En este artículo hablaremos de la vectorización, una técnica de PNL, y comprenderemos su importancia con una guía completa sobre los distintos tipos de vectorización.
Hemos tratado los conceptos fundamentales del preprocesamiento PNL y la limpieza de textos. Hemos visto los fundamentos de la PNL, sus diversas aplicaciones y técnicas como la tokenización, la normalización, la estandarización y la limpieza de textos.

Antes de hablar de la vectorización, repasemos qué es la tokenización y en qué se diferencia de la vectorización.
¿Qué es la tokenización?
La tokenización es el proceso de descomponer las frases en unidades más pequeñas llamadas tokens. Los tokens ayudan a los ordenadores a comprender y trabajar con el texto con facilidad.
EJ. ‘Este artículo es bueno’
Tokens- [‘Este’, ‘artículo’, ‘es’, ‘bueno’]
¿Qué es la vectorización?
Como sabemos, los modelos y algoritmos de aprendizaje automático entienden datos numéricos. La vectorización es un proceso de conversión de datos textuales o categóricos en vectores numéricos. Al convertir los datos en datos numéricos, puede entrenar su modelo con mayor precisión.
¿Por qué necesitamos la vectorización?
❇️ La tokenización y la vectorización tienen distinta importancia en el procesamiento del lenguaje natural (PLN). La tokenización divide las frases en pequeños tokens. La vectorización la convierte en un formato numérico para que el ordenador/modelo LML pueda entenderla.
❇️ La vectorización no sólo es útil para convertirlo en formato numérico, sino también para captar el significado semántico.
❇️ La vectorización puede reducir la dimensionalidad de los datos y hacerlos más eficientes. Esto puede ser muy útil cuando se trabaja con un gran conjunto de datos.
❇️ Muchos algoritmos de aprendizaje automático requieren entradas numéricas, como las redes neuronales, por lo que la vectorización puede ayudarnos.
Existen diferentes tipos de técnicas de vectorización, que entenderemos a lo largo de este artículo.
Bolsa de palabras
Si tiene un montón de documentos o frases y quiere analizarlos, una bolsa de palabras simplifica este proceso tratando el documento como una bolsa llena de palabras.
El enfoque de bolsa de palabras puede ser útil en la clasificación de textos, el análisis de sentimientos y la recuperación de documentos.
Supongamos que está trabajando con mucho texto. Una bolsa de palabras le ayudará a representar los datos de texto creando un vocabulario de palabras únicas en nuestros datos de texto. Tras crear el vocabulario, codificará cada palabra como un vector basado en la frecuencia (con qué frecuencia aparece cada palabra en ese texto) de esas palabras.
Estos vectores están formados por números no negativos (0,1,2…..) que representan el número de frecuencias en ese documento.
La bolsa de palabras consta de tres pasos:
Paso 1: Tokenización
Descompondrá los documentos en tokens.
Ej – (Frase: «Me encanta la pizza y me encantan las hamburguesas»)
Paso2 : Separación de palabras únicas/creación de vocabulario
Cree una lista de todas las palabras únicas que aparecen en sus frases.
[«Yo», «amo», «Pizza», «y», «Hamburguesas»]
Paso 3: Recuento de la aparición de palabras/ creación de vectores
En este paso se contará cuántas veces se repite cada palabra del vocabulario y se almacenará en una matriz dispersa. En la matriz dispersa, cada fila en un vector de frases cuya longitud (las columnas de la matriz) es igual al tamaño del vocabulario.
Importar CountVectorizer
Vamos a importar CountVectorizer para entrenar nuestro modelo de bolsa de palabras
from sklearn.feature_extraction.text import CountVectorizerCrear vectorizador
En este paso, vamos a crear nuestro modelo utilizando CountVectorizer y a entrenarlo utilizando nuestro documento de texto de muestra.
# Documentos de texto de muestra
documentos = [
"Este es el primer documento",
"Este documento es el segundo",
"Y éste es el tercero",
"¿Este es el primer documento?",
]
# Crear un CountVectorizer
cv = CountVectorizer()# Ajustar y transformar
X = cv.fit_transform(documentos)Convertir en una matriz densa
En este paso, convertiremos nuestras representaciones en una matriz densa. Además, obtendremos nombres de rasgos o palabras.
# Obtener los nombres de las características/palabras
feature_names = vectorizer.get_feature_names_out()
# Convertir a matriz densa
X_denso = X.toarray()
Imprimamos la matriz de términos del documento y las palabras de las características
# Imprima la DTM y los nombres de las características
print("Matriz de términos del documento (DTM):")
print(X_denso)
print("Nombres de características:")
print(nombres_caracteristicas)
Matriz Documento-Término (DTM):

Nombres de características:

Como puede ver, los vectores están formados por números no negativos (0,1,2……) que representan la frecuencia de las palabras en el documento.
