Les entreprises modernes s’appuient de plus en plus sur des systèmes intégrés dans le nuage AWS (Amazon Web Services) pour fournir des solutions robustes et évolutives. Toutefois, garantir des performances optimales dans ces systèmes intégrés peut s’avérer une tâche complexe.
L’optimisation de votre système AWS pour une efficacité maximale peut vous aider à améliorer les performances, à réduire les coûts et à renforcer l’efficacité opérationnelle globale.
Cet article traite des stratégies clés, telles que l’équilibrage de la charge, l’échelonnement automatique, la mise en cache et les stratégies de charge de données, pour améliorer les performances des systèmes intégrés dans le nuage AWS.
Qu’est-ce que l’optimisation dans le nuage AWS ?
L’optimisation dans le nuage AWS fait référence aux activités qui améliorent les performances, l’efficacité et les coûts de fonctionnement des systèmes et processus basés sur le nuage. Vous devez vous concentrer sur les domaines dans lesquels des améliorations peuvent être apportées facilement tout en garantissant la sécurité de votre système existant.

Si le niveau d’effort requis pour l’amélioration devient trop élevé, il ne s’agit plus d’optimisation. Dans ce cas, on parle de refonte du système.
La refonte est généralement un processus beaucoup plus coûteux, qui modifie substantiellement la solution technique existante parce qu’elle ne répond plus aux exigences. C’est pourquoi nous devons planifier les mises à jour incrémentales du système de manière à minimiser les besoins de refonte au fil du temps.
L’objectif ultime de l’optimisation des systèmes est donc de mettre en œuvre des stratégies permettant d’obtenir de meilleurs résultats avec un minimum de coûts supplémentaires. Vous pouvez également considérer ce processus comme un moyen de réduire les coûts sans compromettre les performances. Vous pouvez atteindre certaines parties de cet objectif même sans modifier le code source.
Par exemple, grâce à des stratégies telles que le redimensionnement des instances ou l’utilisation d’instances ponctuelles pour les charges de travail non critiques. Vous pouvez également mettre en œuvre diverses stratégies et outils d’optimisation des coûts fournis par AWS, qui vous donneront d’autres conseils utiles de manière proactive.
En outre, vous pouvez examiner votre utilisation actuelle du modèle de tarification AWS dans l’architecture et apporter des modifications pour la rendre plus efficace. AWS définit même l’optimisation des coûts comme l’un des piliers de l’efficacité des performances d’un cadre bien architecturé.
Toutes ces actions retarderont, voire supprimeront complètement la nécessité de remanier le système à long terme.
Il est très important de trouver le bon équilibre entre l’optimisation de l’utilisation des ressources et la minimisation des ressources inutilisées qui permettent de réaliser des économies potentielles. Cet équilibre est mis en œuvre en tenant compte des schémas d’utilisation des ressources applicables à votre application et de la manière dont elle est utilisée.
Cela signifie que vous pouvez toujours augmenter les instances de calcul, le stockage ou les services de réseau pour atteindre les niveaux de performance souhaités. Cependant, vous devez toujours vérifier si les avantages de la mise à niveau que vous avez acquis sont inférieurs à la somme des coûts que vous avez réussi à économiser avec un tel changement d’architecture.
Principaux aspects de l’optimisation AWS
Certains aspects de l’optimisation dans le nuage AWS sont plus importants que d’autres. Examinons les aspects qui, selon moi, sont généralement en tête de liste pour la majorité des initiatives d’optimisation.
#1. Appliquer l’équilibrage de charge là où c’est possible
L’équilibrage des charges joue un rôle crucial dans la distribution du trafic entrant sur plusieurs ressources afin de garantir des performances optimales. Lors de la conception de l’architecture, vous devez envisager d’équilibrer la charge sur autant de parties du système que possible.
