El aprendizaje federado marca un cambio en la forma de entrenar los modelos de aprendizaje automático. Tradicionalmente, los datos procedentes de muchas fuentes se trasladan a una ubicación central para el entrenamiento de los modelos. El aprendizaje federado invierte el proceso: los modelos se envían a los datos, se entrenan localmente y sólo se comparten de vuelta las actualizaciones. Esto protege la privacidad del usuario al mantener los datos sensibles en los dispositivos originales.
El aprendizaje federado en la IA tiene importantes ventajas para el desarrollo del aprendizaje automático. Reduce los costes al eliminar las transferencias masivas de datos, y a menudo permite el entrenamiento en dispositivos de borde menos potentes.
¿Cómo funciona el aprendizaje federado?
El aprendizaje en el aprendizaje federado comprende una serie de pasos atómicos que producen un modelo. Estos pasos se denominan rondas de aprendizaje. Una configuración de aprendizaje típica itera a través de estas rondas, mejorando el modelo en cada paso. Cada ronda de aprendizaje implica los siguientes pasos.
Una ronda de aprendizaje típica
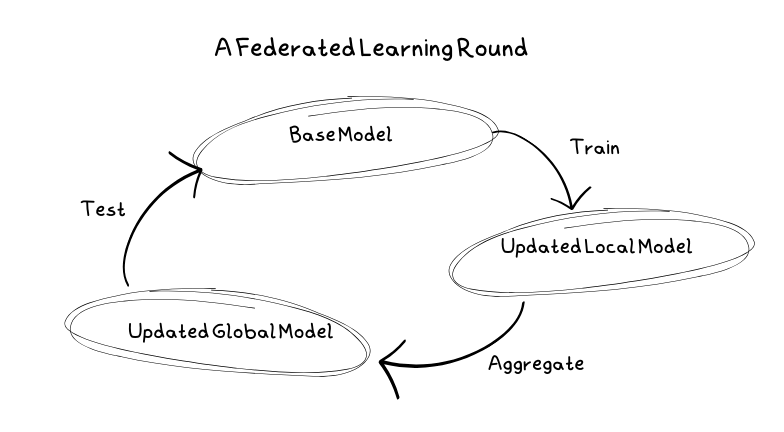
En primer lugar, el servidor elige el modelo a entrenar y los hiperparámetros como el número de rondas, los nodos cliente a utilizar y la fracción de nodos utilizados en cada nodo. En este punto, el modelo también se inicializa con los parámetros iniciales para formar el modelo base.
A continuación, los clientes reciben copias del modelo base para entrenarse. Estos clientes pueden ser dispositivos móviles, ordenadores personales o servidores. Entrenan el modelo en sus datos locales, evitando así compartir datos sensibles con los servidores.
Una vez que los clientes han entrenado el modelo en sus datos locales, lo envían al servidor como una actualización. Cuando el servidor la recibe, la actualización se promedia junto con las actualizaciones de otros clientes para crear un nuevo modelo base. Dado que los clientes pueden ser poco fiables, en este punto, es posible que algunos clientes no envíen sus actualizaciones. En este punto, el servidor se encargará de todos los errores.
Antes de volver a desplegar el modelo base, hay que probarlo. Sin embargo, el servidor no almacena datos. Por lo tanto, para probar el modelo, se envía de nuevo a los clientes, donde se prueba con sus datos locales. Si es mejor que el modelo base anterior, se adopta y se utiliza en su lugar.
Aquí tiene una guía útil sobre cómo funciona el aprendizaje federado del equipo de Aprendizaje Federado de Google AI.
Centralizado vs. Federado vs. Heterogéneo
En esta configuración, hay un servidor central responsable de controlar el aprendizaje. Este tipo de configuración se conoce como Aprendizaje Federado Centralizado.
Lo contrario del Aprendizaje Centralizado sería el Aprendizaje Federado Descentralizado, en el que los clientes se coordinan entre sí.
La otra configuración se denomina Aprendizaje Heterogéneo. En esta configuración, los clientes no tienen necesariamente la misma arquitectura de modelo global.
Ventajas del aprendizaje federado
- La mayor ventaja de utilizar el aprendizaje federado es que ayuda a mantener la privacidad de los datos privados. Los clientes comparten los resultados de la formación, no los datos utilizados en ella. También pueden establecerse protocolos para agregar los resultados de modo que no puedan vincularse a un cliente concreto.
- También reduce el ancho de banda de la red, ya que no se comparten datos entre el cliente y el servidor. En su lugar, los modelos se intercambian entre el cliente y el servidor.
- También reduce el coste del entrenamiento de los modelos, ya que no es necesario comprar un costoso hardware de entrenamiento. En su lugar, los desarrolladores utilizan el hardware del cliente para entrenar los modelos. Al tratarse de pocos datos, no sobrecarga el dispositivo del cliente.
Desventajas del aprendizaje federado
- Este modelo depende de la participación de muchos nodos diferentes. Algunos de los cuales no están controlados por el desarrollador. Por lo tanto, su disponibilidad no está garantizada. Esto hace que el hardware de entrenamiento no sea fiable.
- Los clientes en los que se entrenan los modelos no son precisamente potentes GPU. En su lugar, son dispositivos normales como teléfonos. Estos dispositivos, incluso en conjunto, pueden no ser lo suficientemente potentes en comparación con los clusters de GPU.
- El aprendizaje federado también asume que todos los nodos cliente son dignos de confianza y trabajan por el bien común. Sin embargo, puede que algunos no lo sean y emitan actualizaciones erróneas que provoquen la deriva del modelo.
Aplicaciones del aprendizaje federado
El aprendizaje federado permite aprender preservando la privacidad. Esto es útil en muchas situaciones, como por ejemplo:
- Predicciones de la siguiente palabra en teclados de smartphones.
- Dispositivos IoT que pueden entrenar modelos localmente en función de los requisitos específicos de la situación en la que se encuentran.
- Industrias farmacéuticas y sanitarias.
- Las industrias de defensa también se beneficiarían del entrenamiento de modelos sin compartir datos sensibles.
Marcos para el aprendizaje federado
Existen muchos marcos para implementar patrones de aprendizaje federado. Algunos de los mejores son NVFlare, FATE, Flower y PySft.