
Probablemente esté familiarizado con asistentes de voz como Alexa, Siri y Google Assistant, pero ¿se ha preguntado alguna vez cómo se generan estas voces? La síntesis del habla ayuda a estos dispositivos a generar estas voces de IA.
Se calcula que en 2020 se utilizaban en todo el mundo hasta 4.200 millones de dispositivos con asistente de voz, y se espera que esa cifra alcance los 8.000 millones en 2024.
Comprender e implementar el reconocimiento de voz puede revolucionar la forma en que las empresas operan, interactúan con los clientes y se mantienen competitivas en un panorama que evoluciona tecnológicamente.
En este artículo, explicaré qué es la síntesis del habla, cómo puede ser útil para las empresas, las aplicaciones de la síntesis del habla, cómo funciona la síntesis del habla y los retos y consideraciones éticas asociados a ella.
¿Qué es la síntesis de voz?
La síntesis del habla, o conversión de texto en habla, es un campo de la inteligencia artificial que se centra en crear un habla o voz similar a la humana utilizando una combinación de métodos.

Combinando algoritmos avanzados y aprendizaje automático, las voces de la IA pueden ahora interpretar el texto escrito y transformarlo en palabras habladas. Esta innovadora tecnología ha evolucionado, permitiendo que los ordenadores y los dispositivos electrónicos interactúen con los usuarios a través de un habla similar a la humana en diversas aplicaciones.
Métodos implicados en la síntesis del habla
El desarrollo de las voces de IA implica diferentes pasos, pero los métodos utilizados pueden desglosarse en tres enfoques principales:
#1. Algoritmos de aprendizaje automático
Los algoritmos de aprendizaje automático constituyen el núcleo del desarrollo de voces de IA. A menudo se emplea el aprendizaje supervisado, en el que los modelos de voz de la IA se entrenan utilizando grandes conjuntos de datos del habla humana. Estos conjuntos de datos sirven como un tesoro de patrones lingüísticos, estructuras fonéticas y dinámica del habla.
Mediante el proceso de aprendizaje supervisado, el modelo de IA adquiere la capacidad de identificar patrones y correlaciones entre las entradas textuales proporcionadas y las salidas del habla asociadas.
A medida que procesa más datos, refina su comprensión de la fonética, las entonaciones y otras características del habla, lo que da como resultado voces de IA cada vez más naturales y expresivas.
#2. Procesamiento del lenguaje natural (PLN)
El procesamiento del lenguaje natural es un aspecto crítico de la tecnología de voz de la IA que permite a las máquinas comprender e interpretar el lenguaje humano. El PLN actúa como un detective del lenguaje, diseccionando palabras y frases escritas para discernir la gramática, el significado y las emociones.
La PNL garantiza que las voces de la IA puedan interpretar y pronunciar frases complejas, incluso cuando las palabras tienen varios significados o suenan parecidas. Actúa como puente entre las palabras escritas y el habla, haciendo que las voces de la IA suenen notablemente humanas, independientemente de las complejidades de los patrones lingüísticos.
#3. Técnicas de síntesis del habla
Las técnicas de síntesis del habla son fundamentales para las voces de la IA, ya que permiten a las máquinas transformar un texto procesado en un habla comprensible y expresiva. Existen diferentes métodos, como la síntesis concatenativa (que junta el habla grabada) y la síntesis de formantes (que se basa en modelar el tracto vocal como un conjunto de frecuencias resonantes o formantes)
El TTS neural (texto a voz) aprovecha los modelos de aprendizaje profundo, incluidas las redes neurales, para generar habla a partir de texto. Este método capta detalles intrincados como el ritmo y el tono, haciendo que las voces de la IA suenen excepcionalmente naturales y expresivas.
El TTS neural representa un avance significativo, que acerca las voces de la IA a las cualidades matizadas del habla humana.
Ahora, entendamos brevemente todos los pasos que intervienen en la síntesis del habla.
Proceso de síntesis del habla
Análisis del texto
El proceso comienza con el análisis del texto de entrada. Esto implica descomponer el texto en fonemas (las unidades más pequeñas de sonido), identificar las palabras y comprender la estructura sintáctica y semántica.
Aplicación de reglas lingüísticas
Se aplican reglas y modelos lingüísticos para determinar la pronunciación, los patrones de acentuación y la entonación. Este paso consiste en garantizar que el habla sintetizada suene natural y coherente.
Modelado
Los modelos acústicos se utilizan para representar las características sonoras del habla. Los métodos tradicionales consistían en definir las frecuencias de resonancia del tracto vocal (síntesis de formantes). Los enfoques modernos utilizan la síntesis paramétrica estadística o el aprendizaje profundo para modelar relaciones complejas entre las características del texto y del habla.