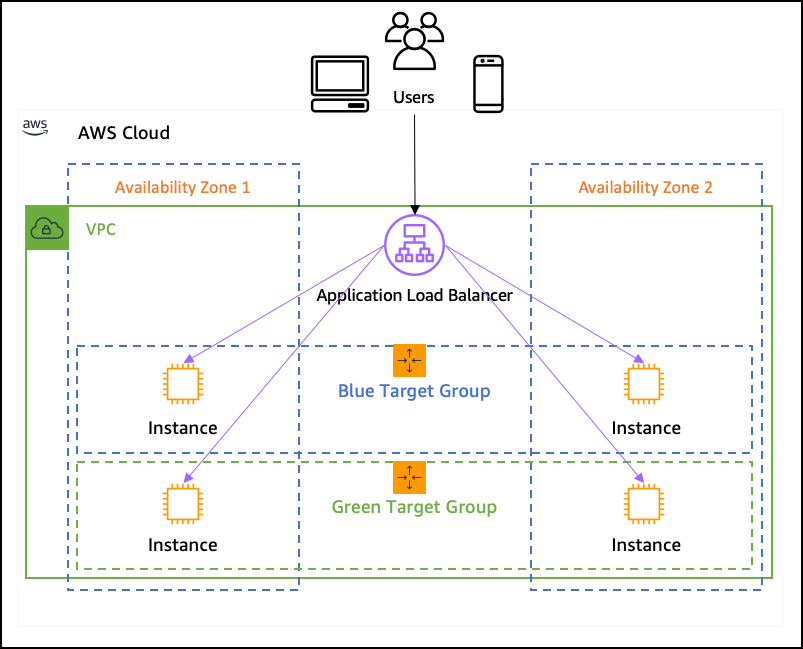
Les systèmes deviennent de plus en plus complexes au fil du temps. Vous ne pouvez pas prédire comment ils évolueront au cours des prochaines années. Grâce aux techniques d’équilibrage de la charge, vous pouvez mieux préparer la plateforme à une telle croissance.
AWS propose des services d’équilibrage de charge élastique (ELB) qui distribuent automatiquement le trafic entrant à plusieurs instances. L’équilibrage de la charge permet d’éviter qu’une seule ressource ne soit submergée, ce qui améliore les performances du système. Il n’est même pas nécessaire que cela coûte plus cher, car vous pouvez vous permettre d’avoir des instances plus petites au lieu d’une instance plus grande et plus puissante.
Vous pouvez appliquer l’équilibrage de charge même au niveau du réseau (indépendamment des applications elles-mêmes) en utilisant des équilibreurs de charge de passerelle. Cela répartira la charge sur plusieurs pare-feu ou composants de l’infrastructure de détection d’intrusion, ce qui rendra l’ensemble de votre plateforme plus sûre.
Dans AWS, vous pouvez concevoir de nombreuses instances sans serveur au lieu d’instances Amazon EC2 standard (qui génèrent des coûts en permanence à moins que vous ne les arrêtiez), ce qui signifie que ces instances supplémentaires ne consomment aucun coût s’il n’y a rien à traiter, à moins qu’elles ne soient réellement en opération (c’est-à-dire en cas d’augmentation de la charge).
#2. Activez la mise à l’échelle automatique lorsque c’est raisonnable
La mise à l’échelle automatique permet à votre système d’ajuster automatiquement sa capacité en fonction du trafic entrant. Cela peut se faire dans les deux sens – vers le haut ou vers le bas. La mise à l’échelle automatique d’AWS est une fonctionnalité spécifique que les principaux fournisseurs de cloud ne possèdent pas tous, même aujourd’hui.
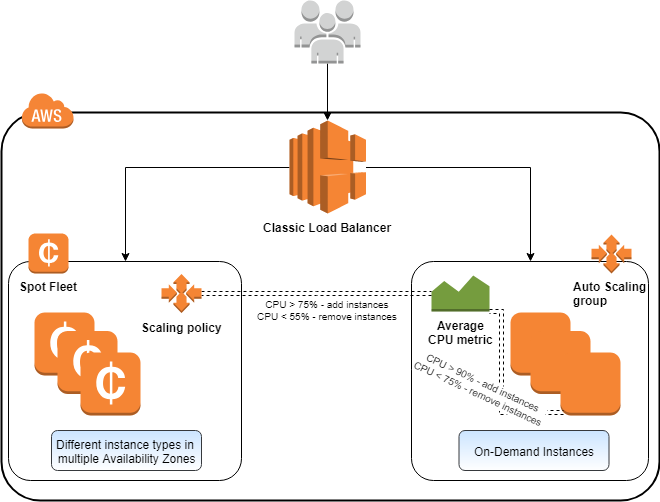
Vous pouvez définir des politiques de mise à l’échelle qui ajoutent ou suppriment automatiquement des instances en fonction de conditions prédéfinies. Il s’agit généralement d’une mise à l’échelle horizontale, lorsque vous démarrez une ou plusieurs instances et que vous les ajoutez ensuite à la chaîne de traitement en fonction de la charge actuelle.
