Les données sont un élément indispensable des entreprises et des organisations, et elles n’ont de valeur que si elles sont structurées correctement et gérées efficacement.
Selon une statistique, 95 % des entreprises considèrent aujourd’hui que la gestion et la structuration des données non structurées posent problème.
C’est là que le data mining entre en jeu. Il s’agit du processus de découverte, d’analyse et d’extraction de modèles significatifs et d’informations précieuses à partir de vastes ensembles de données non structurées.
Les entreprises utilisent des logiciels pour identifier des modèles dans de grands lots de données afin d’en savoir plus sur leurs clients et leur public cible et de développer des stratégies commerciales et marketing pour améliorer les ventes et réduire les coûts.
Outre cet avantage, la fraude et la détection d’anomalies sont les applications les plus importantes du data mining.
Cet article explique la détection d’anomalies et explore plus en détail comment elle peut aider à prévenir les violations de données et les intrusions dans les réseaux afin de garantir la sécurité des données.
Qu’est-ce que la détection d’anomalies et quels sont ses types ?

Si l’exploration de données consiste à trouver des modèles, des corrélations et des tendances qui se rejoignent, c’est aussi un excellent moyen de trouver des anomalies ou des points de données aberrants au sein du réseau.
Dans le cadre de l’exploration de données, les anomalies sont des points de données qui diffèrent des autres points de données de l’ensemble de données et qui s’écartent du modèle de comportement normal de l’ensemble de données.
Les anomalies peuvent être classées en différents types et catégories, notamment
- Changements dans les événements : Il s’agit de changements soudains ou systématiques par rapport au comportement normal antérieur.
- Valeurs aberrantes : Petites anomalies apparaissant de manière non systématique dans la collecte des données. Elles peuvent être classées en aberrations globales, contextuelles et collectives.
- Dérives : Changement progressif, non directionnel et à long terme dans l’ensemble des données.
Ainsi, la détection des anomalies est une technique de traitement des données très utile pour détecter les transactions frauduleuses, traiter les études de cas présentant un déséquilibre de classe élevé et détecter les maladies afin de construire des modèles robustes en science des données.
Par exemple, une entreprise peut vouloir analyser ses flux de trésorerie pour trouver des transactions anormales ou récurrentes vers un compte bancaire inconnu afin de détecter une fraude et de mener une enquête plus approfondie.
Avantages de la détection d’anomalies
La détection d’anomalies dans le comportement des utilisateurs contribue à renforcer les systèmes de sécurité et à les rendre plus précis et plus exacts.
Elle analyse et donne un sens aux diverses informations fournies par les systèmes de sécurité afin d’identifier les menaces et les risques potentiels au sein du réseau.
Voici les avantages de la détection d’anomalies pour les entreprises :
- Détection en temps réel des menaces de cybersécurité et des violations de données , car les algorithmes d’intelligence artificielle (IA) analysent constamment vos données pour détecter les comportements inhabituels.
- La détection d’anomaliesest plus rapide et plus facile que la détection manuelle, ce qui réduit le travail et le temps nécessaires à la résolution des menaces.
- Minimise les risques opérationnels en identifiant les erreurs opérationnelles, telles que les baisses soudaines de performance, avant même qu’elles ne se produisent.
- Elle permet d’éviter des dommages importants pour l’entreprise en détectant rapidement les anomalies. En effet, sans système de détection des anomalies, les entreprises peuvent mettre des semaines, voire des mois, à identifier les menaces potentielles.
La détection des anomalies est donc un atout considérable pour les entreprises qui stockent de vastes ensembles de données sur les clients et les entreprises afin de trouver des opportunités de croissance et d’éliminer les menaces à la sécurité et les goulets d’étranglement opérationnels.
Techniques de détection des anomalies
La détection des anomalies fait appel à plusieurs procédures et algorithmes d’apprentissage automatique pour surveiller les données et détecter les menaces.
Voici les principales techniques de détection des anomalies :
#1. Techniques d’apprentissage automatique

Les techniques d’apprentissage automatique utilisent des algorithmes d’apprentissage automatique pour analyser les données et détecter les anomalies. Les différents types d’algorithmes d’apprentissage automatique pour la détection des anomalies sont les suivants :
- Algorithmes de regroupement
- Les algorithmes de classification
- Algorithmes d’apprentissage en profondeur
Les techniques de ML couramment utilisées pour la détection des anomalies et des menaces comprennent les machines à vecteurs de support (SVM), le regroupement par k-means et les autoencodeurs.