Tenemos cuatro documentos de texto de muestra, y hemos identificado nueve palabras únicas de estos documentos. Almacenamos estas palabras únicas en nuestro vocabulario asignándoles ‘Nombres de características’
A continuación, nuestro modelo Bag of Words comprueba si la primera palabra única está presente en nuestro primer documento. Si está presente, le asigna un valor de 1; en caso contrario, le asigna 0.
Si la palabra aparece varias veces (por ejemplo, 2 veces), le asigna un valor en consecuencia.
Por ejemplo, en el segundo documento, la palabra «documento» se repite dos veces, por lo que su valor en la matriz será 2.
Si queremos una sola palabra como característica en la clave del vocabulario – Representación de unigramas.
n – gramos = Unigramas, bigramas…….etc.
Existen muchas bibliotecas como scikit-learn para implementar la bolsa de palabras: Keras, Gensim y otras. Esto es sencillo y puede ser útil en diferentes casos.
Sin embargo, la bolsa de palabras es más rápida pero tiene algunas limitaciones.
- Asigna el mismo peso a cada palabra, independientemente de su importancia. En muchos casos, algunas palabras son más importantes que otras.
- BoW se limita a contar la frecuencia de una palabra o cuántas veces aparece una palabra en un documento. Esto puede dar lugar a un sesgo hacia palabras comunes como «el», «y», «es», etc., que pueden no tener mucho significado.
- Los documentos más largos pueden tener un mayor número de palabras y crear vectores más grandes. Esto puede dificultar la comparación. Puede crear una matriz dispersa, lo que no puede ser bueno para realizar proyectos de PNL complejos.
Para resolver este problema podemos optar por enfoques mejores, uno de ellos es el TF-IDF. Entendámoslo en detalle.
TF-IDF
TF-IDF, o Term Frequency – Inverse Document Frequency, es una representación numérica para determinar la importancia de las palabras en el documento.
¿Por qué necesitamos el TF-IDF en lugar de la bolsa de palabras?
Una bolsa de palabras trata a todas las palabras por igual y sólo se preocupa por la frecuencia de palabras únicas en las frases. El TF-IDF da importancia a las palabras de un documento teniendo en cuenta tanto la frecuencia como la unicidad.
Las palabras que se repiten con demasiada frecuencia no superan a las palabras menos frecuentes y más importantes.
TF: La frecuencia de términos mide la importancia de una palabra en una frase.
FID: La frecuencia inversa de documentos mide lo importante que es una palabra en toda la colección de documentos.
TF = Frecuencia de palabras en un documento / Número total de palabras en ese documento
DF = Documento que contiene la palabra w / Número total de documentos
IDF = log(Número total de documentos / Documentos que contienen la palabra w)
IDF es recíproco de DF. La razón es que cuanto más común es la palabra en todos los documentos, menor es su importancia en el documento actual.
Puntuación final TF-IDF: TF-IDF = TF * IDF
Es una forma de averiguar qué palabras son comunes dentro de un mismo documento y únicas en todos los documentos. Estas palabras pueden ser útiles para encontrar el tema principal del documento.
Por ejemplo
Doc1 = «Me encanta el aprendizaje automático»
Doc2 = «Me encanta Geekflare»
Tenemos que encontrar la matriz TF-IDF para nuestros documentos.
En primer lugar, crearemos un vocabulario de palabras únicas.
Vocabulario = [«I», «love», «machine», «learning», «Geekflare»]
Así pues, tenemos 5 cinco palabras. Busquemos la TF y la IDF de estas palabras.
TF = Frecuencia de palabras en un documento / Número total de palabras en ese documento
TF:
- Para «yo» = TF para Doc1: 1/4 = 0,25 y para Doc2: 1/3 ≈ 0,33
- Para «amor TF para Doc1: 1/4 = 0,25 y para Doc2: 1/3 ≈ 0,33
- Para «máquina»: TF para Doc1: 1/4 = 0,25 y para Doc2: 0/3 ≈ 0
- Para «Aprendizaje»: TF para Doc1: 1/4 = 0,25 y para Doc2: 0/3 ≈ 0
- Para «Geekflare TF para Doc1: 0/4 = 0 y para Doc2: 1/3 ≈ 0,33
Ahora, calculemos el IDF.
