während relationale Datenbanken im Allgemeinen für bekannte und statische Probleme verwendet werden.
Werfen wir nun einen Blick auf die besten Graphdatenbanklösungen.
Cayley
Cayley ist eine Open-Source-Graphdatenbank, die von Apache 2.0 entwickelt wurde. Sie wurde mit Go entwickelt und arbeitet mit verknüpften Daten. Cayley ist die Datenbank, die beim Aufbau von Googles Freebase und Knowledge Graph verwendet wurde. Sie unterstützt mehrere Abfragesprachen wie MQL und Javascript mit einem Gremlin-basierten Graph-Objekt.

Sie ist einfach zu bedienen, schnell und hat einen modularen Aufbau. Es kann verschiedene Backend-Speicher wie LevelDB, MongoDB und Bolt integrieren und mit ihnen interagieren. Es unterstützt verschiedene APIs von Drittanbietern, die in mehreren Sprachen wie Java, .NET, Rust, Haskell, Ruby, PHP, Javascript und Clojure geschrieben wurden. Es kann in Docker und Kubernetes implementiert werden. Die wichtigsten Bereiche, in denen Cayley eingesetzt wird, sind Informationstechnologie, Computersoftware und Finanzdienstleistungen.
Amazon Neptun
Amazon Neptune ist dafür bekannt, dass es bei stark vernetzten Datensätzen außergewöhnlich gut funktioniert. Es ist zuverlässig, sicher, vollständig verwaltet und unterstützt offene Graph-APIs. Es kann Milliarden von Beziehungen speichern und Daten mit einer extrem niedrigen Latenzzeit von einigen Millisekunden abfragen.
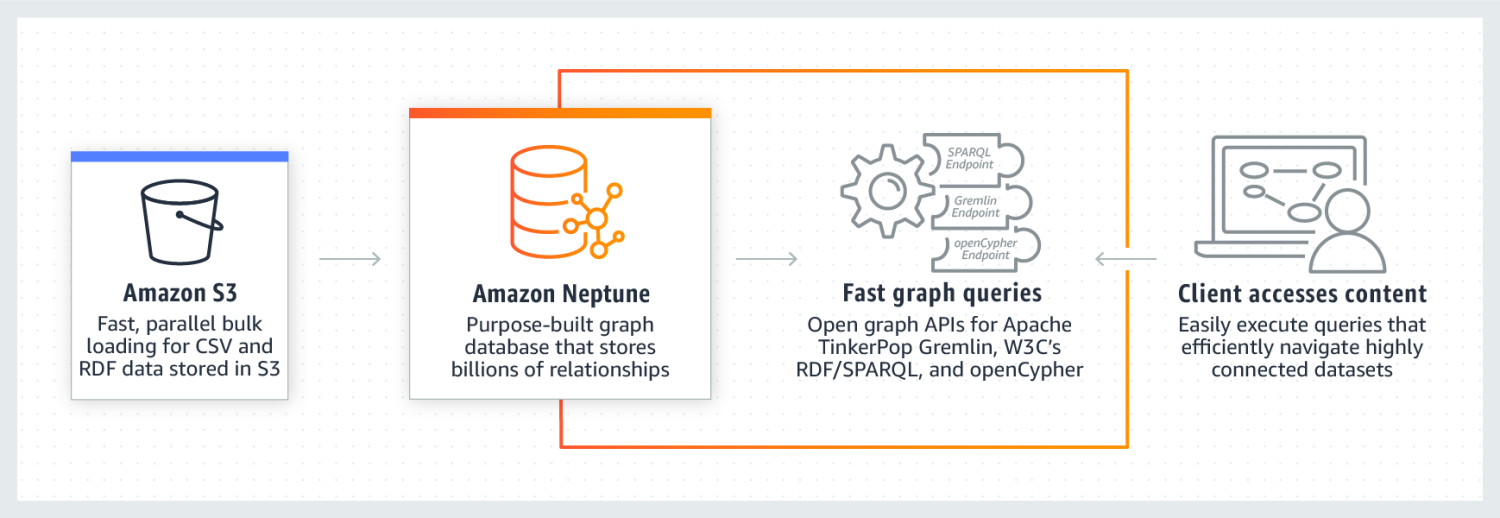
Das Neptune Graph-Datenmodell besteht aus 4 Positionen, nämlich Subjekt (S), Prädikat (P), Objekt (O) und Graph (G). Jede dieser Positionen wird verwendet, um die Position des Quellknotens, des Zielknotens, die Beziehung zwischen ihnen und ihre Eigenschaften zu speichern.