#2. Techniques statistiques
Les techniques statistiques utilisent des modèles statistiques pour détecter des schémas inhabituels (comme des fluctuations inhabituelles dans les performances d’une machine particulière) dans les données afin de détecter les valeurs qui se situent en dehors de la plage des valeurs attendues.
Les techniques statistiques courantes de détection des anomalies comprennent les tests d’hypothèse, l’IQR, le Z-score, le Z-score modifié, l’estimation de la densité, le boxplot, l’analyse des valeurs extrêmes et l’histogramme.
#3. Techniques d’exploration de données

Les techniques d’exploration de données utilisent des techniques de classification et de regroupement des données pour trouver des anomalies dans l’ensemble des données. Parmi les techniques d’exploration de données les plus courantes, on peut citer le regroupement spectral, le regroupement basé sur la densité et l’analyse en composantes principales.
Les algorithmes d’exploration de données par regroupement sont utilisés pour regrouper différents points de données en grappes sur la base de leur similarité afin de trouver des points de données et des anomalies qui se situent en dehors de ces grappes.
En revanche, les algorithmes de classification attribuent les points de données à des classes spécifiques prédéfinies et détectent les points de données qui n’appartiennent pas à ces classes.
#4. Techniques basées sur des règles
Comme leur nom l’indique, les techniques de détection d’anomalies basées sur des règles utilisent un ensemble de règles prédéterminées pour trouver des anomalies dans les données.
Ces techniques sont comparativement plus faciles et plus simples à mettre en place, mais elles peuvent manquer de souplesse et ne pas s’adapter efficacement à l’évolution du comportement et des schémas des données.
Par exemple, vous pouvez facilement programmer un système basé sur des règles pour signaler comme frauduleuses les transactions dépassant un certain montant.
#5. Techniques spécifiques à un domaine
Vous pouvez utiliser des techniques spécifiques à un domaine pour détecter des anomalies dans des systèmes de données spécifiques. Toutefois, si elles sont très efficaces pour détecter des anomalies dans des domaines spécifiques, elles peuvent l’être moins dans d’autres domaines que celui spécifié.
Par exemple, en utilisant des techniques spécifiques à un domaine, vous pouvez concevoir des techniques spécifiquement destinées à détecter des anomalies dans les transactions financières. En revanche, elles peuvent ne pas fonctionner pour détecter des anomalies ou des baisses de performance dans une machine.
Nécessité de l’apprentissage automatique pour la détection des anomalies
L’apprentissage automatique est très important et très utile pour la détection des anomalies.
Aujourd’hui, la plupart des entreprises et des organisations qui ont besoin de détecter des anomalies traitent d’énormes quantités de données, qu’il s’agisse de textes, d’informations sur les clients, de transactions ou de fichiers multimédias tels que des images et du contenu vidéo.
Il est pratiquement impossible d’analyser manuellement toutes les transactions bancaires et les données générées chaque seconde pour obtenir des informations pertinentes. En outre, la plupart des entreprises sont confrontées à des défis et à des difficultés majeures pour structurer les données non structurées et les organiser de manière pertinente pour l’analyse des données.
C’est là que les outils et les techniques comme l’apprentissage automatique jouent un rôle important dans la collecte, le nettoyage, la structuration, l’organisation, l’analyse et le stockage d’énormes volumes de données non structurées.
Les techniques et algorithmes d’apprentissage automatique traitent de grands ensembles de données et offrent la possibilité d’utiliser et de combiner différentes techniques et algorithmes pour obtenir les meilleurs résultats.
En outre, l’apprentissage automatique permet également de rationaliser les processus de détection des anomalies pour les applications du monde réel et d’économiser des ressources précieuses.
Voici d’autres avantages et l’importance de l’apprentissage automatique dans la détection des anomalies :
- Il facilite la mise à l’échelle de la détection d’anomalies en automatisant l’identification de modèles et d’anomalies sans nécessiter de programmation explicite.
- Les algorithmes d’apprentissage automatique s’adaptent facilement à l’évolution des données, ce qui les rend très efficaces et robustes au fil du temps.
- Ilstraitent facilement des ensembles de données complexes et de grande taille, ce qui rend la détection d’anomalies efficace malgré la complexité de l’ensemble des données.
- Ilsgarantissent une identification et une détection précoces des anomalies en les identifiant dès qu’elles se produisent, ce qui permet de gagner du temps et d’économiser des ressources.
- Les systèmes de détection d’anomalies basés sur l’apprentissage automatique permettent d’atteindre des niveaux de précision plus élevés dans la détection d’anomalies que les méthodes traditionnelles.
