
¿Está interesado en analizar sus datos utilizando lenguaje natural? Aprenda a hacerlo utilizando la biblioteca de Python PandasAI.
En un mundo en el que los datos son cruciales, comprenderlos y analizarlos es esencial. Sin embargo, el análisis tradicional de datos puede resultar complejo. Ahí es donde entra PandasAI. Simplifica el análisis de datos permitiéndole hablar con sus datos utilizando lenguaje natural.
Pandas AI funciona convirtiendo sus preguntas en código para el análisis de datos. Se basa en la popular biblioteca de Python Pandas. PandasAI es una biblioteca de Python que amplía pandas, la conocida herramienta de análisis y manipulación de datos, con funciones de IA generativa. Está pensada para complementar a pandas en lugar de sustituirla.
PandasAI introduce un aspecto conversacional a pandas (así como a otras bibliotecas de análisis de datos ampliamente utilizadas), permitiéndole interactuar con sus datos mediante consultas en lenguaje natural.
Este tutorial le guiará por los pasos necesarios para configurar Pandas AI, utilizarlo con un conjunto de datos del mundo real, crear gráficos, explorar atajos y explorar los puntos fuertes y las limitaciones de esta potente herramienta.
Tras completarlo, será capaz de realizar análisis de datos de forma más fácil e intuitiva utilizando el lenguaje natural.
Así pues, ¡exploremos el fascinante mundo del análisis de datos en lenguaje natural con Pandas AI!
Configuración de su entorno
Para empezar con PandasAI, debe comenzar por instalar la biblioteca PandasAI.
Estoy utilizando un Jupyter Notebook para este proyecto. Pero puede utilizar Google Collab o VS Code según sus necesidades.
Si planea utilizar Modelos de Lenguaje Grande (LLMs) de Open AI, también es importante instalar el SDK Python de Open AI para una experiencia sin problemas.
# Instalación de Pandas AI
!pip install pandas-ai
# Pandas AI utiliza los modelos de lenguaje de OpenAI, por lo que necesita instalar el SDK de OpenAI Python
!pip install openaiAhora, vamos a importar todas las librerías necesarias:
# Importando las librerías necesarias
import pandas as pd
import numpy as np
# Importar PandasAI y sus componentes
from pandasai import PandasAI, SmartDataframe
from pandasai.llm.openai import OpenAIUn aspecto clave del análisis de datos utilizando PandasAI es la clave API. Esta herramienta es compatible con varios modelos de grandes lenguajes (LLM) y modelos LangChains, que se utilizan para generar código a partir de consultas en lenguaje natural. Esto hace que el análisis de datos sea más accesible y fácil de usar.
PandasAI es versátil y puede trabajar con varios tipos de modelos. Entre ellos se incluyen los modelos Hugging Face, Azure OpenAI, Google PALM y Google VertexAI. Cada uno de estos modelos aporta sus propios puntos fuertes, mejorando las capacidades de PandasAI.
Recuerde que para utilizar estos modelos, necesitará las claves API adecuadas. Estas claves autentican sus peticiones y le permiten aprovechar la potencia de estos modelos lingüísticos avanzados en sus tareas de análisis de datos. Por lo tanto, asegúrese de tener sus claves API a mano cuando configure PandasAI para sus proyectos.
Puede obtener la clave de la API y exportarla como una variable de entorno.
En el siguiente paso, aprenderá a utilizar PandasAI con diferentes tipos de grandes modelos de lenguaje (LLMs) de OpenAI y Hugging Face Hub.
Uso de grandes modelos de lenguaje
Puede elegir un LLM instanciando uno y pasándolo al constructor SmartDataFrame o SmartDatalake, o puede especificar uno en el archivo pandasai.json.
Si el modelo espera uno o más parámetros, puede pasárselos al constructor o especificarlos en el archivo pandasai.json en el parámetro llm_options, como se indica a continuación:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}¿Cómo utilizar los modelos OpenAI?
Para poder utilizar los modelos de OpenAI, necesita tener una clave de API de OpenAI. Puede obtener una aquí.
