Prometheus es un sistema de monitorización de código abierto basado en métricas. Recopila datos de servicios y hosts enviando peticiones HTTP en puntos finales de métricas. A continuación, almacena los resultados en una base de datos de series temporales y los pone a disposición para su análisis y alerta.
¿Por qué monitorizar?
- Permite alertar cuando las cosas van mal, preferiblemente antes de que vayan mal. Para que alguien pueda echarle un vistazo.
- Proporciona información para permitir el análisis, la depuración y la resolución del problema.
- Le permite ver tendencias/cambios a lo largo del tiempo. Por ejemplo, cuántas sesiones activas hay en un momento dado. Esto ayuda a tomar decisiones de diseño y a planificar la capacidad.
La monitorización suele estar relacionada con eventos. Un evento podría incluir la recepción de una solicitud HTTP, el envío de una respuesta, la lectura desde el disco, el inicio de sesión de un usuario. La supervisión de un sistema podría incluir la creación de perfiles, el registro, el rastreo, las métricas, las alertas y la visualización.
Monitorización de caja negra frente a caja blanca
La monitorización se divide en dos categorías principales:
Supervisión de caja negra
En la supervisión de caja negra, la supervisión se realiza a nivel de la aplicación o del host, ya que se observan desde el exterior. Esto puede ser bastante limitante.
Supervisión de caja blanca
La monitorización de caja blanca significa monitorizar los componentes internos de un servicio. Expondría datos sobre el estado y el rendimiento de los componentes internos.
Las cuatro señales de oro
Según Google, si sólo puede medir cuatro métricas de su sistema de cara al usuario, céntrese en las cuatro siguientes, denominadas las cuatro señales de oro:
#1. Latencia
El tiempo que se tarda en servir una solicitud -con éxito o fallida-. Es importante hacer un seguimiento no sólo de las solicitudes exitosas, sino también de las fallidas.
#2. Tráfico
Una medida de cuánta demanda se está haciendo a su sistema. Para un servicio web, suele tratarse de peticiones HTTP por segundo.
#3. Errores
La tasa de peticiones que fallan.
#4. Saturación
El grado de saturación de su servicio. El aumento de la latencia suele ser un indicador importante de la saturación. Muchos sistemas degradan su rendimiento mucho antes de alcanzar el 100% de utilización.
Tipos de métricas de Prometheus
Las métricas de Prometheus son de cuatro tipos principales :
#1. Contador
El valor de un contador siempre aumentará. Nunca puede disminuir, pero puede ponerse a cero. Por lo tanto, si un raspado falla, sólo significa que se ha perdido un punto de datos. El incremento acumulado estaría disponible en la siguiente lectura. Ejemplos:
- Número total de peticiones HTTP recibidas
- Número de excepciones.
#2. Medidor
Una galga es una instantánea en un momento dado. Puede tanto aumentar como disminuir. Si falla una obtención de datos, se pierde una muestra; la siguiente obtención podría mostrar un valor diferente: ejemplos de espacio en disco, uso de memoria.
#3. Histograma
Un histograma muestrea observaciones y las cuenta en cubos configurables. Se utilizan para cosas como la duración de las solicitudes o el tamaño de las respuestas. Por ejemplo, podría medir la duración de la solicitud para una solicitud HTTP específica. El histograma tendrá un conjunto de cubos, digamos 1 ms, 10 ms y 25 ms. En lugar de almacenar cada duración para cada solicitud, Prometheus almacenará la frecuencia de las solicitudes que caen en un cubo particular.
#4. Resumen
Similar al histograma, muestrea observaciones, normalmente duraciones de solicitud o tamaños de respuesta. Proporcionará un recuento total de observaciones y una suma de todos los valores observados, lo que le permitirá calcular la media de los valores observados. Por ejemplo, en un minuto, tuvo tres peticiones que tardaron 2,3,4 segundos. La suma sería 9 y el recuento 3. La latencia sería de 3 segundos.
