Ein physisches Datenmodell ist ein Rahmen oder ein Schema, das beschreibt, wie die Daten tatsächlich in einer Datenbank gespeichert werden.
Bevor wir mit dem physischen Datenmodell beginnen, sollten wir verstehen, was es mit der Datenmodellierung auf sich hat.
Welche Eigenschaften ermöglichen es den Benutzern, eine Datenbank effektiv zu nutzen? Wie können Sie sicher sein, dass die Datenbank, die Sie entwickeln, alle Ihre Anforderungen erfüllt? Betrachten Sie das Konzept der Datenmodellierung als die Antwort auf die Frage, wie Sie an Daten gelangen und sie in eine nutzbare Datenbank umwandeln können.
Was ist Datenmodellierung?
Bei derDatenmodellierung handelt es sich um den Prozess der Erstellung einer optimierten Darstellung einer Softwareanwendung und der darin enthaltenen Datenkomponenten, wobei Text und Symbole verwendet werden, um die Informationen und ihren Fluss darzustellen.

Es handelt sich dabei um eine Technik zur Darstellung und Visualisierung all der verschiedenen Stellen, an denen ein Softwareprogramm oder eine Anwendung Daten speichert, und wie diese verschiedenen Informationsquellen integriert und ineinander überführt werden.
Die Datenmodellierung ist ein wichtiger Aspekt der Datenverwaltung. Sie hilft bei der Identifizierung von Informationsanforderungen für Arbeitsabläufe, indem sie eine visuelle Darstellung der Datenpunkte und ihrer Verhaltensmuster liefert.
Sie ermöglicht es, zu bestimmen und zu verstehen, wie Daten verwaltet, geändert, angezeigt und im Unternehmen verteilt werden.
Die Bedeutung der Datenmodellierung
Moderne Unternehmen sammeln eine Vielzahl von Daten aus zahlreichen Quellen. Um effektive strategische Entscheidungen treffen zu können, müssen Sie die Daten auf praktische Erkenntnisse hin untersuchen.
Effektive Datenerfassung, -speicherung und -berechnung sind für eine genaue Datenanalyse erforderlich. Je nach Datentyp, wie z.B. strukturiert, halbstrukturiert, ordinal usw., werden zahlreiche Tools für eine effiziente Analyse eingesetzt.

Die Datenmodellierung ermöglicht es Ihnen, Ihre Daten zu verstehen und die beste Lösung für deren Verwaltung und Kontrolle auszuwählen. Unternehmen erstellen ein Datenmodell, bevor sie Datenbanksysteme für ihren Betrieb entwickeln, so wie ein Architekt einen Plan erstellt, bevor er ein Haus baut.
Die wichtigsten Vorteile der Datenmodellierung sind folgende
- Bietet schnelle und effektive Lösungen für den Entwurfsprozess und die Bereitstellung von Datenbanken.
- fördert die Einheitlichkeit bei der Datenberichterstattung und der Entwicklungsarbeit im gesamten Unternehmen
Und außerdem erleichtert die Implementierung eines Datenmodellierungskonzepts die Interaktion zwischen den Analyseteams und den Datenbankingenieuren.
Arten der Datenmodellierung
Es gibt drei verschiedene Arten von Datenmodellen, die von Datenmodellierern verwendet werden, um Marketingkonzepte und -verfahren, relevante Datenelemente und deren Attribute und Beziehungen sowie praktische Datenverwaltungsrahmen zu beschreiben.
Wenn Unternehmen funktionale Programme und Datenbanken erstellen, werden die Datenmodelle oft Schritt für Schritt entwickelt. Im Folgenden finden Sie die verschiedenen Arten von Datenmodellen und was jedes einzelne davon beinhaltet:
#1. Konzeptionelle Datenmodellierung
Es handelt sich im Grunde um eine organisierte Ansicht oder eine visuelle Darstellung von Datenbankkonzepten und deren Beziehungen. Es dient als konventioneller Ausgangspunkt für die Datenmodellierung und definiert die verschiedenen Datenquellen und den Datenfluss innerhalb des Unternehmens.
Es dient als übergeordneter Leitfaden für die Erstellung logischer und physischer Modelle und ist ein wichtiger Bestandteil der Nachweise für die Datenarchitektur.