Una vez que tenga una clave API, puede utilizarla para instanciar un objeto OpenAI:
#Hemos importado todas las librerías necesarias en el paso anterior
llm = OpenAI(api_token="mi-clave-api")
pandas_ai = SmartDataframe("datos.csv", config={"llm": llm})No olvide sustituir «my-api-key» por su clave API original
Como alternativa, puede establecer la variable de entorno OPENAI_API_KEY e instanciar el objeto OpenAI sin pasar la clave de API:
# Establezca la variable de entorno OPENAI_API_KEY
llm = OpenAI() # no es necesario pasar la clave API, se leerá de la variable de entorno
pandas_ai = SmartDataframe("datos.csv", config={"llm": llm})Si está detrás de un proxy explícito, puede especificar openai_proxy al instanciar el objeto OpenAI o establecer la variable de entorno OPENAI_PROXY para que lo atraviese.
Nota importante: Cuando utilice la biblioteca PandasAI para el análisis de datos con su clave API, es importante que lleve un registro del uso de su token para gestionar los costes.
¿Se pregunta cómo hacerlo? Simplemente ejecute el siguiente código de contador de tokens para obtener una imagen clara del uso de su token y los cargos correspondientes. De este modo, podrá gestionar eficazmente sus recursos y evitar sorpresas en su facturación.
Puede contar el número de tokens utilizados por una solicitud de la siguiente manera:
"""Ejemplo de uso de PandasAI con un marco de datos pandas""""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False se supone que muestra un menor uso y coste
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
con get_openai_callback() como cb:
response = df.chat("Calcular la suma del pib de los países norteamericanos")
print(respuesta)
print(cb)Obtendrá resultados como estos
# La suma del PIB de los países de América del Norte es de 19.294.482.071.552.
# Fichas utilizadas: 375
# Fichas de solicitud: 210
# Fichas de finalización: 165
# Coste total (USD): $ 0.000750¡No olvide llevar un registro de su coste total si tiene un crédito limitado!
¿Cómo utilizar Hugging Face Models?
Para poder utilizar los modelos de HuggingFace, necesita tener una clave API de HuggingFace. Puede crear una cuenta HuggingFace aquí y obtener una clave API aquí.
Una vez que tenga una clave API, puede utilizarla para instanciar uno de los modelos HuggingFace.
Por el momento, PandasAI soporta los siguientes modelos HuggingFace:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="mi-cara-abrazable-api-key")
# o
llm = Falcon(api_token="mi-huggingface-api-key")
df = SmartDataframe("datos.csv", config={"llm": llm})Como alternativa, puede establecer la variable de entorno HUGGINGFACE_API_KEY e instanciar el objeto HuggingFace sin pasar la clave API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no es necesario pasar la clave API, se leerá de la variable de entorno
# o
llm = Falcon() # no es necesario pasar la clave API, se leerá de la variable de entorno
df = SmartDataframe("datos.csv", config={"llm": llm})Starcoder y Falcon son modelos LLM disponibles en Hugging Face.
Hemos configurado con éxito nuestro entorno y explorado cómo utilizar tanto los modelos LLM de OpenAI como los de Hugging Face. Ahora, sigamos adelante con nuestro viaje de análisis de datos.
Vamos a utilizar el conjunto de datos Big Mart Sales data, que contiene información sobre las ventas de varios productos en diferentes puntos de venta de Big Mart. El conjunto de datos tiene 12 columnas y 8524 filas. Obtendrá el enlace al final del artículo.
Análisis de datos con PandasAI
Ahora que hemos instalado e importado correctamente todas las librerías necesarias, procedamos a cargar nuestro conjunto de datos.
Cargar el conjunto de datos
Puede elegir un LLM instanciando uno y pasándolo al SmartDataFrame. Obtendrá el enlace al conjunto de datos al final del artículo.
#Cargue el conjunto de datos desde el dispositivo
ruta = r "D:\Pandas AI\Train.csv"
df = SmartDataframe(ruta)Utilizar el modelo LLM de OpenAI
Después de cargar nuestros datos Voy a utilizar el modelo LLM de OpenAI para utilizar PandasAI
llm = OpenAI(api_token="API_Key")
pandas_ai = PandasAI(llm, conversational=False)¡Todo bien! Ahora, probemos a utilizar prompts.
