Python es un lenguaje muy versátil, y los desarrolladores de Python a menudo tienen que trabajar con una gran variedad de archivos y obtener información almacenada en ellos para procesarla. Un formato de archivo popular que seguramente encontrará como desarrollador de Python es el Formato de Documento Portátil conocido popularmente como PDF
Los archivos PDF pueden contener texto, imágenes y enlaces. Al procesar datos en un programa Python, es posible que se encuentre con la necesidad de extraer los datos almacenados en un documento PDF. A diferencia de las estructuras de datos como tuplas, listas y diccionarios, obtener la información almacenada en un documento PDF puede parecer algo difícil de hacer.
Por suerte, existen varias bibliotecas que facilitan el trabajo con PDF y la extracción de los datos almacenados en archivos PDF. Para conocer estas diferentes bibliotecas, veamos cómo puede extraer textos, enlaces e imágenes de archivos PDF. Para seguir adelante, descargue el siguiente archivo PDF y guárdelo en el mismo directorio que el archivo de su programa Python.
Extracción de texto de archivos PDF
Para extraer texto de archivos PDF utilizando Python, vamos a utilizar la biblioteca PyPDF2. PyPDF2 es una biblioteca Python gratuita y de código abierto que puede utilizarse para combinar, recortar y transformar las páginas de archivos PDF. Puede añadir datos personalizados, opciones de visualización y contraseñas a los archivos PDF. Pero lo más importante es que PyPDF2 puede recuperar texto de archivos PDF.
Para utilizar PyPDF2 para extraer texto de archivos PDF, instálelo utilizando pip, que es un instalador de paquetes para Python. pip le permite instalar diferentes paquetes de Python en su máquina:
1. Compruebe si ya tiene pip instalado ejecutando
pip --versionSi no obtiene de vuelta un número de versión, significa que pip no está instalado.
2. Para instalar pip, haga clic en get pip para descargar su script de instalación.
El enlace abre una página con el script para instalar pip como se muestra a continuación:
Haga clic con el botón derecho en la página y pulse Guardar como para guardar el archivo. Por defecto, el nombre del archivo es get-pip.py
Abra el terminal y navegue hasta el directorio con el archivo get-pip. py que acaba de descargar y ejecute el comando
sudo python3 get-pip.pyEsto debería instalar pip como se muestra a continuación:
3. Compruebe que pip se ha instalado correctamente ejecutando
pip --versionSi tuvo éxito, debería obtener un número de versión:

Con pip instalado, ya podemos empezar a trabajar con PyPDF2.
1. Instale PyPDF2 ejecutando el siguiente comando en el terminal:
pip install PyPDF2
2. Cree un archivo Python e importe PdfReader de PyPDF2 utilizando la siguiente línea:
from PyPDF2 import PdfReaderLa biblioteca PyPDF2 proporciona diversas clases para trabajar con archivos PDF. Una de estas clases es el PdfReader , que puede utilizarse para abrir archivos PDF, leer su contenido y extraer texto de archivos PDF, entre otras cosas.
3. Para empezar a trabajar con un archivo PDF, primero tiene que abrir el archivo. Para ello, cree una instancia de la clase PdfReader y pásele el archivo PDF con el que desea trabajar:
reader = PdfReader('juegos.pdf')La línea anterior instancia el PdfReader y lo prepara para acceder al contenido del archivo PDF que especifique. La instancia se almacena en una variable llamada lector, que tendrá que acceder a una serie de métodos y propiedades disponibles en la clase PdfReader.