Une mise à l’échelle verticale est également possible. Il s’agit de modifier la configuration des instances existantes pour obtenir des spécifications plus élevées, telles qu’un processeur plus puissant, de la mémoire ou de l’espace disque. Cette opération est beaucoup plus facile à réaliser dans l’environnement en nuage, car vous n’avez pas besoin de vous occuper du matériel physique. Le matériel sous-jacent nécessaire à l’exécution d’une telle mise à l’échelle verticale est entièrement géré par AWS et vous n’avez pas à vous en préoccuper.
La mise à l’échelle sera alors (conformément à vos politiques) augmentée ou réduite en fonction de la quantité de trafic à traiter. Ce qui est bien, c’est qu’une fois les paramètres définis, vous n’avez pas besoin de rester assis à surveiller les processus de mise à l’échelle.
Ils s’ajustent automatiquement. Si vous définissez des politiques efficaces et bien adaptées à votre volume de traitement habituel, vous économiserez globalement sur les coûts d’infrastructure. Par la suite, vous ne paierez pas pour des instances supplémentaires lorsqu’elles ne sont pas nécessaires.
De même, vous ne traiterez pas les données trop longtemps en cas de pic de charge. Votre système traitera efficacement les différentes charges de travail informatiques, améliorant ainsi les performances pendant les périodes de pointe et réduisant les coûts de l’informatique en nuage pendant les périodes de faible demande.
#3. Principes de la mise en cache
La mise en cache est une technique qui permet de stocker les données fréquemment consultées dans un cache (lié à un service en nuage spécifique), ce qui réduit la nécessité de les rechercher à plusieurs reprises à partir de la source d’origine.
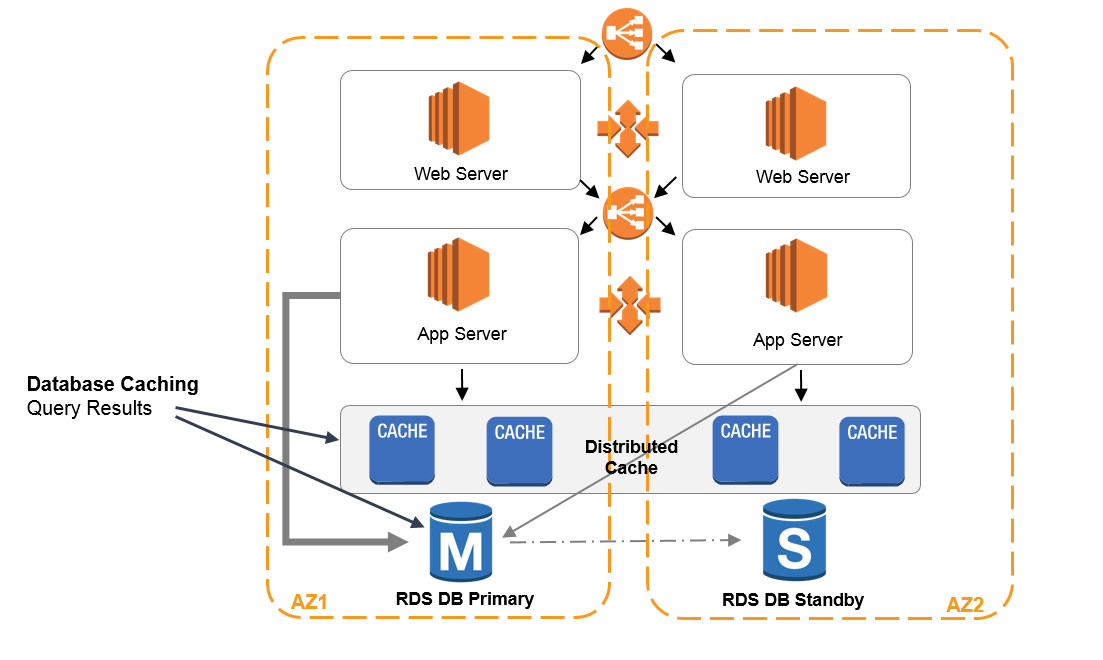
Amazon Web Services contient le service web Amazon ElastiCache. Il s’agit d’un service de mise en cache en mémoire entièrement géré qui prend en charge les moteurs de mise en cache les plus courants tels que Redis et Memcached. Vous pouvez l’exploiter et l’intégrer dans l’architecture de votre système aux endroits spécifiques où l’utilisateur extrait très souvent des données.
