Si hay algo que las empresas no pueden permitirse en el panorama competitivo actual, es un rendimiento del sistema por debajo del nivel óptimo.
Peor aún es el caso de que uno o más subsistemas fallen y el equipo técnico no sea consciente de ello. En industrias críticas como la banca, el comercio de acciones, etc., el tiempo de inactividad puede costar millones de dólares (o más) cada minuto, mientras que en otras, puede haber una reacción fatal de los clientes. Casi se ha llegado a un punto en el que conocer un error antes que su cliente ya no es sólo inteligente; es obligatorio.
APIs, APIs, en todas partes
Es un mundo dominado por las API, y es probable que oiga y utilice el término varias veces al día. Si usted es un proveedor de servicios de cualquier tipo, tiene APIs en las que otros confían, y hay APIs que usted consume para mantener el negocio en marcha (Google Maps API, SERP APIs, etc.). Pero esto es sólo la punta del iceberg. Para los que pertenecen al mundo de la programación informática, una interfaz de programación de aplicaciones (API) es un término amplio que abarca mucho más que los mapas y las compras.
Sin que se dé cuenta, todo en un sistema de software (sí, literalmente todo) es una API o expone una API.
Antes de pasar a la supervisión de las API, dediquemos un momento a entender qué es una API y qué extensión de nuestro sistema de software abarca. Eso le ayudará a reducir las opciones y a decidir mejor qué API desea cubrir y, por lo tanto, qué herramientas serán mejores para su caso de uso único.
¿Qué es una API?
Empecemos con la definición estándar de libro de texto antes de profundizar utilizando el vocabulario empresarial cotidiano. Si preguntamos a Wikipedia sobre las API, nos dice lo siguiente:
En programación informática, una interfaz de programación de aplicaciones (API) es un conjunto de definiciones de subrutinas, protocolos de comunicación y herramientas para crear software. En términos generales, es un conjunto de métodos de comunicación claramente definidos entre varios componentes. Una buena API facilita el desarrollo de un programa informático al proporcionar todos los componentes básicos, que luego son ensamblados por el programador.
Una API puede ser para un sistema basado en web, un sistema operativo, un sistema de base de datos, hardware informático o una biblioteca de software.
La segunda línea es esencial (el subrayado es mío). No sólo los servicios web cuentan como API. Las llamadas al sistema operativo, las interacciones con el sistema de base de datos, las señales de hardware, las bibliotecas de software (código que otro código puede reutilizar) entran todas en el ámbito de una API, ya que todas ellas presentan una interfaz y un conjunto de protocolos bien definidos y comprendidos.
Ahora bien, un día cualquiera, cualquiera de estas API puede dejar de funcionar. Puede que el disco duro haya alcanzado su límite de operaciones de entrada/salida por segundo, o que el certificado SSL haya caducado, o que haya un error no detectado en la última versión del código que se está utilizando: todas estas situaciones justifican una supervisión constante y una actuación inmediata cuando se produzca el problema (preferiblemente antes).
Apropiadamente, este artículo sugerirá herramientas que pueden supervisar su aplicación en todas las áreas, no sólo el intercambio de datos entre dos sistemas.
El coste del tiempo de inactividad de la API
Es difícil cuantificar cuánto duele el tiempo de inactividad, pero Gartner publicó un estudio que cifraba la cifra en 300.000 dólares por hora. Se trata de una media modesta, por supuesto. Considere la pérdida de negocio causada por una hora de tiempo de inactividad durante, digamos, la temporada de descuentos del Viernes Negro. Para conocer más historias de terror sobre cómo el mal funcionamiento o la falta de funcionamiento de las API acabaron con el negocio o con el espíritu de los empleados, consulte aquí y aquí.

Aunque no se puede subestimar el lado empresarial del tiempo de inactividad de las API, también hay una pérdida oculta que podría ser incluso mayor a largo plazo: la moral del equipo. A los desarrolladores les encanta la automatización y la fiabilidad de los sistemas (en realidad, a todos nos gusta; ¡imagínese su servidor de correo cayendo varias veces al día!), y los tiempos de inactividad rompen su código y les frustran. Si persisten, los problemas pronto empezarán a afectar a otras funciones empresariales (ventas y marketing) que se cansarán de perder continuamente la cara ante el cliente.
He visto de cerca a dos empresas casi morir por culpa de unos sistemas de monitorización internos deficientes, y no tengo corazón para volver a verlo. 😐
Ahora bien, los tiempos de inactividad no pueden eliminarse; en el mundo real, cualquier cosa puede ir mal en cualquier momento. Pero si disponemos de sistemas de supervisión adecuados, podemos conocer los errores en el momento en que se producen, ¡a veces incluso antes que el cliente!
Con esto en mente, veamos algunas de las mejores herramientas de monitorización de API del mercado.
Uptrends
Uptrends, una solución completa para todo tipo de monitorización de API (¿recuerda nuestra amplia definición de API de antes?), ofrece monitorización para sitios web, API, servidores y mucho más. Presume de una base de 25.000 clientes satisfechos, con nombres como Vimeo, Microsoft, Volkswagen y más, entre sus clientes.
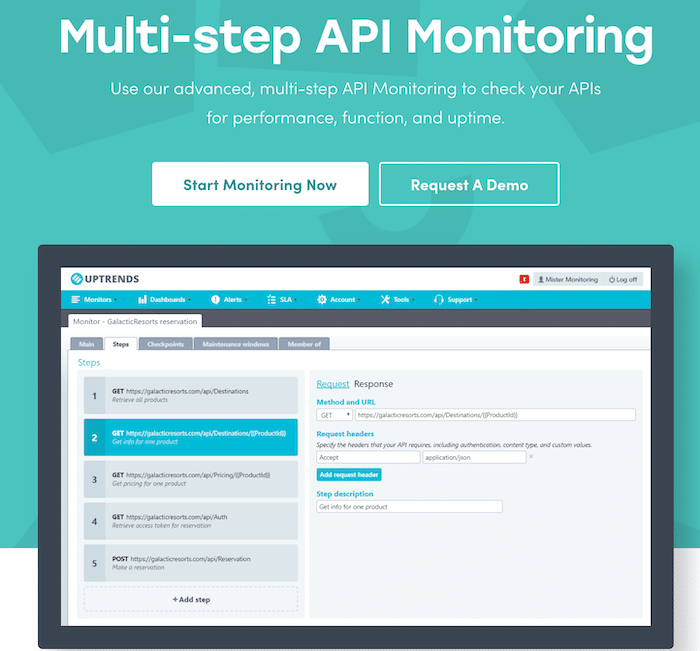
Una característica única de Uptrends es la prueba basada en navegador. El servicio pone en marcha diferentes navegadores reales para ejecutar su aplicación/página web y proporciona una métrica detallada sobre su rendimiento.
Pero los tiempos de respuesta y las métricas son sólo la mitad de la historia. Uptrends también le proporciona un informe de rendimiento detallado por activos, para que sepa exactamente qué está causando un cuello de botella y dónde. Cuando se produce un error, el servicio hace una captura de pantalla y se la envía, para que pueda ver exactamente cómo se siente en el otro extremo de la ecuación. 🙂
En definitiva, Uptrends es un servicio fiable y encantador en el que confían muchos grandes nombres.
Dotcom-Monitor
La plataforma Dotcom-Monitor le permite configurar un dispositivo de monitorización multitarea mediante una tarea HTTP/S. Con ello, puede supervisar las API web basadas en OAuth 2.0 para comprobar su disponibilidad, rendimiento y respuestas adecuadas. Al replicar una o varias solicitudes de clientes finales y supervisar un servicio web SOAP, los agentes de Dotcom-Monitor verifican que los datos pueden intercambiarse correctamente entre la API y una aplicación web.