Imprima las 6 primeras filas de nuestro conjunto de datos
Intentemos cargar las 6 primeras filas, proporcionando instrucciones:
Resultado = pandas_ai(df, "Mostrar las 6 primeras filas de datos en forma tabular")
Resultado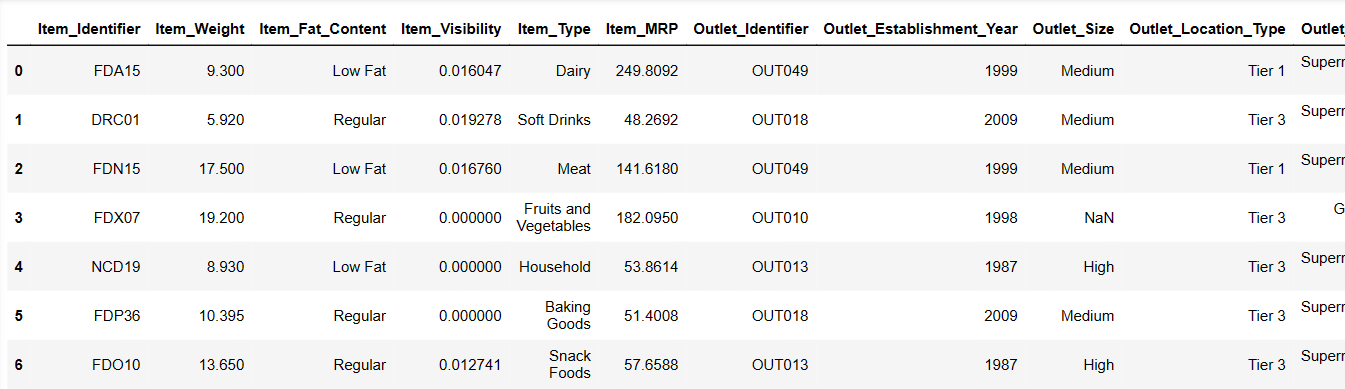
¡Eso fue realmente rápido! Vamos a entender nuestro conjunto de datos.
Generación de estadísticas descriptivas de DataFrame
# Obtener estadísticas descriptivas
Resultado = pandas_ai(df, "Mostrar la descripción de los datos en forma tabular")
Resultado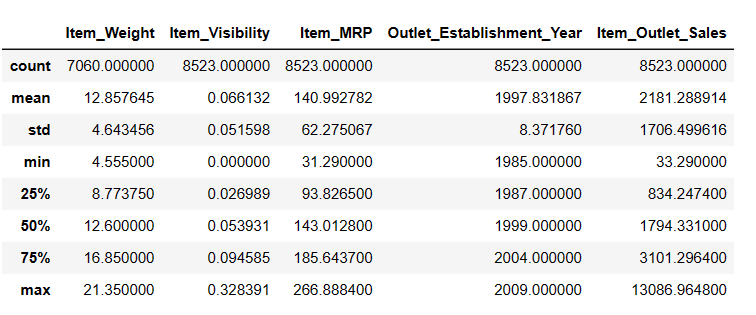
Hay 7060 valores en Item_Weigth; tal vez haya algunos valores perdidos.
Encontrar valores perdidos
Hay dos formas de encontrar valores perdidos utilizando pandas ai.
#Encontrar valores perdidos
Resultado = pandas_ai(df, "Mostrar los valores perdidos de los datos en forma tabular")
Resultado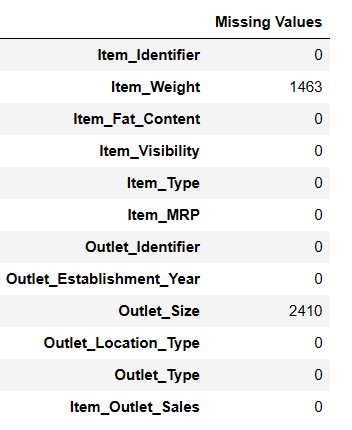
#Acceso directo para la limpieza de datos
df = SmartDataframe('datos.csv')
df.limpiar_datos()Este atajo hará la limpieza de datos en el marco de datos.
Ahora, rellenemos los valores nulos que faltan.
Rellenar valores nulos
#Rellenar valores nulos
result = pandas_ai(df, "Rellene los valores nulos Peso del artículo con la mediana y Tamaño de salida del artículo con la moda y Muestre los valores perdidos de los datos en forma tabular")
resultado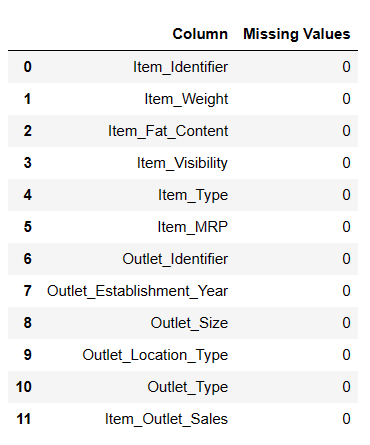
Es un método útil para rellenar valores nulos, pero me encontré con algunos problemas al rellenar valores nulos.
