Les DataFrames sont une structure de données fondamentale dans R, offrant la structure, la polyvalence et les outils nécessaires à l’analyse et à la manipulation des données. Leur importance s’étend à divers domaines, notamment les statistiques, la science des données et la prise de décision fondée sur les données dans tous les secteurs d’activité.
Les DataFrames fournissent la structure et l’organisation nécessaires pour obtenir des informations et prendre des décisions fondées sur des données de manière systématique et efficace.
Les DataFrames en R sont structurés comme des tableaux, avec des lignes et des colonnes. Chaque ligne représente une observation et chaque colonne une variable. Cette structure facilite l’organisation et le traitement des données. Les DataFrames peuvent contenir différents types de données, notamment des nombres, du texte et des dates, ce qui les rend polyvalents.
Dans cet article, je vais vous expliquer l’importance des cadres de données et discuter de leur création à l’aide de la fonction data.frame().
En outre, nous explorerons les méthodes de manipulation des données et verrons comment créer des cadres à partir de fichiers CSV et Excel, comment convertir d’autres structures de données en cadres de données et comment utiliser la bibliothèque tibble.
Voici quelques raisons pour lesquelles les DataFrames sont essentielles dans R :
Importance des DataFrames

- Stockage de données structurées: Les DataFrames offrent un moyen structuré et tabulaire de stocker des données, à l’instar d’une feuille de calcul. Ce format structuré simplifie la gestion et l’organisation des données.
- Types de données mixtes: Les cadres de données peuvent contenir différents types de données au sein d’une même structure. Vous pouvez avoir des colonnes contenant des valeurs numériques, des chaînes de caractères, des facteurs, des dates, etc. Cette polyvalence est essentielle lorsque vous travaillez avec des données réelles.
- Organisation des données: Chaque colonne d’un DataFrame représente une variable, tandis que chaque ligne représente une observation ou un cas. Cette disposition structurée facilite la compréhension de l’organisation des données, ce qui améliore la clarté des données.
- Importation et exportation de données: Les DataFrames permettent d’importer et d’exporter facilement des données à partir de différents formats de fichiers tels que CSV, Excel et les bases de données. Cette fonctionnalité rationalise le processus de travail avec des sources de données externes.
- Interopérabilité: Les DataFrames sont largement pris en charge par les paquets et fonctions R, ce qui garantit leur compatibilité avec d’autres outils et bibliothèques d’analyse statistique et de données. Cette interopérabilité permet une intégration transparente dans l’écosystème R.
- Manipulation des données: R offre un riche écosystème de paquets, dont
"dplyr” est un exemple frappant. Ces packages facilitent le filtrage, la transformation et la synthèse des données à l’aide de DataFrames. Cette capacité est cruciale pour le nettoyage et la préparation des données.
- Analyse statistique: Les DataFrames sont le format de données standard pour de nombreuses fonctions statistiques et d’analyse de données dans R. Vous pouvez effectuer des régressions, des tests d’hypothèse et de nombreuses autres analyses statistiques efficacement à l’aide des DataFrames.
- Visualisation: Les logiciels de visualisation de données de R, comme
ggplot2,fonctionnent de manière transparente avec DataFrames. Il est ainsi facile de créer des diagrammes et des graphiques informatifs pour l’exploration et la communication des données.
- Exploration des données: Les DataFrames facilitent l’exploration des données grâce à des statistiques sommaires, à la visualisation et à d’autres méthodes analytiques. Cela aide les analystes et les scientifiques des données à comprendre les caractéristiques des données et à détecter les modèles ou les valeurs aberrantes.
Comment créer un DataFrame en R
Il existe plusieurs façons de créer un DataFrame en R. Voici quelques-unes des méthodes les plus courantes :
#1. Utilisation de la fonction data.frame()
# Chargez la bibliothèque nécessaire si elle ne l'est pas déjà
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# install.packages("dplyr")
library(dplyr)
# Définissez une graine pour la reproductibilité
set.seed(42)
# Créez un échantillon de DataFrame de ventes avec des noms de produits réels
sales_data <- data.frame(
OrderID = 1001:1010,
Produit = c("Ordinateur portable", "Smartphone", "Tablette", "Casque", "Appareil photo", "TV", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes"),
Quantité = sample(1:10, 10, replace = TRUE),
Prix = round(runif(10, 100, 2000), 2),
Remise = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Affichez le DataFrame des ventes
print(ventes_données)
Voyons ce que notre code va faire :
- Il vérifie d’abord si la bibliothèque
"dplyr” est disponible dans l’environnement R. Si “dplyr” n’est pas disponible, il l’installe et la charge. - Si “dplyr” n’est pas disponible, il installe et charge la bibliothèque.