Componentes del ecosistema Prometheus
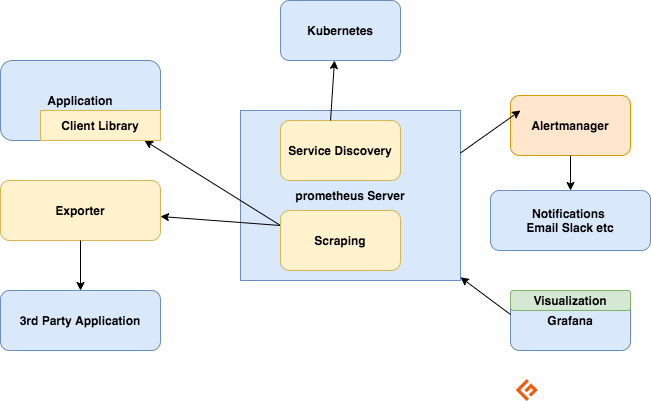
El servidor Prometheus
Recopila métricas, las almacena y las pone a disposición para su consulta, envía alertas basadas en las métricas recopiladas.
Raspado
Prometheus es un sistema basado en pull. Para obtener métricas, Prometheus envía una solicitud HTTP denominada «scrape». Envía scrapes a objetivos basados en su configuración.
Cada objetivo (definido estáticamente, o descubierto dinámicamente) es scrapeado a un intervalo regular (intervalo scrape). Cada scrape lee el endpoint HTTP /metrics para obtener el estado actual de las métricas del cliente y persiste los valores en la base de datos de series temporales de Prometheus.
Existen más bases de datos de series temporales para soluciones de monitorización que quizá desee explorar.
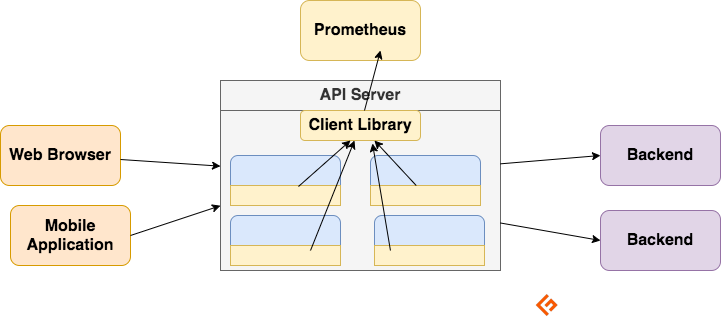
Bibliotecas de clientes
Para monitorizar un servicio, necesita añadir instrumentación a su código. Existen bibliotecas cliente disponibles para todos los lenguajes y tiempos de ejecución populares. Utilizando estas bibliotecas, una vez que añada unas pocas líneas de código, su código puede empezar a emitir métricas. Esto se denomina instrumentación directa. Estas bibliotecas le permiten definir métricas internas y también exponerlas a través de un punto final HTTP. Cuando Prometheus rastrea el punto final HTTP de métricas, la biblioteca cliente envía las métricas al servidor.
Prometheus ofrece bibliotecas cliente oficiales para Go, Java, Python y Ruby. Prometheus tiene un ecosistema abierto. También hay bibliotecas cliente construidas por la comunidad disponibles para C, PHP, Node.js, C#/.NET y muchos otros.
Exportadores
Muchas aplicaciones exponen métricas en un formato que no es el de Prometheus. Para éstas y para las aplicaciones que no posea o para las que no tenga acceso al código, no podrá añadir instrumentación directamente. Por ejemplo, MySQL, Kafka, JMX, HAProxy y el servidor NGINX. En estos escenarios, usted hace uso de exportadores.
Un exportador es una herramienta que despliega junto con la aplicación de la que desea obtener métricas. Un exportador actúa como un proxy entre la aplicación y Prometheus. Recibirá peticiones del servidor de Prometheus, recopilará datos de los registros de acceso, registros de errores de la aplicación, los transformará en el formato correcto y, finalmente, los devolverá al servidor de Prometheus.
Algunos de los exportadores más populares son:
- Windows – para métricas de servidores Windows
- Node – para métricas de servidores Linux
- Blackbox – para métricas de rendimiento de DNS y sitios web
- JMX – para métricas de aplicaciones basadas en Java
Una vez que las aplicaciones han sido instrumentadas, o los exportadores están en su lugar, usted necesita decirle a Prometheus, dónde están. Esto puede hacerse mediante una configuración estática. En el caso de entornos dinámicos, esto no puede hacerse, por lo que se utiliza el descubrimiento de servicios.