# Atajo para rellenar valores nulos
df = SmartDataframe('datos.csv')
df.impute_valores_que_faltan()Este atajo imputará los valores perdidos en el marco de datos.
Eliminar valores nulos
Si desea eliminar todos los valores nulos de su df, puede probar este método.
result = pandas_ai(df, "Eliminar la fila con valores perdidos con inplace=True")
resultadoEl análisis de datos es esencial para identificar tendencias, tanto a corto como a largo plazo, lo que puede ser muy valioso para empresas, gobiernos, investigadores y particulares.
Intentemos encontrar una tendencia general de las ventas a lo largo de los años desde su establecimiento.
Encontrar la tendencia de las ventas
# Hallar la tendencia de las ventas
resultado = pandas_ai(df, "¿Cuál es la tendencia general de las ventas a lo largo de los años desde el establecimiento del punto de venta?")
resultado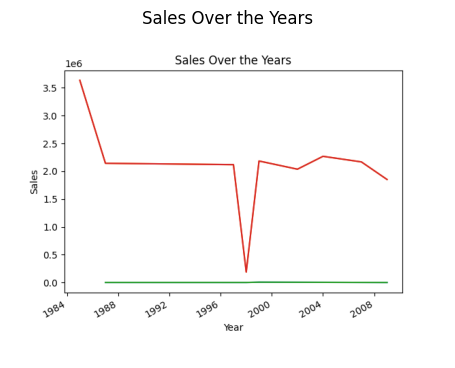
El proceso inicial de creación de gráficos fue un poco lento, pero después de reiniciar el núcleo y ejecutarlo todo, funcionó más rápido.
# Acceso directo para trazar gráficos de líneas
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])Este método abreviado trazará un gráfico de líneas del marco de datos.
Quizá se pregunte por qué hay un descenso en la tendencia. Se debe a que no tenemos datos de 1989 a 1994.
Encontrar el año de mayores ventas
Ahora, averigüemos qué año tiene las ventas más altas.
# Hallar el año de mayores ventas
resultado = pandas_ai(df, "Explicar qué años tienen mayores ventas")
resultado
Así pues, el año con mayores ventas es 1985.
Pero, quiero averiguar qué tipo de artículo genera las ventas medias más altas y qué tipo genera las ventas medias más bajas.
Ventas medias más altas y más bajas
# Hallar la venta media más alta y más baja
result = pandas_ai(df, "¿Qué tipo de artículo genera las ventas medias más altas y cuál las más bajas?")
resultado
Los alimentos con almidón tienen las ventas medias más altas y Otros tiene las ventas medias más bajas. Si no desea que Otros tenga las ventas más bajas, puede mejorar el resultado según sus necesidades.
¡Magnífico! Ahora quiero averiguar la distribución de las ventas entre los distintos puntos de venta.
Distribución de las ventas entre los distintos puntos de venta
Existen cuatro tipos de puntos de venta: Supermercados tipo 1/2/3 y tiendas de ultramarinos.
# Distribución de las ventas entre los distintos tipos de puntos de venta desde el establecimiento
response = pandas_ai(df, "Visualizar la distribución de las ventas entre los distintos tipos de puntos de venta desde el establecimiento mediante un diagrama de barras, tamaño del diagrama=(13,10)")
respuesta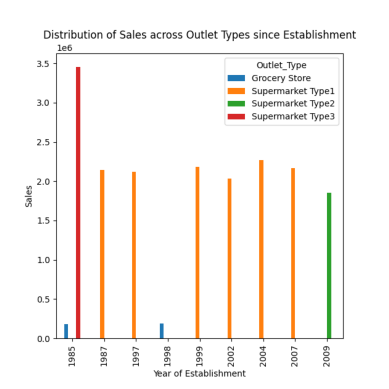
Como se ha observado en las indicaciones anteriores, el pico de ventas se produjo en 1985, y este gráfico destaca las mayores ventas en 1985 de los puntos de venta de tipo supermercado 3.