Es verwendet auch einen Cache, der die Ausführung von Leseabfragen beschleunigt. Die Daten werden in Form von DB-Clustern gespeichert. Jeder Cluster umfasst eine primäre DB-Instanz und Lese-Replikate von DB-Instanzen. Neptune ist äußerst sicher, da es IAM-Authentifizierung, SSL-Zertifizierung und Protokollüberwachung verwendet. Es ist auch einfach, Daten aus anderen Quellen in Amazon Neptune zu migrieren. Außerdem wird die Ausfallsicherheit durch die Erstellung von Replikaten und regelmäßigen Backups gewährleistet. Zu den Unternehmen, die Neptune verwenden, gehören Herren, Onedot, Juncture und Hi Platform.
Neo4j
Neo4j ist eine skalierbare, sichere, bedarfsgesteuerte und zuverlässige Graphdatenbank. Neo4j wurde in Java entwickelt und verwendet Cypher als Abfragesprache. Es verwendet das Bolt-Protokoll, und alle Transaktionen erfolgen über einen HTTP-Endpunkt. Im Vergleich zu anderen relationalen Datenbanken beantwortet sie Abfragen viel schneller. Sie hat keinen Overhead durch komplexe Joins und ihre Optimierungen funktionieren gut, wenn der Datensatz groß und stark verknüpft ist. Sie bietet den Vorteil der Graphenspeicherung zusammen mit den ACID-Eigenschaften einer relationalen Datenbank.

Neo4j unterstützt verschiedene Sprachen wie Java, .NET, Node.js, Ruby, Python usw. mit Hilfe von Treibern. Es wird auch in Graph Data Science, Analytik und maschinellen Lernprozessen eingesetzt. Neo4j Aura DB ist eine fehlertolerante und vollständig verwaltete Cloud-Graph-Datenbank. Unternehmen wie Microsoft, Cisco, Adobe, eBay, IBM, Samsung, usw. verwenden Neo4j.
ArangoDB
ArangoDB ist eine Open-Source-Multimodell-Datenbank. Der Multi-Modell-Ansatz ermöglicht es Benutzern, die Daten in einer beliebigen Abfragesprache ihrer Wahl abzufragen. Die Knoten und Kanten von ArangoDB sind JSON-Dokumente. Jedes Dokument hat eine eindeutige ID. Beziehungen zwischen zwei Knoten werden in Form von Kanten angezeigt, und ihre eindeutigen IDs werden gespeichert. Die gute Leistung ist auf das Vorhandensein eines Hash-Index zurückzuführen.

Traversals, Joins und Suchen in den Datenbanken werden verbessert. Es hilft bei der Entwicklung, Skalierung und Anpassung an verschiedene Architekturen. Sie spielt eine wichtige Rolle bei komplexen Data Science-Aufgaben wie der Merkmalsextraktion und der erweiterten Suche.
ArrangoDB kann in einer Cloud-basierten Umgebung ausgeführt werden und ist mit Mac OS, Linux und Windows kompatibel. LDAP-Authentifizierung, Datenmaskierung und Verschlüsselungsalgorithmen gewährleisten die Sicherheit der Datenbank. Sie wird in den Bereichen Risikomanagement, IAM, Betrugserkennung, Netzwerkinfrastruktur, Recommendation Engines usw. eingesetzt. Accenture, Cisco, Dish und VMware sind einige Unternehmen, die ArangoDB verwenden.