- Ensuite, il définit une graine aléatoire à des fins de reproductibilité.
- Ensuite, il crée un échantillon de DataFrame de ventes avec nos données remplies.
- Enfin, il affiche le DataFrame des ventes dans la console.
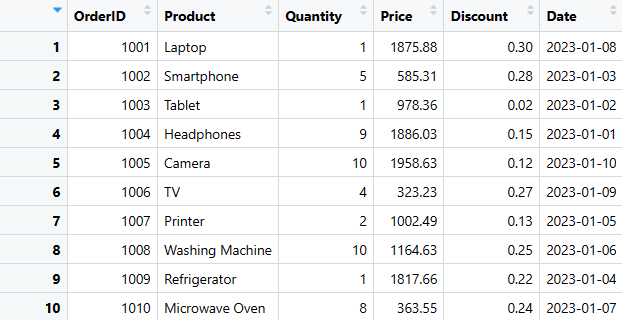
Il s’agit de l’une des méthodes les plus simples pour créer un DataFrame dans R. Nous verrons également comment extraire, ajouter, supprimer et sélectionner des colonnes ou des lignes spécifiques, ainsi que comment résumer les données.
Extraire des colonnes
Il existe deux méthodes pour extraire les colonnes nécessaires de notre cadre de données :
- Pour extraire les trois dernières colonnes d’un DataFrame dans R, vous pouvez utiliser l’indexation.
- Vous pouvez extraire les colonnes d’un DataFrame à l’aide de l’
opérateur $lorsque vous souhaitez accéder à des colonnes individuelles par leur nom.
Nous allons voir les deux ensemble pour gagner du temps :
# Extrayez les trois dernières colonnes (Remise, Prix et Date) du DataFrame sales_data
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Affichez les colonnes extraites
print(dernières_trois_colonnes)
############################################# OU #########################################################
# Extrayez les trois dernières colonnes (Remise, Prix et Date) en utilisant l'opérateur $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_colonne <- sales_data$Date
# Créez un nouveau DataFrame avec les colonnes extraites
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Affichez les colonnes extraites
print(dernières_trois_colonnes)
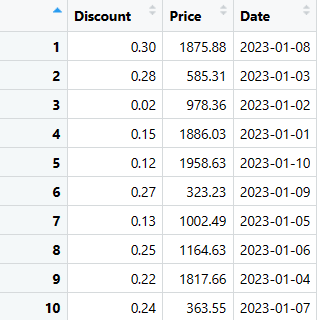
Vous pouvez extraire les colonnes nécessaires en utilisant l’un de ces codes.