Ainsi, la détection d’anomalies associée à l’apprentissage automatique permet une détection plus rapide et plus précoce des anomalies afin de prévenir les menaces de sécurité et les brèches malveillantes.
Algorithmes d’apprentissage automatique pour la détection des anomalies
Vous pouvez détecter les anomalies et les valeurs aberrantes dans les données à l’aide de différents algorithmes d’exploration de données pour la classification, le regroupement ou l’apprentissage de règles d’association.
En règle générale, ces algorithmes d’exploration de données sont classés en deux catégories différentes : lesalgorithmes d’apprentissage superviséet les algorithmes d’apprentissage non supervisé.
Apprentissage supervisé
L’apprentissage supervisé est un type courant d’algorithme d’apprentissage qui comprend des algorithmes tels que les machines à vecteurs de support, la régression logistique et linéaire et la classification multi-classe. Ce type d’algorithme est formé sur des données étiquetées, ce qui signifie que son ensemble de données de formation comprend à la fois des données d’entrée normales et des sorties correctes correspondantes ou des exemples anormaux pour construire un modèle prédictif.
Son objectif est donc de faire des prédictions de sortie pour des données inédites et nouvelles en se basant sur les modèles de l’ensemble des données d’apprentissage. Les applications des algorithmes d’apprentissage supervisé comprennent la reconnaissance d’images et de la parole, la modélisation prédictive et le traitement du langage naturel (NLP).
Apprentissage non supervisé
L’apprentissage non supervisé n’est pas formé sur des données étiquetées. Il permet de découvrir des processus complexes et des structures de données sous-jacentes sans fournir d’orientation à l’algorithme de formation et au lieu de faire des prédictions spécifiques.
Les applications des algorithmes d’apprentissage non supervisé comprennent la détection des anomalies, l’estimation de la densité et la compression des données.
Examinons maintenant quelques algorithmes populaires de détection d’anomalies basés sur l’apprentissage automatique.
Facteur local aberrant (LOF)
Local Outlier Factor ou LOF est un algorithme de détection d’anomalies qui prend en compte la densité locale des données pour déterminer si un point de données est une anomalie.
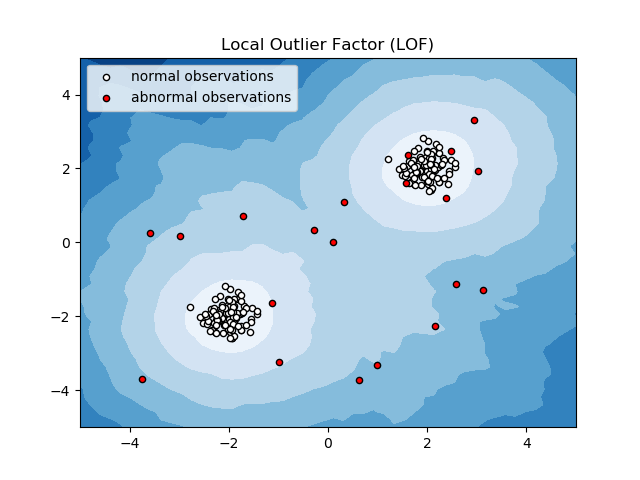
Il compare la densité locale d’un élément aux densités locales de ses voisins afin d’analyser les zones de densités similaires et les éléments dont les densités sont comparativement plus faibles que celles de leurs voisins, qui ne sont rien d’autre que des anomalies ou des valeurs aberrantes.
Ainsi, en termes simples, la densité entourant une valeur aberrante ou un élément anormal diffère de la densité entourant ses voisins. C’est pourquoi cet algorithme est également appelé algorithme de détection des valeurs aberrantes basé sur la densité.
K-Voisins les plus proches (K-NN)
K-NN est l’algorithme de classification et de détection d’anomalie supervisée le plus simple, facile à mettre en œuvre, qui stocke tous les exemples et données disponibles et classe les nouveaux exemples sur la base des similitudes dans les mesures de distance.
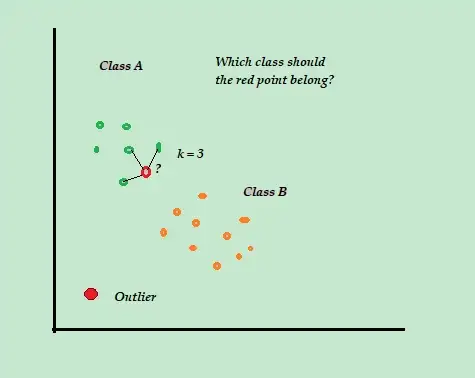
Cet algorithme de classification est également appelé ” apprenant paresseux “, car il ne stocke que les données d’apprentissage étiquetées, sans rien faire d’autre pendant le processus d’apprentissage.