DataStax
DataStax ist eine NoSQL-Cloud-Datenbank-as-a-Service, die auf Apache Cassandra basiert. Sie ist hoch skalierbar und verwendet eine Cloud-native Architektur. Sie ist zuverlässig und sicher. Jedes in DataStax gespeicherte Dokument verfügt über einen Index, der eine einfache Suche und ein schnelles Abrufen von Daten ermöglicht. Shards werden über den indizierten Daten erstellt. Mit Datastax Enterprise-Tools, Kafka und Docker können verschiedene Datenquellen zur Erstellung von Anwendungen verwendet werden.
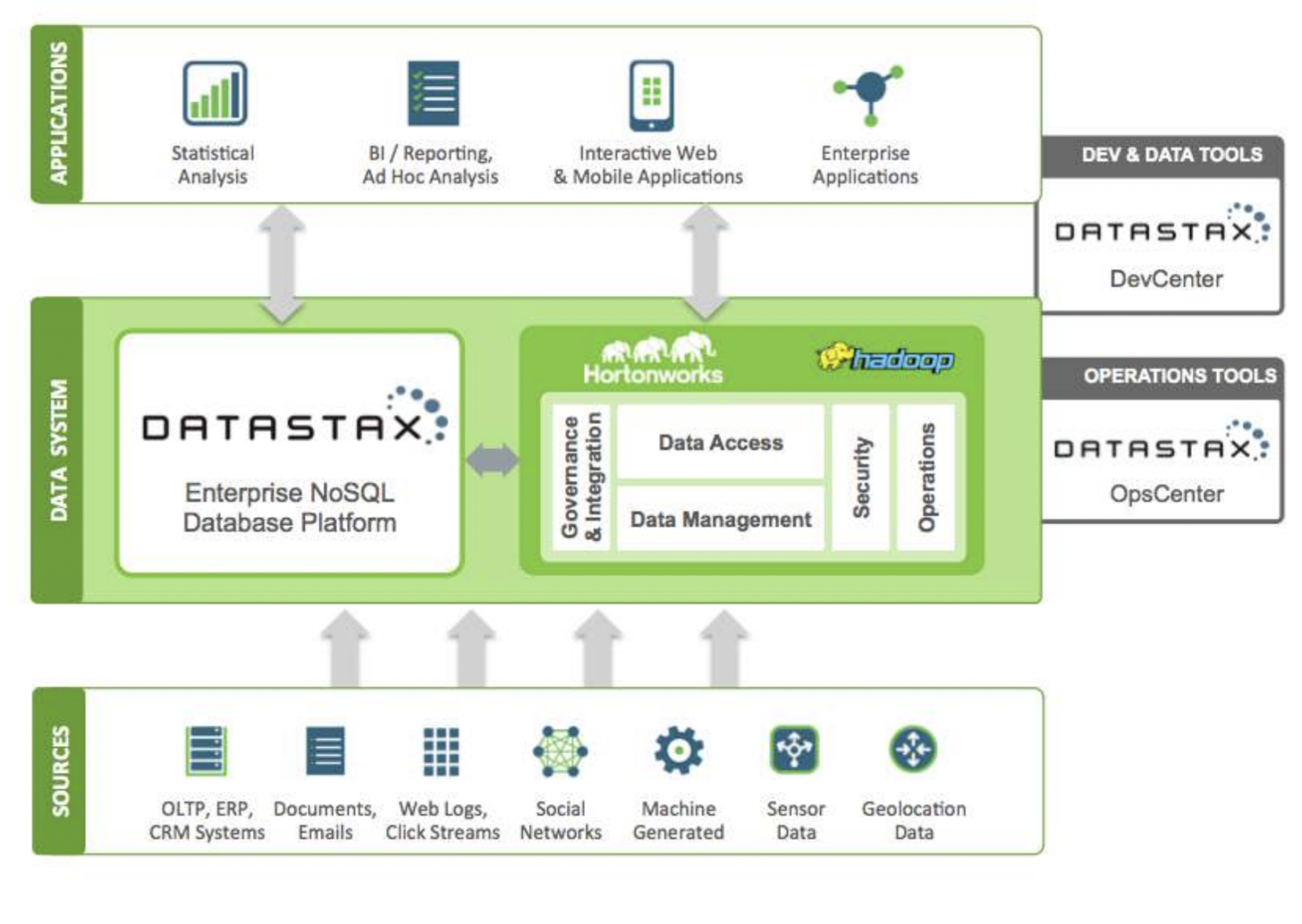
Die von den Quellen gesammelten Daten werden an ein Hadoop-Ökosystem und DataStax gesendet. Hadoop verwaltet die Sicherheit, den Betrieb, den Datenzugriff und die Verwaltung durch Interaktion mit DataStax. Die Daten werden mit den Entwicklungs- und Betriebstools von DataStax verfeinert.