# Atajo para trazar gráfico de barras
df = SmartDataframe('datos.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])Este atajo trazará un gráfico de barras del marco de datos.
# Atajo para trazar un histograma
df = SmartDataframe('datos.csv')
df.trazar_histograma(columna = 'a')Este atajo trazará un histograma del marco de datos.
Ahora, averigüemos cuáles son las ventas medias de los artículos con contenido de grasa «Bajo en grasa» y «Normal».
Hallar las ventas medias de los artículos con contenido de grasa
# Encontrar el índice de una fila utilizando el valor de una columna
result = pandas_ai(df, "¿Cuál es el promedio de ventas para los artículos con 'Bajo contenido en grasa' y 'Regular' contenido en grasa?")
resultado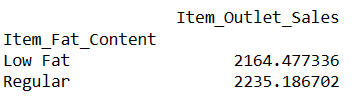
Escribir preguntas como ésta le permite comparar dos o más productos.
Ventas medias de cada tipo de artículo
Quiero comparar todos los productos con sus ventas medias.
#Ventas medias para cada tipo de artículo
result = pandas_ai(df, "¿Cuáles son las ventas medias de cada tipo de artículo en los últimos 5 años?, use gráfico circular, size=(6,6)")
resultado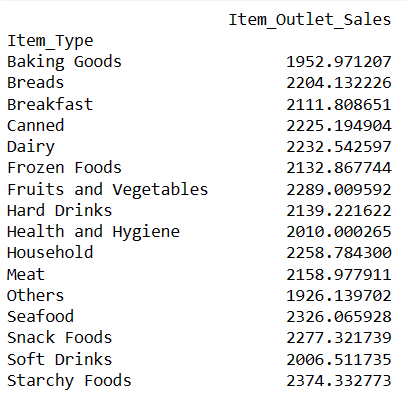
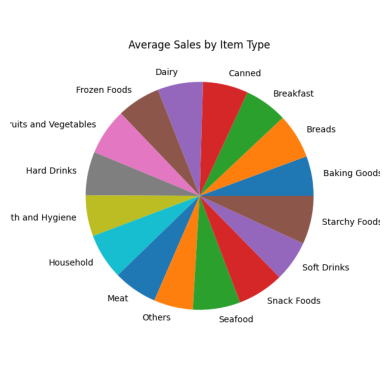
Todas las secciones del gráfico circular parecen similares porque tienen casi las mismas cifras de ventas.
# Atajo para trazar el gráfico circular
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])Este método abreviado trazará un gráfico circular del marco de datos.
Los 5 tipos de artículos más vendidos
Aunque ya hemos comparado todos los productos en función de las ventas medias, ahora me gustaría identificar los 5 artículos con mayores ventas.
#Hallar los 5 artículos con mayores ventas
result = pandas_ai(df, "¿Cuáles son los 5 tipos de artículos más vendidos en función de las ventas medias? Escribir en forma de tabla")
resultado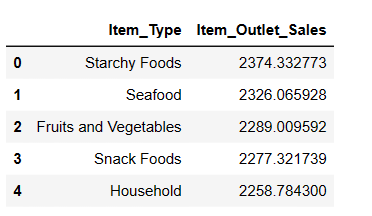
Como era de esperar, los alimentos con almidón son el artículo más vendido en función de las ventas medias.
Los 5 tipos de artículos que menos se venden
resultado = pandas_ai(df, "¿Cuáles son los 5 tipos de artículos que menos se venden en función de las ventas medias?")
resultado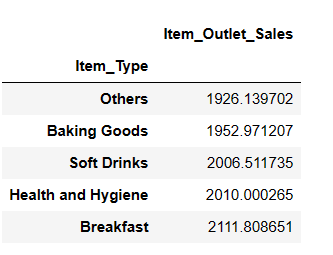
Puede que le sorprenda ver refrescos en la categoría de artículos menos vendidos. Sin embargo, es esencial tener en cuenta que estos datos sólo llegan hasta 2008, y la tendencia de los refrescos despegó unos años más tarde.
