Cada día se generan millones de registros de datos en los sistemas informáticos actuales. Entre ellos se incluyen sus transacciones financieras, la realización de un pedido o los datos del sensor de su coche. Para procesar estos eventos de flujo de datos en tiempo real y mover de forma fiable los registros de eventos entre diferentes sistemas empresariales, necesita Apache Kafka.
Apache Kafka es una solución de flujo de datos de código abierto que gestiona más de un millón de registros por segundo. Junto a este alto rendimiento, Apache Kafka proporciona una gran escalabilidad y disponibilidad, baja latencia y almacenamiento permanente.
Empresas como LinkedIn, Uber y Netflix confían en Apache Kafka para el procesamiento en tiempo real y el flujo de datos. La forma más sencilla de iniciarse en Apache Kafka es tenerlo instalado y funcionando en su máquina local. Esto le permite no sólo ver el servidor Apache Kafka en acción, sino también producir y consumir mensajes.

Con experiencia práctica en el arranque del servidor, la creación de temas y la escritura de código Java utilizando el cliente Kafka, estará preparado para utilizar Apache Kafka para satisfacer todas sus necesidades de canalización de datos.
Cómo descargar Apache Kafka en su máquina local
Puede descargar la última versión de Apache Kafka desde el enlace oficial. El contenido descargado estará comprimido en formato .tgz. Una vez descargado, tendrá que extraerlo.
Si es usted Linux, abra su terminal. A continuación, navegue hasta la ubicación donde haya descargado la versión comprimida de Apache Kafka. Ejecute el siguiente comando:
tar -xzvf kafka_2.13-3.5.0.tgzUna vez completado el comando, encontrará que un nuevo directorio llamado kafka_2 .13-3.5.0. Navegue dentro de la carpeta utilizando
cd kafka_2.13-3.5.0Ahora puede listar el contenido de este directorio utilizando el comando ls.
Para los usuarios de Windows, puede seguir los mismos pasos. Si no encuentra el comando tar, puede utilizar una herramienta de terceros como
Cómo iniciar Apache Kafka en su máquina local
Después de haber descargado y extraído Apache Kafka, es hora de empezar a ejecutarlo. No tiene ningún instalador. Puede empezar a utilizarlo directamente a través de su línea de comandos o de la ventana del terminal.
Antes de empezar con Apache Kafka, asegúrese de que tiene Java 8 instalado en su sistema. Apache Kafka requiere una instalación de Java en ejecución.
#1. Ejecute el servidor Apache Zookeeper
El primer paso es ejecutar Apache Zookeeper. Lo obtendrá predescargado como parte del archivo. Es un servicio que se encarga de mantener las configuraciones y proporcionar sincronización para otros servicios.
Una vez dentro del directorio donde ha extraído el contenido del archivo, ejecute el siguiente comando:
Para usuarios de Linux
bin/zookeeper-server-start.sh config/zookeeper.propertiesPara usuarios de Windows
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
El archivo zookeeper. properties proporciona las configuraciones para ejecutar el servidor Apache Zookeeper. Puede configurar propiedades como el directorio local donde se almacenarán los datos y el puerto en el que se ejecutará el servidor.
#2. Inicie el servidor Apache Kafka
Ahora que ha iniciado el servidor Apache Zookeeper, es el momento de iniciar el servidor Apache Kafka.
Abra una nueva ventana de terminal o de símbolo del sistema y navegue hasta el directorio donde se encuentran los archivos extraídos. A continuación, puede iniciar el servidor Apache Kafka utilizando el siguiente comando:
Para usuarios de Linux
bin/kafka-server-start.sh config/server.propertiesPara usuarios de Windows
bin/windows/kafka-server-start.bat config/server.propertiesYa tiene su servidor Apache Kafka en marcha. Si desea cambiar la configuración por defecto, puede hacerlo modificando el archivo server . properties. Los diferentes valores están presentes en la documentación oficial.
Cómo utilizar Apache Kafka en su máquina local
Ya está preparado para empezar a utilizar Apache Kafka en su máquina local para producir y consumir mensajes. Ya que los servidores Apache Zookeeper y Apache Kafka están en funcionamiento, veamos cómo puede crear su primer tema, producir su primer mensaje y consumir el mismo.
¿Cuáles son los pasos para crear un tema en Apache Kafka?
Antes de crear su primer tema, entendamos qué es realmente un tema. En Apache Kafka, un tema es un almacén lógico de datos que ayuda en el flujo de datos. Piense en él como el canal a través del cual los datos se transportan de un componente a otro.