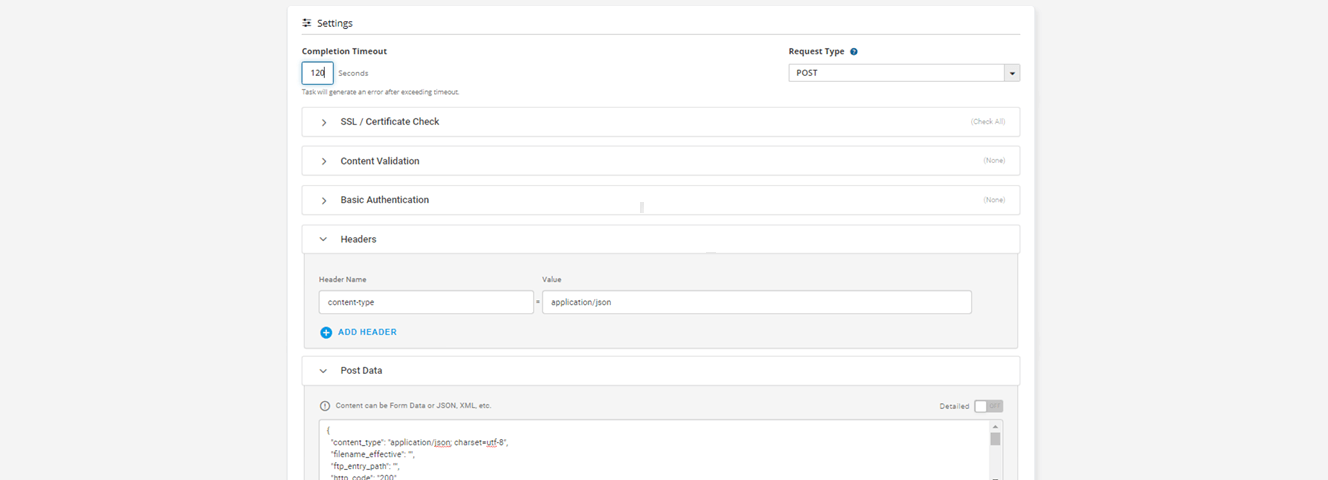
Cuando un agente detecta un error, lo coteja con el filtro del dispositivo. Si el error no se filtra, el dispositivo dispara una alerta. Puede configurar varios grupos de alerta y establecer horarios de alerta personalizados y opciones de escalado. Los informes están disponibles en formatos CSV, PDF y TXT. Muestran múltiples y útiles métricas, como los tiempos de respuesta, el tiempo de inactividad y el rendimiento medio por ubicación.
Los planes de precios de Dotcom-Monitor empiezan en 1,99 $ al mes y ofrecen supervisión de servicios web con soporte para HTTP/S, Web API SOAP/REST, comprobación de certificación SSL, validación de respuestas, alertas instantáneas y 30 ubicaciones de supervisión, entre otras características.
Checkly
Checkly afirma ser una solución de monitorización y comprobación de última generación que ha llamado mucho la atención, especialmente en la comunidad JavaScript con clientes como Vercel y Humio. Puede supervisar las API web, así como las transacciones del sitio, los flujos en un navegador real. El panel de control único le muestra todo lo que necesita saber sobre la corrección y el rendimiento de su aplicación en cualquier momento.
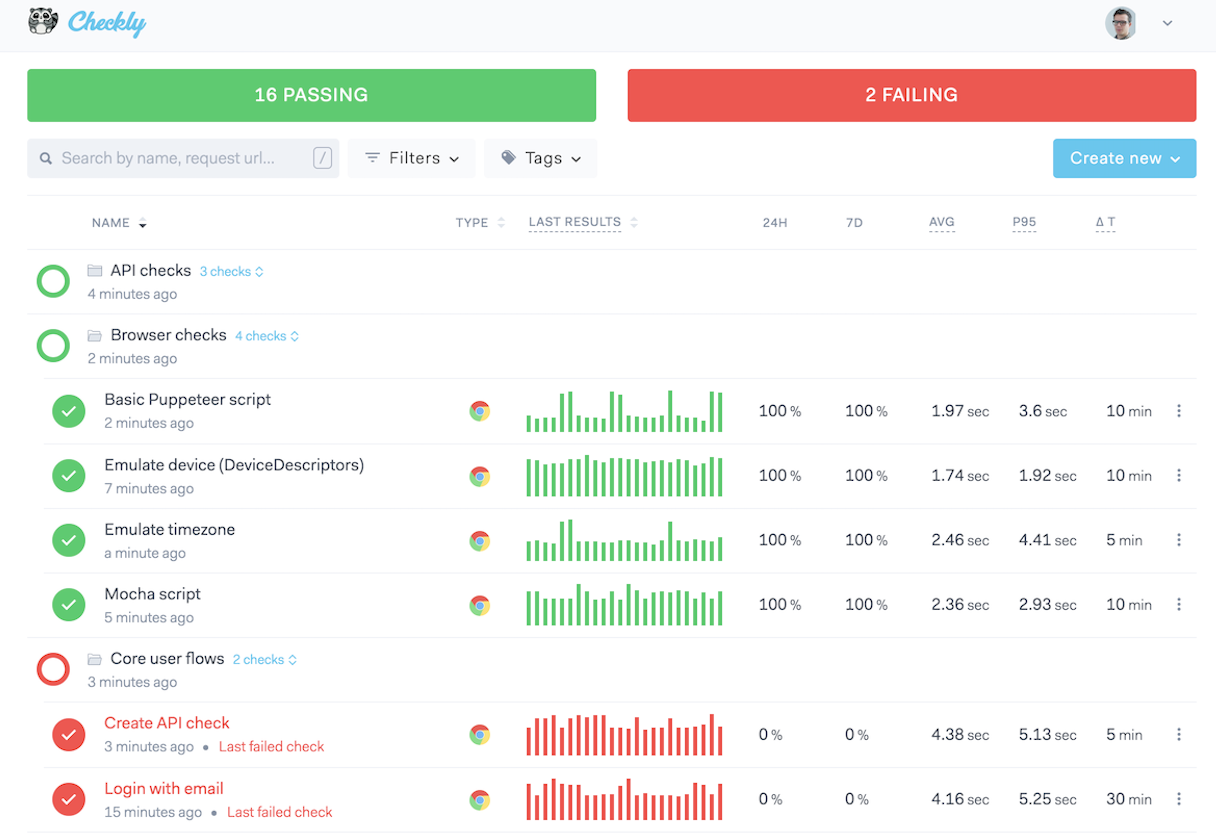
Me gusta mucho cómo Checkly combina una configuración sin esfuerzo y facilidad de uso con potentes herramientas para personalizar sus comprobaciones. En lugar de un simple ping, utiliza comprobaciones HTTP configurables completas para supervisar las API. Esto también incluye scripts de configuración/retiro, lo que resulta muy útil cuando, por ejemplo, desea firmar solicitudes o limpiar datos de prueba.