Ventas de las categorías de productos
Aquí, utilicé la palabra «categoría de producto» en lugar de «tipo de artículo», y PandasAI siguió creando los gráficos, mostrando su comprensión de palabras similares.
result = pandas_ai(df, "Dar un gráfico de barras apiladas de gran tamaño de las ventas de las distintas categorías de productos durante el último ejercicio")
resultado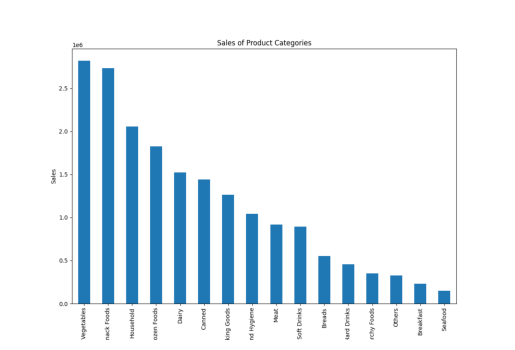
Puede observar que cuando escribimos una instrucción y proporcionamos instrucciones a una PandasAI, ésta proporciona resultados basados únicamente en esa instrucción específica. No analiza sus prompt anteriores para ofrecer respuestas más precisas.
Sin embargo, con la ayuda de un agente de chat, también puede conseguir esta funcionalidad.
Agente de chat
Con el agente de chat, puede entablar conversaciones dinámicas en las que el agente conserva el contexto durante toda la conversación. Esto le permite mantener intercambios más interactivos y significativos.
Las características clave que potencian esta interacción incluyen la Retención del contexto, en la que el agente recuerda el historial de la conversación, lo que permite interacciones fluidas y conscientes del contexto. Puede utilizar el método Preguntas aclaratorias para solicitar aclaraciones sobre cualquier aspecto de la conversación, asegurándose de que entiende perfectamente la información proporcionada.
Además, el método Explicar está disponible para obtener explicaciones detalladas de cómo el agente llegó a una solución o respuesta concreta, ofreciendo transparencia y conocimientos sobre el proceso de toma de decisiones del agente.
Siéntase libre de iniciar conversaciones, buscar aclaraciones y explorar explicaciones para mejorar sus interacciones con el agente del chat
from pandasai import Agente
agente = Agente(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Cuáles son los 5 artículos con mayor MRP")
resultado
A diferencia de un SmartDataframe o un SmartDatalake, un agente mantendrá un seguimiento del estado de la conversación y podrá responder a conversaciones de varios turnos.
Pasemos a las Ventajas y Limitaciones de PandasAI
Ventajas de PandasAI
El uso de Pandas AI ofrece varias ventajas que lo convierten en una valiosa herramienta para el análisis de datos, como por ejemplo
- Accesibilidad: PandasAI simplifica el análisis de datos, haciéndolo accesible a un amplio abanico de usuarios. Cualquiera, independientemente de su formación técnica, puede utilizarla para extraer información de los datos y responder a preguntas de negocio.
- Consultas en lenguaje natural: La posibilidad de formular preguntas directamente y recibir respuestas de los datos mediante consultas en lenguaje natural facilita la exploración y el análisis de los datos. Esta función permite que incluso los usuarios sin conocimientos técnicos interactúen con los datos de forma eficaz.
- Función de chat conagentes: La función de chat permite a los usuarios interactuar con los datos de forma interactiva, mientras que la función de chat con agente aprovecha el historial de chat anterior para ofrecer respuestas contextualizadas. Esto promueve un enfoque dinámico y conversacional del análisis de datos.
- Visualización de datos: PandasAI proporciona una gama de opciones de visualización de datos, incluyendo mapas de calor, gráficos de dispersión, gráficos de barras, gráficos circulares, gráficos de líneas, y mucho más. Estas visualizaciones ayudan a comprender y presentar los patrones y tendencias de los datos.
- Atajosque ahorran tiempo: La disponibilidad de atajos y funciones de ahorro de tiempo agiliza el proceso de análisis de datos, ayudando a los usuarios a trabajar de forma más eficiente y eficaz.
- Compatibilidad de archivos: PandasAI es compatible con varios formatos de archivo, incluyendo CSV, Excel, Google Sheets, y más. Esta flexibilidad permite a los usuarios trabajar con datos de diversas fuentes y formatos.
- Avisospersonalizados: Los usuarios pueden crear avisos personalizados utilizando instrucciones sencillas y código Python. Esta función permite a los usuarios adaptar sus interacciones con los datos a necesidades y consultas específicas.
- Guardarcambios: La posibilidad de guardar los cambios realizados en los marcos de datos garantiza la conservación de su trabajo y le permite volver a visitar y compartir su análisis en cualquier momento.