Entrenamiento
Los modelos de voz de la IA se entrenan con extensos conjuntos de datos de habla humana grabada. Este entrenamiento permite al modelo aprender los matices del habla natural, incluidas las variaciones de tono, velocidad y expresión.
Uso de redes neuronales
El aprendizaje profundo, en concreto las redes neuronales, es una tecnología clave en la moderna síntesis de voz con IA. Modelos como Tacotron y WaveNet utilizan redes neuronales para generar espectrogramas o producir directamente la forma de onda del habla a partir de entradas de texto.
Síntesis de forma de onda
La síntesis de forma de onda es el proceso de convertir la información del espectrograma en la señal de voz real. Técnicas como WaveNet generan formas de onda de alta calidad y sonido natural.
Aplicación de técnicas de postprocesado
Tras la síntesis, pueden aplicarse técnicas de postprocesamiento para refinar el resultado. Esto puede implicar ajustar el tono y la duración o añadir efectos para mejorar la naturalidad.
Salida
La salida final es el habla generada por la IA que corresponde al texto de entrada.
Algunos modelos emplean el aprendizaje por transferencia, en el que los modelos preentrenados se afinan para voces o idiomas específicos. Esto ayuda a conseguir voces más personalizadas y conscientes del contexto.
Los sistemas de síntesis de voz suelen someterse a una mejora continua a través de bucles de retroalimentación. Las interacciones, correcciones y preferencias de los usuarios contribuyen a perfeccionar los modelos con el tiempo.
Aplicaciones reales de la síntesis de voz
- Aprendizaje de idiomas: Las aplicaciones de aprendizaje de idiomas utilizan la síntesis de voz para pronunciar palabras y frases. Los alumnos pueden escuchar las pronunciaciones correctas y practicar sus habilidades auditivas, lo que mejora la experiencia general de aprendizaje de idiomas. (Ejemplo: Duolingo)
- Asistentes virtuales: Los asistentes virtuales aprovechan la síntesis de voz para ofrecer respuestas naturales y conversacionales a las consultas de los usuarios. Los usuarios pueden interactuar con estos asistentes a través del lenguaje hablado, realizando tareas como establecer recordatorios, consultar el tiempo o controlar dispositivos inteligentes con manos libres. (Ejemplos: Siri, Asistente de Google, Alexa)
- Sistemas de navegación GPS: Cuando está conduciendo y necesita indicaciones, las voces de IA de los sistemas GPS actúan como un guía amistoso, dando instrucciones giro a giro. Le ayudan a llegar a su destino con seguridad, proporcionándole actualizaciones en tiempo real y sugiriéndole las mejores rutas. Las voces de IA hacen que sus viajes por carretera sean más fluidos y seguros.
- Lectores de pantalla: La síntesis de voz se utiliza mucho en los lectores de pantalla para personas con discapacidad visual. Estas herramientas convierten el texto en pantalla en palabras habladas, lo que permite a los usuarios navegar por sitios web, leer documentos, artículos e interactuar con contenidos digitales. (Ejemplos: Google, Medium.com)
- Podcasting y creación de contenidos de audio: Los creadores de contenidos utilizan herramientas de síntesis de voz para generar locuciones para podcasts, audiolibros y otros contenidos de audio. Esto puede ahorrar tiempo y recursos, especialmente cuando se desea un tono o estilo específico para la narración.
- Dispositivos domésticos inteligentes: Los dispositivos domésticos inteligentes utilizan la síntesis de voz para comunicarse con los usuarios. Estos dispositivos pueden proporcionar actualizaciones, responder preguntas y ejecutar órdenes a través de voces sintetizadas, mejorando la interacción con el usuario en entornos domésticos inteligentes. (Ejemplos: Amazon Echo, Google Home)
Además, resulta beneficioso para muchas empresas.
Cómo puede ser útil la síntesis de voz para las empresas
La síntesis de voz puede ofrecer diversas ventajas a las empresas, mejorando la comunicación, la interacción con los clientes y la eficiencia en general.
He aquí algunos de los ejemplos más comunes:
- Creación de contenidos digitales: La síntesis de voz puede hacer que los contenidos digitales sean más accesibles para un público más amplio, incluidas las personas con deficiencias visuales. Las empresas pueden utilizar esta tecnología para proporcionar descripciones habladas del contenido visual en sitios web, aplicaciones o documentos, garantizando la inclusividad y el cumplimiento de las normas de accesibilidad.
- Comunicación multilingüe: Las empresas que operan en diversas regiones o que atienden a un público internacional pueden beneficiarse de la síntesis de voz multilingüe. Esto permite crear interfaces de voz y sistemas de comunicación que pueden cambiar dinámicamente de un idioma a otro, mejorando la comunicación con clientes y socios a nivel mundial.
- Servicio y asistencia al cliente: Los clientes pueden obtener información, realizar consultas o resolver problemas utilizando indicaciones de voz naturales y automatizadas, lo que mejora la eficacia del servicio de atención al cliente.