Grâce à ces stratégies de mise en cache, vous pouvez réduire considérablement le temps de réponse et améliorer les performances globales de vos systèmes intégrés. Toutefois, il convient de s’assurer que les données que vous lisez sont toujours à jour en ce qui concerne le système source.
Bien que la mise en cache permette une lecture beaucoup plus rapide pour les utilisateurs finaux, elle ne sera pas très utile si les données sont déjà obsolètes. Pour éviter cela, vous devez prendre en compte les propriétés de mise en cache suivantes :
- L’un des moyens de garantir la fraîcheur des données consiste à fixer un délai d’expiration ou Time-to-Live (TTL) pour les données mises en cache. Lorsque les données atteignent leur délai d’expiration, le cache est invalidé et la requête suivante récupère les données mises à jour à partir de la source. Si vous définissez un TTL approprié, vous pouvez équilibrer le compromis entre la fraîcheur des données et les performances du cache.
- L’invalidation du cache est une technique utilisée pour maintenir les données à jour. Lorsque les données sous-jacentes changent, le cache doit être invalidé pour récupérer les données les plus récentes de la source. AWS propose différents mécanismes pour déclencher l’invalidation du cache. Par exemple, vous pouvez programmer des fonctions AWS Lambda pour le faire ou intégrer l’invalidation du cache au processus de mise à jour des données de votre application.
- Le modèle cache-aside consiste à récupérer les données du cache uniquement si elles existent. Si ce n’est pas le cas, récupérez-les à la source et remplissez le cache. Lors de la mise à jour des données, le cache est invalidé et les requêtes suivantes récupèrent les données mises à jour à partir de la source. Ce modèle garantit que le cache reste à jour tout en minimisant l’impact sur les performances.
- Le modèle cache-through met à jour le cache à chaque fois qu’une donnée est mise à jour dans la source. Lorsqu’une opération d’écriture est effectuée du côté de la source, la mémoire cache est mise à jour en même temps. Cette méthode garantit que le cache contiendra toujours les données les plus récentes, mais elle peut entraîner des frais généraux supplémentaires en raison de l’obligation de synchronisation des mises à jour.
- Le maintien de la cohérence et de l’homogénéité du cache est essentiel pour garantir que les données restent à jour. Vous pouvez y parvenir en mettant en œuvre des mécanismes de synchronisation appropriés lors de la mise à jour des données. C’est ainsi que vous éviterez les incohérences entre le cache et la source. AWS propose des services tels qu’Amazon ElastiCache, qui vous offre des fonctionnalités prêtes à l’emploi telles que la réplication du cache et des modèles de cohérence pour garantir l’intégrité des données.
Stratégies efficaces de chargement des données
Lorsque vous intégrez des systèmes d’exploitation dans le nuage AWS, il est essentiel de réfléchir aux stratégies de chargement des données que vous allez appliquer. Nous ne parlons pas ici de la vitesse de rafraîchissement des données (en temps réel ou par lots).
Il s’agit plutôt de savoir combien de données je dois traiter à chaque fois du côté de la cible pour obtenir des résultats pertinents. En général, le choix final se fait entre le chargement complet des données et le chargement incrémental des données.
#1. Stratégie de chargement complet des données
Une stratégie de chargement complet des données vous donnera l’avantage d’une mise en œuvre simple et facile. C’est ce que les équipes de projet ont souvent tendance à faire.
