9 Commandes AWS S3 avec des exemples pour gérer les données et les dépôts de données
Le contrôle et la gestion des données peuvent être une tâche ardue. Ces commandes AWS S3 vous aideront à gérer rapidement et efficacement vos buckets et vos données AWS S3.
AWSS3 est le service de stockage d’objets fourni par AWS. Il s’agit du service de stockage le plus utilisé d’AWS, qui peut virtuellement contenir une quantité infinie de données. Il est hautement disponible, durable et facile à intégrer avec plusieurs autres services AWS.
AWS S3 peut être utilisé par des personnes ayant des besoins variés tels que le stockage d’applications mobiles/web, le stockage de big data, le stockage de données d’apprentissage automatique, l’hébergement de sites web statiques, et bien d’autres encore.
Si vous avez utilisé S3 dans votre projet, vous savez qu’étant donné la vaste capacité de stockage, la gestion de centaines de buckets et de téraoctets de données dans ces buckets peut être une tâche exigeante. Nous avons une liste de commandes AWS S3 avec des exemples que vous pouvez utiliser pour gérer efficacement vos buckets et vos données AWS S3.
Configuration de l’interface de programmation AWS
Une fois que vous avez téléchargé et installé le CLI AWS, vous devez configurer les identifiants AWS pour pouvoir accéder à votre compte et à vos services AWS. Voyons rapidement comment vous pouvez configurer le CLI AWS.
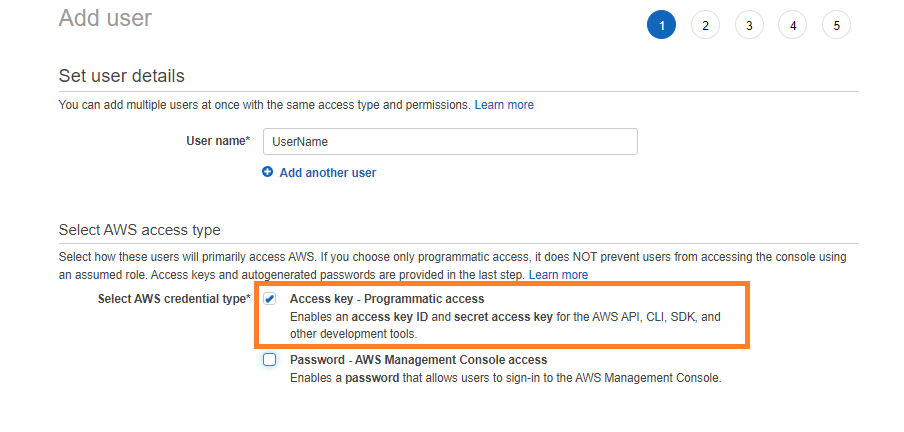
La première étape consiste à créer un utilisateur ayant un accès programmatique au compte AWS. N’oubliez pas de cocher cette case lorsque vous créez un utilisateur pour AWS CLI.
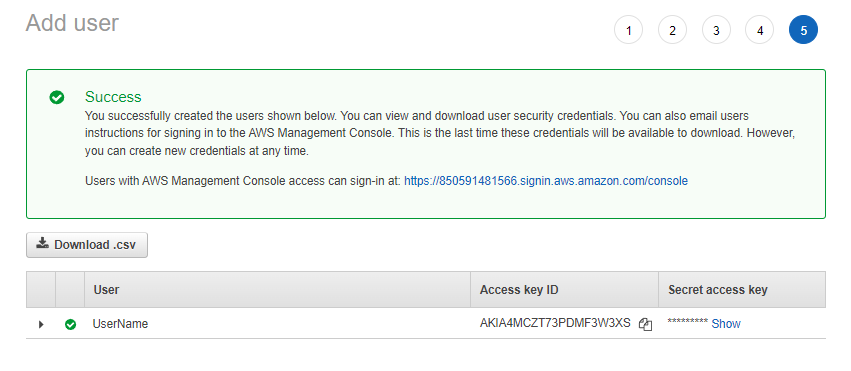
Attribuez les autorisations et créez un utilisateur. Dans le dernier écran après avoir créé cet utilisateur, copiez l’ID de la clé d’accès et la clé d’accès secrète pour cet utilisateur. Nous utiliserons ces informations d’identification pour nous connecter via AWS CLI.