IDF = log(Número total de documentos / Documentos que contienen la palabra w)
IDF:
- Para «I IDF es log(2/2) = 0
- Para «amor IDF es log(2/2) = 0
- Para «máquina»: IDF es log(2/1) = log(2) ≈ 0,69
- Para «Aprendizaje IDF es log(2/1) = log(2) ≈ 0,69
- Para «Geekflare IDF es log(2/1) = log(2) ≈ 0,69
Ahora, calculemos la puntuación final del TF-IDF:
- Para «I TF-IDF para Doc1: 0,25 * 0 = 0 y TF-IDF para Doc2: 0,33 * 0 = 0
- Para «amor»: TF-IDF para Doc1: 0,25 * 0 = 0 y TF-IDF para Doc2: 0,33 * 0 = 0
- Para «máquina»: TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 y TF-IDF para Doc2: 0 * 0,69 = 0
- Para «Aprendizaje TF-IDF para Doc1: 0,25 * 0,69 ≈ 0,17 y TF-IDF para Doc2: 0 * 0,69 = 0
- Para «Geekflare TF-IDF para Doc1: 0 * 0,69 = 0 y TF-IDF para Doc2: 0,33 * 0,69 ≈ 0,23
La matriz TF-IDF tiene este aspecto:
Me encanta el aprendizaje automático Geekflare
Doc1 0,0 0,0 0,17 0,17 0,0
Doc2 0,0 0,0 0,0 0,0 0,23
Los valores de una matriz TF-IDF le indican la importancia de cada término dentro de cada documento. Los valores altos indican que un término es importante en un documento concreto, mientras que los valores bajos sugieren que el término es menos importante o común en ese contexto.
El TF-IDF se utiliza sobre todo en la clasificación de textos, la construcción de chatbot de recuperación de información y el resumen de textos.
Importar TfidfVectorizer
Vamos a , importar TfidfVectorizer de sklearn
from sklearn.feature_extraction.text import TfidfVectorizerCrear el vectorizador
Como puede ver, crearemos nuestro modelo Tf Idf utilizando TfidfVectorizer.
# Documentos de texto de muestra
texto = [
"Este es el primer documento",
"Este documento es el segundo",
"Y éste es el tercero",
"¿Este es el primer documento?",
]
# Crear un TfidfVectorizer
cv = TfidfVectorizer()Crear la matriz TF-IDF
Vamos a entrenar nuestro modelo proporcionándole texto. Después, convertiremos la matriz representativa en matriz densa.
# Ajustar y transformar para crear la matriz TF-IDF
X = cv.fit_transform(texto)# Obtener los nombres/palabras de las características
feature_names = vectorizer.get_feature_names_out()
# Convierta la matriz TF-IDF en una matriz densa para facilitar su manipulación (opcional)
X_densa = X.toarray()Imprimir la matriz TF-IDF y las palabras característica
# Imprima la matriz TF-IDF y las palabras características
print("Matriz TF-IDF:")
print(X_dense)
print("Nombres_de_características:")
print(nombres_caracteristicas)
Matriz TF-IDF:

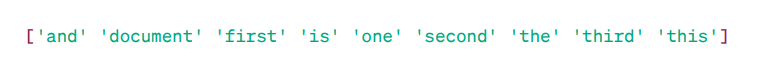
Como puede ver, estos enteros decimales indican la importancia de las palabras en documentos específicos.
Además, se pueden combinar palabras en grupos de 2,3,4, etc. utilizando n-gramas.
Hay otros parámetros que podemos incluir: min_df, max_feature, subliner_tf, etc.
Hasta ahora, hemos explorado las técnicas básicas basadas en la frecuencia.
Pero el TF-IDF no puede proporcionar un significado semántico y una comprensión contextual del texto.
Conozcamos técnicas más avanzadas que han cambiado el mundo de la incrustación de palabras y que son mejores para el significado semántico y la comprensión contextual.
Word2Vec
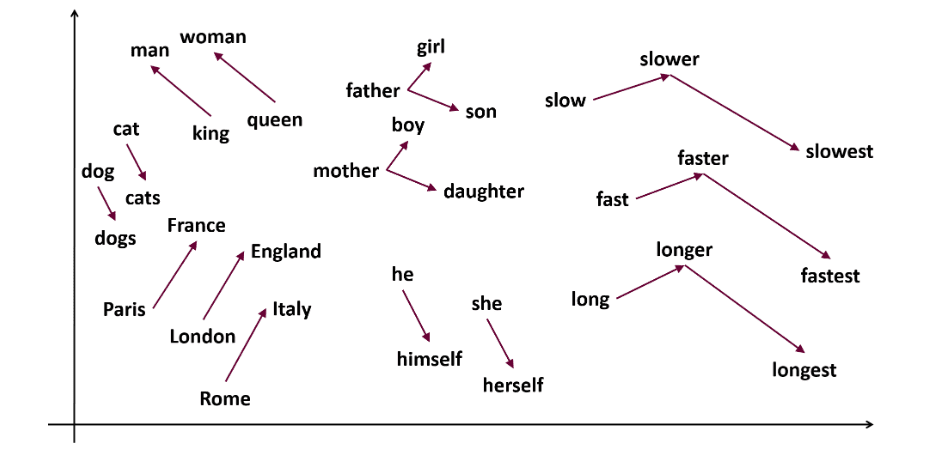
Word2vec es una popular técnica de incrustación de palabras (tipo de vector de palabras y útil para captar la similitud semántica y sintáctica) en PNL. Fue desarrollada por Tomas Mikolov y su equipo en Google en 2013. Word2vec representa las palabras como vectores continuos en un espacio multidimensional.
