
Apprenez tout ce que vous devez savoir sur l’analyse exploratoire des données, un processus critique utilisé pour découvrir des tendances et des modèles et pour résumer des ensembles de données à l’aide de résumés statistiques et de représentations graphiques.
Comme tout projet, un projet de science des données est un long processus qui nécessite du temps, une bonne organisation et le respect scrupuleux de plusieurs étapes. L’analyse exploratoire des données (AED) est l’une des étapes les plus importantes de ce processus.
C’est pourquoi, dans cet article, nous verrons brièvement ce qu’est l’analyse exploratoire des données et comment vous pouvez l’effectuer avec R !
Qu’est-ce que l’analyse exploratoire des données ?
L’analyse exploratoire des données examine et étudie les caractéristiques d’un ensemble de données avant de le soumettre à une application, qu’elle soit exclusivement commerciale, statistique ou d’apprentissage automatique.

Ce résumé de la nature de l’information et de ses principales particularités se fait généralement par des méthodes visuelles, telles que des représentations graphiques et des tableaux. Cette pratique est réalisée en amont, précisément pour évaluer le potentiel de ces données, qui feront l’objet d’un traitement plus complexe dans le futur.
L’AED permet donc de
- De formuler des hypothèses sur l’utilisation de ces informations ;
- D’explorer les détails cachés dans la structure des données
- Identifier les valeurs manquantes, les valeurs aberrantes ou les comportements anormaux ;
- Découvrir les tendances et les variables pertinentes dans leur ensemble ;
- Écarter les variables non pertinentes ou les variables en corrélation avec d’autres ;
- Déterminer la modélisation formelle à utiliser.
Quelle est la différence entre l’analyse descriptive et l’analyse exploratoire des données ?
Il existe deux types d’analyse de données, l’analyse descriptive et l’analyse exploratoire, qui vont de pair, bien qu’elles aient des objectifs différents.
La première s’attache à décrire le comportement des variables, par exemple la moyenne, la médiane, le mode, etc.
L’analyse exploratoire vise à identifier les relations entre les variables, à extraire des informations préliminaires et à orienter la modélisation vers les paradigmes d’apprentissage automatique les plus courants : classification, régression et regroupement.
Les deux types d’analyse peuvent avoir en commun une représentation graphique ; cependant, seule l’analyse exploratoire cherche à apporter des informations exploitables, c’est-à-dire des informations qui incitent le décideur à prendre des mesures.
Enfin, alors que l’analyse exploratoire des données cherche à résoudre des problèmes et à apporter des solutions qui guideront les étapes de la modélisation, l’analyse descriptive, comme son nom l’indique, vise uniquement à produire une description détaillée de l’ensemble de données en question.
| Analyse descriptive | Analyse exploratoire des données |
| Analyse le comportement | Analyse le comportement et la relation |
| Fournit un résumé | Conduit à des spécifications et à des actions |
| Organise les données sous forme de tableaux et de graphiques | Organise les données sous forme de tableaux et de graphiques |
| N’a pas de pouvoir explicatif significatif | A un pouvoir explicatif significatif |
Quelques cas d’utilisation pratique de l’EDA
#1. Marketing numérique
Lemarketing numérique est passé d’un processus créatif à un processus axé sur les données. Les organisations de marketing utilisent l’analyse exploratoire des données pour déterminer les résultats des campagnes ou des efforts et pour guider les décisions d’investissement et de ciblage des consommateurs.
Les études démographiques, la segmentation de la clientèle et d’autres techniques permettent aux spécialistes du marketing d’utiliser de grandes quantités de données d’achat, d’enquêtes et de panels de consommateurs pour comprendre et communiquer la stratégie de marketing.
L’analyse exploratoire du web permet aux spécialistes du marketing de collecter des informations au niveau de la session sur les interactions sur un site web. Google Analytics est un exemple d’outil d’analyse gratuit et populaire que les spécialistes du marketing utilisent à cette fin.
Les techniques exploratoires fréquemment utilisées en marketing comprennent la modélisation du marketing mix, l’analyse des prix et des promotions, l’optimisation des ventes et l’analyse exploratoire des clients, par exemple la segmentation.
#2. Analyse exploratoire de portefeuille
Une application courante de l’analyse exploratoire des données est l’analyse exploratoire de portefeuille. Une banque ou un organisme de crédit possède une collection de comptes dont la valeur et le risque varient.
Les comptes peuvent varier en fonction du statut social du titulaire (riche, classe moyenne, pauvre, etc.), de sa situation géographique, de sa valeur nette et de nombreux autres facteurs. Le prêteur doit trouver un équilibre entre le rendement du prêt et le risque de défaillance pour chaque prêt. La question est alors de savoir comment évaluer le portefeuille dans son ensemble.
Le prêt le moins risqué peut être destiné à des personnes très riches, mais il y a un nombre très limité de personnes riches. En revanche, de nombreux pauvres peuvent prêter, mais avec un risque plus élevé.
La solution d’analyse exploratoire des données peut combiner l’analyse des séries temporelles avec de nombreux autres problèmes pour décider quand prêter de l’argent à ces différents segments d’emprunteurs ou le taux de prêt. Les intérêts sont facturés aux membres d’un segment de portefeuille pour couvrir les pertes parmi les membres de ce segment.