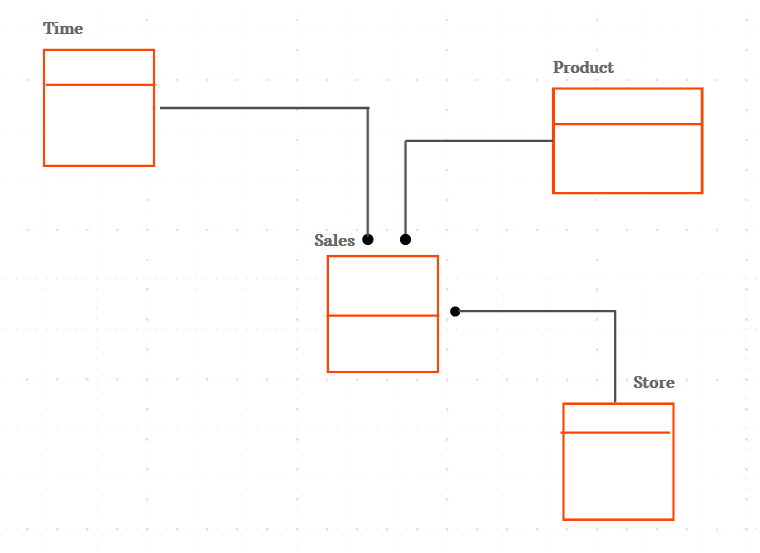
Das konzeptionelle Datenmodell stellt lediglich das Gesamtlayout und den Inhalt dar, nicht aber die Einzelheiten der einzelnen Objekte. Die gesamte Organisationsstruktur und die Daten Ihres Unternehmens werden durch ein konzeptionelles Datenmodell beschrieben.
Es dient der Organisation von Geschäftskonzepten, die von Ihren Dateningenieuren festgelegt wurden. Es konzentriert sich auf den Entwurf von Entitäten, die Definition der Attribute einer Entität und die Definition von Beziehungen zwischen Objekten und nicht nur auf die Besonderheiten der Datenbankstruktur.
Sie haben zum Beispiel Daten über Geschäfte, Zeit und Produkte. Diese Datensätze oder Entitäten haben alle Verbindungen zu anderen Entitäten. In diesem konzeptionellen Datenmodell werden sowohl die Entitäten als auch die Verbindungen zwischen den Entitäten angegeben.
#2. Logische Datenmodellierung
Ein logisches Datenmodell erweitert das konzeptionelle Modell um präzise inhaltliche Eigenschaften innerhalb jeder Entität und detaillierte Verbindungen zwischen diesen Attributen. Die Erstellung eines logischen Datenmodells mit geringer Komplexität kann anhand des konzeptionellen Datenmodells als Richtlinie erfolgen.
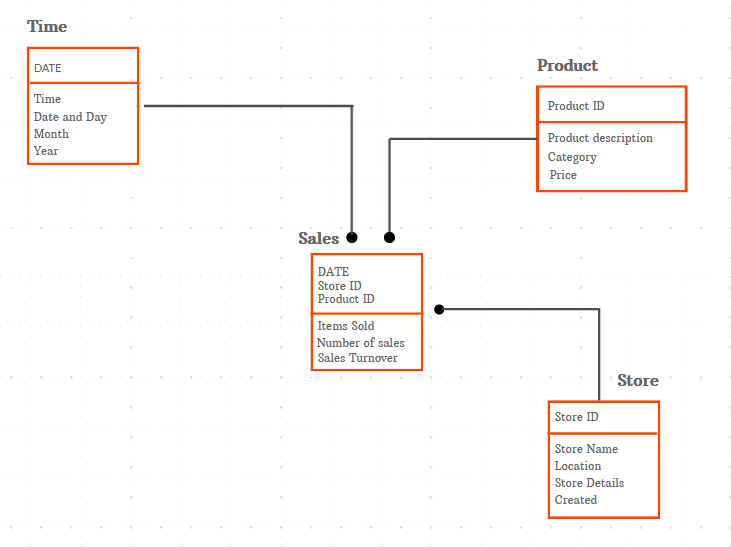
Die Beziehungen zwischen Datenelementen werden in logischen Datenmodellen dargestellt, die auch eine technische Beschreibung der Daten enthalten. Beispiel: Kunde A kauft Artikel B in Geschäft C.
Die Anordnung der Datenobjekte und die Verbindungen zwischen ihnen werden durch dieses Modell weiter definiert. Da das Ziel darin besteht, ein detailliertes Diagramm der Standards und Datenstrukturen zu erstellen, werden logische Datenmodelle in der Regel für ein bestimmtes Projekt verwendet.