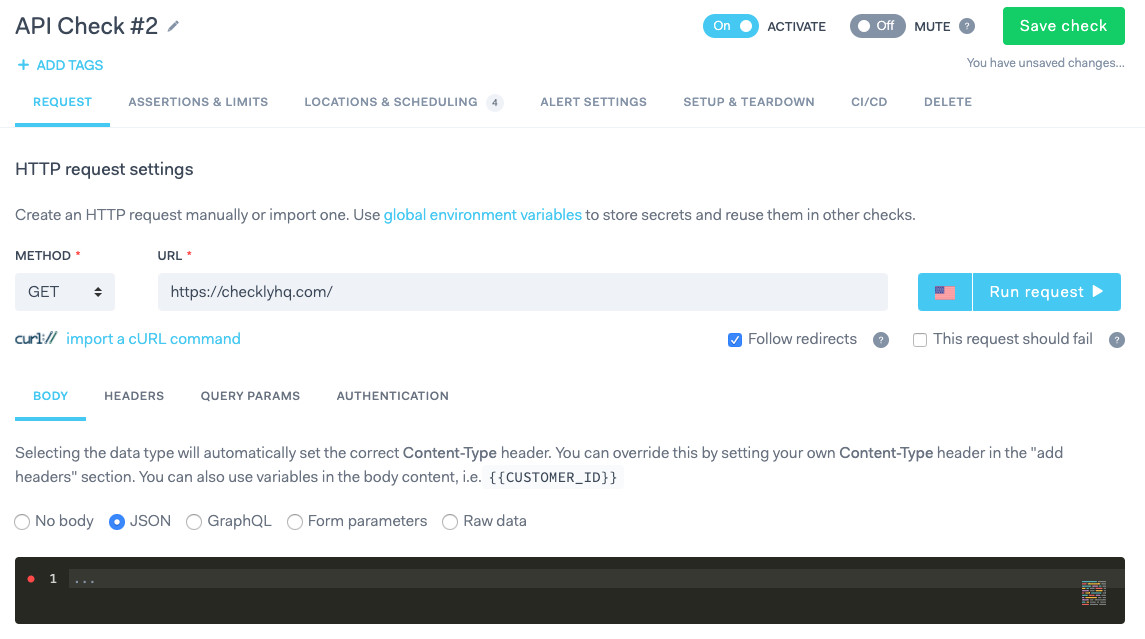
Otra cosa que destaca es la potente API REST que le permite orquestar y automatizar sus comprobaciones, por ejemplo, con Terraform. También permite a los usuarios configurar alertas de grano fino en combinación con Opsgenie, Pagerduty o Slack. En conjunto, una gran solución que veo muy interesante para los equipos DevOps modernos.
Checkly ofrece un plan gratuito para desarrolladores que incluye un intervalo de comprobación de 1 minuto y ubicaciones de centros de datos globales.
Better Uptime
BetterUptime es un moderno servicio de monitorización que combina API, ping y monitorización del tiempo de actividad, gestión de incidencias y páginas de estado en un único producto de bonito diseño.
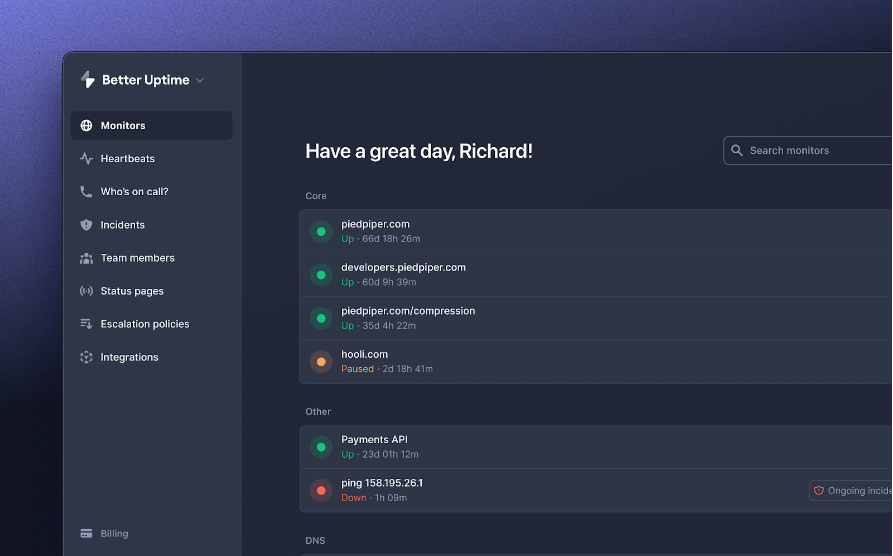
La configuración tarda 3 minutos. Después, recibirá una llamada, un correo electrónico o una alerta de Slack cada vez que su punto final de API no funcione correctamente. Las características principales son:
- API, Ping, HTTP(s), SSL y caducidad de TLD, comprobaciones de Cron jobs
- Alertas de llamada ilimitadas
- Fácil programación de llamadas
- Capturas de pantalla y registros de errores de incidencias
- Slack, Teams, Heroku, AWS y 100 integraciones más
Sematext
Sematext es ya bastante conocido entre los equipos DevOps gracias a su conjunto de herramientas de monitorización diseñadas para garantizar la visibilidad de extremo a extremo de aplicaciones y sitios web. La monitorización de API forma parte de su servicio de monitorización sintética, Sematext Synthetics.
Sematext ofrece un sistema avanzado de notificación de supervisión de API que puede personalizar para que funcione en varias condiciones diferentes basadas en errores y métricas. De este modo, puede configurar la herramienta para que realice una doble o triple comprobación antes de enviar una alerta. Básicamente, eliminará los falsos positivos en el proceso y obtendrá alertas más precisas y evitará la fatiga por alertas.
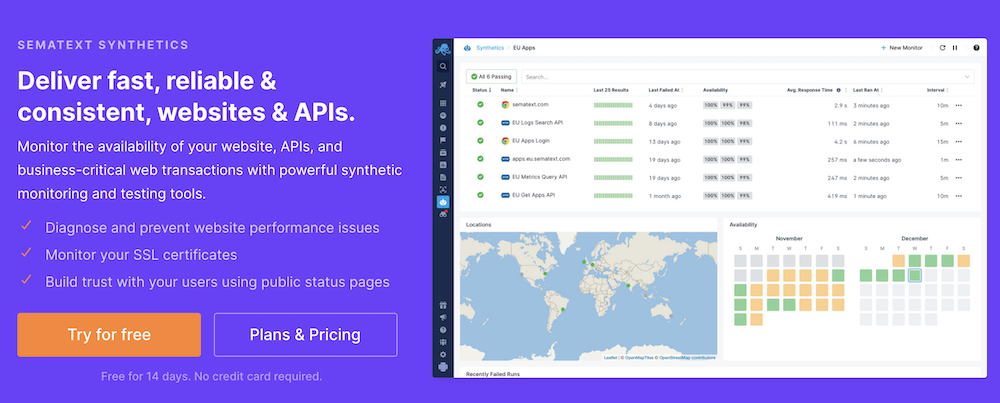
Además, aparte del sencillo pero potente monitor HTTP que cabe esperar en una buena herramienta sintética de supervisión y comprobación, Sematext destaca por su completo monitor de navegador, que le permite recopilar métricas de rendimiento web y comprobar continuamente los recorridos críticos de los usuarios en su sitio basándose en las interacciones de los usuarios con el sitio web mediante secuencias de comandos.
Esto significa que puede realizar pruebas más allá de los tiempos de carga de la página, profundizar y observar detalladamente las interacciones simuladas del usuario con el sitio web, como el inicio de sesión y el registro, añadir a la cesta y ejecutar consultas de búsqueda en el sitio. Una serie de interacciones de usuario comunes se proporcionan fuera de la caja.
Amazon CloudWatch
Si tiene infraestructura en AWS, CloudWatch no puede recomendarse lo suficiente. Además de la monitorización de aplicaciones, CloudWatch también dispone de monitorización de infraestructuras, lo que ayudará a su equipo de DevOps a dormir tranquilo por la noche.