L’avantage du délai de production le plus court (et des coûts les plus bas pour la version initiale) est si tentant que le client et les équipes de projet sont rarement désireux d’explorer d’autres options.
Dans une stratégie de chargement complet des données, vous souhaitez transférer toutes les données du système source vers le système cible. Cette approche convient parfaitement à la synchronisation initiale des données ou lorsque vous devez simplement rafraîchir l’ensemble des données. Cependant, elle peut prendre beaucoup de temps et nécessiter de nombreuses ressources. Parfois, elle reste la meilleure stratégie. Par exemple, si les données de la source changent souvent de façon spectaculaire.
Disons que plus de 50 % de toutes les données sont modifiées avant chaque processus de chargement suivant dans votre architecture. Dans ce cas, il est tout à fait logique de mettre en œuvre le processus de chargement complet des données.
Mais qu’en est-il si le système source ne modifie qu’un petit pourcentage de l’ensemble des données de temps à autre ? Et si vous planifiez l’exécution du processus de chargement toutes les heures ou même plus fréquemment ?
Dans ces cas-là, un chargement complet des données représente une perte de temps absolue, une utilisation élevée des ressources, des coûts de stockage, de la puissance de calcul et de l’argent, tout cela en même temps. Il peut être plus rapide à mettre en œuvre, mais à long terme, il sera beaucoup plus coûteux qu’un chargement incrémentiel.
#2. Stratégie de chargement incrémentiel des données
Dans une stratégie de chargement incrémental des données, vous souhaitez transférer uniquement les modifications ou les mises à jour effectuées depuis la dernière synchronisation. Cette approche réduit considérablement la quantité de données qui doivent être transférées entre les systèmes ou stockées pendant l’exécution du transfert.
La stratégie de chargement incrémentiel des données permet d’accélérer la synchronisation et d’améliorer les performances. Elle est idéale pour les scénarios où les mises à jour sont fréquentes.
Cependant, le chargement incrémentiel nécessite généralement une approche beaucoup plus sophistiquée. Il exige une conception intelligente de l’architecture et parfois même une bonne synchronisation de tous les processus de connexion dont vous avez besoin pour accomplir les processus de chargement.
Il y a également beaucoup plus de chances que vous manquiez une partie des changements de données au cours des processus. Cela se produit surtout si le système source se trouve en dehors de votre plateforme et de votre responsabilité directe.
Dans ce cas, il est évident que vous ne pouvez pas contrôler totalement les processus qui se déroulent dans le système source. Vous devez vous appuyer sur une bonne communication avec le fournisseur externe et veiller à mettre à jour les modèles d’intégration chaque fois qu’un changement intervient dans le système source.
Sinon, vous risquez de ne pas obtenir l’ensemble des derniers incréments de données. Et peut-être ne le savez-vous même pas. Cela peut se produire si le changement dans le système source est d’une nature telle que toutes les interfaces et interconnexions existantes fonctionnent encore parfaitement malgré le fait qu’elles récupèrent moins de données qu’elles ne le devraient maintenant.
Exemple pratique du processus d’optimisation d’AWS
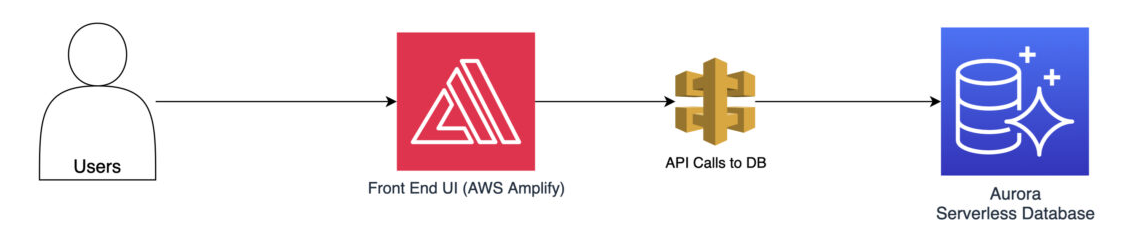
Prenons un exemple concret pour illustrer l’application pratique de ces techniques. Imaginez un site web d’achat populaire hébergé sur AWS. Pendant les périodes de pointe, le site est soumis à un trafic extrêmement important, ce qui entraîne des temps de réponse beaucoup plus lents. Potentiellement, cela peut même entraîner des temps d’arrêt sporadiques.