Un tema admite múltiples productores y múltiples consumidores: más de un sistema puede escribir y leer de un tema. A diferencia de otros sistemas de mensajería, cualquier mensaje de un tema puede consumirse más de una vez. Además, también puede mencionar el periodo de retención de sus mensajes.
Tomemos el ejemplo de un sistema (productor) que produce datos para transacciones bancarias. Y otro sistema (consumidor) consume estos datos y envía una notificación de la aplicación al usuario. Para facilitar esto, se necesita un tema.
Abra una nueva ventana de terminal o de símbolo del sistema y navegue hasta el directorio en el que ha extraído el archivo. El siguiente comando creará un tema llamado transacciones:
Para usuarios de Linux
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092Para usuarios de Windows
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
Ya ha creado su primer tema y está listo para empezar a producir y consumir mensajes.
¿Cómo producir un mensaje en Apache Kafka?
Con su tema de Apache Kafka listo, ya puede producir su primer mensaje. Abra una nueva ventana de terminal o de símbolo del sistema, o utilice la misma que ha utilizado para crear el tema. A continuación, asegúrese de que se encuentra en el directorio adecuado en el que ha extraído el contenido del archivo. Puede utilizar la línea de comandos para producir su mensaje sobre el tema utilizando el siguiente comando:
Para usuarios de Linux
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092Para usuarios de Windows
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092Una vez que ejecute el comando, verá que su terminal o ventana de símbolo del sistema está esperando la entrada. Escriba su primer mensaje y pulse Intro.
> Este es un registro transaccional por 100
Ha producido su primer mensaje a Apache Kafka en su máquina local. Posteriormente, ya está listo para consumir este mensaje.
¿Cómo consumir un mensaje de Apache Kafka?
Siempre que su tema haya sido creado y haya producido un mensaje a su tema Kafka, ahora puede consumir ese mensaje.
Apache Kafka le permite adjuntar varios consumidores al mismo tema. Cada consumidor puede formar parte de un grupo de consumidores, un identificador lógico. Por ejemplo, si tiene dos servicios que necesitan consumir los mismos datos, entonces pueden tener diferentes grupos de consumidores.
Sin embargo, si tiene dos instancias del mismo servicio, entonces querrá evitar consumir y procesar el mismo mensaje dos veces. En ese caso, ambas tendrán el mismo grupo de consumidores.
En la ventana del terminal o del símbolo del sistema, asegúrese de que se encuentra en el directorio adecuado. Utilice el siguiente comando para iniciar el consumidor:
Para usuarios de Linux
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumerPara usuarios de Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer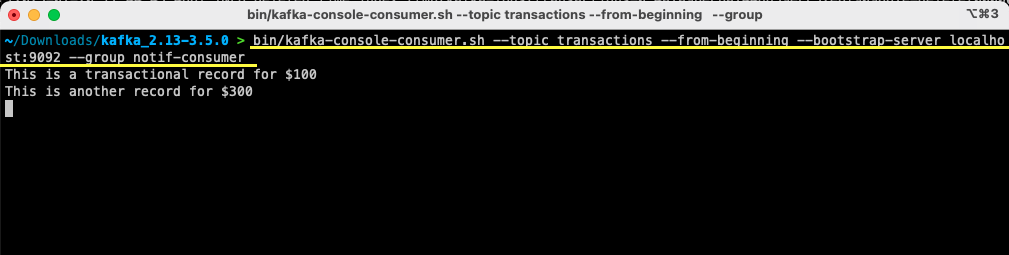
Verá aparecer en su terminal el mensaje que ha producido previamente. Ahora ha utilizado Apache Kafka para consumir su primer mensaje.
El comando kafka-console-consumer acepta que se le pasen muchos argumentos. Veamos qué significa cada uno de ellos:
- El
--topicmenciona el tema desde el que va a consumir - –
-from-beginningindica al consumidor de consola que empiece a leer los mensajes desde el primer mensaje presente - Su servidor Apache Kafka se menciona mediante la opción
--bootstrap-server - Además, puede mencionar el grupo de consumidores pasando el parámetro
--group - En ausencia de un parámetro de grupo de consumidores, éste se genera automáticamente
Con el consumidor de consola en funcionamiento, puede intentar producir nuevos mensajes. Verá que todos ellos se consumen y aparecen en su terminal.
Ahora que ha creado su tema y ha producido y consumido mensajes con éxito, vamos a integrarlo con una aplicación Java.