Alerta
La alerta con Prometheus consta de dos partes –
Las reglas de alerta envían alertas al Alertmanager.
A continuación, el Alertmanager gestiona esas alertas. Envía notificaciones utilizando muchas integraciones listas para usar, como correo electrónico, Slack, Hipchat y PagerDuty. El Alertmanager también puede realizar el silenciamiento o la agregación para reducir el número de notificaciones.
Esta es la guía para monitorizar el servidor Linux utilizando Prometheus y Dashboard.
Visualización con Dashboards
Prometheus tiene una serie de APIs mediante las cuales las consultas PromQL pueden producir datos en bruto para visualizaciones.
Aunque Prometheus incluye un navegador de expresiones que puede utilizarse para consultas ad-hoc, la mejor herramienta disponible es Grafana. Grafana se integra completamente con Prometheus y puede producir una amplia variedad de cuadros de mando.
Deberá configurar Prometheus como fuente de datos para Grafana.
Puede añadir cuadros de mando mediante:
- Importando cuadros de mando construidos por la comunidad
- Creando los suyos propios
- Utilizando un cuadro de mando predefinido.
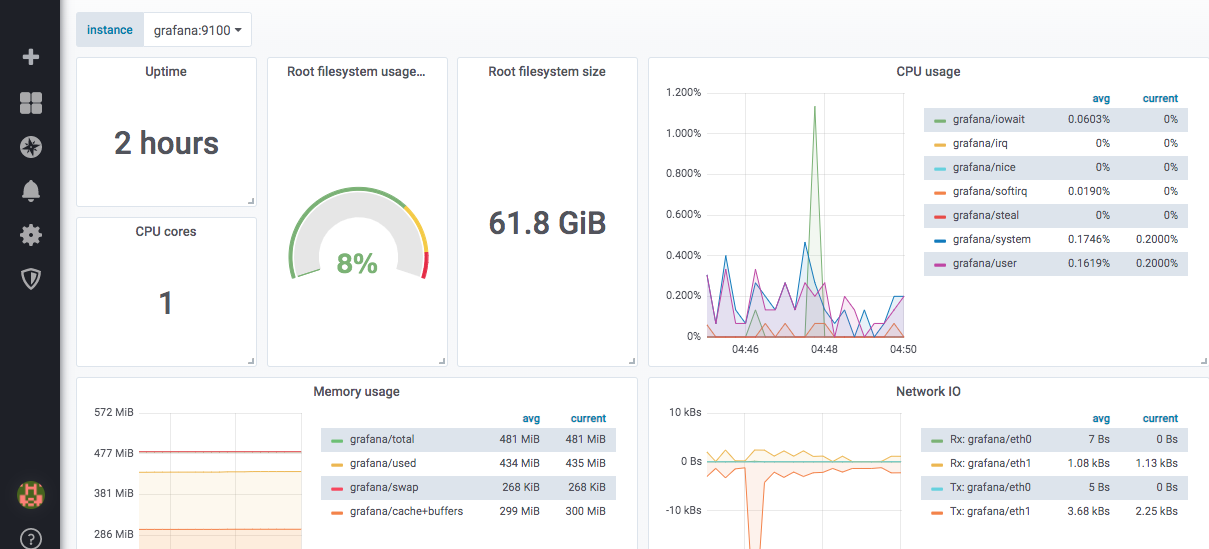
Este es el aspecto de un cuadro de mando predefinido del exportador de nodos:
Grafana dispone de un módulo worldPing que le permite monitorizar las métricas de rendimiento de sitios y DNS de todo el mundo.
Resumen
Prometheus tiene muy pocos requisitos. Puede ser bastante sencillo de ejecutar, ya que se trata de un único binario con un archivo de configuración. Puede manejar miles de objetivos e ingerir millones de muestras por segundo. Prometheus está diseñado para rastrear el sistema en general, la salud y el comportamiento del sistema.
Grafana es la mejor herramienta disponible para la visualización de métricas y se integra perfectamente con Prometheus.