Lorsqu’un nouveau point de données d’apprentissage non étiquetées arrive, l’algorithme examine les K points de données d’apprentissage les plus proches afin de les utiliser pour classer et déterminer la classe du nouveau point de données non étiquetées.
L’algorithme K-NN utilise les méthodes de détection suivantes pour déterminer les points de données les plus proches :
- Ladistance euclidienne pour mesurer la distance pour les données continues.
- Distance de Hamming pour mesurer la proximité des deux chaînes de texte pour les données discrètes.
Si un nouveau point de données arrive, l’algorithme calcule la distance entre le nouveau point de données et chacun des points de données de l’ensemble et sélectionne les points qui sont les plus proches en nombre du nouveau point de données.
Ainsi, supposons que K=3 et que 2 des 3 points de données soient étiquetés comme A, le nouveau point de données est étiqueté comme appartenant à la classe A.
L’algorithme K-NN fonctionne donc mieux dans les environnements dynamiques nécessitant une mise à jour fréquente des données.
Il s’agit d’un algorithme populaire de détection d’anomalies et d’exploration de texte qui trouve des applications dans la finance et les entreprises afin de détecter les transactions frauduleuses et d’augmenter le taux de détection des fraudes.
Machine à vecteur de support (SVM)
La machine à vecteurs de support est un algorithme de détection d’anomalies basé sur l’apprentissage automatique supervisé, principalement utilisé dans les problèmes de régression et de classification.
Il utilise un hyperplan multidimensionnel pour séparer les données en deux groupes (nouvelles et normales). Ainsi, l’hyperplan agit comme une limite de décision qui sépare les observations de données normales et les nouvelles données.
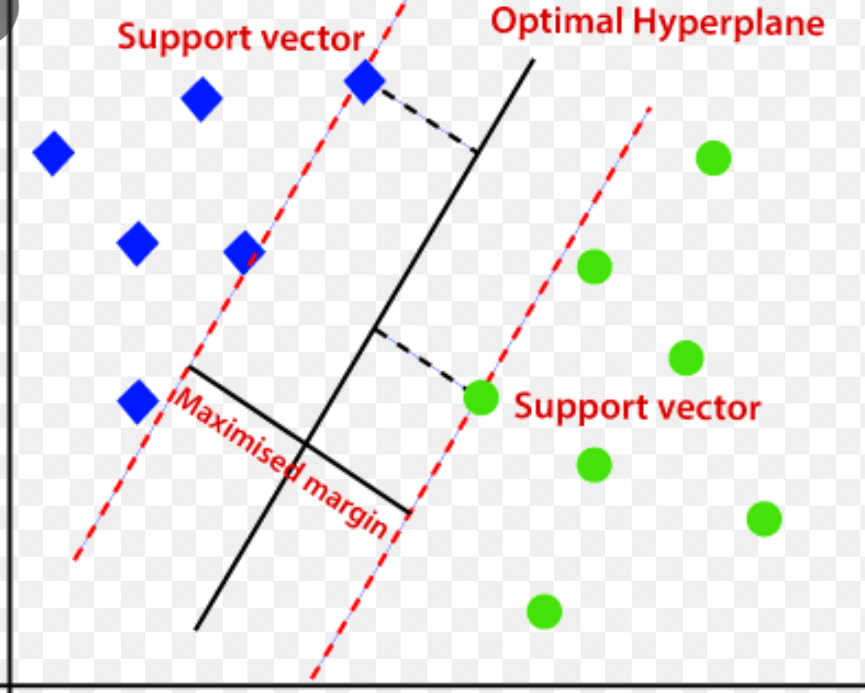
La distance entre ces deux points de données est appelée ” marges “.
L’objectif étant d’augmenter la distance entre les deux points, le SVM détermine le meilleur hyperplan ou l’hyperplan optimal avec la marge maximale afin que la distance entre les deux classes soit la plus grande possible.
En ce qui concerne la détection des anomalies, le SVM calcule la marge de l’observation du nouveau point de données par rapport à l’hyperplan afin de le classer.
Si la marge dépasse le seuil fixé, il classe la nouvelle observation comme une anomalie. Dans le même temps, si la marge est inférieure au seuil, l’observation est classée comme normale.
Les algorithmes SVM sont donc très efficaces pour traiter des ensembles de données complexes et de haute dimension.