Cómo crear un productor y un consumidor de Apache Kafka utilizando Java
Antes de empezar, asegúrese de que tiene Java 8 instalado en su máquina local. Apache Kafka proporciona su propia biblioteca cliente que le permite conectarse sin problemas. Si utiliza Maven para gestionar sus dependencias, añada la siguiente dependencia a su pom.xml
<dependencia>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependencia>También puede descargar la biblioteca desde el repositorio de Maven y añadirla a su classpath de Java.
Una vez que su biblioteca está en su lugar, abra un editor de código de su elección. Veamos cómo puede poner en marcha su productor y consumidor utilizando Java.
Crear el productor Java de Apache Kafka
Con la biblioteca kafka-clients en su lugar, ya está listo para empezar a crear su productor Kafka.
Vamos a crear una clase llamada SimpleProducer.java. Esta se encargará de producir mensajesen el tema que ha creado anteriormente. Dentro de esta clase, creará una instancia de org.apache.kafka.clients.producer.KafkaProducer. Posteriormente, utilizará este productor para enviar sus mensajes.
Para crear el productor Kafka, necesitará el host y el puerto de su servidor Apache Kafka. Dado que lo está ejecutando en su máquina local, el host será localhost. Dado que no ha cambiado las propiedades por defecto al iniciar el servidor, el puerto será 9092. Considere el siguiente código que le ayudará a crear su productor:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String servidor = host ":" puerto;
Properties propiedades = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servidor);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}Observará que se están estableciendo tres propiedades. Recorramos rápidamente cada una de ellas:
- La BOOTSTRAP_SERVERS_CONFIG permite definir dónde se ejecuta el servidor Apache Kafka
- La KEY_SERIALIZER_CLASS_CONFIG indica al productor qué formato debe utilizar para enviar las claves de los mensajes.
- El formato para enviar el mensaje real se define utilizando la propiedad VALUE_SERIALIZER_CLASS_CONFIG.
Dado que va a enviar mensajes de texto, ambas propiedades están configuradas para utilizar StringSerializer.class.
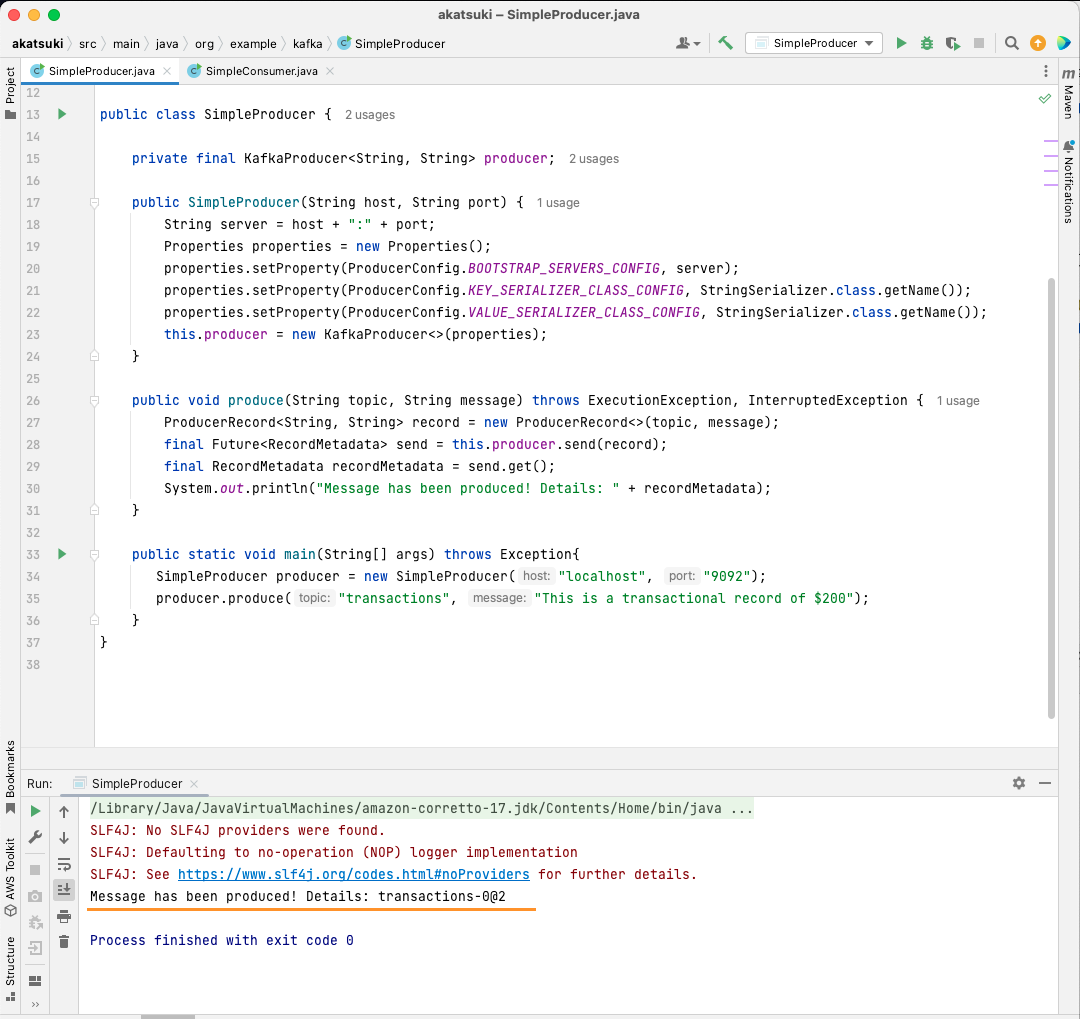
Para enviar realmente un mensaje a su tema, necesita utilizar el método producer.send( ) que recibe un ProducerRecord. El siguiente código le proporciona un método que enviará un mensaje al tema e imprimirá la respuesta junto con el desplazamiento del mensaje.
