L’apprentissage fédéré marque un changement dans la manière dont les modèles d’apprentissage automatique sont formés. Traditionnellement, les données provenant de nombreuses sources sont déplacées vers un emplacement central pour l’entraînement des modèles. L’apprentissage fédéré inverse le processus : les modèles sont envoyés vers les données, entraînés localement et seules les mises à jour sont partagées en retour. Cela permet de protéger la vie privée des utilisateurs en conservant les données sensibles sur les appareils d’origine.
L’apprentissage fédéré dans l’IA présente des avantages significatifs pour le développement de l’apprentissage automatique. Il réduit les coûts en éliminant les transferts massifs de données et permet souvent la formation sur des appareils moins puissants.
Comment fonctionne l’apprentissage fédéré ?
L’apprentissage fédéré comprend une série d’étapes atomiques qui produisent un modèle. Ces étapes sont appelées cycles d’apprentissage. Une configuration d’apprentissage typique itère à travers ces cycles, en améliorant le modèle à chaque étape. Chaque cycle d’apprentissage comprend les étapes suivantes.
Un cycle d’apprentissage typique
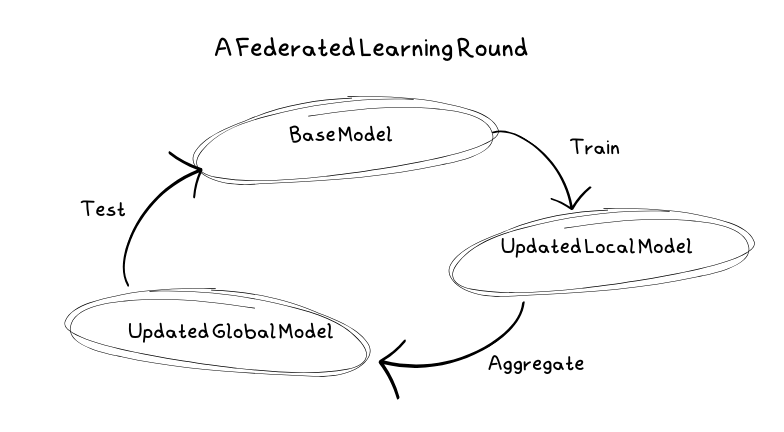
Tout d’abord, le serveur choisit le modèle à former et les hyperparamètres tels que le nombre de cycles, les nœuds clients à utiliser et la fraction de nœuds utilisée à chaque nœud. À ce stade, le modèle est également initialisé avec les paramètres initiaux pour former le modèle de base.
Ensuite, les clients reçoivent des copies d’un modèle de base à entraîner. Ces clients peuvent être des appareils mobiles, des ordinateurs personnels ou des serveurs. Ils entraînent le modèle sur leurs données locales, évitant ainsi de partager des données sensibles avec les serveurs.
Une fois que les clients ont formé le modèle sur leurs données locales, ils le renvoient au serveur sous la forme d’une mise à jour. Une fois reçue par le serveur, la mise à jour est combinée aux mises à jour des autres clients pour créer un nouveau modèle de base. Les clients n’étant pas toujours fiables, il se peut que certains d’entre eux n’envoient pas leurs mises à jour. À ce stade, le serveur traite toutes les erreurs.
Avant de pouvoir être redéployé, le modèle de base doit être testé. Or, le serveur ne stocke pas de données. Par conséquent, pour tester le modèle, il est renvoyé aux clients, où il est testé par rapport à leurs données locales. S’il est meilleur que le modèle de base précédent, il est adopté et utilisé à la place.
Voici un guide utile sur le fonctionnement de l’apprentissage fédéré, rédigé par l’équipe Federated Learning de Google AI.
Centralisé, fédéré ou hétérogène
Dans cette configuration, un serveur central est chargé de contrôler l’apprentissage. Ce type de configuration est connu sous le nom d’apprentissage fédéré centralisé.
Le contraire de l’apprentissage centralisé est l’apprentissage fédéré décentralisé, dans lequel les clients se coordonnent entre eux.
L’autre configuration est appelée apprentissage hétérogène. Dans cette configuration, les clients n’ont pas nécessairement la même architecture de modèle globale.
Avantages de l’apprentissage fédéré
- Le principal avantage de l’apprentissage fédéré est qu’il permet de préserver la confidentialité des données. Les clients partagent les résultats de la formation, et non les données utilisées pour la formation. Des protocoles peuvent également être mis en place pour agréger les résultats afin qu’ils ne puissent pas être liés à un client particulier.