Allez maintenant dans le terminal de votre choix et exécutez la commande suivante.
aws configure
Saisissez l’ID de la clé d’accès et la clé d’accès secrète lorsque vous y êtes invité. Sélectionnez la région AWS de votre choix et le format de sortie de la commande. Personnellement, je préfère utiliser le format JSON. Ce n’est pas grave, vous pouvez toujours modifier ces valeurs ultérieurement.
Vous pouvez maintenant exécuter n’importe quelle commande AWS CLI dans la console. Voyons maintenant les commandes AWS S3.
cp
La commande cp copie simplement les données vers et depuis les buckets S3. Elle peut être utilisée pour copier des fichiers de local à S3, de S3 à local, et entre deux buckets S3. Il existe de nombreux autres paramètres que vous pouvez fournir avec les commandes.
Par exemple, le paramètre -dryrun pour tester la commande, le paramètre –storage-class pour spécifier la classe de stockage de vos données dans S3, d’autres paramètres pour définir le cryptage, et bien plus encore. La commande cp vous permet de contrôler entièrement la manière dont vous configurez la sécurité de vos données dans S3.
Utilisation
aws s3 cp [--options]
Exemples
Copier des données d’un fichier local vers un fichier S3
La commande ls est utilisée pour lister les buckets ou leur contenu. Ainsi, si vous souhaitez simplement afficher des informations sur vos buckets ou les données qu’ils contiennent, vous pouvez utiliser la commande ls.
Cette commande liste tous les seaux de votre compte avec la date de création du seau.
Lister tous les objets de premier niveau d’un bucket
aws s3 ls BUCKET_NAME_1 ou s3://BUCKET_NAME_1
Résultat :
PRE samplePrefix/
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 fichier_2.json
2021-12-09 12:23:21 3088 fichier_3.html
Cette commande répertorie tous les objets de premier niveau d’un seau S3. Notez que les objets avec le préfixe samplePrefix/ ne sont pas affichés ici, mais seulement les objets de premier niveau.
Cette commande dresse la liste de tous les objets d’un panier S3. Notez ici que les objets avec le préfixe samplePrefix/ et tous les sous-préfixes sont également affichés.
mb
La commande mb est simplement utilisée pour créer de nouveaux buckets S3. Il s’agit d’une commande assez simple, mais pour créer de nouveaux buckets, le nom du nouveau bucket doit être unique pour tous les buckets S3.
Utilisation
aws s3 mb
Exemple de commande
Créez un nouveau bucket dans une région spécifique
aws s3 mb myUniqueBucketName --region eu-west-1
mv
La commande mv déplace simplement les données vers et depuis les buckets S3. Tout comme la commande cp, la commande mv est utilisée pour déplacer des données de local à S3, de S3 à local, ou entre deux buckets S3.
La seule différence entre la commande mv et la commande cp est que lorsque vous utilisez la commande mv, le fichier est supprimé de la source. AWS déplace ce fichier vers la destination. Vous pouvez spécifier de nombreuses options avec la commande.
Utilisation
aws s3 mv [--options]
Exemples
Déplacer des données d’un fichier local vers un fichier S3
La commande presign génère une URL pré-signée pour une clé dans le seau S3. Vous pouvez utiliser cette commande pour générer des URL qui peuvent être utilisées par d’autres personnes pour accéder à un fichier dans la clé du seau S3 spécifiée.
Utilisation
aws s3 presign –expires-in
Exemple
Générez une URL pré-signée valable pendant une heure pour un objet dans le seau
La commande sync copie et met à jour les fichiers de la source vers la destination, tout comme la commande cp. Il est important de comprendre la différence entre les commandes cp et sync. Lorsque vous utilisez la commande cp, elle copie les données de la source vers la destination, même si les données existent déjà dans la destination.
Elle ne supprime pas non plus les fichiers de la destination s’ils ont été supprimés de la source. En revanche, la commande sync examine la destination avant de copier vos données et ne copie que les fichiers nouveaux et mis à jour. La commande sync est similaire à la commande “committing” et “pushing” des changements vers une branche distante dans git. La commande sync offre de nombreuses options pour personnaliser la commande.
Vous pouvez utiliser les buckets S3 pour héberger des sites web statiques. La commande website est utilisée pour configurer l’hébergement de sites web statiques S3 pour votre bucket.
Vous spécifiez les fichiers d’index et d’erreur et le S3 vous donne une URL où vous pouvez voir le fichier.
Utilisation
aws s3 website [--options]
Exemple
Configurez l’hébergement statique d’un seau S3 et indiquez les fichiers d’index et d’erreur