Die analysierten Informationen werden dann für statistische Analysen, Unternehmensanwendungen, Reporting usw. verwendet. Da es sich um eine Cloud-basierte Lösung handelt, zahlen die Kunden für das, was sie nutzen, und die Preise sind angemessen. Verizon, CapitalOne, TMobile und Overstock sind einige Unternehmen, die DataStax nutzen.
Orient DB
OrientDB ist eine Graphdatenbank, die Daten effektiv verwaltet und bei der Erstellung visueller Darstellungen zur Präsentation von Daten hilft. Es handelt sich um eine Multi-Modell-Graph-Datenbank, die mit Java entwickelt wurde. Sie speichert Daten in Form von Schlüssel-Werte-Paaren, Dokumenten, Objektmodellen usw. Sie besteht aus 3 wichtigen Komponenten: Graph Editor, Studio Query und Kommandozeilenkonsole.
Ein Graph-Editor dient zur Visualisierung und Interaktion mit Daten. Die Studio-Abfrageoberfläche dient zum Ausführen von Abfragen und zur sofortigen Ausgabe in einem bildlichen und tabellarischen Format. Die Befehlszeilenkonsole dient zur Abfrage von Daten aus OrientDB. Sie verfügt über eine verteilte Architektur mit mehreren Servern, die Lese- und Schreiboperationen durchführen können. Replikatserver werden für die Durchführung von Lese- und Abfrageoperationen verwendet. Sie unterstützt die Indizierung und ist außerdem ACID-kompatibel. Einige der Unternehmen, die OrientDB verwenden, sind Comcast Corporation und Blackfriars Group.
Dgraph
Dgraph ist eine Cloud-Graph-Datenbank, die GraphQL unterstützt. Sie wurde mit Go entwickelt. Sie minimiert die Netzwerkaufrufe und reduziert die Latenzzeit durch Maximierung der gleichzeitigen Abfrageverarbeitung. Die nahtlose Integration von Dgraph mit GraphQL hilft bei der einfachen Entwicklung von GraphQL-Backend-Anwendungen.

Eine GraphQL-Mutation wird durch eine Lambda-Funktion geleitet, die mit der Datenbank und einer Datenpipeline interagiert. Dies vereinfacht die Abfrageverarbeitung. Es ist horizontal skalierbar, d.h. die Anzahl der Ressourcen wird mit zunehmenden Abfragen und Daten erhöht. Es bietet verschiedene Funktionen wie JWT-basierte Autorisierung, Datenvisualisierung, Cloud-Authentifizierung, Datensicherungen usw. Zu den Unternehmen, die Dgraph verwenden, gehören Intuit, Intel und Factset.