Word2vec pretende representar las palabras de forma que capten su significado semántico. Los vectores de palabras generados por word2vec se sitúan en un espacio vectorial continuo.
Por ejemplo, los vectores de «gato» y «perro» estarían más próximos que los vectores de «gato» y «niña».
Word2vec puede utilizar dos arquitecturas de modelos para crear la incrustación de palabras.
CBOW: La bolsa continua de palabras o CBOW intenta predecir una palabra promediando el significado de las palabras cercanas. Toma un número fijo o ventana de palabras alrededor de la palabra objetivo, luego la convierte en forma numérica (incrustación), después hace la media de todas y utiliza esa media para predecir la palabra objetivo con la red neuronal.
Ej- Predecir objetivo: ‘Zorro’
Palabras de la frase: ‘El’, ‘rápido’, ‘marrón’, ‘salta’, ‘sobre’, ‘el’
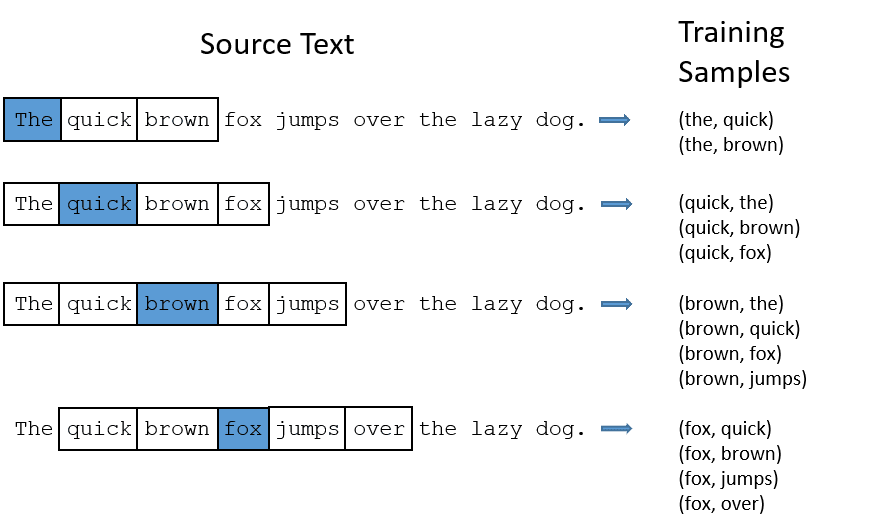
- CBOW toma una ventana de tamaño fijo (número) de palabras como 2 (2 a la izquierda y 2 a la derecha)
- Convierte a incrustación de palabras.
- CBOW promedia la incrustación de palabras.
- CBOW promedia la incrustación de la palabra con las palabras del contexto.
- El vector promediado intenta predecir una palabra objetivo utilizando una red neuronal.
Ahora, entendamos en qué se diferencia el skip-gram de la CBOW.
Skip-gram: Es un modelo de incrustación de palabras, pero funciona de forma diferente. En lugar de predecir la palabra objetivo, el skip-gram predice las palabras del contexto dadas las palabras objetivo.
Los skip-grams captan mejor las relaciones semánticas entre las palabras.
Ej- ‘Rey – Hombre Mujer = Reina’
Si desea trabajar con Word2Vec, tiene dos opciones: entrenar su propio modelo o utilizar un modelo preentrenado. Nosotros utilizaremos un modelo preentrenado.
Importar gensim
Puede instalar gensim utilizando pip install:
pip install gensimTokenice la frase utilizando word_tokenize:
FIrst, vamos a convertir las frases a bajo. Después, tokenizaremos nuestras frases utilizando word_tokenize.
# Importar las bibliotecas necesarias
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Frases de muestra
frases = [
"Me encanta thor
"Hulk es un miembro importante de los Vengadores",
"Ironman ayuda a Spiderman",
"Spiderman es uno de los miembros populares de los Vengadores",
]
# Tokenizar las frases
sentencias_tokenizadas = [palabra_tokenizada(sentencia.lower()) para sentencia en sentencias]
Vamos aentrenar nuestro modelo:
Entrenaremos nuestro modelo proporcionando frases tokenizadas. Estamos utilizando 5 ventanas para este modelo de entrenamiento, puede adaptarlo según sus necesidades.
# Entrenar un modelo Word2Vec
model = Word2Vec(sentences=frases_tokenizadas, vector_size=100, window=5, min_count=1, sg=0)
# Encontrar palabras similares
palabras_similares = modelo.wv.más_similares("vengadores")# Imprimir palabras similares
print("Palabras similares a 'vengadores':")
para palabra, puntuación en palabras_similares
print(f"{palabra}: {puntuación}")Palabras similares a ‘vengadores’:

A continuación se listan algunas palabras similares a «vengadores» mediante el modelo Word2Vec, junto con su puntuación de similitud.
El modelo calcula una puntuación de simil itud (en su mayoría, similitud coseno) entre los vectores de palabras de «vengadores» y otras palabras de su vocabulario. La puntuación de similitud indica lo estrechamente relacionadas que están dos palabras en el espacio vectorial.