- Cette méthode permet également de réduire la bande passante du réseau, car aucune donnée n’est partagée entre le client et le serveur. Les modèles sont échangés entre le client et le serveur.
- Elle réduit également le coût de la formation des modèles, puisqu’il n’est pas nécessaire d’acheter du matériel de formation coûteux. Les développeurs utilisent le matériel du client pour former les modèles. En raison de la faible quantité de données impliquées, l’appareil du client n’est pas mis à rude épreuve.
Inconvénients de l’apprentissage fédéré
- Ce modèle dépend de la participation de nombreux nœuds différents. Certains d’entre eux ne sont pas contrôlés par le développeur. Leur disponibilité n’est donc pas garantie. Le matériel d’apprentissage n’est donc pas fiable.
- Les clients sur lesquels les modèles sont formés ne sont pas exactement des GPU puissants. Il s’agit plutôt d’appareils normaux tels que des téléphones. Ces appareils, même regroupés, peuvent ne pas être suffisamment puissants par rapport aux grappes de GPU.
- L’apprentissage fédéré suppose également que tous les nœuds clients sont dignes de confiance et travaillent pour le bien commun. Or, il se peut que certains d’entre eux ne le soient pas et qu’ils émettent de mauvaises mises à jour entraînant une dérive du modèle.
Applications de l’apprentissage fédéré
L’apprentissage fédéré permet d’apprendre tout en préservant la vie privée. Cela s’avère utile dans de nombreuses situations, telles que
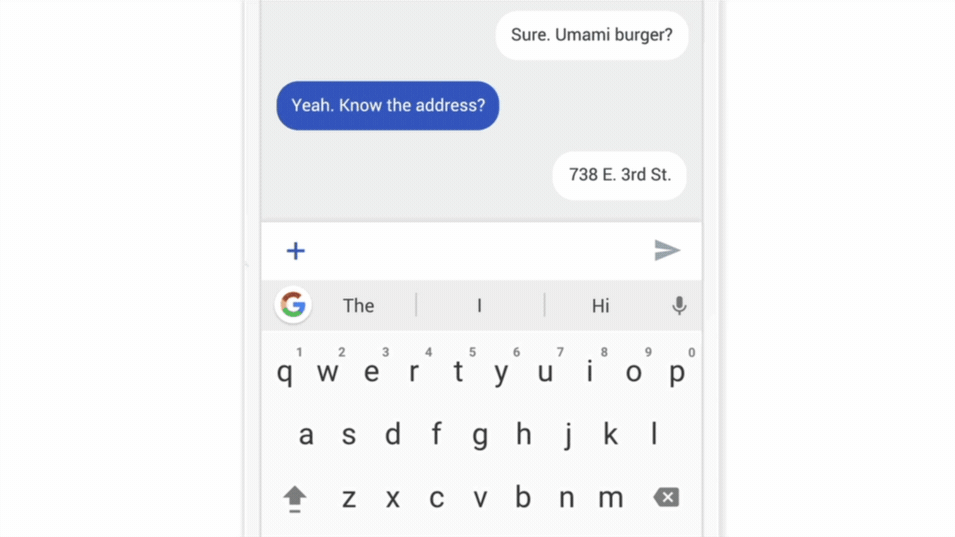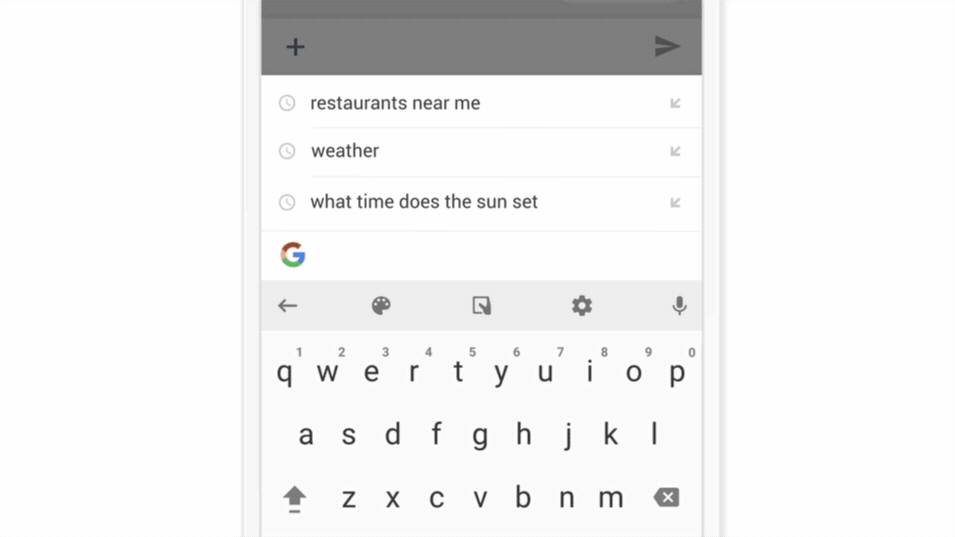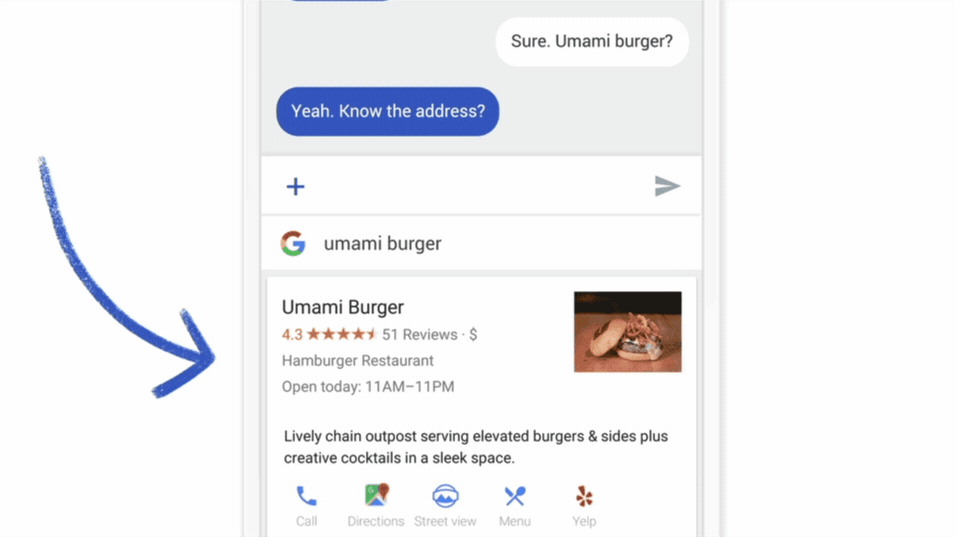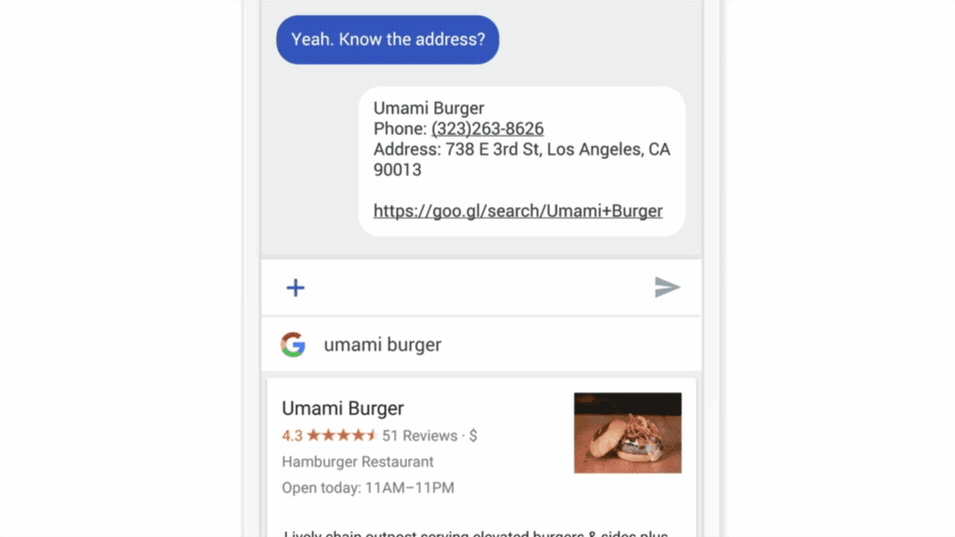
- Les prédictions du mot suivant sur les claviers de smartphones.
- Les appareils IoT qui peuvent former des modèles localement en fonction des exigences spécifiques de la situation dans laquelle ils se trouvent.
- Les industries pharmaceutiques et de la santé.
- Les industries de la défense bénéficieraient également de l’entraînement de modèles sans partage de données sensibles.
Cadres pour l’apprentissage fédéré
Il existe de nombreux cadres permettant de mettre en œuvre des modèles d’apprentissage fédéré. Parmi les meilleurs, citons NVFlare, FATE, Flower et PySft.