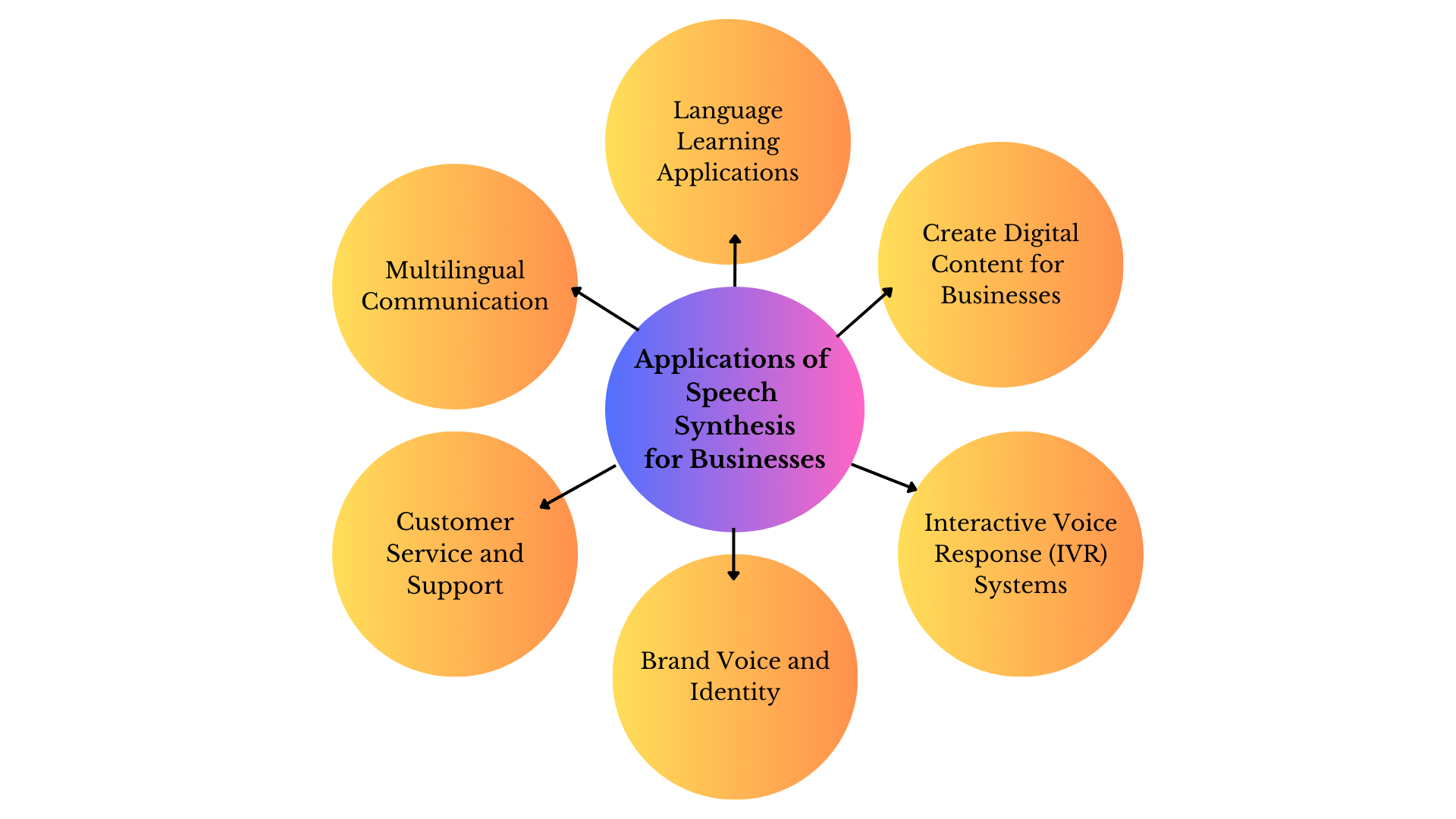
- Asistentes de voz y dispositivos inteligentes: La integración de la síntesis de voz en asistentes activados por voz o dispositivos inteligentes puede mejorar las interacciones de los usuarios. Las empresas pueden desarrollar aplicaciones que permitan a los usuarios acceder a información, realizar pedidos o controlar dispositivos mediante comandos hablados, creando experiencias fluidas y fáciles de usar.
- Sistemas de respuesta vocal interactiva (IVR): Los sistemas automatizados de atención al cliente suelen utilizar la síntesis de voz para guiar a los usuarios a través de las opciones del menú, proporcionar información y gestionar las consultas rutinarias.