4. Para comprobar que todo funciona correctamente, imprima el número de páginas del PDF que ha pasado utilizando el siguiente código:
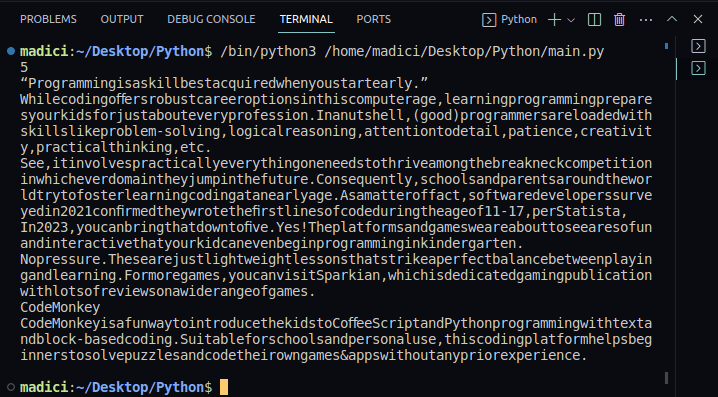
print(len(reader.pages))Salida:
5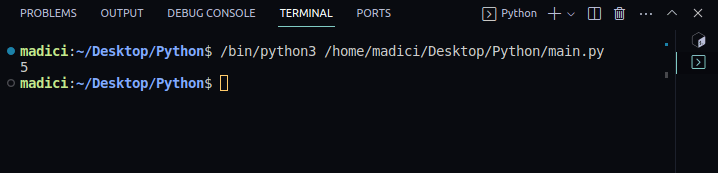
5. Como nuestro archivo PDF tiene 5 páginas, podemos acceder a cada una de las páginas disponibles en el PDF. Sin embargo, el conteo comienza desde 0, al igual que la convención de indexación de Python. Por lo tanto, la primera página del archivo pdf será la página número 0. Para recuperar la primera página del PDF, añada la siguiente línea a su código:
página1 = lector.páginas<x><x><x><x><x>[0]</x></x></x></x></x>La línea anterior recupera la primera página del archivo PDF y la almacena en una variable llamada page1.
6. Para extraer el texto de la primera página del archivo PDF, añada la siguiente línea:
textPage1 = page1.extract_text()Esto extrae el texto de la primera página del PDF y almacena el contenido en una variable llamada textPage1. De este modo, tendrá acceso al texto de la primera página del archivo PDF a través de la variable textPage1.
7. Para confirmar que el texto se ha extraído correctamente, puede imprimir el contenido de la variable textPage1. Nuestro código completo, que también imprime el texto de la primera página del archivo PDF, se muestra a continuación:
# importar la clase PdfReader de PyPDF2
from PyPDF2 import PdfReader
# crear una instancia de la clase PdfReader
reader = PdfReader('juegos.pdf')
# obtener el número de páginas disponibles en el archivo pdf
print(len(lector.paginas))
# acceda a la primera página del pdf
página1 = lector.páginas<x><x><x><x><x>[0]</x></x></x></x></x>
# extraiga el texto de la página 1 del archivo pdf
textPage1 = page1.extract_text()
# imprima el texto extraído
print(pagina_texto1)Salida:
Extracción de enlaces de archivos PDF
Para extraer enlaces de archivos PDF, vamos a recurrir a PyMuPDF, que es una biblioteca de Python para extraer, analizar, convertir y manipular los datos almacenados en documentos como los PDF. Para utilizar PyMuPDF, debe tener Python 3.8 o posterior. Para empezar:
1. Instale PyMuPDF ejecutando la siguiente línea en el terminal:
pip install PyMuPDF2. Importe PyMuPDF en su archivo Python utilizando la siguiente sentencia:
import fitz3. Para acceder al PDF del que desea extraer enlaces, primero debe abrirlo. Para abrirlo, introduzca la siguiente línea
doc = fitz.open("juegos.pdf")4. Una vez abierto el archivo PDF, imprima el número de páginas del PDF mediante la siguiente línea:
print(doc.cuenta_páginas)Salida:
5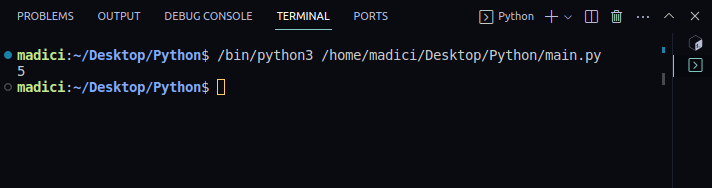
4. Para extraer enlaces de una página del archivo PDF, necesitamos cargar la página de la que queremos extraer enlaces. Para cargar una página, introduzca la siguiente línea, en la que pasará el número de página que desea cargar a una función llamada load_page()
page = doc.load_page(0)Para extraer los enlaces de la primera página, pasamos 0(cero). El recuento de páginas comienza desde cero, al igual que en las estructuras de datos como las matrices y los diccionarios.