Extraire des lignes
Vous pouvez extraire des lignes d’un DataFrame dans R à l’aide de différentes méthodes. Voici une façon simple de procéder :
# Extrayez des lignes spécifiques (lignes 3, 6 et 9) du DataFrame last_three_columns
selected_rows <- last_three_columns[c(3, 6, 9), ]
# Affichez les lignes sélectionnées
print(rangs_sélectionnés)
Vous pouvez également utiliser les conditions spécifiées :
# Extraire et classer les lignes qui répondent aux conditions spécifiées
selected_rows <- sales_data %>%
filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>%
arrange(OrderID) %>%
select(Remise, Prix, Date)
# Affichez les lignes sélectionnées
print(lignes_sélectionnées)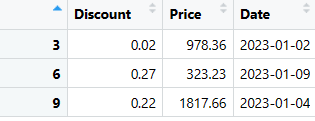
Ajouter une nouvelle ligne
Pour ajouter une nouvelle ligne à un DataFrame existant dans R, vous pouvez utiliser la fonction rbind():
# Créez une nouvelle ligne en tant que cadre de données
new_row <- data.frame(
OrderID = 1011,
Produit = "Cafetière",
Quantité = 2,
Prix = 75,99,
Remise = 0,1,
Date = as.Date("2023-01-12")
)
# Utilisez la fonction rbind() pour ajouter la nouvelle ligne au DataFrame
sales_data <- rbind(sales_data, new_row)
# Affichez le DataFrame mis à jour
print(sales_data)
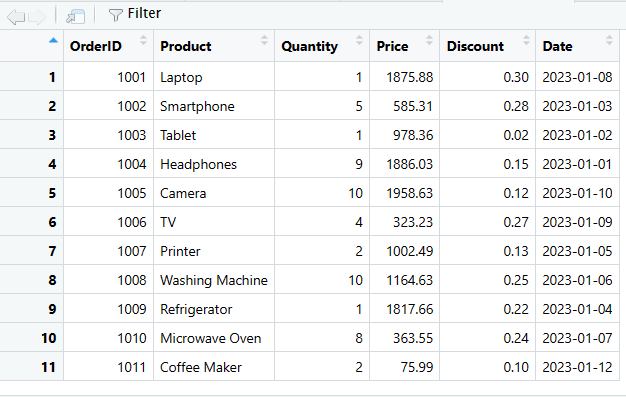
Ajouter une nouvelle colonne
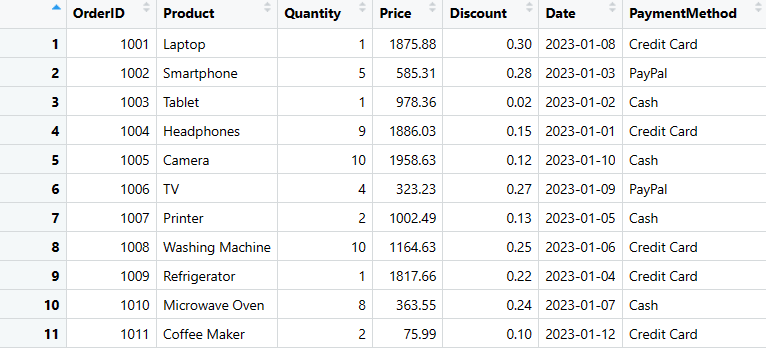
Vous pouvez ajouter des colonnes à votre DataFrame avec un simple code. Ici, je veux ajouter la colonne Mode de paiement à mes données.
# Créez une nouvelle colonne "PaymentMethod" avec des valeurs pour chaque ligne
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Affichez le DataFrame mis à jour
print(sales_data)
Supprimer des lignes
Si vous souhaitez supprimer des lignes inutiles, cette méthode peut s’avérer utile :
# Identifiez la ligne à supprimer par son OrderID
row_to_delete <- sales_data$OrderID == 1010
# Utilisez la ligne identifiée pour l'exclure et créez un nouveau DataFrame
sales_data <- sales_data[!row_to_delete, ]
# Affichez le DataFrame mis à jour sans la ligne supprimée
print(sales_data)
Supprimer des colonnes
Vous pouvez supprimer une colonne d’un DataFrame dans R en utilisant le package dplyr.
# install.packages("dplyr")
library(dplyr)
# Supprimez la colonne "Discount" à l'aide de la fonction select()
sales_data <- sales_data %>% select(-Discount)
# Affichez le DataFrame mis à jour sans la colonne "Discount"
print(sales_data)Obtenir un résumé
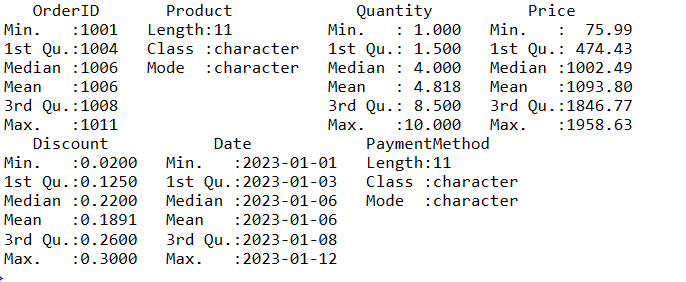
Pour obtenir un résumé de vos données dans R, vous pouvez utiliser la fonction summary(). Cette fonction fournit un aperçu rapide des tendances centrales et de la distribution des variables numériques de vos données.