- Respuestaspersonalizadas: La opción de crear respuestas personalizadas permite a los usuarios definir comportamientos o interacciones específicos, haciendo que la herramienta sea aún más versátil.
- Integración de modelos: PandasAI es compatible con varios modelos lingüísticos, incluidos los de Hugging Face, Azure, Google Palm, Google VertexAI y los modelos LangChain. Esta integración mejora las capacidades de la herramienta y permite un procesamiento y comprensión avanzados del lenguaje natural.
- Compatibilidad integrada con LangChain: La compatibilidad integrada con los modelos LangChain amplía aún más la gama de modelos y funcionalidades disponibles, mejorando la profundidad del análisis y las perspectivas que pueden derivarse de los datos.
- Comprensión de nombres: PandasAI demuestra la capacidad de comprender la correlación entre los nombres de las columnas y la terminología de la vida real. Por ejemplo, aunque utilice términos como «categoría de producto» en lugar de «tipo de artículo» en sus preguntas, la herramienta puede seguir proporcionando resultados relevantes y precisos. Esta flexibilidad a la hora de reconocer sinónimos y asignarlos a las columnas de datos adecuadas mejora la comodidad del usuario y la adaptabilidad de la herramienta a las consultas en lenguaje natural.
Aunque PandasAI ofrece varias ventajas, también presenta algunas limitaciones y retos que los usuarios deben conocer:
Limitaciones de PandasAI
He aquí algunas limitaciones que he observado:
- Requisito de clave API: Para utilizar PandasAI, es esencial disponer de una clave API. Si no dispone de créditos suficientes en su cuenta de OpenAI, es posible que no pueda utilizar el servicio. Sin embargo, vale la pena señalar que OpenAI proporciona un crédito de 5 dólares para los nuevos usuarios, lo que lo hace accesible para aquellos que son nuevos en la plataforma.
- Tiempo de procesamiento: En ocasiones, el servicio puede experimentar retrasos a la hora de proporcionar resultados, lo que puede atribuirse a un uso elevado o a la carga del servidor. Los usuarios deben estar preparados para posibles tiempos de espera cuando consulten el servicio.
- Interpretación de las indicaciones: Aunque se pueden hacer preguntas a través de prompts, la capacidad del sistema para explicar las respuestas puede no estar completamente desarrollada, y la calidad de las explicaciones puede variar. Este aspecto de PandasAI puede mejorar en el futuro con un mayor desarrollo.
- Sensibilidad de las instrucciones: Los usuarios deben tener cuidado a la hora de elaborar las instrucciones, ya que incluso pequeños cambios pueden conducir a resultados diferentes. Esta sensibilidad al fraseo y a la estructura de las instrucciones puede afectar a la coherencia de los resultados, especialmente cuando se trabaja con gráficos de datos o consultas más complejas.
- Limitaciones en las instrucciones complejas: Es posible que PandasAI no maneje peticiones o consultas muy complejas con la misma eficacia que otras más sencillas. Los usuarios deben ser conscientes de la complejidad de sus preguntas y asegurarse de que la herramienta se adapta a sus necesidades específicas.
- Cambios inconsistentes en DataFrame: Los usuarios han informado de problemas a la hora de realizar cambios en los DataFrames, como rellenar valores nulos o eliminar filas con valores nulos, incluso cuando se especifica ‘Inplace=True’ Esta incoherencia puede resultar frustrante para los usuarios que intentan modificar sus datos.
- Resultados variables: Cuando se reinicia un núcleo o se vuelven a ejecutar las consultas, es posible recibir resultados o interpretaciones diferentes de los datos de ejecuciones anteriores. Esta variabilidad puede ser un reto para los usuarios que requieren resultados consistentes y reproducibles. No aplicable a todas las preguntas.
Puede descargar el conjunto de datos aquí.
El código está disponible en GitHub.
Conclusión
PandasAI ofrece un enfoque fácil de usar para el análisis de datos, accesible incluso para aquellos sin amplios conocimientos de codificación.
En este artículo, he cubierto cómo configurar y utilizar PandasAI para el análisis de datos, incluyendo la creación de gráficos, el manejo de valores nulos y el aprovechamiento de la funcionalidad de chat del agente.
Suscríbase a nuestro boletín para recibir más artículos informativos. Puede que le interese aprender sobre los modelos de IA para crear IA generativa.