public void produce(String tema, String mensaje) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(tema, mensaje);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}Con todo el código en su sitio, ya puede enviar mensajes a su tema. Puede utilizar un método main para probarlo, como se presenta en el código siguiente:
paquete org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String servidor = host ":" puerto;
Properties propiedades = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servidor);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String tema, String mensaje) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(tema, mensaje);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transacciones", "Este es un registro transaccional de 200 $");
}
}
En este código, está creando un SimpleProducer que se conecta a su servidor Apache Kafka en su máquina local. Internamente utiliza el KafkaProducer para producir mensajes de texto sobre su tema.
Crear el consumidor Java de Apache Kafka
Es hora de crear un consumidor de Apache Kafka utilizando el cliente Java. Cree una clase llamada SimpleConsumer.java. A continuación, creará un constructor para esta clase, que inicializará el org.apache.kafka.clients.consumer.KafkaConsumer. Para crear el consumidor, necesitará el host y el puerto donde se ejecuta el servidor Apache Kafka. Además, necesita el grupo de consumidores y el tema desde el que desea realizar el consumo. Utilice el fragmento de código que se indica a continuación:
paquete org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class ConsumidorSimple {
private static final String OFFSET_RESET = "más temprano";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String servidor = host ":" puerto;
Properties propiedades = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servidor);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(tema));
}
}De forma similar al productor Kafka, el consumidor Kafka también recibe un objeto Properties. Echemos un vistazo a las diferentes propiedades establecidas:
- BOOTSTRAP_SERVERS_CONFIG indica al consumidor dónde se está ejecutando el servidor Apache Kafka
- El grupo de consumidores se menciona mediante GROUP_ID_CONFIG
- Cuando el consumidor comienza a consumir, el AUTO_OFFSET_RESET_CONFIG le permite mencionar desde cuándo quiere empezar a consumir mensajes
- KEY_DESERIALIZER_CLASS_CONFIG indica al consumidor el tipo de clave del mensaje
- VALUE_DESERIALIZER_CLASS_CONFIG indica al consumidor el tipo del mensaje real
Dado que, en su caso, estará consumiendo mensajes de texto, las propiedades del deserializador se establecen en StringDeserializer.class.
Ahora consumirá los mensajes de su tema. Para mantener las cosas simples, una vez que el mensaje es consumido, usted estará imprimiendo el mensaje en la consola. Veamos cómo puede lograr esto utilizando el siguiente código:
private boolean mantenerConsumiendo = true;
public void consumir() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}Este código seguirá sondeando el tema. Cuando reciba algún registro de consumidor, se imprimirá el mensaje. Pruebe su consumidor en acción utilizando un método main. Iniciará una aplicación Java que seguirá consumiendo el tema e imprimiendo los mensajes. Detenga la aplicación Java para terminar el consumidor.
paquete org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class ConsumidorSimple {
private static final String OFFSET_RESET = "más temprano";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String servidor = host ":" puerto;
Properties propiedades = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servidor);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(tema));
}
public void consumir() {
while (seguirConsumiendo) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transacciones-consumidor", "transacciones");
simpleConsumer.consume();
}
}
Cuando ejecute el código, observará que no sólo consume los mensajes producidos por su productor Java, sino también los que ha producido a través del productor de consola. Esto se debe a que la propiedad AUTO_OFFSET_RESET_CONFIG se ha establecido en earliest.