# Obtenez un résumé des données
data_summary <- summary(sales_data)
# Affichez le résumé
print(données_sommaire)
Voici les différentes étapes que vous pouvez suivre pour manipuler vos données dans un DataFrame.
Passons maintenant à la deuxième méthode de création d’un DataFrame.
#2. Créer un DataFrame R à partir d’un fichier CSV
Pour créer un DataFrame R à partir d’un fichier CSV, vous pouvez utiliser la méthode read.csv()
# Lire le fichier CSV dans un DataFrame
df <- read.csv("my_data.csv")
# Affichez les premières lignes du DataFrame
head(df)Cette fonction lit les données d’un fichier CSV et les convertit. Vous pouvez ensuite travailler avec les données dans R selon vos besoins.
# Installez et chargez le paquetage readr s'il n'est pas déjà installé
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Lire le fichier CSV dans un DataFrame
df <- read_csv("data.csv")
# Affichez les premières lignes du DataFrame
head(df)
vous pouvez utiliser le package readr pour lire un fichier CSV dans R. La fonction read_csv() du package readr est couramment utilisée à cette fin. Elle est plus rapide que la méthode habituelle.
#3. Utilisation de la fonction as.data.frame()
Vous pouvez créer un DataFrame dans R en utilisant la fonction as. data.frame(). Cette fonction vous permet de convertir d’autres structures de données, telles que des matrices ou des listes, en DataFrame.
Voici comment l’utiliser :
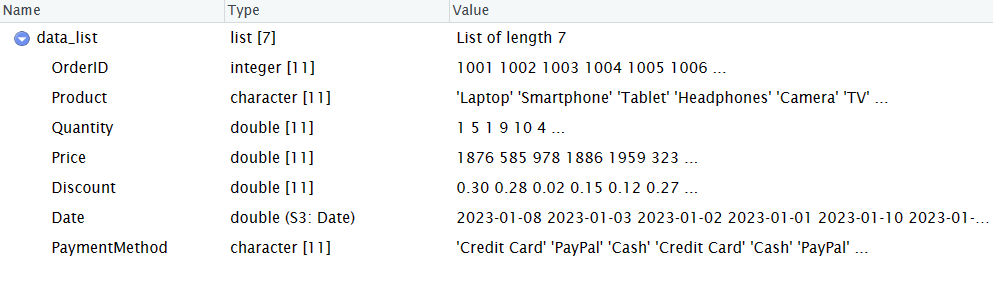
# Créez une liste imbriquée pour représenter les données
data_list <- list(
OrderID = 1001:1011,
Produit = c("Ordinateur portable", "Smartphone", "Tablette", "Casque", "Appareil photo", "Télévision", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière"),
Quantité = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Prix = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Escompte = c(0,3, 0,28, 0,02, 0,15, 0,12, 0,27, 0,13, 0,25, 0,22, 0,24, 0,1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Convertissez la liste imbriquée en DataFrame
sales_data <- as.data.frame(data_list)
# Affichez le DataFrame
print(sales_data)
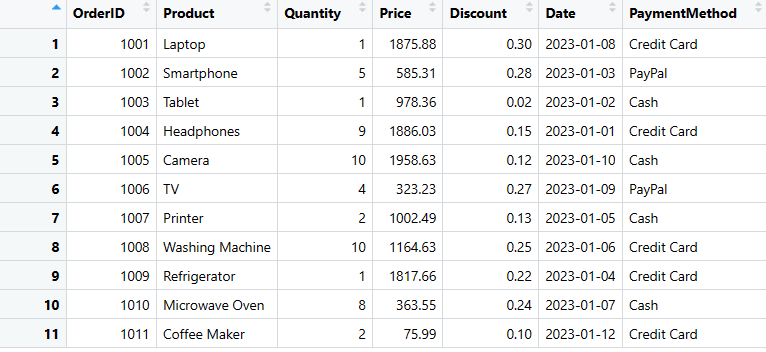
Cette méthode vous permet de créer un DataFrame sans spécifier chaque colonne une à une et est particulièrement utile lorsque vous disposez d’une grande quantité de données.
