Hablemos de la base de datos de series temporales de supervisión distribuida.
Una base de datos de series temporales está optimizada para datos de marcas de tiempo o series temporales. Por datos de series temporales se entienden las mediciones o eventos que se rastrean, supervisan, recopilan o agregan durante un periodo de tiempo. Podrían ser datos recogidos de los latidos del corazón de sensores de seguimiento del movimiento, métricas de la JVM de las aplicaciones java, datos de operaciones de mercado, datos de red, respuestas de la API, tiempo de actividad de los procesos, etc.
Las bases de datos de series temporales están completamente personalizadas con datos con marca de tiempo, que están indexados y escritos de forma eficiente para que pueda insertar datos de series temporales. Puede consultar esos datos de series temporales mucho más rápido que como lo haría en una base de datos relacional o NoSQL.
Últimamente, ha ganado mucha popularidad. ¿Y por qué no? Hace un trabajo fantástico para la supervisión de las operaciones empresariales y de TI. La buena noticia es que hay muchas opciones entre las que elegir, y la mayoría son de código abierto.
InfluxDB
InfluxDB es una de las bases de datos de series temporales más populares entre los DevOps, que está escrita en Go. InfluxDB fue diseñada desde cero para proporcionar un motor de ingestión y almacenamiento de datos altamente escalable. Es muy eficiente a la hora de recopilar, almacenar, consultar, visualizar y tomar medidas sobre flujos de datos de series temporales, eventos y métricas en tiempo real.
Proporciona muestreo descendente y políticas de retención de datos para apoyar el mantenimiento de los datos de alto valor y alta precisión en la memoria, y los datos de menor valor en el disco. Está construido de forma nativa en la nube para proporcionar escalabilidad a través de múltiples topologías de despliegue, incluyendo la nube en las instalaciones y entornos híbridos.
InfluxDB es una solución de código abierto y preparada para la empresa. Utiliza InfluxQL, que es muy similar a un lenguaje de consulta de estructuras, para interactuar con los datos. La última versión ofrece agentes, cuadros de mando, consultas y tareas en un conjunto de herramientas. Es una herramienta todo en uno para la creación de cuadros de mando, la visualización y las alertas.
Características
- Alto rendimiento para datos de series temporales con alta ingesta total y consultas en tiempo real
- InfluxQL para interactuar con los datos que es un lenguaje de consulta tipo SQL
- Componente central de la pila TICK (Telegraf, InfluxDB, Chronograf y Kapacitor).
- Soporte de plugins para protocolos como collectd, Graphite, OpenTSDB para la ingestión de datos
- Puede manejar millones de puntos de datos en sólo 1 segundo
- Políticas de retención para eliminar automáticamente los datos obsoletos
Dado que es de código abierto, puede descargarlo y ponerlo en marcha en su servidor. Sin embargo, ofrecen InfluxDB Cloud en AWS, Azure y GCP.
Prometheus
Prometheus es una solución de monitorización de código abierto que se utiliza para comprender las percepciones de los datos métricos y enviar las alertas necesarias. Cuenta con una base de datos local de series temporales en disco que almacena los datos en un formato personalizado en el disco.
El modelo de datos de Prometheus es multidimensional basado en series temporales; almacena todos los datos como flujos de valores con marca de tiempo. Resulta muy útil cuando se trabaja con series temporales totalmente numéricas. Recopilar datos de microservicios y consultarlos es uno de los puntos fuertes de Prometheus.
Se integra estrechamente con Grafana para la visualización y si usted es un novato, entonces lea este artículo de introducción a Prometheus y Grafana.
Características
- Dispone de un modelo multidimensional que utiliza el nombre de las métricas y pares clave-valor (etiquetas)
- PromQL para la consulta de datos de series temporales para generar tablas, alertas y gráficos Adhoc
- Utiliza el modo pull HTTP para recopilar datos de series temporales
- Utiliza una pasarela intermediaria para empujar series temporales
Prometheus dispone de cientos de exportadores para exportar los datos de Windows, Linux, Java, Base de datos, APIs, Sitio web, Hardware de servidor, PHP, Mensajería y más. Para monitorizar Linux, consulte esta configuración de Prometheus Grafana.
TimescaleDB
TimescaleDB es una base de datos relacional de código abierto que hace que SQL sea escalable para datos de series temporales. Esta base de datos está construida sobre PostgreSQL.
Ofrece dos productos: la primera opción es una edición comunitaria, de uso gratuito que puede instalar en su servidor. La segunda opción es TimescaleDB Cloud, donde obtendrá una infraestructura totalmente alojada y gestionada en la nube para sus necesidades de implantación.

Se puede utilizar para la supervisión de DevOps, la comprensión de las métricas de las aplicaciones, el seguimiento de los datos de los dispositivos IoT, la comprensión de los datos financieros, etc. Puede medir registros, eventos de Kubernetes, métricas de Prometheus e incluso métricas personalizadas.
Para los propietarios de productos, puede utilizarlo para comprender el rendimiento de un producto a lo largo del tiempo, lo que ayuda a tomar decisiones estratégicas para el crecimiento.
Características
- Ejecuta consultas 10-100X más rápido que PostgreSQL, MongoDB
- Puede escalar a petabytes horizontalmente y escribe millones de puntos de datos por segundo
- Muy similar a PostgreSQL, por lo que es fácil de manejar para desarrolladores y administradores
- Combina funcionalidades de bases de datos relacionales y de series temporales para crear aplicaciones potentes.