Das logische Datenmodell bietet mehr Informationen über das gesamte Design des konzeptionellen Modells, vernachlässigt aber Details über die Datenbank selbst, da das Modell zur Beschreibung verschiedener Datenbankprodukte und -dienste verwendet werden kann.
Das logische Datenmodell dient als technisches Modell der Prinzipien und Datenstrukturen, wie sie von Dateningenieuren festgelegt wurden, und es hilft bei der Entscheidungsfindung über das physische Datenmodell, das zur Erfüllung Ihrer betrieblichen und datenbezogenen Anforderungen benötigt wird.
#3. Physische Datenmodellierung
Im Allgemeinen wird die Implementierung eines Datenmodells in einer Datenbank durch ein physisches Datenmodell beschrieben. Physische Datenmodelle werden von Datenbankingenieuren verwendet, um Layouts und Architekturen für Datenbanken zu entwickeln.
Durch die Simulation der RDBMS-Komponenten, einschließlich Tabellen, Feldern, Indizes, Spaltenschlüsseln, Constraints, Triggern und anderen, hilft das physische Datenmodell erheblich bei der Visualisierung des Designs von Datenbanken.
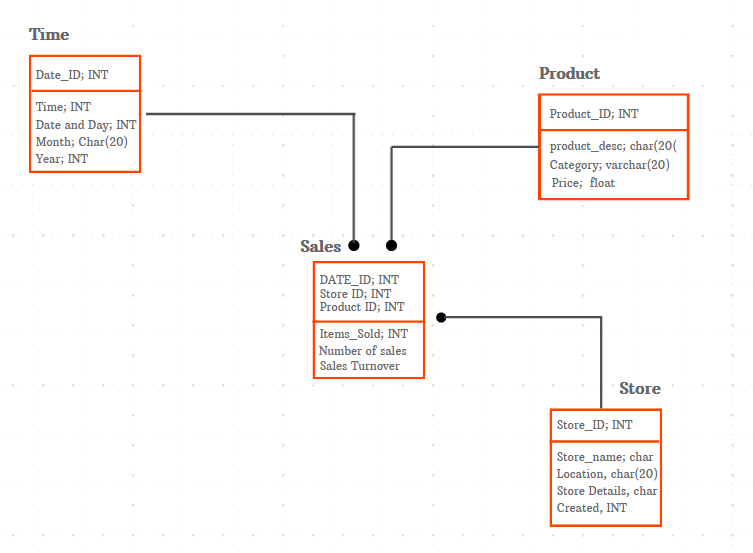
Es spezifiziert die organisatorischen Prozesse, die eine Datenbank oder ein Dateisystem zur Erfassung und Verarbeitung der Daten verwendet. Das physische Datenmodell erklärt die relevanten Details, wie das logische Modell implementiert wird.
Es bietet eine Datenbankabstraktion und hilft bei der Erstellung des Schemas oder eines Layouts. Dies ist auf die umfangreichen Metadaten zurückzuführen, die ein physisches Datenmodell liefert.
In diesem Artikel wird in erster Linie das Konzept der physischen Datenmodellierung behandelt.
Fangen wir an!
Was ist ein physisches Datenmodell?
Ein physisches Datenmodell ist ein Rahmenwerk oder eine Architektur, die beschreibt, wie die Daten tatsächlich in einer Datenbank gespeichert werden. Das eigentliche Schema einer Datenbank wird anhand dieses physischen Datenmodells entworfen. Es umfasst alle verschiedenen Tabellen, ihre Spalten und die Verbindungen zwischen ihnen.
Das interne Schema einer Datenbank wird mit Hilfe eines physischen Modells entworfen. Das Ziel ist es, die Datenbank in Gebrauch zu nehmen. Dieses physische Modell kann direkt in ein tatsächliches Datenbankdesign umgewandelt werden und unterstützt die weitere Entwicklung des Informationsmanagements. Bei der Verwendung mehrerer Datenbanksysteme ist es möglich, dass aus demselben logischen Datenmodell verschiedene physische Modelle erstellt werden.
Merkmale eines physischen Datenmodells
- Es deckt die Datenanforderungen für ein bestimmtes Projekt oder Programm ab, obwohl es je nach den Projektzielen mit einigen anderen physischen Modellen kombiniert werden kann.
- Die spezifischen Datentypen und zugewiesenen Größen sowie die Standardwerte für Spalten sollten angegeben werden.
- Ansichten (virtuelle Tabelle auf der Grundlage der Ergebnismenge), Indizes, Transaktionen und andere Konzepte werden definiert, einschließlich Primär- und Fremdschlüssel.