Tigergraph
Tigergraph ist eine Property-Graph-Datenbank, die mit C entwickelt wurde. Sie ist hochgradig skalierbar und führt fortschrittliche Analysen für stark verknüpfte Daten durch. Sie verwendet eine native Graphenstruktur für die Speicherung von Daten und eine Graphenverarbeitungsmaschine für die Verarbeitung von Daten. Die Datenbank wird auf der Festplatte und im Arbeitsspeicher gespeichert und verwendet außerdem einen CPU-Cache für den schnellen Abruf. Es verwendet die Funktion Map Reduce für die parallele Datenverarbeitung.
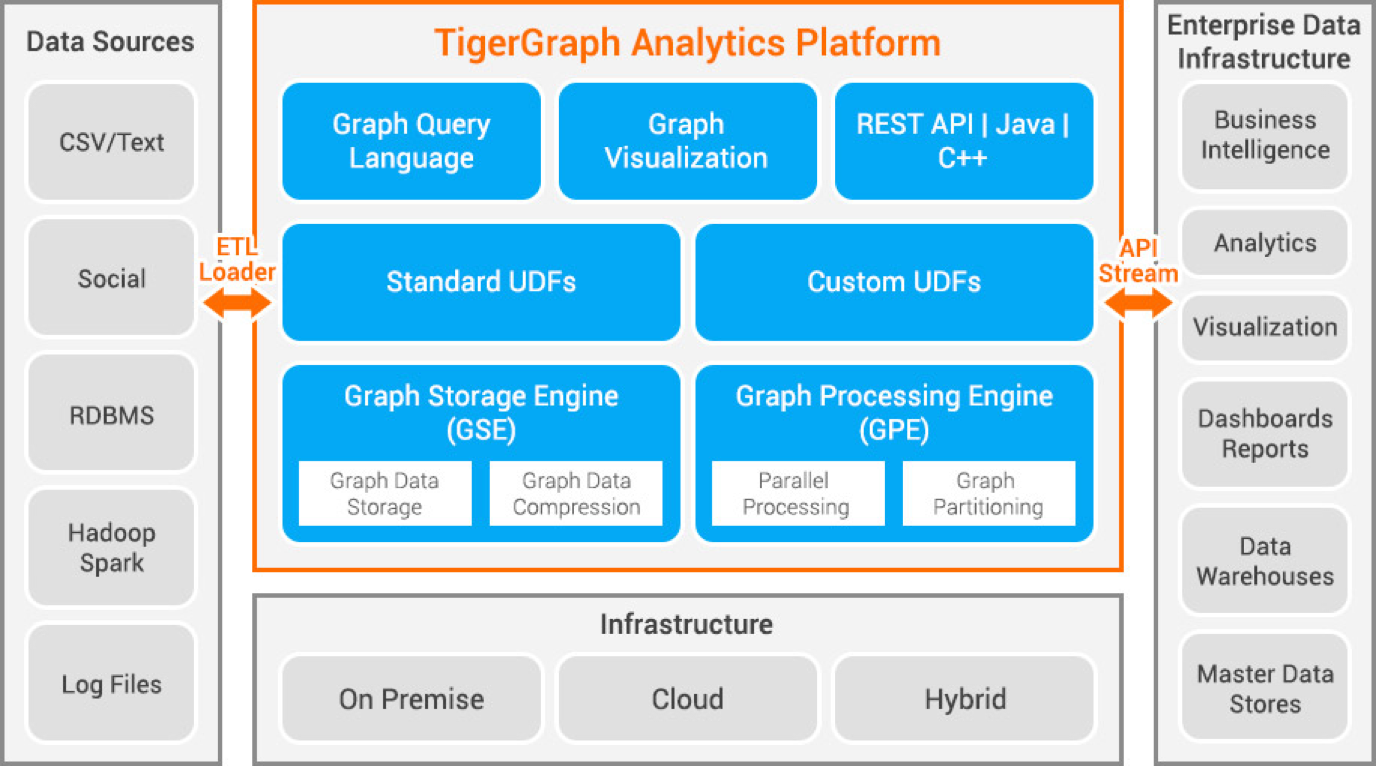
Sie ist extrem schnell und skalierbar. Sie führt parallele Berechnungen durch und bietet Aktualisierungen in Echtzeit. Es verwendet Datenkomprimierungstechniken und komprimiert die Daten um das 10-fache. Die Daten werden automatisch auf verschiedene Server aufgeteilt, so dass der Benutzer keine Zeit und Mühe aufwenden muss, die Daten manuell aufzuteilen. Es wird zur Aufdeckung von Betrug in Haushalten, zum Management der Lieferkette und zur Verbesserung des Gesundheitswesens eingesetzt. JPMorgan Chase, Intuit und die United Health Group sind einige Unternehmen, die Tigergraph nutzen.