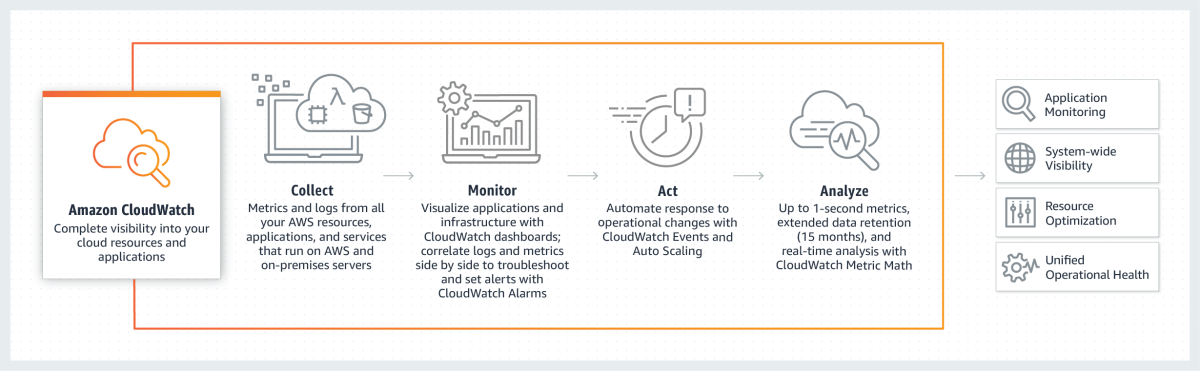
Según la descripción oficial, CloudWatch ofrece:
- Monitorización de aplicaciones
- Visibilidad de todo el sistema
- Optimización de recursos
- Salud operativa unificada
Por lo tanto, siempre que tenga una implementación exclusiva de AWS, CloudWatch podrá monitorizar el tiempo de actividad de su aplicación, el rendimiento, el uso de recursos, el ancho de banda de la red, el uso de disco/CPU, etc., proporcionando una solución sólida para todo tipo de monitorización.
Quizá la ventaja más significativa con CloudWatch es que prácticamente no necesita configurar nada. Los servicios de AWS generan los registros pertinentes y los comparten directamente con CloudWatch, que termina en un panel de control ordenado y fácil de entender.
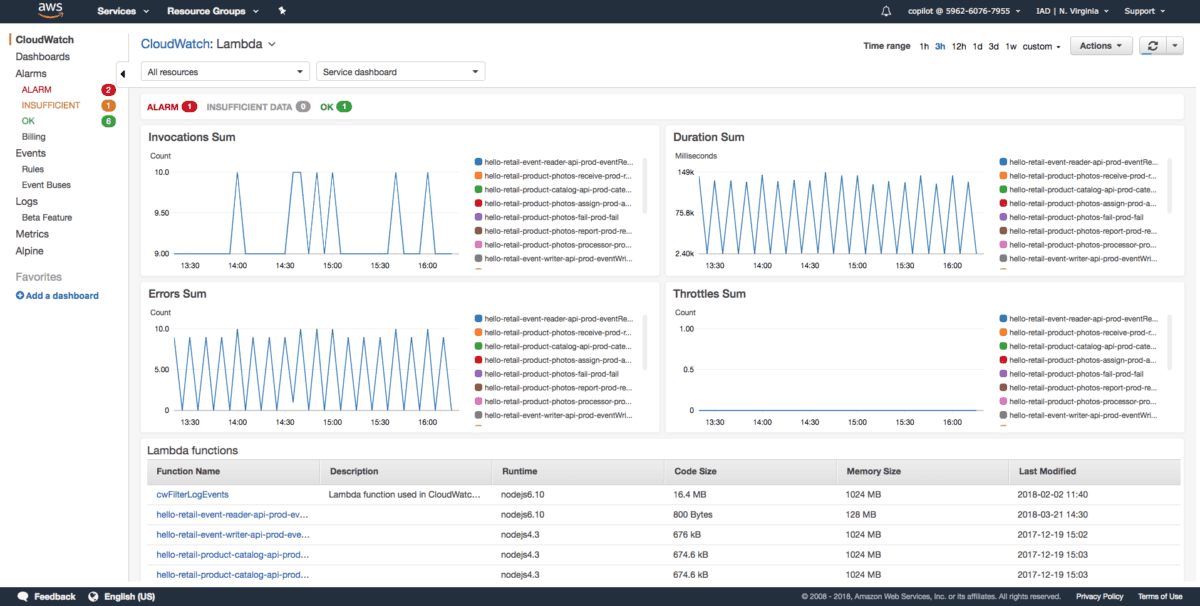
Desde el salpicadero, no sólo puede leer las métricas (mientras que los planes gratuitos ofrecen una precisión de hasta un minuto, los planes de pago pueden acercarle a una precisión de un segundo, lo que le permite monitorizar en tiempo real), sino también crear reglas personalizadas, configurar alarmas y cuándo deben dispararse, escanear los registros del sistema con tantos detalles como desee y mucho más.
Claro, no todo el mundo está en AWS, pero la mayoría de las empresas digitales críticas y famosas sí lo están, por eso pensé que CloudWatch debía introducirse en esta lista. Puede que empiece a sonar como un cuerno roto en este punto, pero sinceramente, si está en AWS, no hay forma más fácil de configurar la monitorización que CloudWatch.
Si desea obtener más información sobre AWS CloudWatch, aprenda del experto aquí.
En cuanto a los precios, Amazon también los ha mantenido sencillos. No hay ningún bloqueo mensual o anual. Usted decide cuánto necesita y paga sólo en función de lo que utiliza.
Pero, sobre todo, eche un vistazo a la oferta gratuita y dígame que no es posible decantarse por este servicio 🙂

Rigor
Si vive en función de las métricas de rendimiento y pone la experiencia del cliente por encima de todo, merece la pena echar un vistazo a Rigor. El nombre está bien elegido, ya que puede ser tan riguroso con la herramienta como desee. 🙂
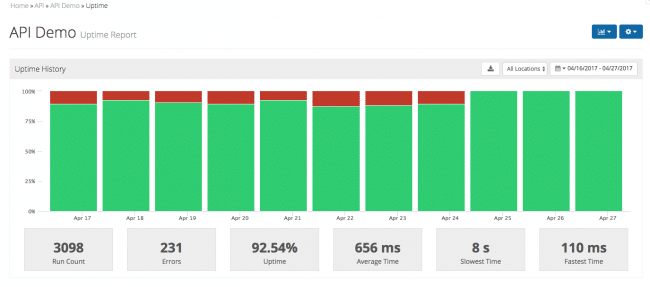
Una de las características más útiles de Rigor son las pruebas funcionales. Si no está metido en la jerga de las pruebas, no se preocupe; las pruebas funcionales se refieren al acto de probar todo el flujo de una transacción, y no sólo centrarse en un único punto final.
En cierto modo, las pruebas funcionales son más importantes que las pruebas unitarias porque cubren implícitamente estas últimas y proporcionan directamente una predicción de la experiencia del cliente.
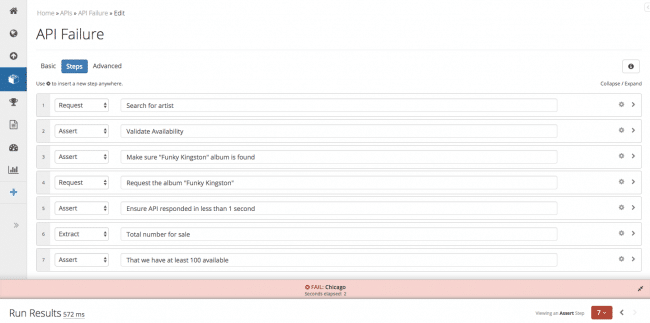
Como puede ver en la imagen superior, esta prueba funcional tiene una serie de siete reglas que constituyen una transacción.