Datenbankingenieure erstellen das physische Datenmodell, bevor das endgültige Datenbankschema in Betrieb genommen wird. Um sicherzustellen, dass jede Komponente der Architektur berücksichtigt wurde, verwenden sie auch umfassende Datenmodellierungsansätze.
Erforderliche Schritte zur Erstellung eines physischen Datenmodells
Dies sind die Schritte, die zur Erstellung eines physischen Datenmodells befolgt werden müssen.
- Erstellen Sie ein physisches Datenmodell unter Verwendung des bereits vorhandenen logischen Datenmodells.
- Fügen Sie dem physischen Datenmodell Datenbankattribute und -eigenschaften hinzu.
- Konvertieren Sie Entitäten in Tabellen und Entitätsbeziehungen in Fremdschlüssel.
- Konvertieren Sie Attribute in Spalten.
- Überprüfen Sie, ob alles in Ordnung ist, indem Sie die Datenbank und das Datenmodell vergleichen.
- Wenn es Änderungen zwischen der aktuellen und früheren Iterationen des Datenmodells gibt, erstellen Sie einen Änderungsprotokollsatz.
Hauptkomponenten eines physischen Datenmodells
Ein physisches Datenmodell (PDM) beschreibt die Art und Weise, wie ein Datenmodell in einer Datenbank strukturiert werden soll, und einige der wichtigsten Komponenten sind
- Tabelle: Das PDM legt Tabellen fest, die Instanzen realer Konzepte wie Kunden, Produkte und Aufträge sowie Beziehungen zwischen ihnen definieren und gleichzeitig die Anforderungen an die Speicherung relevanter Informationen umreißen.
- Spalte: Jede Datenbank verfügt über einzelne Tabellen, die in Spalten unterteilt sind, welche die Attribute der Entität oder vielleicht Merkmale darstellen, jeweils mit Namen, eindeutigem Datentyp und Einschränkungen wie Primär-/Fremdschlüssel. Schließlich enthält jede Zeile einen Datensatz mit echten Daten.
- Datentypen: Die Informationen einer Spalte definieren die Daten, die sie speichern muss, sowie ihre Speicheranforderungen und die damit verbundene Leistung. Die Art der Informationen, die eine Spalte enthält, bestimmt u.a. den Genauigkeitsbedarf, die Verarbeitungsmöglichkeiten und die Kapazität. Verschiedene Datentypen haben unterschiedliche Anforderungen an Genauigkeit, Handhabungsmöglichkeiten und Kapazität.
- Primärschlüssel: Er gewährleistet die Datenintegrität mit nicht-nullbaren, eindeutigen Spalten mit eindeutigen Identifikationen jeder Zeile in einer Tabelle.
- Fremdschlüssel: Garantieren einen präzisen Datenaustausch zur Wahrung der Integrität zwischen Tabellen mit Fremdschlüsseln mit garantierten, zuverlässigen, assoziativen und leistungsstarken Verknüpfungen.
- Indizes: Die Datenstruktur hilft der Abfrage, besser zu funktionieren, indem Zeilen, die bestimmte Kriterien erfüllen, schnell identifiziert werden.
- Einschränkungen (Constraints): Constraints sind Regeln, die sicherstellen, dass Ihre Daten in der Datenbank sauber, gültig und konsistent bleiben. Einige gängige Arten von Beschränkungen sind:
- NOT NULL: Garantiert, dass keine Nullwerte in einer Spalte gespeichert werden.
- UNIQUE : Erzwingt, dass alle Werte in einer Spalte eindeutig und verschieden sind.
- CHECK: Eine Einschränkung dieser Art verlangt, dass die Daten in den Spalten eine bestimmte Bedingung erfüllen.
- Speicherinformationen: Physische Mechanismen, die ein Produktdatenverwaltungssystem für die Datenspeicherung verwendet. Dabei kann es sich um Datenbank-Engines, Dateisysteme oder Plattenspeichergeräte handeln.
Physisches vs. konzeptionelles vs. logisches Datenmodell
Im Folgenden vergleichen wir diese drei verschiedenen Kategorien von Datenmodellen. Die verschiedenen Merkmale werden in der folgenden Tabelle gegenübergestellt.
| Merkmal | Konzeptionell | Logisch | Physisch |
|---|---|---|---|
| Entität Namen | ✓ | ✓ | |
| Beziehungen zwischen Entitäten | ✓ | ✓ | |
| Attribute | ✓ | ||
| Primärschlüssel | ✓ | ✓ | |
| Fremdschlüssel | ✓ | ✓ | |
| Tabellennamen | ✓ | ||
| Spaltennamen | ✓ | ||
| Datentypen der Spalten | ✓ |
Entitäten und Verbindungen werden in einem konzeptionellen Datenmodell dargestellt. Die Merkmale und der Primärschlüssel werden nicht erwähnt. Es deckt lediglich den High-Level-Entwurf ab, einschließlich der Tabellen und ihrer Verknüpfungen, die es geben soll.
