Apache Kafka est un service de diffusion de messages en continu qui permet à différentes applications d’un système distribué de communiquer et de partager des données par le biais de messages.
Il fonctionne comme un système pub/sub où les applications productrices publient des messages et les systèmes consommateurs s’y abonnent.
Apache Kafka vous permet d’adopter une architecture faiblement couplée entre les parties de votre système qui produisent et consomment des données. Cela simplifie la conception et la gestion du système. Kafka s’appuie sur Zookeeper pour la gestion des métadonnées et la synchronisation des différents éléments du cluster.

Caractéristiques d’Apache Kafka
Apache K afka est devenu populaire, entre autres, pour les raisons suivantes
- Évolutif grâce aux clusters et aux partitions
- Rapide, capable d’effectuer 2 millions d’écritures par seconde
- Il conserve l’ordre dans lequel les messages sont envoyés
- Fiable grâce à son système de répliques
- Il peut être mis à niveau sans interruption de service
Examinons maintenant quelques-uns des cas d’utilisation courants de Kafka.
Cas d’utilisation courants d’Apache Kafka
Kafka est souvent utilisé pour le traitement de données volumineuses, l’enregistrement et l’agrégation d’événements tels que les clics de boutons pour l’analyse, et la combinaison de journaux provenant de différentes parties d’un système dans un emplacement central.
Il facilite la communication entre les différentes applications d’un système et le traitement en temps réel des données provenant d’appareils IoT.
Voyons maintenant les étapes détaillées de l’installation de Kafka sous Windows et Linux.
Installation de Kafka sur Windows
Tout d’abord, vérifiez si Java est installé sur votre machine pour installer Apache Kafka sur Windows. Ouvrez l’invite de commande en mode administrateur et entrez la commande suivante :
java --versionSi Java est installé, vous devriez obtenir le numéro de version du JDK actuellement installé.
Si vous obtenez un message d’erreur indiquant que la commande n’a pas été reconnue, cela signifie que Java n’est pas installé et que vous devez l’installer. Pour installer Java, rendez-vous sur Adoptium.net et cliquez sur le bouton de téléchargement.
Le fichier d’installation de Java devrait être téléchargé. Une fois le téléchargement terminé, exécutez le programme d’installation. L’invite d’installation devrait s’ouvrir.
Appuyez plusieurs fois sur Suivant pour choisir les options par défaut. L’installation devrait alors commencer. Vérifiez l’installation en fermant l’invite de commande, en ouvrant à nouveau une autre invite de commande en mode administrateur et en entrant la commande suivante :
java --versionCette fois, vous devriez obtenir la version du JDK que vous venez d’installer. Une fois l’installation terminée, nous pouvons commencer à installer Kafka.
Pour installer Kafka, allez d’abord sur le site web de Kafka.

Cliquez sur le lien, et vous devriez arriver à la page Downloads. Téléchargez les derniers binaires disponibles.
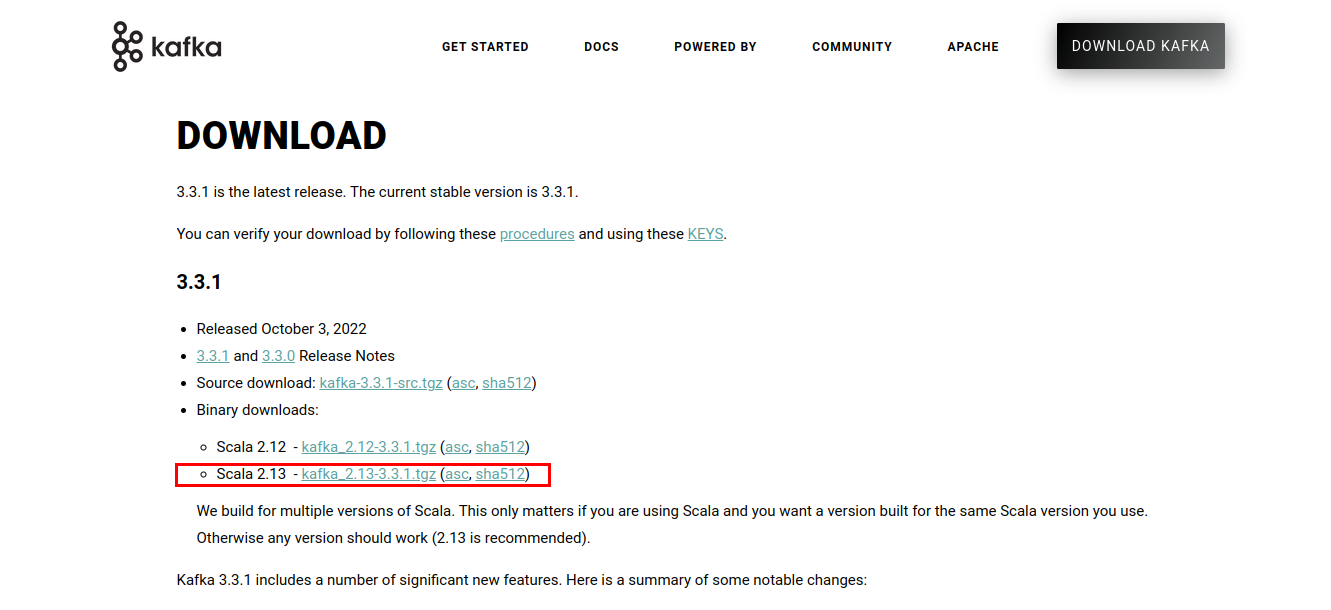
Les scripts et les binaires de Kafka seront téléchargés dans un fichier .tgz. Après le téléchargement, vous devez extraire les fichiers de l’archive .tgz. Pour ce faire, j’utiliserai WinZip, qui peut être téléchargé à partir du site web de WinZip.