Ej –
Aquí, la palabra «ayuda» tiene una similitud coseno de -0,005911458611011982 con la palabra «vengadores«. El valor negativo sugiere que podrían ser disímiles entre sí.
Los valores de similitud del coseno van de -1 a 1, donde:
- 1 indica que los dos vectores son idénticos y tienen una similitud positiva.
- Los valores cercanos a 1 indican una gran similitud positiva.
- Los valores cercanos a 0 indican que los vectores no están muy relacionados.
- Los valores cercanos a -1 indican una alta disimilitud.
- –1 indica que los dos vectores son totalmente opuestos y tienen una similitud negativa perfecta .
Visite este enlace si desea comprender mejor los modelos word2vec y una representación visual de su funcionamiento. Es una herramienta muy interesante para ver el CBOW y el skip-gram en acción.
Similar a Word2Vec, tenemos GloVe. GloVe puede producir incrustaciones que requieren menos memoria en comparación con Word2Vec. Vamos, a entender más sobre GloVe.
GloVe
Los vectores globales para la representación de palabras (GloVe) son una técnica como word2vec. Se utiliza para representar palabras como vectores en un espacio continuo. El concepto en el que se basa GloVe es el mismo que el de Word2Vec: produce incrustaciones contextuales de palabras teniendo en cuenta el rendimiento superior de Word2Vec.
¿Por qué necesitamos GloVe?
Word2vec es un método basado en ventanas, y utiliza las palabras cercanas para comprender las palabras. Esto significa que el significado semántico de la palabra objetivo sólo se ve afectado por las palabras que la rodean en las frases, lo que supone un uso ineficaz de las estadísticas.
Mientras que GloVe captura tanto las estadísticas globales como las locales para llegar a la incrustación de palabras.
¿Cuándo utilizar GloVe?
Utilice GloVe cuando desee una incrustación de palabras que capte relaciones semánticas más amplias y una asociación global de palabras.
GloVe es mejor que otros modelos en tareas de reconocimiento de entidades con nombre, analogía de palabras y similitud de palabras.
En primer lugar, necesitamos instalar Gensim:
pip install gensimPaso 1: Vamos a instalar bibliotecas importantes
# Importar las bibliotecas necesarias
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import gensim.downloader as api Paso 2: Importar el modelo Glove
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')Paso3: Recuperar la representación vectorial de la palabra ‘cute
guante_modelo["mono"]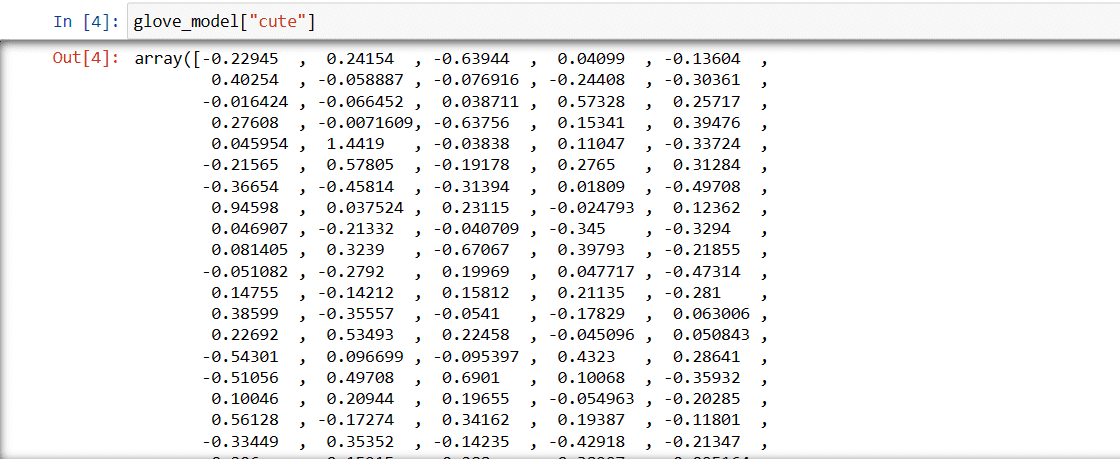
Estos valores capturan el significado de la palabra y sus relaciones con otras palabras. Los valores positivos indican asociaciones positivas con determinados conceptos, mientras que los negativos indican asociaciones negativas con otros conceptos.
En un modelo GloVe, cada dimensión del vector de palabras representa un determinado aspecto del significado o el contexto de la palabra.
Los valores negativos y positivos de estas dimensiones contribuyen a determinar cómo se relaciona semánticamente «mono» con otras palabras del vocabulario del modelo.