Im Anschluss an das konzeptionelle Modell wird das logische Modell erstellt. Die Beziehungen zwischen Datenelementen werden in logischen Datenmodellen dargestellt, die auch eine technische Beschreibung der Daten enthalten. Zusätzlich gibt es ein physisches Datenmodell, das das logische Datenmodell erweitert und jedem Feld seinen Datentyp, seine Größe usw. zuordnet.
Bewährte Vorgehensweisen bei der Modellierung physischer Daten
Im Folgenden finden Sie einige Richtlinien oder Best Practices für die physische Datenmodellierung, die je nach Geschäft modifiziert und geändert werden können:
Geschäftsziel: Der Schlüssel liegt in der Ausrichtung Ihres physischen Datenmodells auf die Geschäftsziele und den Datenbedarf Ihres Unternehmens. Das Modell muss auf einfache, aber effektive Weise die für kritische Prozesse und gute Entscheidungen erforderlichen Daten widerspiegeln und darf nicht zu kompliziert sein.
Design und Skalierbarkeit: Zu Beginn ist es wichtig, ein gut definiertes logisches Datenmodell als Grundlage für jede physische Datenbank zu erstellen. Es ist wichtig, vorausschauend zu planen und Ihr System so flexibel und anpassungsfähig zu gestalten, dass künftige Änderungen ohne allzu große Unterbrechungen oder Zeitverzögerungen vorgenommen werden können. Modularisierte Datenbanken, bei denen die Wiederverwendung im Vordergrund steht, sind der Schlüssel zum Aufbau nachhaltiger Strukturen, die den Geschäftsanforderungen gerecht werden, die sich im Laufe der Zeit stark verändern.
Technik der Datenmodellierung: Faktoren wie Datengröße, Leistungsanforderungen, Datenstruktur und Skalierbarkeit helfen bei der Auswahl der richtigen Datenmodellierungstechnik. Ihr spezifischer Bedarf hängt jedoch z.B. davon ab, welche Art von Datenbank Sie verwenden, um den maximalen Nutzen aus der gewählten Lösung zu ziehen.
Benennungskonvention: Die Schaffung sinnvoller Namen für Entitäten, Attribute und andere Merkmale Ihres physischen Datenmodells. Dies erleichtert die Kommunikation und Zusammenarbeit zwischen den Beteiligten. Einfache, aber eindeutige Namen werden so gewählt, dass jedes Element den Grund für dasselbe widerspiegelt.
Standardisierung von Datentypen: Verwenden Sie in Ihrem physischen Datenmodell standardisierte Datentypen für eine einheitliche und effiziente Leistung. Dies soll die Manipulation der Daten vereinfachen, ihre Integrität gewährleisten und einen effektiven Austausch zwischen verschiedenen Systemen ermöglichen, indem Sie geeignete Typen auswählen und dabei die Speicheranforderungen und andere Aspekte berücksichtigen.
Regeln für die Datenintegrität: Sie sorgen für Konsistenz und Genauigkeit bei allen Einträgen von Primär- und Fremdschlüsseln sowie für Einschränkungen wie NOT NULL, UNIQUE und CHECK in den physischen Modellen.
Indizierung: Die Indizierung von Tabellen sollte strategisch für eine verbesserte Abfrageleistung konzipiert sein. Die Indizes verbessern den schnelleren Datenzugriff, indem sie einen kriterienbasierten Abruf ermöglichen und eine Indizierungsoptimierung bieten, die eine effektive Analyse der Abfragen und die Erkennung der Spalten, die häufig in der Abfrage vorkommen, beinhaltet.
Optimierung: Neben der Verbesserung der Datenintegrität können die Administratoren die Gesamtleistung Ihrer Datenbank optimieren, indem sie Normalisierung und Denormalisierung, Partitionierung, geclusterte und nicht geclusterte Indizes sowie schnellere Speichergeräte für häufig verwendete Tabellen/Indizes intelligent einsetzen.