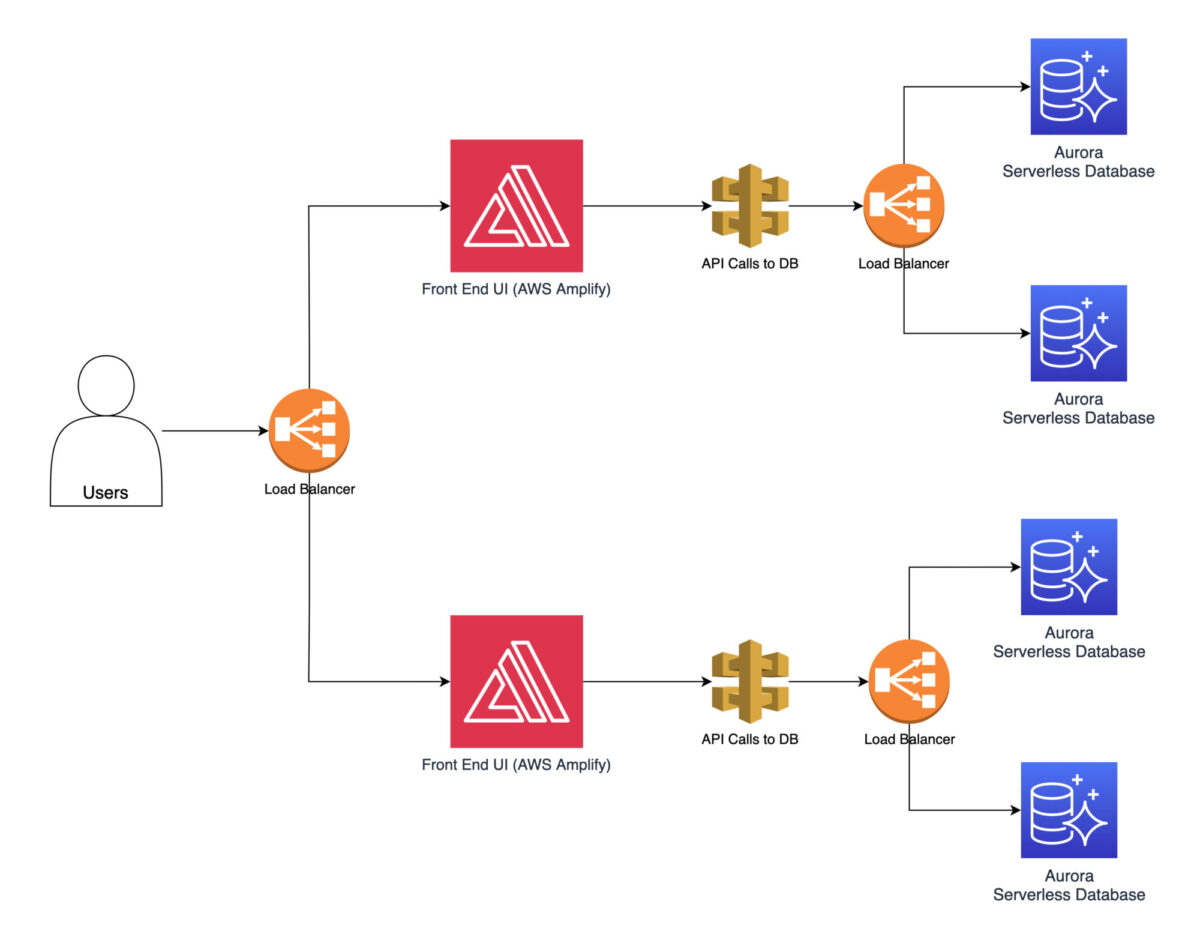
Pour commencer à optimiser les performances, vous pouvez mettre en place un équilibrage de la charge à l’aide d’AWS Elastic Load Balancer. Cela permet de répartir uniformément le trafic entrant entre plusieurs instances. Vous éviterez ainsi que les instances ne soient submergées.