AllegroGraph
AllegroGraph verwendet die Entity-Event Knowledge Graph-Technologie, um Analysen und Entscheidungen auf hoch vernetzten, komplexen und dichten Daten durchzuführen. Die Daten werden im JSON- und JSON-LD-Format in den Knotenpunkten des Graphen gespeichert. Es verwendet die REST-Protokollarchitektur. Es kann auch mit extrem großen Datenmengen umgehen, indem es die Daten nach bestimmten Kriterien aufteilt und über mehrere Wissensdatenbank-Repositories verteilt.
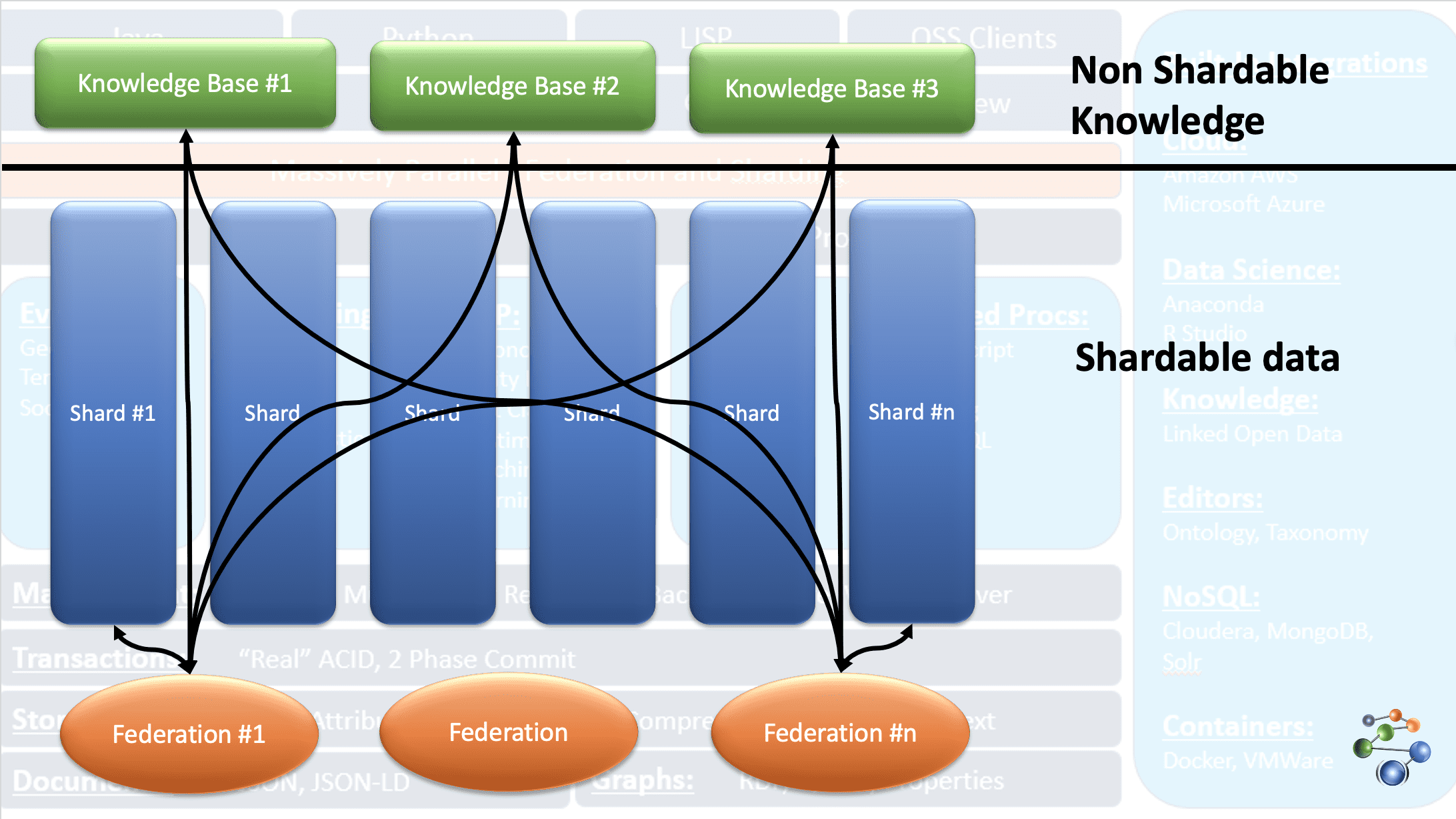
Dies ist dank der FedShard-Funktion der AllegroGraph Datenbank möglich. Die Ausführung von Abfragen erfolgt durch die Kombination der Föderationen mit Wissensdatenbank-Repositories. Sie unterstützt XML-Schematypen und verwendet Triple-Indizes. Sie speichert geografische Daten wie Breiten- und Längengrade und zeitliche Daten wie Datum, Zeitstempel usw. Es ist mit Windows, Mac und Linux kompatibel. Es wird in den Bereichen Betrugserkennung, Gesundheitswesen, Identifizierung von Entitäten, Risikovorhersage usw. eingesetzt.
Stardog
Stardog ist eine Graphdatenbank, die eine Graphdatenvirtualisierung durchführt und Daten aus Data Warehouses und Data Lakes miteinander verknüpft, ohne die Daten physisch in einen neuen Speicherort zu kopieren. Stardog basiert auf den offenen RDF-Standards. Es unterstützt