- Programas de formación y aprendizaje: La síntesis de voz puede utilizarse para mejorar los programas de formación y aprendizaje electrónico. Puede generar voces que suenen naturales para narrar los materiales de formación, haciendo que el contenido sea más atractivo y accesible. Esto resulta especialmente útil para la incorporación, la formación sobre el cumplimiento de las normas o los contenidos educativos.
- Voz e identidad de marca: Las empresas pueden establecer una voz y una identidad de marca únicas utilizando voces sintetizadas personalizadas y reconocibles. Esto puede contribuir a una imagen de marca coherente en los distintos canales de comunicación, incluidas las líneas de atención al cliente, los anuncios y los materiales promocionales.
A medida que la tecnología siga avanzando, es probable que las aplicaciones y ventajas de la síntesis de voz en el contexto empresarial se amplíen aún más.
Retos asociados a la síntesis de voz
- Una voz sintetizada puede tener dificultades para transmitir las emociones matizadas de un texto, haciendo que suene monótono o robótico en lugar de captar la expresividad pretendida.
- Las voces sintetizadas suelen tener dificultades para ser conscientes del contexto. Comprender e incorporar las señales contextuales, como las pausas, el énfasis y la entonación adecuada según el contexto de la conversación o el texto, es un reto complejo.
- Sintetizar palabras poco comunes, términos técnicos, jerga, formas abreviadas y nombres propios no presentes en los datos de entrenamiento puede ser todo un reto. Los sistemas pueden pronunciar mal o tener dificultades para generar con precisión estas palabras menos comunes.

- Conseguir un procesamiento en tiempo real, especialmente en aplicaciones que requieren respuestas inmediatas (por ejemplo, los asistentes virtuales), manteniendo al mismo tiempo un resultado de alta calidad supone un reto. Minimizar la latencia es útil para mejorar la experiencia del usuario.
- Desarrollar modelos de síntesis que puedan manejar con precisión múltiples lenguas y dialectos es todo un reto. Las diferencias en los patrones fonéticos, la entonación y el acento entre lenguas y dialectos requieren técnicas de modelado sofisticadas.
Consideraciones éticas asociadas a la síntesis del habla
Las consideraciones éticas en la síntesis del habla giran en torno al uso responsable y justo de esta tecnología.

- La síntesis de voz puede utilizarse indebidamente para crear contenidos de audio deepfake; a veces, las videollamadas imitan voces reales con fines maliciosos como difundir información errónea, suplantar identidades o generar apoyos falsos.
- Recopilar y utilizar datos de voz para entrenar voces sintéticas plantea problemas de privacidad. Los usuarios pueden sentirse incómodos con que se utilicen sus voces sin su consentimiento explícito, especialmente si ello puede dar lugar a clones de voz realistas.
- Si las voces sintéticas se utilizan en aplicaciones críticas para la seguridad, como la autenticación de voz, las vulnerabilidades del proceso de síntesis podrían aprovecharse para un acceso no autorizado, lo que conllevaría riesgos para la seguridad.
- Los modelos de síntesis de voz entrenados en conjuntos de datos sesgados pueden perpetuar o amplificar los sesgos existentes en cuanto a acento, género o idioma, lo que daría lugar a resultados injustos y discriminatorios.
- El uso de voces sintéticas emocionalmente expresivas en el servicio de atención al cliente o en anuncios con la intención de manipular o engañar a los consumidores plantea problemas éticos sobre la manipulación emocional con fines comerciales.
- El cumplimiento de la normativa sobre protección de datos, como la GDPR, es crucial a la hora de recopilar, almacenar o procesar datos de voz para entrenar modelos de síntesis de voz.
- Aunque la síntesis de voz puede mejorar la accesibilidad, es esencial garantizar que la tecnología sea inclusiva y atienda a usuarios con diversos antecedentes lingüísticos, acentos y patrones de habla.
- La síntesis de voz de alta calidad puede utilizarse para suplantar la identidad de personas con fines de robo de identidad o fraude, lo que puede acarrear consecuencias legales y financieras para la persona suplantada.
Abordar estas consideraciones éticas implica adoptar prácticas responsables en el desarrollo, despliegue y uso de la tecnología de síntesis de voz.
Requiere transparencia, el consentimiento del usuario, esfuerzos para mitigar los sesgos y la adhesión a las normas de privacidad y seguridad para garantizar el uso ético de las voces sintéticas en diversas aplicaciones.
Palabras finales
Estamos en el futuro y, aunque los coches voladores aún no sean una realidad, podemos comunicarnos con los ordenadores utilizando lenguajes naturales y la síntesis del habla. La síntesis del habla resulta beneficiosa para los creadores de contenidos a la hora de generarlos, para las empresas a la hora de automatizar las tareas repetitivas cotidianas basadas en la voz y para los particulares como asistentes de voz.
En este artículo, exploramos qué es la síntesis del habla y cómo funciona, hablamos de los distintos pasos que implica, destacamos los retos y consideramos las consideraciones éticas.