La regla n.º 1 es una solicitud de búsqueda de un artista concreto en la API; a continuación, la regla n.º 2 es una aserción, lo que significa que queremos hacer cumplir que el artista que buscamos está disponible; si se superan estas dos pruebas, el sistema pasa a la regla n.º 3, y así sucesivamente.
En el ejemplo anterior, la prueba funcional se rompe en la Regla nº 7, y se notifica inmediatamente a las partes interesadas que no hay suficientes copias del álbum «Funky Kingston» ¡Hablando de centrarse en el negocio en lugar de preocuparse por las piezas tecnológicas!
Rigor es un servicio severo para empresas serias a las que no les importa pagar una prima por algo asombroso, así que si usted es una de ellas, no dude en echarle un vistazo.
Assertible
Assertible se autodenomina la herramienta de supervisión de API más sencilla y está orientada principalmente a los equipos de pruebas y control de calidad. Así que si cree que no tiene la competencia técnica interna para lidiar con JSON, XML y escribir código, merece la pena echar un vistazo a Assertible.
La USP de Assertible es atractiva y directa: Sus equipos de control de calidad y de pruebas pueden crear pruebas y verificarlas/supervisarlas utilizando la interfaz de Assertible. Se integra perfectamente con GitHub, por lo que su base de conocimientos permanece con usted, además de funcionar a la perfección con Slack.
La integración completa y la funcionalidad de revisión permiten que prácticamente cualquier persona de su equipo (incluso los jefes de proyecto) pueda crear pruebas y revisar las métricas de rendimiento.
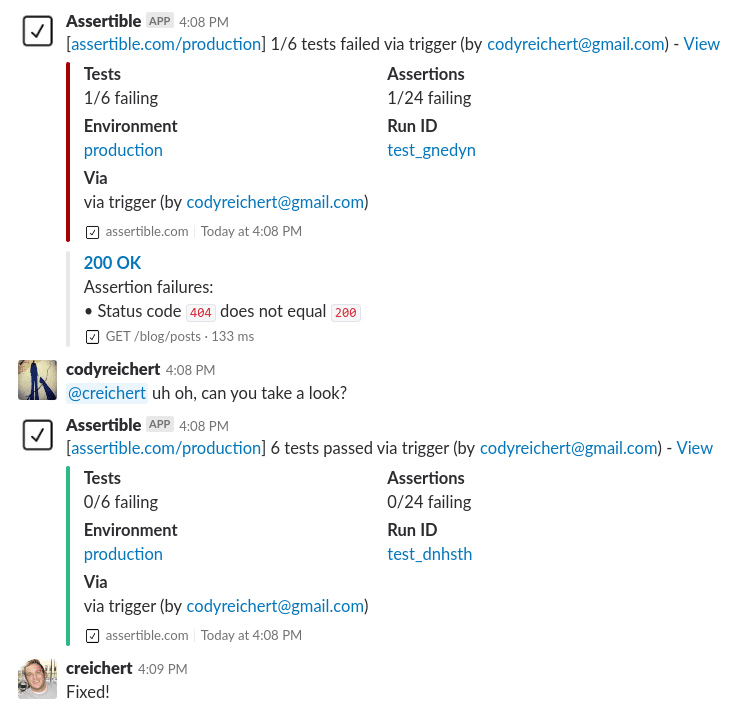
De acuerdo, la situación de la captura de pantalla anterior puede parecer un poco irreal (resolución de problemas en un minuto), pero es posible cuando la retroalimentación es clara e inmediata. La ausencia total de codificación necesaria significa que las pruebas pueden crearse tan rápido como sus equipos de control de calidad puedan teclear y, una vez hechas, pueden aplicarse una y otra vez. Esto contrasta fuertemente con la práctica de las «pruebas manuales» que se sigue en la mayoría de las empresas, en las que un solo probador puede tardar varios días en cubrir la aplicación y, sin embargo, perderse detalles más excelentes simplemente por descuido o esfuerzo.
Por tan sólo 100 dólares al mes (que es su plan superior, por cierto), Assertible le permite supervisar hasta 50 servicios web, un total de 50.000 pruebas y 20 miembros de equipo. Considere el coste de tener a un QA trabajando a tiempo completo para crear y ejecutar manualmente las pruebas, y es obvio que Assertible ofrece una eficiencia exponencial.
BlazeMeter
Cuando se trata de pruebas de extremo a extremo y supervisión de aplicaciones, BlazeMeter es el gigante que se come todo lo demás para almorzar. Al mismo tiempo, sin embargo, no es para los débiles de corazón o para aquellos que buscan una solución sencilla de monitorización de API que no exija mucho.
BlazeMeter es algo con lo que uno se casa, y luego sigue dando sus frutos a lo largo de la vida útil de la aplicación.
El mayor punto a favor de BlazeMeter es la integración con Apache JMeter, posiblemente la herramienta de medición del rendimiento por defecto para grandes aplicaciones web. Sí, con BlazeMeter, tiene libertad para elegir marcos de pruebas de código abierto y analizarlos fácilmente a través de sencillos paneles.
Los planes son caros, y si su aplicación puede ver hasta 5.000 usuarios concurrentes, le costará 649 dólares al mes utilizar BlazeMeter. Existen planes de costes fijos para cargas de trabajo aún mayores, que es lo normal dado el tipo de clientes que tiene BlazeMeter: Pfizer, Adobe, GAP, NFL, Atlassian, por nombrar algunos.
No es que BlazeMeter no pueda utilizarse de formas más sencillas. Como la mayoría de las herramientas de supervisión de API, proporciona pruebas funcionales (ellos las llaman «escenarios»), que pueden realizarse mediante una interfaz gráfica de usuario intuitiva.
Dicho esto, BlazeMeter está pensado para desarrolladores. A través de su herramienta de pruebas dedicada Taurus, BlazeMeter expone un DSL (lenguaje específico de dominio) que puede utilizarse para escribir pruebas genéricas que pueden ejecutarse con JMeter, Selenium y otras herramientas populares de código abierto. Y no deje que la mención de un DSL le preocupe; no es más que un archivo YAML glorificado (extensión .yml):
ejecución:
- concurrencia: 100
aceleración 1m
espera 1m30s
escenario: simple
escenarios:
simple:
think-time: 0.75
solicitudes:
- http://blazedemo.com/
Pase algún tiempo con Taurus, ¡y sus desarrolladores le agradecerán poder escribir pruebas intrincadas y reutilizables!
En definitiva, BlazeMeter es un peso pesado para los pesos pesados.
AppDynamics
Ahora parte de Cisco, AppDynamics ha estado en el juego de la monitorización de aplicaciones web durante mucho tiempo y es bastante conocida. En la actualidad, AppDynamics es un conjunto de herramientas para resolver una amplia gama de requisitos de rendimiento y supervisión de un equipo moderno de SaaS.
En cuanto a la monitorización pura de API/microservicios, la suite ofrece Microservice IQ. Con este servicio, puede supervisar y analizar un clúster de microservicios de prácticamente cualquier escala, conservando el historial y permitiéndole correlacionarlo con los cambios en el clúster. En cualquier caso, esto le permite al menos simular el impacto de añadir/eliminar nodos del clúster.
Lo mismo ocurre con la supervisión de las métricas en tiempo real, que puede hacerse a nivel de clúster o de nodo, presentándole tanto la visión de conjunto como el detalle extremo, según sea necesario.