Los valores pueden ser diferentes para distintos modelos. Busquemos algunas palabras similares a la palabra «chico
Las 10 palabras similares que el modelo considera más parecidas a la palabra ‘chico
# encontrar palabra similar
glove_model.most_similar("chico")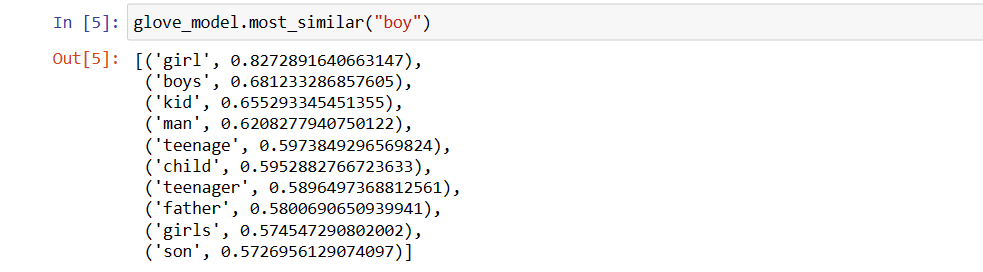
Como puede ver, la palabra más parecida a ‘chico’ es ‘chica’.
Ahora, intentaremos averiguar la precisión con la que el modelo obtendrá el significado semántico de las palabras proporcionadas.
glove_model.most_similar(positive=['chico', 'reina'], negative=['chica'], topn=1)
Nuestro modelo es capaz de encontrar la relación perfecta entre las palabras.
Defina la lista de vocabulario:
Ahora, intentemos comprender el significado semántico o la relación entre las palabras utilizando un gráfico. Defina la lista de palabras que desea visualizar.
# Defina la lista de palabras que desea visualizar
vocab = ["niño", "niña", "hombre", "mujer", "rey", "reina", "plátano", "manzana", "mango", "vaca", "coco", "naranja", "gato", "perro"]
Crear matriz de incrustación:
Vamos, escriba el código para crear la matriz de incrustación.
# Su código para crear la matriz de incrustación
EMBEDDING_DIM = glove_model.vectors.shape[1]
palabra_índice = {palabra: índice para índice, palabra en enumerar(vocab)}
num_palabras = len(vocab)
matriz_incrustación = np.ceros((número_palabras, DIM_INCUSIÓN))
para palabra, i en índice_palabra.elementos()
vector_incrustación = modelo_guante[palabra]
si vector_incrustación no es Ninguno
matriz_incrustación<x><x><x><x><x><x>[i]</x></x></x></x></x></x> = vector_incrustaciónDefina una función para la visualización t-SNE:
A partir de este código, definiremos la función para nuestro gráfico de visualización.
def tsne_plot(matriz_incrustada, palabras):
tsne_model = TSNE(perplejidad=3, n_componentes=2, init='pca', estado_aleatorio=42)
coordenadas = tsne_model.fit_transform(matriz_incrustada)
x, y = coordenadas[:, 0], coordenadas[:, 1]
plt.figure(figsize=(14, 8))
para i, palabra en enumerar(palabras)
plt.scatter(x<x><x><x><x><x><x>[i]</x></x></x></x></x></x>, y<x><x><x><x><x><x>[i]</x></x></x></x></x></x>)
plt.annotate(palabra,
xy=(x<x><x><x><x><x><x>[i]</x></x></x></x></x></x>, y<x><x><x><x><x><x>[i]</x></x></x></x></x></x>),
xytext=(2, 2),
textcoords='puntos de desplazamiento',
ha='derecha',
va='abajo')
plt.show()
Veamos qué aspecto tiene nuestro Plot:
# Llame a la función tsne_plot con su matriz de incrustación y su lista de palabras
tsne_plot(matriz_incrustación, vocab)
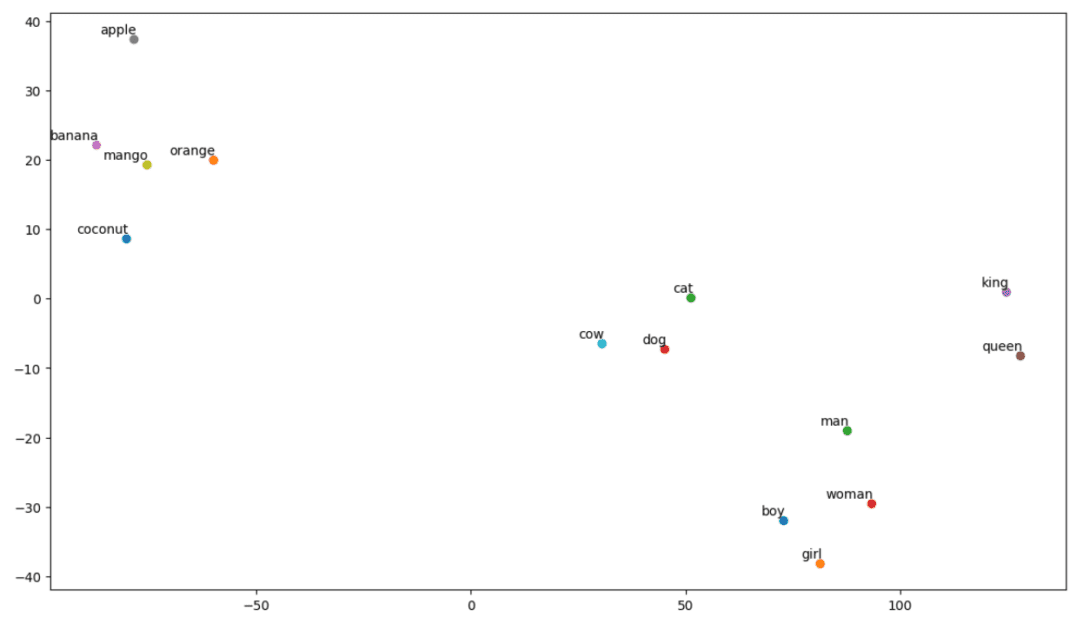
Así, como podemos ver, hay palabras como ‘ plátano’, ‘mango’, ‘naranja’, ‘coco’ y ‘manzana’ en el lado izquierdo de nuestro gráfico. Mientras que ‘vaca’, ‘perro’ y ‘gato ‘ son similares entre sí porque son animales.