Après avoir extrait le fichier, déplacez-le dans le répertoire C:\Nde sorte que le chemin d’accès au fichier devienne C:\Nkafka
Ouvrez ensuite l’invite de commande en mode administrateur et démarrez Zookeeper en naviguant d’abord jusqu’au répertoire Kafka. Et exécutez le fichier zookeeper-server-start.bat avec zookeeper.properties comme fichier de configuration
cd C:\NKafka
binwindows\zookeeper-server-start.bat configzookeeper.propertiesUne fois Zookeeper lancé, nous devons ajouter le fichier exécutable wmic utilisé par Kafka dans le PATH de notre système,
set PATH=C:\NWindows\NSystem32\Nwbem\N;%PATH% ;Ensuite, démarrez le serveur Apache Kafka en ouvrant une autre session d’invite de commande en mode administrateur et en naviguant jusqu’au dossier C:\Nkafka
cd C:\kafkaDémarrez ensuite Kafka en exécutant
bin\windows\kafka-server-start.bat config\server.propertiesKafka devrait alors être en cours d’exécution. Vous pouvez personnaliser les propriétés du serveur, comme l’endroit où les journaux sont écrits dans le fichier server.properties.
Installation de Kafka sur Linux
Tout d’abord, assurez-vous que votre système est à jour en mettant à jour tous les paquets
sudo apt update && sudo apt upgradeEnsuite, vérifiez que Java est installé sur votre machine en exécutant
java --versionSi Java est installé, vous verrez le numéro de version. Si ce n’est pas le cas, vous pouvez l’installer à l’aide d’apt.
sudo apt install default-jdkEnsuite, nous pouvons installer Apache Kafka en téléchargeant les binaires depuis le site web.
Ouvrez votre terminal et naviguez jusqu’au dossier où le téléchargement a été sauvegardé. Dans mon cas, je dois naviguer vers le dossier Downloads.
cd TéléchargementsUne fois dans le dossier Downloads, extrayez les fichiers téléchargés à l’aide de tar:
tar -xvzf kafka_2.13-3.3.1.tgzNaviguez jusqu’au dossier extrait
cd kafka_2.13-3.3.1.tgzListez les répertoires et les fichiers.
Une fois dans le dossier, démarrez un serveur Zookeeper en exécutant le script zookeeper-server-start.sh situé dans le répertoire bin du dossier extrait.
Le script nécessite un fichier de configuration de Zookeeper. Le fichier par défaut s’appelle zookeeper.properties et se trouve dans le sous-répertoire config.
Ainsi, pour démarrer le serveur, utilisez la commande :
bin/zookeeper-server-start.sh config/zookeeper.propertiesUne fois Zookeeper lancé, nous pouvons démarrer le serveur Apache Kafka. Le script kafka-server-start.sh se trouve également dans le répertoire bin. La commande attend également un fichier de configuration. Le fichier par défaut est server.properties, stocké dans le fichier config.
bin/kafka-server-start.sh config/server.propertiesCela devrait permettre de lancer Apache Kafka. Dans le répertoire bin, vous trouverez de nombreux scripts permettant de créer des sujets, de gérer les producteurs et les consommateurs. Vous pouvez également personnaliser les propriétés du serveur dans le fichier server.properties.
Mot de la fin
Dans ce guide, nous avons vu comment installer Java et Apache Kafka. Bien que vous puissiez installer et gérer les clusters Kafka manuellement, vous pouvez également utiliser des options gérées telles que Amazon Web Services et Confluent.
Ensuite, vous pouvez apprendre le traitement des données avec Kafka et Spark.