- Incorpora algoritmos y funciones de rendimiento para ahorrar muchos costes.
Graphite
Graphite es una solución todo en uno para almacenar y visualizar eficazmente datos de series temporales en tiempo real. Graphite puede hacer dos cosas, almacenar datos de series temporales y renderizar gráficos bajo demanda. Pero no recopila datos por usted; para eso, puede utilizar herramientas como collectd, Ganglia, Sensu, telegraf, etc.
Tiene tres componentes: Carbon, Whisper y Graphite-Web. Carbon recibe los datos de series temporales, los agrega y los persiste en el disco. Whisper es la base de datos de series temporales que almacena los datos. Graphite-Web es el front-end para crear cuadros de mando y visualizar los datos.
Características de Graphite:
- El formato métrico en el que se presentan los datos es sencillo.
- API completa para renderizar los datos y crear tablas, cuadros de mando y gráficos
- Proporciona un rico conjunto de funciones de renderizado transformadoras y de biblioteca estadística
- Encadena múltiples funciones de renderizado para construir una consulta de destino.
QuestDB
QuestDB es una base de datos relacional orientada a columnas que puede realizar análisis en tiempo real de datos de series temporales. Funciona con SQL y algunas extensiones para crear un modelo relacional para datos de series temporales. QuestDB se ha codificado desde cero y no tiene dependencias, lo que mejora su rendimiento.
QuestDB soporta uniones relacionales y de series temporales, lo que ayuda a correlacionar los datos. La forma más sencilla de empezar a utilizar QuestDB es desplegarlo dentro de un contenedor Docker.

Características de QuestDB:
- Consola interactiva para importar datos mediante arrastrar y soltar y consultarlos
- Soportado en la nube nativa (AWS, Azure, GCP), en las instalaciones o integrado
- Proporciona integración empresarial con funciones como directorio activo, alta disponibilidad, seguridad empresarial, agrupación en clústeres
- Proporciona información en tiempo real mediante análisis operativos y predictivos
AWS Timestream
¿Cómo es posible que AWS no esté en la lista?
AWS Tim estream es un servicio de base de datos de series temporales sin servidor que es rápido y escalable. Se utiliza principalmente para aplicaciones IoT para almacenar billones de eventos en un día y 1000 veces más rápido con 1/10 del coste de las bases de datos relacionales.
Gracias a su motor de consulta específico, puede consultar simultáneamente datos recientes y datos históricos almacenados. Ofrece múltiples funciones integradas para analizar datos de series temporales y encontrar perspectivas útiles.
Características de Amazon Timestream:
- Sin servidores que administrar ni instancias que aprovisionar; todo se gestiona automáticamente.
- Rentable, pague sólo por lo que ingiera, almacene y consulte.
- Capaz de ingerir billones de eventos diarios sin merma del rendimiento
- Capacidad de análisis integrada con funciones SQL estándar, interpolación y suavizado para identificar tendencias, patrones y anomalías
- Todos los datos se cifran utilizando el sistema de administración de claves (KMS) de AWS con claves gestionadas por el cliente (CMK)
OpenTSDB
OpenTSDB es una base de datos de series temporales escalable que se ha escrito sobre HBase. Es capaz de almacenar billones de puntos de datos a millones de escrituras por segundo. Puede conservar los datos en OpenTSDB para siempre con su marca de tiempo original y su valor preciso, por lo que no perderá ningún dato.
Dispone de un demonio de series temporales (TSD) y de utilidades de línea de comandos. El demonio de series temporales se encarga de almacenar los datos en HBase o de recuperarlos de él. Puede hablar con el TSD mediante la API HTTP, telnet o la sencilla interfaz gráfica de usuario incorporada. Necesita herramientas como flume, collectd, vacuumetrix, etc., para recopilar datos de diversas fuentes en OpenTSDB.
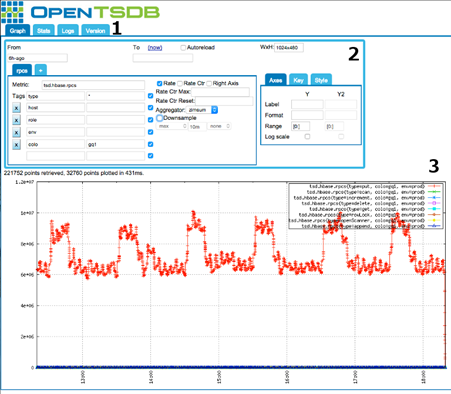
Características de OpenTSBD:
- Puede agregar, filtrar y reducir la muestra de métricas a una velocidad vertiginosa
- Almacena y escribe datos con una precisión de milisegundos
- Se ejecuta en Hadoop y HBase y se escala fácilmente añadiendo nodos al clúster
- Utiliza una interfaz gráfica de usuario para generar gráficos
Conclusión
Dado que cada vez se utilizan más dispositivos IoT/Smart en la actualidad, se genera un enorme tráfico en tiempo real en los sitios web con millones de eventos en un día, las operaciones en el mercado aumentan, ¡y la base de datos de series temporales ha llegado! Las bases de datos de series temporales son imprescindibles en su pila de producción para la monitorización.
La mayoría de las bases de datos de series temporales mencionadas están disponibles para autoalojarse, así que adelante, consiga una VM en la nube y pruébelas para ver qué le funciona.