5. Extraiga los enlaces de la página utilizando la siguiente línea:
links = page.get_links()Se extraerán todos los enlaces de la página especificada, en nuestro caso, la página 1, y se almacenarán en la variable llamada enlaces
6. Para ver el contenido de la variable links, imprímala de la siguiente manera
print(enlaces)Salida:
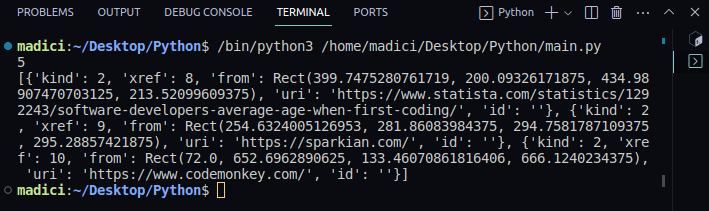
En la salida impresa, observe que la variable links contiene una lista de diccionarios con pares clave-valor. Cada enlace de la página está representado por un diccionario, con el enlace real almacenado bajo la clave«uri«
7. Para obtener los enlaces de la lista de objetos almacenados bajo el nombre variable links, itere a través de la lista utilizando una sentencia for in e imprima los enlaces específicos almacenados bajo la clave uri. El código completo que hace esto se muestra a continuación:
import fitz
# Abrir el archivo PDF
doc = fitz.open("juegos.pdf")
# Imprima el número de páginas
print(doc.recuento_páginas)
# cargue la primera página del PDF
página = doc.cargar_página(0)
# extraiga todos los enlaces de la página y guárdelos en - enlaces
enlaces = page.get_links()
# imprimir el objeto links
#imprimir(enlaces)
# imprimir los enlaces reales almacenados bajo la clave "uri
para obj en enlaces
print(obj["uri"])Salida:
5
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/
https://sparkian.com/
https://www.codemonkey.com/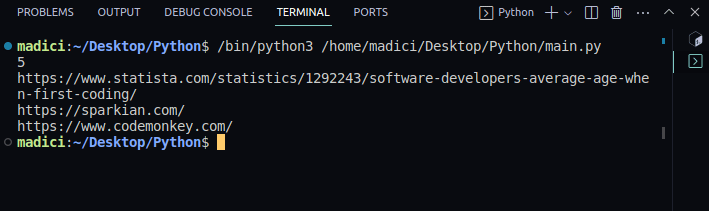
8. Para que nuestro código sea más reutilizable, podemos refactorizarlo definiendo una función para extraer todos los enlaces de un PDF y una función para imprimir todos los enlaces encontrados en un PDF. De esta forma, puede llamar a las funciones con cualquier PDF y obtendrá de vuelta todos los enlaces del PDF. El código que hace esto se muestra a continuación:
importar fitz
# Extraer todos los enlaces de un documento PDF
def extraer_enlace(ruta_al_pdf):
enlaces = []
doc = fitz.open(ruta_al_pdf)
para page_num en range(doc.page_count):
page = doc.load_page(page_num)
enlaces_de_página = page.get_links()
links.extend(enlaces_página)
devolver enlaces
# imprimir todos los enlaces devueltos del documento PDF
def imprimir_todos_los_enlaces(enlaces):
for enlace en enlaces
print(enlace["uri"])
# Llame a la función para extraer todos los enlaces de un pdf
# todos los enlaces devueltos se almacenan en all_links
all_links = extraer_enlace("juegos.pdf")
# llame a la función para imprimir todos los enlaces del pdf
imprimir_todos_los_enlaces(todos_los_enlaces)Salida:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/
https://sparkian.com/
https://www.codemonkey.com/
https://scratch.mit.edu/
https://www.tynker.com/
https://codecombat.com/
https://lightbot.com/
https://sparkian.com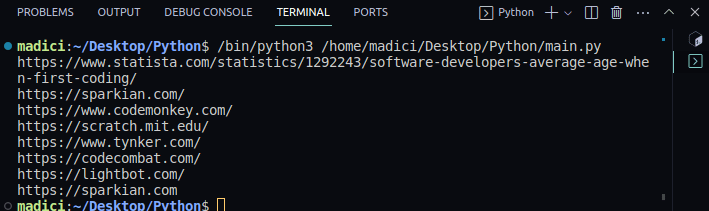
A partir del código anterior, la función extraer_enlace() recibe un archivo PDF, itera por todas las páginas del PDF, extrae todos los enlaces y los devuelve. El resultado de esta función se almacena en una variable llamada all_links
La función print_all_links() recibe el resultado de extract_link(), recorre la lista e imprime todos los enlaces reales encontrados en el PDF que pasó a la función extract_link() .