Überwachung: Die Überwachung ist einer der letzten Schritte, die durchgeführt werden. Ihr Ziel ist es, die Leistung des physischen Datenmodells zu bewerten, potenzielle Engpässe zu identifizieren, mögliche Probleme zu erkennen, Bereiche für Verbesserungen zu erkunden und mit Hilfe von Tools zur Leistungsüberwachung die erforderlichen Informationen zu sammeln, um die beste Entscheidung zu treffen.
Wartung: Regelmäßige Bewertung des physischen Datenmodells, um seine anhaltende Effizienz zu bestätigen und es entsprechend anzupassen, wenn sich die geschäftlichen Bedürfnisse und Datenanforderungen ändern.
Dokumentation: Erläutern Sie das physische Datenmodell in Diagrammen, Beschreibungen, Tabellen und vielen anderen Details zu dem, was implementiert wird. Verwenden Sie eine detaillierte Sprache, die jedoch gleichzeitig für alle Beteiligten, ob technisch oder nicht, leicht zu verstehen ist.
Auf diese Weise lässt sich das physische Datenmodell optimal gestalten und effektiv nutzen
Lernressourcen zur Datenmodellierung
Sie können online viele Ressourcen finden, die Ihnen helfen, die Datenmodellierung zu verstehen, aber es kann schwierig sein, die guten auszuwählen. Datenmodellierung ist ein wertvolles Talent, aber es muss auf die richtige Weise erlernt werden.

Wenn Sie versuchen, Ihre Datenmanagement- oder Analysefähigkeiten für persönliche oder geschäftliche Zwecke zu verbessern, werfen Sie einen Blick auf diese Liste der besten Datenmodellierungskurse und -bücher.
#1. Mastering Data Modeling Grundlagen
In diesem Udemy-Kurs lernen Sie die Methoden kennen, die erforderlich sind, um Datenmodelle für Ihr Unternehmen zu erstellen, die Entitäten, Merkmale, Assoziationen, Strukturen und andere Modellierungselemente enthalten, die semantisch genau sind.

Die Lernenden benötigen lediglich ein grundlegendes Verständnis der Begriffe und Strukturen der Datenverwaltung, wie z.B. RDBMS-Tabellen und die konzeptionelle Beziehung zwischen verschiedenen Datensätzen.
#2. Fortgeschrittene Datenmodellierung
Dieser Coursera-Kurs ist fantastisch für diejenigen, die ihre Karriere vorantreiben wollen. Am Ende dieses Kurses werden Sie ein solides Verständnis dafür haben, wie man grundlegende Datenmodellierungstechniken anwendet und moderne Speicherlösungen für ein Datenbanksystem durchläuft. Für die Teilnehmer sind keine Vorkenntnisse im Bereich Datenbanktechnik erforderlich.
#3. OBIEE 12c Datenmodellierungskurs
Dieser Udemy-Kurs richtet sich an alle, die sich für eine Karriere in der OBIEE-Datenmodellierung interessieren, einschließlich Studenten, IT-Fachleute und Projektmanager.

Am Ende dieses Kurses werden Sie in der Lage sein, verschiedene Zeitreihenfunktionen und Datenmodellierungskonzepte zu implementieren, einschließlich Datendenormalisierung, dimensionaler Datenmodellierung und Sternschema-Modellierung.
#4. Excel Business Intelligence: Datenmodellierung 101
In diesem LinkedIn-Kurs behandelt der Trainer die Grundlagen der Datenbankarchitektur und der Normalisierung, führt Sie durch die Datenmodellschnittstelle von Excel und stellt Ihnen erprobte Techniken vor.

Sie können Ihr Wissen über Tabellenverknüpfungen, Topologien und andere Konzepte verbessern, indem Sie die in diesem Kurs vorgestellten Themen studieren. Es sind keine Voraussetzungen erforderlich, um mit diesem Kurs zu beginnen.
#5. Das Data Warehouse Toolkit
In diesem Buch führen die Autoren die Kursteilnehmer in dimensionale Modellierungsansätze wie Rechnungsstellung, Kundeninteraktionen und den Aufbau grundlegender Datenbanken ein. Außerdem werden die neuen und verbesserten Dimensionsmodellierungsmuster des Sternschemas besprochen.
| Preview | Product | Rating | |
|---|---|---|---|

|
The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd Edition | Buy on Amazon |
Darüber hinaus enthält dieses Buch einen Leitfaden für fortgeschrittene Simulationsbesprechungen mit Unternehmensvertretern. Es sind keine Vorkenntnisse in der Datenmodellierung erforderlich. Selbst Anfänger können sich durch die Lektüre dieses Buches problemlos in die Konzepte der Datenmodellierung einarbeiten.