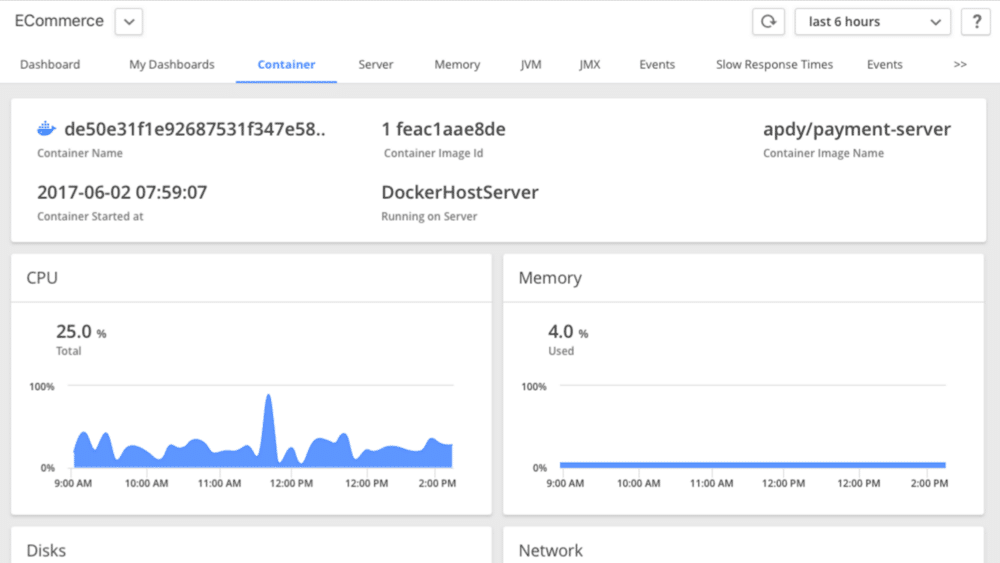
Como puede ver en la captura de pantalla, la monitorización de Docker está incorporada, lo que agradecerán los equipos con su infraestructura ejecutándose en Docker (casi todos, es decir 🙂 ).
Además de esto, también están disponibles la monitorización de la nube y la monitorización de DevOps, que funcionan a través de varios proveedores de IaaS como Amazon AWS, Azure, Pivotal, etc. La retroalimentación continua está disponible a través de toda su tubería de entrega, proporcionando confianza y una base sólida para su equipo de DevOps.
La guinda del pastel es la integración del aprendizaje automático en el corazón mismo del sistema. Por ejemplo, a veces no conoce la línea de base ideal para su aplicación, pero como el negocio funciona sin problemas, puede aceptar las métricas actuales como línea de base.
Entonces, ¿cómo calcular la línea de base? Es difícil cuando se tienen miles de puntos de datos fluyendo cada hora, pero no si hay un sistema de aprendizaje automático capaz funcionando.
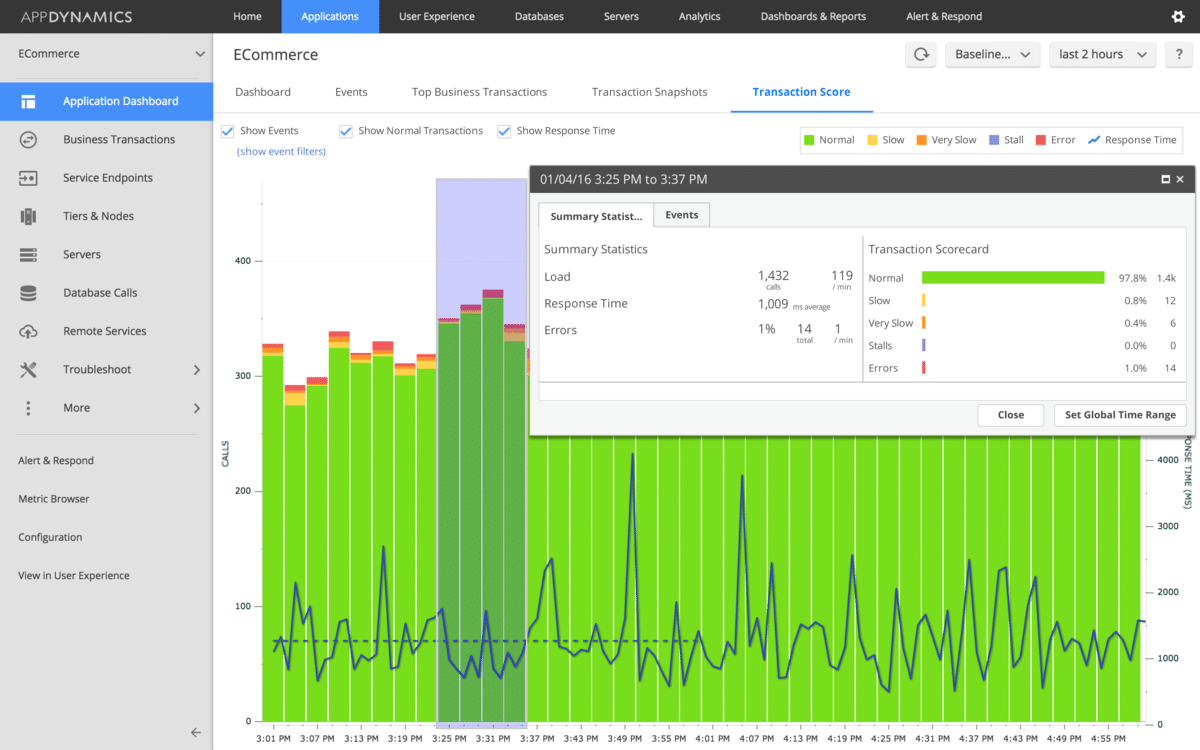
¿Cómo ayuda esto a las empresas? He aquí un ejemplo. Si sabe que su línea de base para el tiempo de actividad es del 98,5%, y actualmente está funcionando al 98,6%, puede estar realmente tranquilo. Además, tener acceso a líneas de base reales y sólidas le ahorra la sobreingeniería y las costosas migraciones que algunos consultores podrían recomendar para impulsar la consecución de «seis nueves» (99,9999% de tiempo de actividad).
El sistema ML también es lo suficientemente inteligente como para averiguar e informar de la única causa de fallo entre un clúster de microservicios desde dentro del código (¡esa es la parte más impresionante!), de modo que sus equipos sepan exactamente qué deben arreglar. La captura de pantalla siguiente muestra cómo el sistema puede profundizar en un servicio REST basado en Java Spring y señalar el Bean que falló.
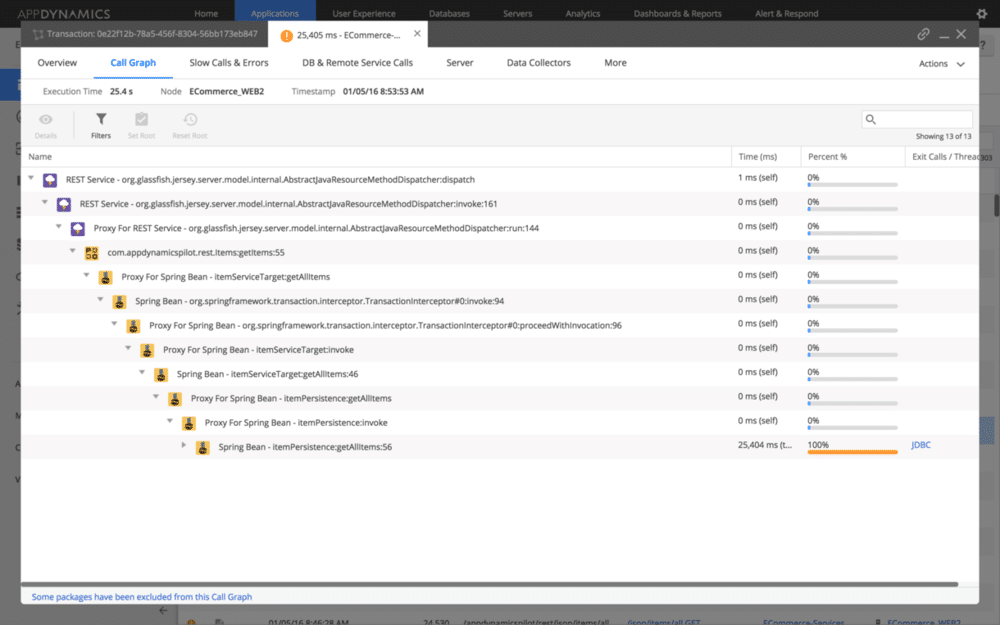
No es posible cubrir todas las asombrosas características aquí, así que no dude en consultar la documentación oficial.