Así pues, ¡nuestro modelo también puede encontrar el significado semántico y las relaciones entre las palabras!
Simplemente cambiando el vocabulario o creando su modelo desde cero, puede experimentar con diferentes palabras.
Puede utilizar esta matriz de incrustación como quiera. Puede aplicarse a tareas de similitud de palabras por sí sola o alimentar la capa de incrustación de una red neuronal.
GloVe se entrena en una matriz de co-ocurrencia para derivar el significado semántico. Se basa en la idea de que las co-ocurrencias palabra-palabra son una pieza esencial del conocimiento y que su uso es una forma eficaz de utilizar la estadística para producir incrustaciones de palabras. Así es como GloVe consigue añadir «estadística global» al producto final.
Y eso es GloVe; Otro método popular para la vectorización es FastText. Hablemos más sobre él.
FastText
FastText es una biblioteca de código abierto introducida por el equipo de investigación de IA de Facebook para la clasificación de textos y el análisis de sentimientos. FastText proporciona herramientas para entrenar la incrustación de palabras, que son vectores densos que representan palabras. Esto resulta útil para captar el significado semántico del documento. FastText admite la clasificación multietiqueta y multiclase.
¿Por qué FastText?
FastText es mejor que otros modelos por su capacidad de generalizar a palabras desconocidas, de la que carecían otros métodos. FastText proporciona vectores de palabras preentrenados para distintos idiomas, lo que podría ser útil en diversas tareas en las que necesitamos conocimientos previos sobre las palabras y su significado.
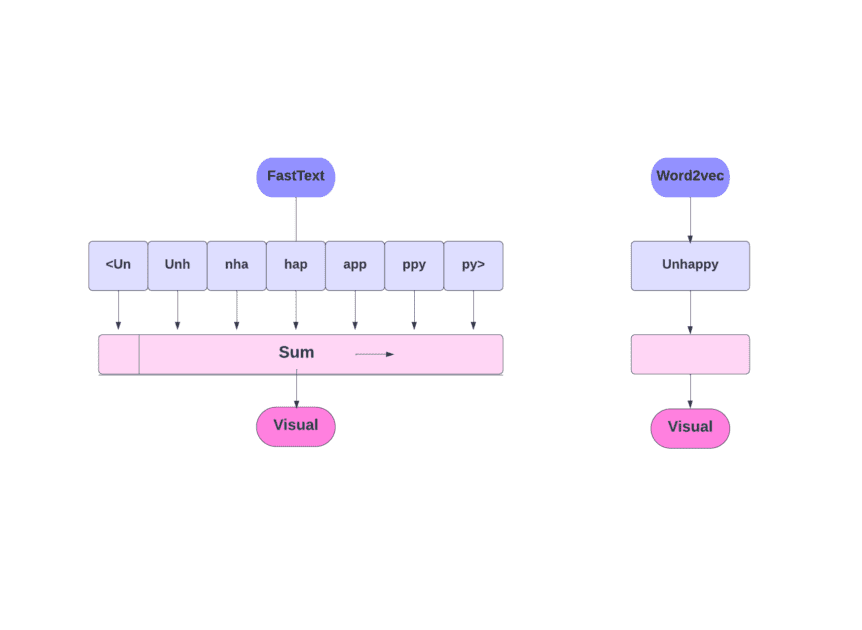
¿Cómo funciona?
Como ya hemos comentado, otros modelos, como Word2Vec y GloVe, utilizan palabras para la incrustación de palabras. Pero, el bloque de construcción de FastText son letras en lugar de palabras. Lo que significa que utilizan letras para la incrustación de palabras.
Utilizar caracteres en lugar de palabras tiene otra ventaja. Se necesitan menos datos para el entrenamiento. Como una palabra se convierte en su contexto, se puede extraer más información del texto.