#6. Datenmodellierung leicht gemacht, 2. Auflage
Dieses Buch ist in einer unterhaltsamen Art und Weise geschrieben, die die Benutzer dazu anregt, die wichtigsten Ziele zu erlernen, wie z.B. zu verstehen, wann ein Datenmodell erforderlich ist und welche Form am vorteilhaftesten ist, ein normalisiertes relationales Datenbanksystem zu erstellen und Methoden zu verwenden, um ein Datenmodell in ein aussagekräftiges physisches Layout für die Datenbank zu verwandeln.
| Preview | Product | Rating | |
|---|---|---|---|

|
Data Modeling Made Simple, 2nd Edition: A Practical Guide for Business and IT Professionals (Take It… | Buy on Amazon |
Dieses Buch bietet ein realistisches, funktionales Verständnis von Datenmodellierungsprinzipien und Best Practices für geschäftliche oder IT-Zwecke.
#7. Data Modeling Essentials, Dritte Ausgabe
Dieses Buch vermittelt die Grundlagen der Datenmodellierung, wobei der Schwerpunkt auf der Entwicklung von Techniken und nicht nur auf der Kenntnis der “Prinzipien” liegt
| Preview | Product | Rating | |
|---|---|---|---|

|
Data Modeling Essentials (The Morgan Kaufmann Series in Data Management Systems) | Buy on Amazon |
Dieses Buch untersucht die Komplexität der Erstellung von Systemen unter realen Bedingungen, indem es die Vor- und Nachteile verschiedener Alternativen abwägt und sprachliche und grafische Analysetechniken verwendet, die den Industriestandards entsprechen. Dadurch werden die Lernenden ermutigt, die Grundlagen der Datenmodellierung auf reale Modelle anzuwenden.
Zukünftige Trends in der physischen Datenmodellierung
Angesichts des zunehmenden Wettbewerbs und der Notwendigkeit, die angebotenen Produkte oder Dienstleistungen zu differenzieren, wenden sich Unternehmen zunehmend der Datenmodellierung zu, um sich Wettbewerbsvorteile zu verschaffen und ihr Kundenerlebnis zu verbessern.
Angesichts dieser kostensparenden Strategien werden Unternehmen nun digitale Technologien wie künstliche Intelligenz (KI), maschinelles Lernen (ML) und Automatisierung einsetzen, um ihre IT-Investitionen so effizient wie möglich zu nutzen und gleichzeitig bessere Ergebnisse bei der Datenmodellierung zu erzielen.

Und in Zeiten der Ungewissheit werden Unternehmen prädiktive Analysen propagieren, um Trends so vorherzusagen, dass eine bessere Planung gewährleistet werden kann. Für eine effektive Umsetzung dieser Trends ist es für Unternehmen und Organisationen von entscheidender Bedeutung, die Ziele der Aufgaben, für die sie Datenmodellierungslösungen benötigen, richtig zu definieren und sie mit der allgemeinen Unternehmensstrategie abzustimmen.
Einige dieser Trends gehören zu den grundlegenden Trends, die den größten Einfluss auf die Zukunft der physischen Datenmodellierung haben:
#1. Automatisierung und KI
Die Möglichkeiten von KI und ML sind enorm. Datenexperten werden in der Lage sein, KI und Algorithmen des maschinellen Lernens für die komplizierteren Lösungen der Datenmodellierung, wie z.B. prädiktive Analysen, zu nutzen. Sie werden Erkenntnisse liefern, die dann helfen, bessere Entscheidungen zu treffen und im Gegenzug die Effizienz von Unternehmen zu steigern.
Im Laufe der Jahre werden KI und ML zunehmend dazu genutzt werden, den physischen Datenmodellierungsprozess zu automatisieren, z. B. bei der Datentransformation, der Datenaufnahme und der Automatisierung der Zero-Day-Datenbereinigung. Dadurch können sich die Datenmodellierer auf strategischere Aufgaben konzentrieren, z. B. auf Data Governance und Datenqualität.
#2. Data Governance und Qualität
Da die Datensicherheit, die Einhaltung von Vorschriften und der Schutz der Privatsphäre immer wichtiger werden, werden physische Modelle so dargestellt, dass sie diese gesetzlichen Anforderungen berücksichtigen. Darüber hinaus sind Containerisierung und Orchestrierung aufkommende Implementierungstechniken für Datenbanken, die sich auf die Struktur und damit auf die zukünftige Verwaltung ihrer physischen Modelle auswirken können.