#4. À partir d’un cadre de données existant
Pour créer un nouveau DataFrame en sélectionnant des colonnes ou des lignes spécifiques dans un DataFrame existant dans R, vous pouvez utiliser des crochets [] pour l’indexation. Voici comment cela fonctionne :
# Sélectionnez des lignes et des colonnes
sales_subset <- sales_data[c(1, 3, 4), c("Produit", "Quantité")]
# Affichez le sous-ensemble sélectionné
print(jeu_de_ventes)
Dans ce code, nous créons un nouveau DataFrame appelé sales_subset, qui contient des lignes spécifiques (1, 3 et 4) et des colonnes spécifiques (“Produit” et “Quantité”) des sales_data.
Vous pouvez ajuster les indices et les noms des lignes et des colonnes pour sélectionner les données dont vous avez besoin.

#5. A partir d’un vecteur
Un vecteur est une structure de données unidimensionnelle dans R qui se compose d’éléments du même type de données, y compris logique, entier, double, caractère, complexe ou brut.
En revanche, un DataFrame R est une structure bidimensionnelle conçue pour stocker des données dans un format tabulaire avec des lignes et des colonnes. Il existe plusieurs méthodes pour créer un DataFrame R à partir d’un vecteur, et l’un de ces exemples est fourni ci-dessous.
# Créez des vecteurs pour chaque colonne
OrderID <- 1001:1011
Produit <- c("Ordinateur portable", "Smartphone", "Tablette", "Casque", "Appareil photo", "Télévision", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière")
Quantité <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Prix <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card", "Cash", "Credit Card")
# Créez le DataFrame à l'aide de data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Produit = Produit,
Quantité = Quantité,
Prix = Prix,
Remise = Remise,
Date = Date,
Mode de paiement = Mode de paiement
)
# Affichez le DataFrame
print(sales_data)
Dans ce code, nous créons des vecteurs distincts pour chaque colonne, puis nous utilisons la fonction data.frame() pour combiner ces vecteurs dans un DataFrame nommé sales_data.
Cela vous permet de créer un tableau de données structuré à partir de vecteurs individuels dans R.
#6. À partir d’un fichier Excel
Pour créer un DataFrame en important un fichier Excel dans R, vous pouvez utiliser des packages tiers comme readxl puisque la base R n’offre pas de support natif pour la lecture des fichiers CSV. L’une de ces fonctions de lecture de fichiers Excel est read_excel().
# Chargez la bibliothèque readxl
library(readxl)
# Définissez le chemin d'accès au fichier Excel
excel_file_path <- "votre_fichier.xlsx" # Remplacer par le chemin du fichier réel
# Lisez le fichier Excel et créez un DataFrame
data_frame_from_excel <- read_excel(excel_file_path)
# Affichez le DataFrame
print(data_frame_from_excel)
Ce code lira le fichier Excel et stockera ses données dans un DataFrame R, ce qui vous permettra de travailler avec les données dans votre environnement R.
#7. A partir d’un fichier texte
Vous pouvez utiliser la fonction read.table() dans R pour importer un fichier texte dans un DataFrame. Cette fonction nécessite deux paramètres essentiels : le nom du fichier que vous souhaitez lire et le délimiteur qui spécifie comment les champs du fichier sont séparés.
# Définissez le nom du fichier et le délimiteur
nom_du_fichier <- "votre_fichier_texte.txt" # Remplacer par le nom réel du fichier
delimiter <- "\t" # Remplacez par le délimiteur actuel (par exemple, "\t" pour la séparation par tabulation, "," pour CSV)
# Utilisez la fonction read.table() pour créer un DataFrame
data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter)
# Affichez le DataFrame
print(data_frame_from_text)
Ce code lira le fichier texte et le créera dans R, le rendant accessible pour l’analyse des données dans votre environnement R.