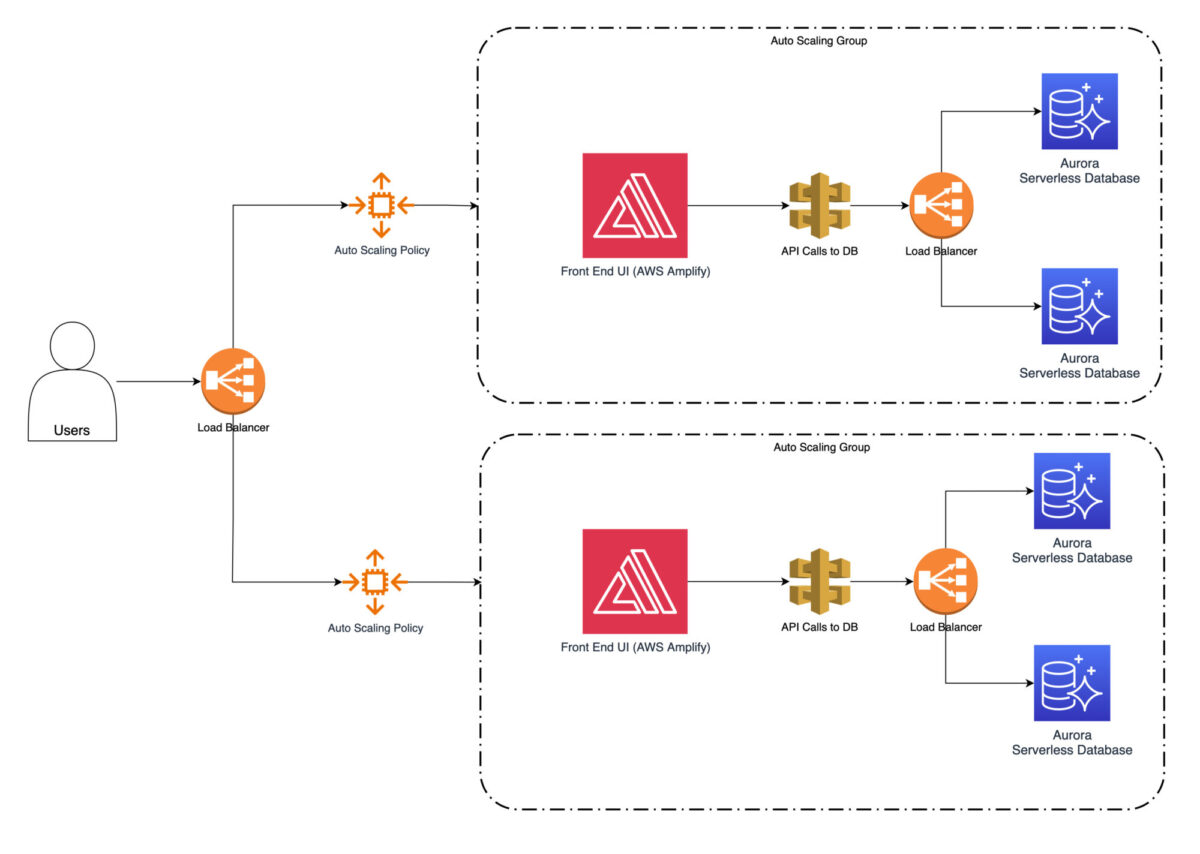
L’étape suivante consiste à configurer la mise à l’échelle automatique pour ajouter automatiquement des instances pendant les périodes de pointe et les supprimer pendant les périodes de faible demande. Cela permet de s’assurer que le site web peut gérer l’augmentation du trafic et maintenir des performances optimales.