New Relic
Según muchos, New Relic es el líder del mercado en herramientas de supervisión del rendimiento de las aplicaciones, y por una buena razón. Lo utilizan grandes y pequeñas empresas por igual -desde behemoths de Fortune 500 hasta pequeñas y ágiles startups- y ofrece una gran combinación de precisión y detalle.
El equipo de New Relic se enorgullece de su profundo conocimiento de DevOps y, en consecuencia, esta oferta está construida para proporcionar una visión completa y en tiempo real de su infraestructura.
La mayor USP de New Relic es el diseño intuitivo de todo el sistema, que le permite ver al instante cómo está fluyendo todo y dónde se encuentra exactamente el cuello de botella, si lo hay. Es difícil describir la interfaz de usuario con palabras, así que aquí tiene una captura de pantalla:
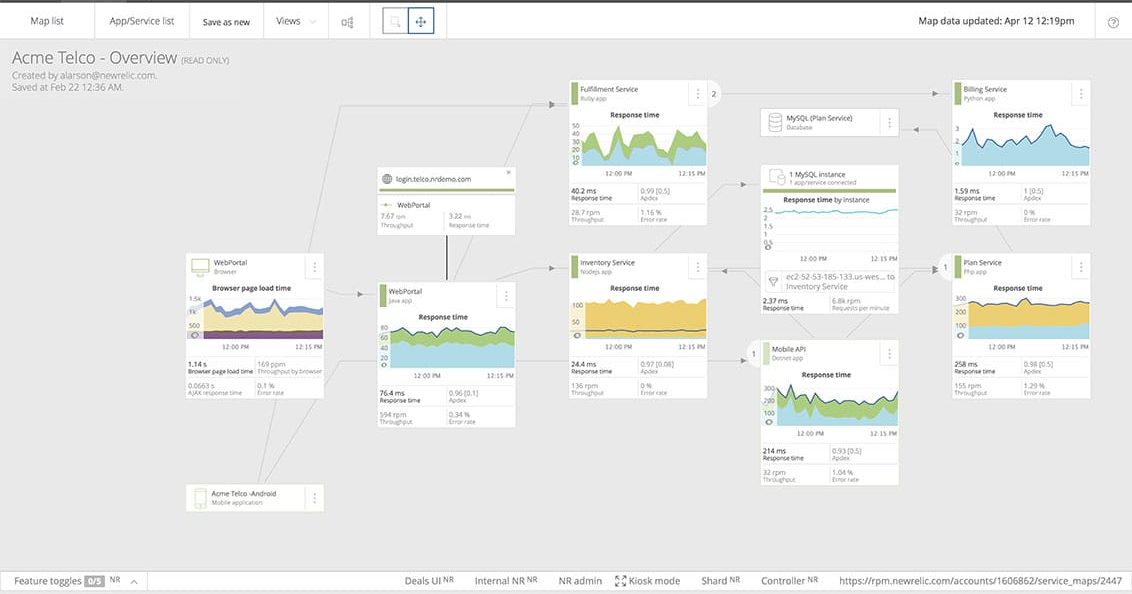
Como puede ver, es bastante fácil rastrear visualmente cómo están fluyendo los datos de un sistema a otro y las métricas de rendimiento resultantes. La lentitud y los tiempos de inactividad activan alertas instantáneas, lo que les permite solucionar los problemas antes de que el negocio se resienta.
No sólo el lado DevOps está cubierto en New Relic. También es posible establecer objetivos y reglas para la experiencia del cliente y obtener informes detallados para averiguar dónde se necesita más trabajo. Como sabe cualquier vendedor digital que se precie, esta información es oro sólido.
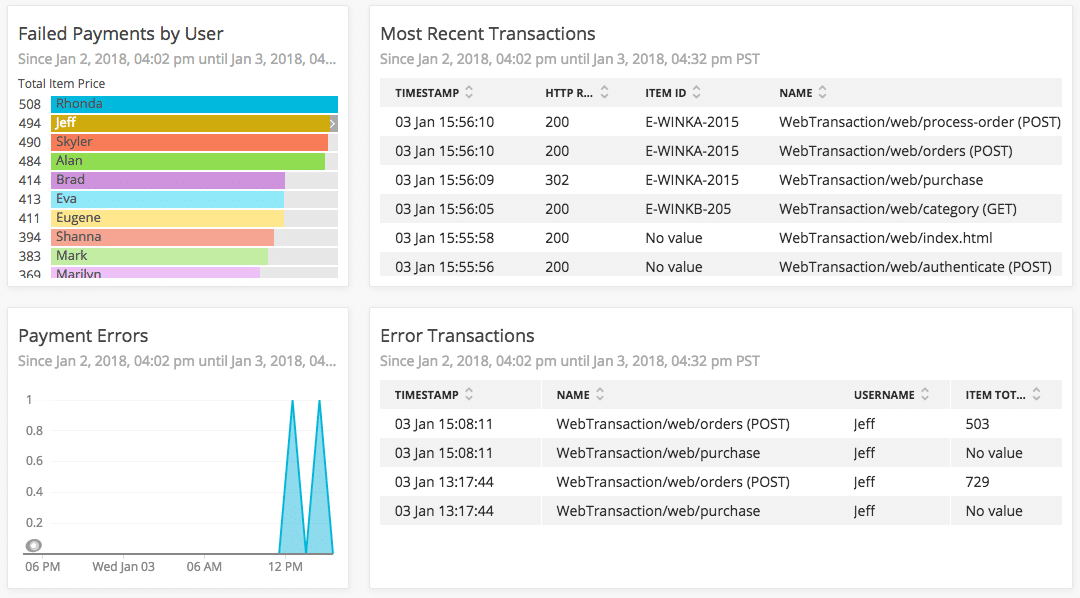
Los ingeniosos cuadros de mando de New Relic no tienen fin. Eche un vistazo a éste, por ejemplo, que mapea todo el clúster de la aplicación por nodos, y proporciona información en directo sobre lo que está sucediendo en cada nodo.