Forêt d’isolation
Isolation Forest est un algorithme d’apprentissage automatique non supervisé de détection d’anomalies basé sur le concept d’un classificateur de forêt aléatoire .
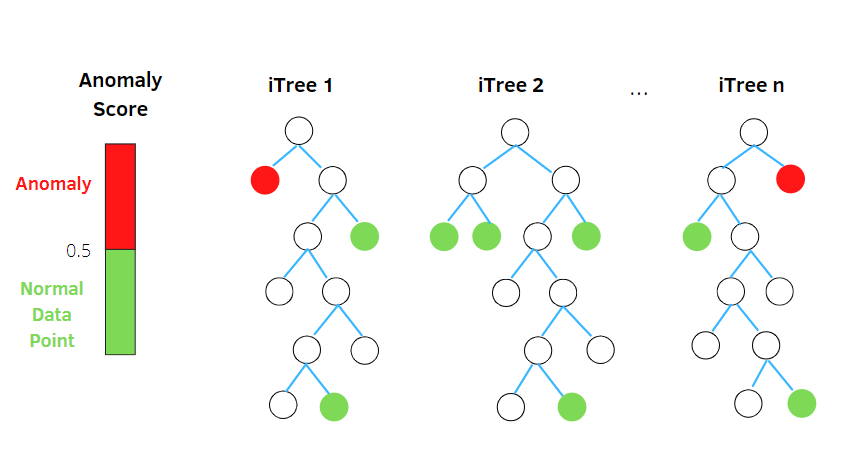
Cet algorithme traite des données sous-échantillonnées de manière aléatoire dans l’ensemble de données dans une structure arborescente basée sur des attributs aléatoires. Il construit plusieurs arbres de décision pour isoler les observations. Il considère une observation particulière comme une anomalie si elle est isolée dans moins d’arbres en fonction de son taux de contamination.
Ainsi, en termes simples, l’algorithme de la forêt d’isolement divise les points de données en différents arbres de décision, ce qui permet d’isoler chaque observation d’une autre.
Les anomalies se situent généralement à l’écart de la grappe de points de données, ce qui facilite leur identification par rapport aux points de données normaux.
Les algorithmes de forêt d’isolement peuvent facilement traiter des données catégorielles et numériques. Par conséquent, ils sont plus rapides à former et très efficaces pour détecter les anomalies dans les ensembles de données de grande taille et de haute dimension.
Intervalle interquartile
L’intervalle interquartile ou IQR est utilisé pour mesurer la variabilité statistique ou la dispersion statistique afin de trouver des points anormaux dans les ensembles de données en les divisant en quartiles .

L’algorithme trie les données par ordre croissant et divise l’ensemble en quatre parties égales. Les valeurs séparant ces parties sont les Q1, Q2 et Q3 (premier, deuxième et troisième quartiles).
Voici la distribution des percentiles de ces quartiles :
- Q1 correspond au 25e percentile des données.
- Q2 correspond au 50e centile des données.
- Q3 signifie le 75e percentile des données.
L’IQR est la différence entre les ensembles de données du troisième (75e) et du premier (25e) percentile, représentant 50 % des données.
L’utilisation de l’IQR pour la détection des anomalies nécessite que vous calculiez l’IQR de votre ensemble de données et que vous définissiez les limites inférieures et supérieures des données pour trouver les anomalies.
- Limite inférieure : Q1 – 1,5 * IQR
- Limite supérieure : Q3 – 1,5 * IQR
En règle générale, les observations qui sortent de ces limites sont considérées comme des anomalies.
L’algorithme IQR est efficace pour les ensembles de données dont la distribution est inégale et mal comprise.
Dernières remarques
Les risques de cybersécurité et les violations de données ne semblent pas vouloir diminuer dans les années à venir. Ce secteur à risque devrait continuer à croître en 2023, et les cyberattaques de l’IdO devraient à elles seules doubler d’ici à 2025.
En outre, les cybercrimes coûteront aux entreprises et organisations mondiales environ 10,3 billions de dollars par an d’ici à 2025.
C’est pourquoi le besoin de techniques de détection d’anomalies devient aujourd’hui plus répandu et nécessaire pour la détection des fraudes et la prévention des intrusions dans les réseaux.
Cet article vous aidera à comprendre ce que sont les anomalies dans le data mining, les différents types d’anomalies et les moyens de prévenir les intrusions dans les réseaux à l’aide de techniques de détection d’anomalies basées sur la ML.
Ensuite, vous pourrez explorer tout ce qui concerne la matrice de confusion dans l’apprentissage automatique.