#3. Änderungen in bestehenden Datenmodellen
Da Unternehmen dazu neigen, Zeitseriendatenbanken einzusetzen, um Echtzeitmodelle und KI-gesteuerte Modelle rund um Zeitdaten einzubeziehen, wird es in der Folge zu Veränderungen innerhalb der Datenmodelle kommen. Zeitreihen – Sie helfen dem Analysten, Trends in der Darstellung von Daten zu erkennen, um den Kontext besser einschätzen zu können. Die Modellierer verwenden Zeitfenster, um die Diagramme für bessere Prozesse und Abläufe zu aktualisieren.
#4. Große Daten
Echtzeit-Analysekapazitäten erfordern ebenso gestraffte Tools für die Modellierung, und deshalb werden entwickelte Graphendatenbanken mit ihrer Fähigkeit, komplexe Verbindungen zu modellieren, auch schnell zu einer Standardwahl für Big-Data-Projekte neben den neu eingeführten Data-Mesh-Architekturen, die dezentralisierte Funktionalität über zahlreiche Systeme hinweg bieten und in letzter Zeit zu alltäglich geworden sind oder zu werden drohen.
#5. Datensicherheit
Datensicherheit, Datenschutz und ethische Überlegungen sind zentrale Ereignisse, die moderne Unternehmen für ihren Erfolg berücksichtigen müssen. In den Unternehmen ist man besorgt über die zahlreichen Vorschriften, die persönliche Daten schützen, um sicherzustellen, dass sie nicht durch äußere Einflüsse gefährdet sind – von der Verschlüsselung bis zur Zugangskontrolle.
Solche strengen Maßnahmen, die einen Sinn für Fairness und Transparenz widerspiegeln, werden es den Unternehmen erleichtern, ihre eigenen Interessen sowie die Rechte der Personen zu schützen, die mit der digitalen Identität verbunden sind.
#6. Daten als Dienstleistung (DaaS)
Data as a Service, auch DaaS genannt, gewinnt im heutigen Datenmanagement-Panorama zunehmend an Bedeutung, da es Modelle und Tools bietet, auf die bei Bedarf ähnlich wie bei der Softwarebereitstellung im Voraus zugegriffen werden kann.
Die Auswirkungen von DaaS gehen weit über die physische Datenmodellierung hinaus, da es die Aufgaben im Zusammenhang mit der Verwaltung riesiger Informationsmengen vereinfacht, indem es deren Genauigkeit und Qualität verbessert, die Zugänglichkeit von Analyseergebnissen erhöht und unsere Beziehung zu Datenpunkten verändert, was zu einer schnelleren Entscheidungsfindung durch die umfassende Analyse von Quellen mit riesigen Mengen führt.
Die oben genannten Trends sind nur einige der wichtigsten Trends im Bereich der physischen Datenmodellierung, die die Zukunft und die Entwicklung aller Unternehmen prägen werden.
Mit dem Wissen und der schnellen Anpassung werden Unternehmen nicht nur effektiv und effizient bleiben, sondern auch in der Lage sein, die Anforderungen ihres Geschäfts zu erfüllen. Datenexperten, die diese Trends aufgreifen und die neuesten Technologien und Tools weiterentwickeln können, werden sicherstellen, dass ihre Organisationen
Einpacken
Organisationen und Unternehmen versuchen ständig, Kunden für sich zu gewinnen. Dazu müssen sie Taktiken entwickeln, die ihre Dienstleistungen vorantreiben. Zu diesen Taktiken gehört der Einsatz von Datenmodellen zur Verbesserung der Geschäftsabläufe.
Ein gutes Datenmodell wird Ihnen helfen, Geld und Zeit zu sparen und die Produktivität zu steigern. Die Anwendung des Datenmodellierungskonzepts kann sicherstellen, dass ein Unternehmen wettbewerbsfähig wird, indem es Anpassungen auf der Grundlage der gesammelten Daten vornimmt.
Heutzutage gibt es eine große Nachfrage nach Fachleuten mit Kenntnissen in der Datenmodellierung. Ein Job in dieser Branche kann zahlreiche Möglichkeiten bieten, da Daten immer zur Untersuchung und Speicherung verfügbar sind. Ich hoffe, dass Ihnen dieser Artikel beim Erlernen von Konzepten zur Datenmodellierung geholfen hat.