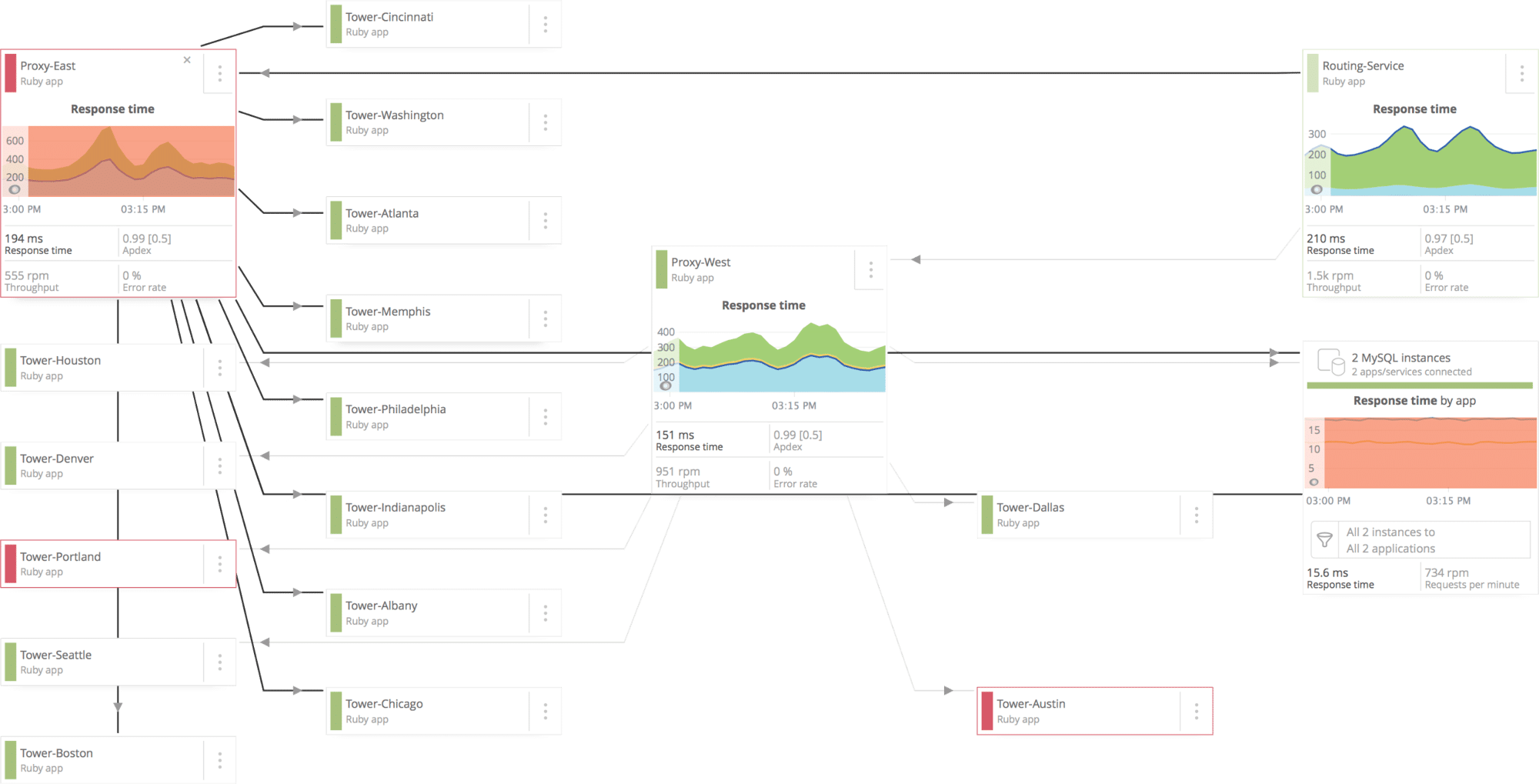
Así pues, tanto si su aplicación es sencilla como compleja, New Relic puede ofrecerle muchas perspectivas interesantes.
Fortaleza API
El siguiente en la lista es API Fortress, que pretende ser el cuchillo suizo de la supervisión de API para varios equipos de una organización, y lo hace bastante bien.

Dirigida tanto a probadores como a desarrolladores, API Fortress permite la creación de pruebas visuales y colaborativas como cualquier otra herramienta moderna de monitorización de API por ahí, y luego camina un poco más en cuanto a comodidad y características. Las dos que más me gustan son Load Testing y Mocking.
Para los desarrolladores, API Fortress puede crear un conjunto de pruebas a partir de una especificación de API dada. Así, si sigue Swagger, OpenAPI o RAML, la mitad del trabajo ya está hecho. API Mocking permite a sus equipos de desarrollo definir la interfaz de la nueva API como un servicio simulado, a partir del cual los equipos de control de calidad pueden empezar a crear los conjuntos de pruebas inmediatamente. Se acabaron las agotadoras y largas esperas hasta que la API real esté terminada para que el QA pueda empezar

API Fortress también funciona con todos los principales sistemas de CI/CD, aliviando un punto doloroso más de la integración. Por último, la prueba de carga sólida como una roca y la supervisión también están incorporadas, haciendo de API Fortress un paquete completo para los equipos de desarrollo y pruebas para probar y supervisar rápidamente las API.
Ciencia API
Con API Science, podrá probar sus API con una API. Aunque parezca una forma elegante de decir lo mismo, API Science viene con algunas características novedosas que probablemente atraigan a muchos. La primera es la monitorización completa de su pila de API, lo que significa cubrir también las API externas.
Ocurre muchas veces que sus API son eficaces y responden bien, pero aquellas de las que depende su negocio están caídas. Además, en algunos casos, no hay ninguna base objetiva para afirmar qué API estaba caída en qué momento, una lucha que puede convertirse en una especie de guerra fría entre dos proveedores de API.
En esos casos, API Science funciona como un punto intermedio indiscutible que puede mostrar la disponibilidad histórica de las API.

La segunda característica interesante es la comprobación distribuida de las API. API Science supervisa sus API desde varias ubicaciones en todo el mundo y le permite saber cómo se comporta la API en las distintas ubicaciones. Combine todo este JavaScript personalizado en su sistema de monitorización y tendrá una herramienta de monitorización de API casi ideal 🙂
APImetrics
Con una cobertura completa de extremo a extremo, la monitorización de API de APImetrics hace un trabajo fantástico al permitirle conocer los problemas incluso antes de que sean notificados por sus usuarios. Puede monitorizar desde más de 80 ubicaciones diferentes y recibir alertas en tiempo real directamente en su herramienta preferida, que incluye correo electrónico, Slack, Pager Duty y otras similares.

Aparte de eso, le permite mirar a través del funcionamiento de la API, ya sea la búsqueda de DNS o los tiempos de procesamiento del servidor para confirmar que las transacciones se completan como deberían. Se trata de una función bastante práctica, y dado que APImetrics es súper sencillo de configurar en general, hace que las cosas sean aún mejores.
Este servicio puede gestionar cualquier tipo de solicitudes de API, establecer condiciones, definir aserciones y ofrecerle información sobre diversas áreas, incluidos los problemas de conectividad.
Moesif
Moesif es una herramienta muy centrada en el usuario que realiza un seguimiento de la experiencia del usuario en sus API. Le permite realizar un seguimiento de los problemas de las API que están afectando a los clientes y tomar medidas proactivas para solucionarlos.
La función de «reglas de alerta» le permite realizar un seguimiento de diversas métricas y le avisa cada vez que se supera un umbral, por ejemplo, un aumento repentino del número de visitantes del sitio o un pico en la utilización de la CPU. Puede integrar esta herramienta con herramientas de colaboración como Slack para recibir alertas a nivel de equipo.
La función de «notificación al usuario» le proporciona la lista de clientes o visitantes que han utilizado su API y su comportamiento, lo que puede ayudarle en marketing, retargeting y retención de clientes. También puede integrar Moesif con herramientas CRM como Hubspot y Salesforce para reforzar su automatización del marketing.
La herramienta ofrece múltiples cuadros de mando de equipo preconstruidos para que los distintos proyectos o departamentos se centren en lo que es importante para ellos.
Moesif ofrece una prueba gratuita de 14 días y los planes de pago comienzan en 85 dólares al mes.
Conclusión
Con esto, mis principales recomendaciones para la supervisión de API llegan a su fin. He hecho todo lo posible por no restringir las API a la estrecha definición con la que se etiquetan la mayoría de las veces. Desde propietarios de empresas hasta desarrolladores, probadores, control de calidad y gestores de proyectos, hay herramientas en esta lista que sirven para todos.
A continuación, descubra cómo proteger las API.