Extracción de imágenes de archivos PDF
Para extraer imágenes de un PDF, vamos a seguir utilizando PyMuPDF. Para extraer imágenes de un archivo PDF
1. Importe PyMuPDF, io, y PIL. Python Imaging Library(PIL) proporciona herramientas que facilitan la creación y almacenamiento de imágenes, entre otras funciones. io proporciona clases para el manejo fácil y eficiente de datos binarios.
importar fitz
from io import BytesIO
from PIL import Imagen2. Abra el archivo PDF del que desea extraer las imágenes:
doc = fitz.open("juegos.pdf")3. Cargue la página de la que desea extraer las imágenes:
page = doc.load_page(0)4. PyMuPdf identifica las imágenes de un archivo PDF mediante un número de referencia cruzada (xref), que suele ser un número entero. Cada imagen de un archivo PDF tiene un xref único. Por lo tanto, para extraer una imagen de un PDF, primero tenemos que obtener el número xref que la identifica. Para obtener el número xref de las imágenes de una página, utilizamos la función get_images() del siguiente modo:
image_xref = page.get_images()
print(imagen_xref)Salida:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]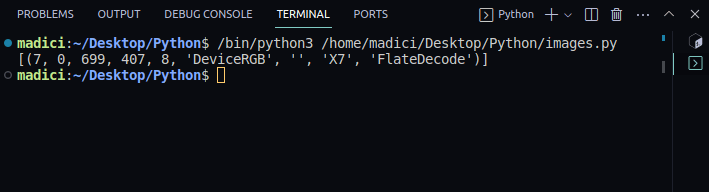
get_images() devuelve una lista de tuplas con información sobre la imagen. Como sólo tenemos una imagen en la primera página, sólo hay una tupla. El primer elemento de la tupla representa el xref de la imagen en la página. Por lo tanto, la xref de la imagen en la primera página es 7.
5. Para extraer el valor xref de la imagen de la lista de tuplas, utilizamos el código siguiente:
# obtener el valor xref de la imagen
valor_xref = valor_xref<x><x><x><x><x>[0]</x></x></x></x></x><x><x><x><x><x>[0]</x></x></x></x></x>de la imagen
print(valor_xref)Salida:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
7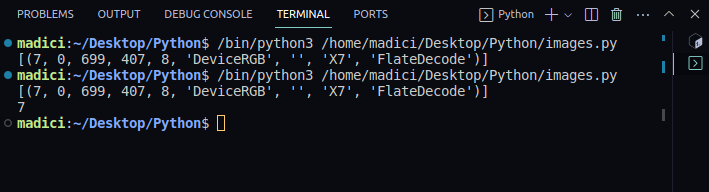
6. Como ahora tiene la xref que identifica una imagen en el PDF, puede extraer la imagen utilizando la función extract_image( ) de la siguiente manera
img_diccionario = doc.extraer_imagen(valor_xref)Esta función, sin embargo, no devuelve la imagen real. En su lugar, devuelve un diccionario que contiene los datos binarios de la imagen y metadatos sobre la imagen, entre otras cosas.
7. A partir del diccionario devuelto por la función extraer_imagen( ), compruebe la extensión de archivo de la imagen extraída. La extensión del archivo se almacena bajo la clave«ext«:
# obtener extensión de archivo
img_extension = img_dictionary["ext"]
print(img_extension)Salida:
png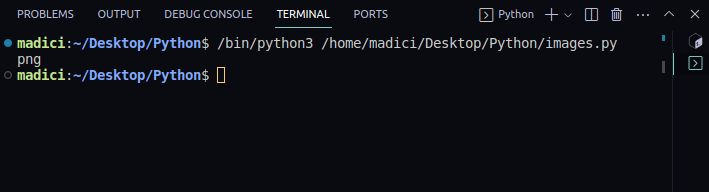
8. Extraiga los binarios de imagen del diccionario almacenado en img_dictionary. Los binarios de imagen se almacenan bajo la clave«image«
# Obtener los datos binarios reales de la imagen
img_binary = img_dictionary["imagen"]9. Cree un objeto BytesIO e inicialícelo con los datos binarios de la imagen que la representan. Esto crea un objeto similar a un archivo que puede ser procesado por bibliotecas de Python como PIL para que pueda guardar la imagen.