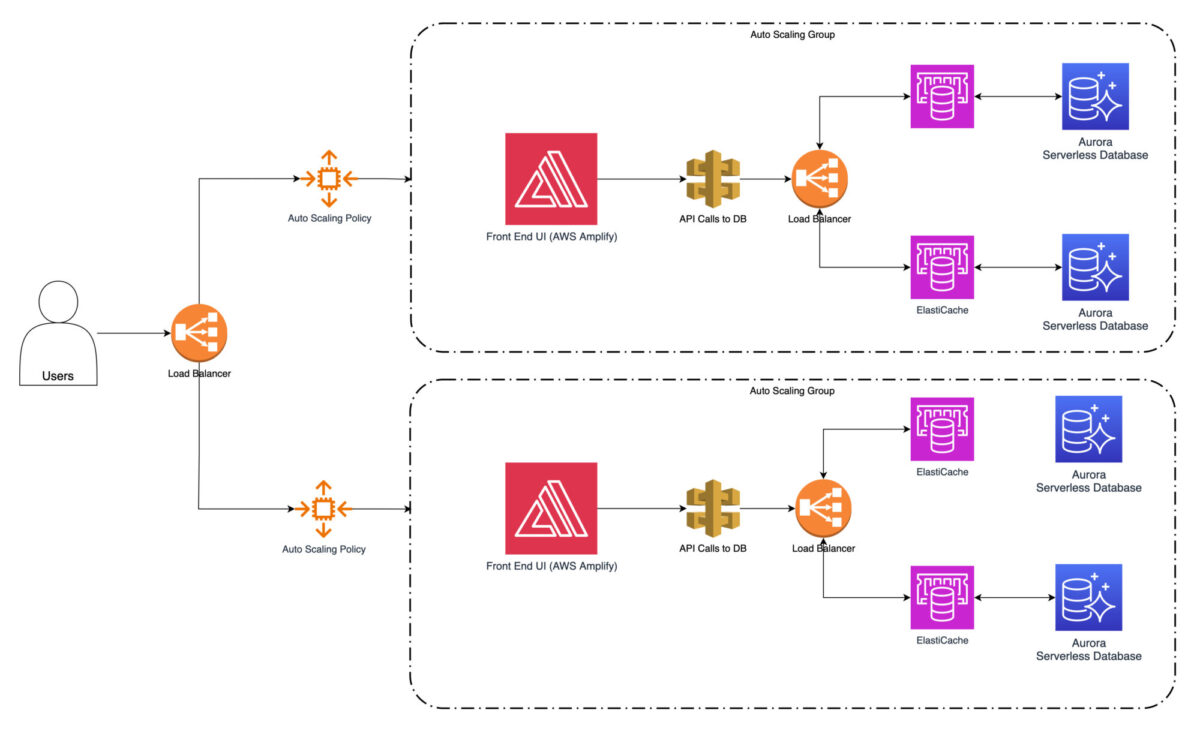
Enfin, il est toujours possible de mettre en œuvre des stratégies de mise en cache à l’aide d’Amazon ElastiCache, ce qui réduira encore le temps nécessaire pour récupérer les données à la source. Les données fréquemment consultées, telles que les informations sur les produits ou les préférences des utilisateurs, peuvent être mises en cache.
Il n’y a pas de risque majeur à ce que les données soient à jour, car ces informations ne changent que très rarement. Cela réduira considérablement la nécessité d’aller les chercher à plusieurs reprises dans les services de base de données. Les temps de réponse et les performances globales du système d’exploitation s’en trouvent considérablement améliorés.
Réflexions finales : Optimiser l’efficacité de l’intégration dans le nuage AWS
L’optimisation des performances dans le cadre de l’intégration de systèmes dans le nuage AWS et la résolution des problèmes de performances sont des tâches permanentes. Au fur et à mesure que votre plateforme évolue, vous devez revoir régulièrement l’architecture AWS.
Pour maintenir des performances optimales, il est conseillé de revoir régulièrement l’architecture AWS et de mettre en œuvre des techniques telles que l’équilibrage de la charge, la mise à l’échelle automatique, les stratégies de mise en cache et la sélection de la stratégie de chargement des données appropriée.
Les stratégies et techniques d’optimisation AWS présentées ici ne sont pas seulement théoriques, mais peuvent être mises en pratique dans des projets réels. Vous pouvez utiliser ces stratégies d’optimisation AWS pour obtenir des systèmes intégrés hautement performants qui répondent aux exigences du paysage numérique dans le monde des affaires d’aujourd’hui.