#8. Utilisation de Tibble
Pour le créer en utilisant les vecteurs fournis et en utilisant la bibliothèque tidyverse, vous pouvez suivre les étapes suivantes :
# Chargez la bibliothèque tidyverse
library(tidyverse)
# Créez un tibble en utilisant les vecteurs fournis
sales_data <- tibble(
OrderID = 1001:1011,
Produit = c("Ordinateur portable", "Smartphone", "Tablette", "Casque", "Appareil photo", "Télévision", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière"),
Quantité = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Prix = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Escompte = c(0,3, 0,28, 0,02, 0,15, 0,12, 0,27, 0,13, 0,25, 0,22, 0,24, 0,1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Affichez le tableau des ventes créé
print(sales_data)
Ce code utilise la fonction tibble() de la bibliothèque tidyverse pour créer un DataFrame tibble nommé sales_data. Le format tibble offre une impression plus informative que le cadre de données R par défaut, comme vous l’avez mentionné.
Comment utiliser efficacement les DataFrames en R
L’utilisation efficace des DataFrames dans R est essentielle pour la manipulation et l’analyse des données. Les DataFrames sont une structure de données fondamentale dans R et sont généralement créées et manipulées à l’aide de la fonction data.frame. Voici quelques conseils pour travailler efficacement :
- Avant de créer un cadre, assurez-vous que vos données sont propres et bien structurées. Supprimez les lignes et les colonnes inutiles, gérez les valeurs manquantes et assurez-vous que les types de données sont appropriés.
- Définissez des types de données appropriés pour vos colonnes (par exemple, numérique, caractère, facteur, date). Cela peut améliorer l’utilisation de la mémoire et la vitesse de calcul.
- Utilisez l’indexation et le sous-ensemble pour travailler avec de plus petites parties de vos données. Les opérateurs
subset()et[ ]sont utiles à cette fin.
- Les opérateurs
attach()etdetach() peuvent être pratiques, mais ils peuvent également entraîner des ambiguïtés et des comportements inattendus.
- R est très optimisé pour les opérations vectorielles. Dans la mesure du possible, utilisez des fonctions vectorielles plutôt que des boucles pour la manipulation des données.
- Les boucles imbriquées peuvent être lentes dans R. Au lieu d’utiliser des boucles imbriquées, essayez d’utiliser des opérations vectorisées ou d’appliquer des fonctions telles que
lapplyousapply.
- Les DataFrames de grande taille peuvent consommer beaucoup de mémoire. Envisagez d’utiliser les packages
data.tableoudtplyr, qui sont plus efficaces en termes de mémoire pour les grands ensembles de données.
- R dispose d’un large éventail de packages pour la manipulation des données. Utilisez des packages tels que
dplyr,tidyretdata.tablepour des transformations de données efficaces.
- Minimisez l’utilisation de variables globales, en particulier lorsque vous travaillez avec plusieurs DataFrames. Utilisez des fonctions et passez les DataFrames en tant qu’arguments.
- Lorsque vous travaillez avec des données agrégées, utilisez les fonctions
group_by()etsummarize()dedplyrpour effectuer des calculs de manière efficace.
- Pour les grands ensembles de données, envisagez d’utiliser le traitement parallèle avec des packages tels que
parallelouforeachpour accélérer les opérations.
- Lorsque vous lisez des données dans R, utilisez des fonctions telles que
readroudata.table::freadau lieu des fonctions R de base telles queread.csvpour accélérer l’importation des données.
- Pour les très grands ensembles de données, envisagez d’utiliser des systèmes de base de données ou des formats de stockage spécialisés tels que Feather, Arrow ou Parquet.
En suivant ces bonnes pratiques, vous pouvez travailler efficacement avec les DataFrames dans R, ce qui rendra vos tâches de manipulation et d’analyse de données plus faciles à gérer et plus rapides.
Réflexions finales
La création de dataframes en R est simple et plusieurs méthodes sont à votre disposition. J’ai souligné l’importance des cadres de données et discuté de leur création à l’aide de la fonction data.frame().
En outre, nous avons exploré les méthodes de manipulation des données et abordé la création à partir de fichiers CSV et Excel, la conversion d’autres structures de données en cadres de données et l’utilisation de la bibliothèque tibble.
Vous pourriez être intéressé par les meilleurs IDE pour la programmation R.