# cree un objeto BytesIO para trabajar con los bytes de la imagen
image_io = BytesIO(img_binary)10. Abra y analice los datos de la imagen almacenados en el objeto BytesIO llamado image_io utilizando la biblioteca PIL. Esto es importante ya que permite a la biblioteca PIL determinar el formato de la imagen con la que está intentando trabajar, en este caso, un PNG. Tras detectar el formato de la imagen, PIL crea un objeto imagen que puede ser manipulado con las funciones y métodos PIL, como el método save(), para guardar la imagen en el almacenamiento local.
# abra la imagen utilizando PIL
imagen = Image.open(imagen_io)11. Especifique la ruta donde desea guardar la imagen.
ruta_salida = "imagen_1.png"Dado que la ruta anterior sólo contiene el nombre del archivo con su extensión, la imagen extraída se guardará en el mismo directorio que el archivo Python que contiene este programa. La imagen se guardará como imagen_1.png. La extensión PNG es importante para que coincida con la extensión original de la imagen.
12. Guarde la imagen y cierre el objeto ByteIO.
# guardar la imagen
image.save(ruta_salida)
# Cierre el objeto BytesIO
image_io.close()A continuación se muestra el código completo para extraer una imagen de un archivo PDF:
import fitz
from io import BytesIO
from PIL import Imagen
doc = fitz.open("juegos.pdf")
página = doc.cargar_página(0)
# obtener una referencia cruzada(xref) a la imagen
image_xref = page.get_images()
# obtenga el valor xref real de la imagen
valor_xref = valor_xref<x><x><x><x><x>[0]</x></x></x></x></x><x><x><x><x><x>[0]</x></x></x></x></x>de la imagen
# extraiga la imagen
img_dictionary = doc.extraer_imagen(valor_xref)
# obtener la extensión del archivo
img_extension = img_dictionary["ext"]
# obtener los datos binarios reales de la imagen
img_binary = img_dictionary["imagen"]
# cree un objeto BytesIO para trabajar con los bytes de la imagen
image_io = BytesIO(img_binary)
# abra la imagen utilizando la biblioteca PIL
imagen = Image.open(imagen_io)
#especifique la ruta donde desea guardar la imagen
ruta_salida = "imagen_1.png"
#guardar la imagen
image.save(ruta_salida)
# Cierre el objeto BytesIO
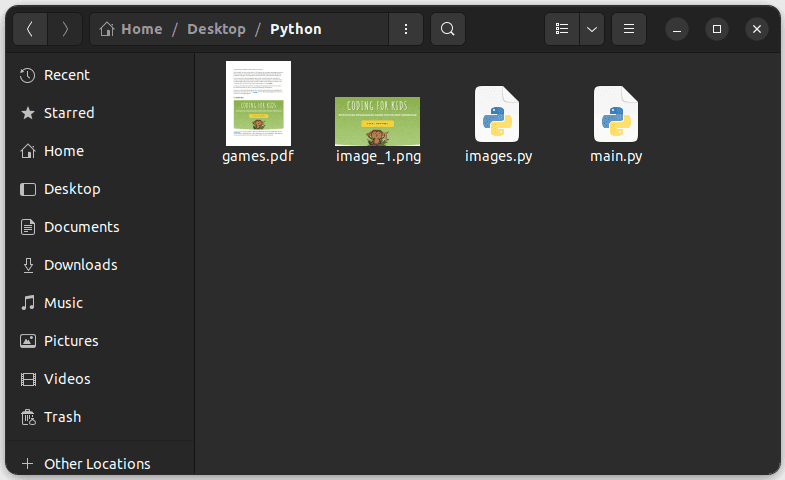
image_io.close()Ejecute el código y vaya a la carpeta que contiene su archivo Python; debería ver la imagen extraída llamada imagen_1.png, como se muestra a continuación:
Conclusión
Para adquirir más práctica con la extracción de enlaces, imágenes y textos de los PDF, intente refactorizar el código de los ejemplos para hacerlos más reutilizables, como se muestra en el ejemplo de los enlaces. De esta manera, sólo tendrá que pasar un archivo PDF, y su programa Python extraerá todos los enlaces, imágenes o texto en todo el PDF. ¡Feliz codificación!
También puede explorar algunas de las mejores API PDF para cada necesidad empresarial.