La incrustación de palabras obtenida mediante FastText es una combinación de incrustaciones de nivel inferior.
Veamos ahora cómo utiliza FastText la información de las subpalabras.
Supongamos que tenemos la palabra «lectura». Para esta palabra, se generarían n-gramas de caracteres de longitud 3-6 como sigue:
- El principio y el final se indican mediante corchetes angulares.
- Se utiliza el hashing porque podría haber un gran número de n-gramas; en lugar de aprender una incrustación para cada n-grama distinto, aprendemos un total de B incrustaciones, donde B representa el tamaño del cubo. En el artículo original se utilizó el tamaño de cubo de 2 millones.
- Cada n-grama de caracteres, como «eadi», se asigna a un número entero entre 1 y B utilizando esta función hashing, y ese índice tiene la incrustación correspondiente.
- Al promediar estas incrustaciones de n-gramas constituyentes, se obtiene entonces la incrustación completa de la palabra.
- Aunque este enfoque de hashing da lugar a colisiones, ayuda a manejar en gran medida el tamaño del vocabulario.
- La red utilizada en FastText es similar a la de Word2Vec. Al igual que allí, podemos entrenar FastText en dos modos: CBOW y skip-gram. Por lo tanto, no necesitamos repetir esa parte aquí de nuevo.
Puede entrenar su propio modelo o puede utilizar un modelo preentrenado. Nosotros vamos a utilizar un modelo preentrenado.
En primer lugar, necesita instalar FastText.
pip install fasttextUtilizaremos un conjunto de datos que consiste en texto conversacional relativo a unos cuantos fármacos, y tenemos que clasificar esos textos en 3 tipos. Como el tipo de drogas con el que están asociados.

Ahora, para entrenar un modelo FastText en cualquier conjunto de datos, tenemos que preparar los datos de entrada en un formato determinado, que es:
__etiqueta__<valor de la etiqueta><espacio><punto de datos asociado>
Hagamos esto también para nuestro conjunto de datos.
all_texts = tren['texto'].tolist()
all_labels = tren['tipo de fármaco'].tolist()
prep_datapoints=[]
for i in range(len(todos_textos)):
sample = '__label__' str(all_labels<x><x><x><x><x><x>[i]</x></x></x></x></x></x>) ' ' all_texts<x><x><x><x><x><x>[i]</x></x></x></x></x></x>
prep_datapoints.append(muestra)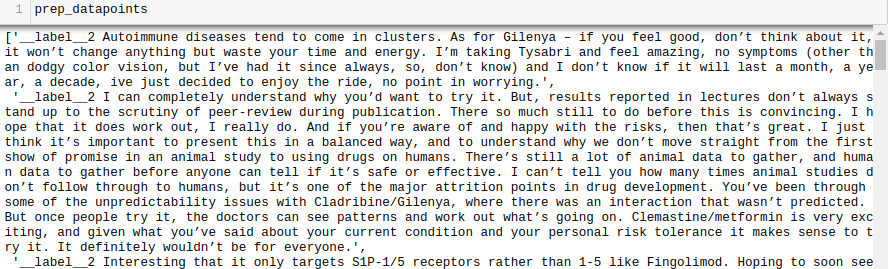
Omitimos mucho preprocesamiento en este paso. De lo contrario, nuestro artículo sería demasiado grande. En los problemas del mundo real, es mejor hacer el preprocesamiento para que los datos sean adecuados para el modelado.
Ahora, escriba los puntos de datos preparados en un archivo .txt.
con open('train_fasttext.txt','w') como f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Entrenemos nuestro modelo
model = fasttext.train_supervised('train_fasttext.txt')Obtendremos predicciones de nuestro modelo.

El modelo predice la etiqueta y le asigna una puntuación de confianza.
Como con cualquier otro modelo, el rendimiento de éste depende de diversas variables, pero si quiere hacerse una idea rápida de cuál es la precisión esperada, FastText puede ser una gran opción.
Conclusión
En conclusión, los métodos de vectorización de texto como Bag of Words (BoW), TF-IDF, Word2Vec, GloVe y FastText proporcionan una gran variedad de capacidades para las tareas de PNL.
Mientras que Word2Vec captura la semántica de las palabras y es adaptable a diversas tareas de PNL, BoW y TF-IDF son sencillos y adecuados para la clasificación y recomendación de textos.
Para aplicaciones como el análisis de sentimientos, GloVe ofrece incrustaciones preentrenadas, y FastText se desenvuelve bien en el análisis a nivel de subpalabra, lo que lo hace útil para las lenguas estructuralmente ricas y el reconocimiento de entidades.
La elección de la técnica depende de la tarea, los datos y los recursos. Trataremos más a fondo las complejidades de la PNL a medida que avance esta serie. ¡Feliz aprendizaje!
A continuación, consulte los mejores cursos de PNL para aprender el Procesamiento del Lenguaje Natural.