strukturierte, halbstrukturierte und unstrukturierte Daten. Diese Art der Materialisierung durch Stardog bietet Flexibilität. Es ist die einzige Graphdatenbank, die Wissensgraphen und Virtualisierung kombiniert.

Stardog verwendet eine auf KI basierende Inferenzmaschine, um Abfragen effizient zu verarbeiten und auszugeben. Es handelt sich um eine ACID-konforme Graphdatenbank. Gleichzeitiges Lesen und Schreiben wird unterstützt. Dank der “State-of-the-Art”-Architektur lassen sich komplexe Abfragen mühelos bearbeiten. Sie wird in den Bereichen IT-Asset-Management, Datenverwaltung und -analyse eingesetzt und bietet hohe Verfügbarkeit. Einige Unternehmen, die Stardog verwenden, sind Cisco, eBay, die NASA und Finra.
Abschließende Worte
Mit Graphdatenbanken lassen sich viele Beziehungen einfach abfragen und Daten effektiv speichern. Sie sind skalierbar, sicher und können mit vielen Tools, APIs und Sprachen von Drittanbietern integriert werden. In den letzten Jahren wurden sie in die Cloud integriert und bieten die beste Leistung.
Sie vereinfachen komplexe Verknüpfungen in einfache Abfragen, was für die Entwickler eine leichte Aufgabe ist. Datenintensive Aufgaben wie IoT und Big Data sind ebenfalls Graphdatenbanken. Diese werden sich weiter entwickeln und in Zukunft sicherlich auch auf andere Anwendungsfälle ausgedehnt werden.