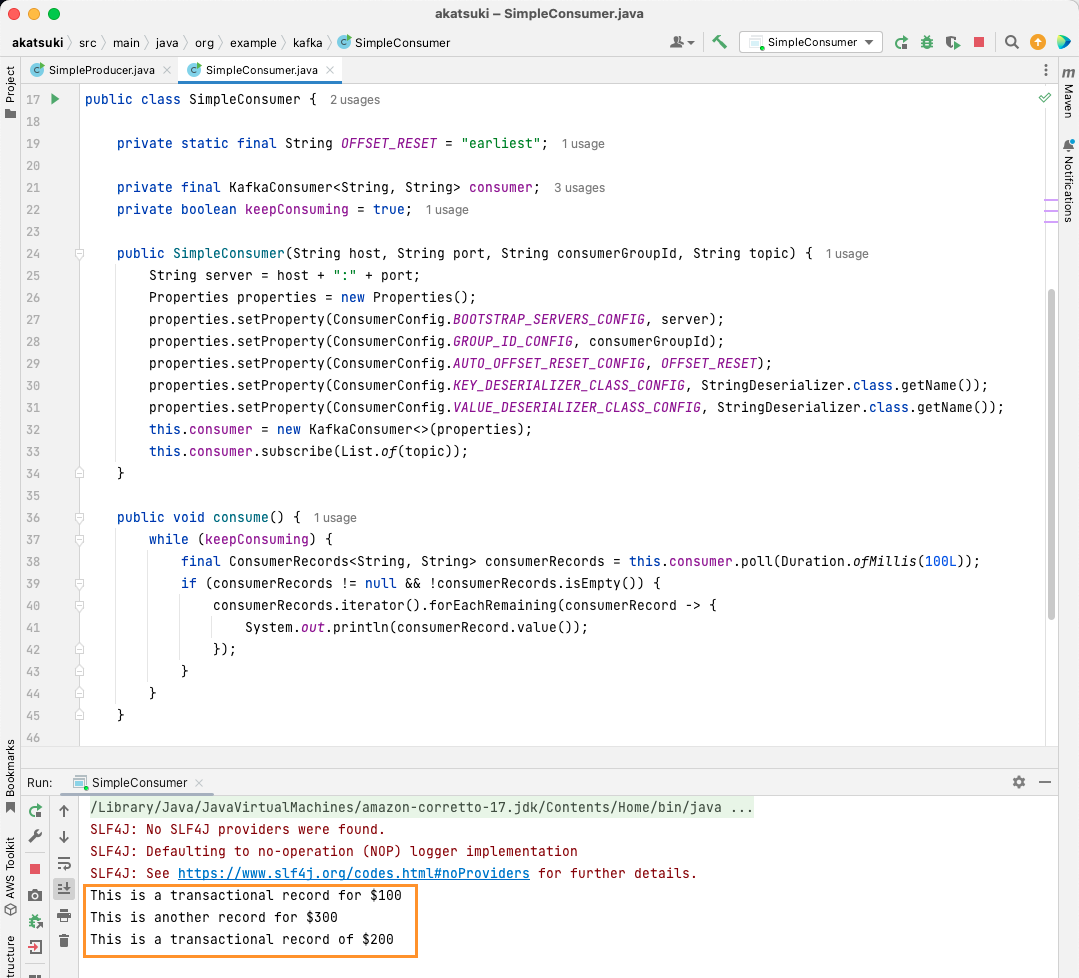
Con el SimpleConsumer en marcha, puede utilizar el productor de consola o la aplicación Java SimpleProducer para producir más mensajes al tema. Verá cómo se consumen y se imprimen en la consola.
Satisfaga todas sus necesidades de canalización de datos con Apache Kafka
Apache Kafka le permite manejar todas sus necesidades de canalización de datos con facilidad. Con la configuración de Apache Kafka en su máquina local, puede explorar todas las diferentes características que ofrece Kafka. Además, el cliente Java oficial le permite escribir, conectarse y comunicarse con su servidor Apache Kafka de forma eficiente.
Al ser un sistema de flujo de datos versátil, escalable y de alto rendimiento, Apache Kafka puede suponer un auténtico cambio de juego para usted. Puede utilizarlo para su desarrollo local o incluso integrarlo en sus sistemas de producción. Al igual que es fácil de configurar localmente, configurar Apache Kafka para aplicaciones más grandes no es una gran tarea.
Si busca plataformas de streaming de datos, puede consultar las mejores plataformas de streaming de datos para análisis y procesamiento en tiempo real.