#3. L’analyse exploratoire des risques
Des modèles prédictifs sont développés dans le secteur bancaire afin de fournir des certitudes sur les scores de risque pour les clients individuels. Les scores de crédit sont conçus pour prédire le comportement délinquant d’un individu et sont largement utilisés pour évaluer la solvabilité de chaque demandeur.
En outre, l’analyse du risque est effectuée dans le monde scientifique et dans le secteur de l’assurance. Elle est également largement utilisée dans les institutions financières telles que les sociétés de passerelles de paiement en ligne pour analyser si une transaction est authentique ou frauduleuse.
Pour ce faire, elles utilisent l’historique des transactions du client. Il est plus couramment utilisé pour les achats par carte de crédit ; lorsqu’il y a un pic soudain dans le volume de transactions du client, celui-ci reçoit un appel de confirmation s’il a initié la transaction. Cela permet également de réduire les pertes dues à de telles circonstances.
Analyse exploratoire des données avec R
La première chose dont vous avez besoin pour effectuer une AED avec R est de télécharger R base et R Studio (IDE), puis d’installer et de charger les paquets suivants :
#Installation des paquets
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Chargement des paquets
library(dplyr)
bibliothèque(ggplot2)
bibliothèque(magrittr)
bibliothèque(tsibble)
bibliothèque(forecast)
bibliothèque(skimr)
Pour ce tutoriel, nous utiliserons un jeu de données économiques qui est intégré à R et qui fournit des indicateurs économiques annuels de l’économie américaine, et nous changerons son nom en econ pour plus de simplicité :
econ <- ggplot2::economics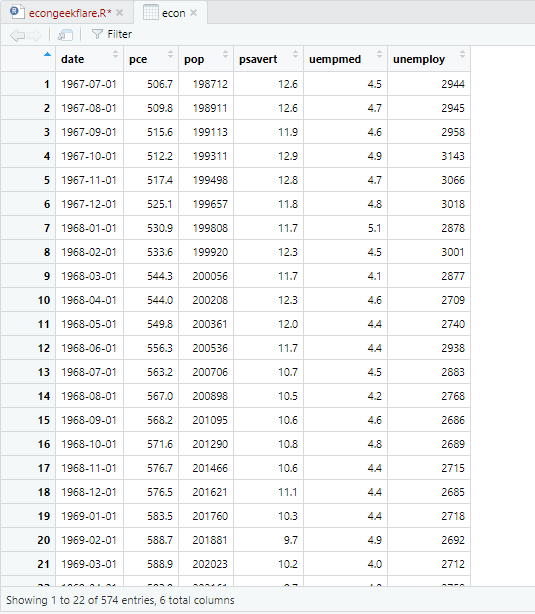
Pour effectuer l’analyse descriptive, nous utiliserons le paquet skimr, qui calcule ces statistiques d’une manière simple et bien présentée :
#Analyse descriptive
skimr::skim(econ)
Vous pouvez également utiliser la fonction summary pour l’analyse descriptive :
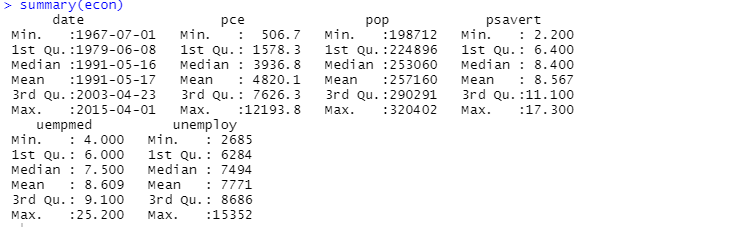
Ici, l’analyse descriptive montre 547 lignes et 6 colonnes dans l’ensemble de données. La valeur minimale est pour 1967-07-01, et la valeur maximale pour 2015-04-01. De même, elle indique également la valeur moyenne et l’écart-type.
Vous avez maintenant une idée de ce que contient l’ensemble de données econ. Traçons un histogramme de la variable uempmed pour mieux examiner les données :
#Histogramme du chômage
econ %>%
ggplot2::ggplot()
ggplot2::aes(x = uempmed)
ggplot2::geom_histogram()
labs(x = "Chômage", title = "Taux de chômage mensuel aux États-Unis entre 1967 et 2015")
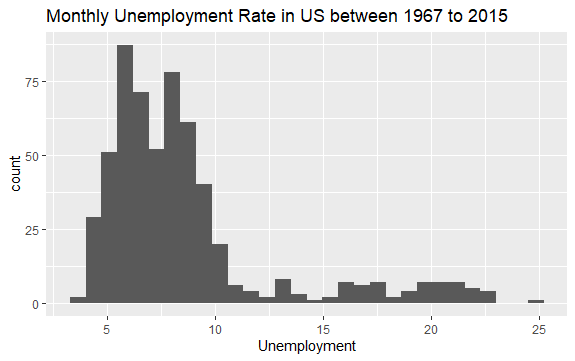
La distribution de l’histogramme montre qu’il a une queue allongée sur la droite ; c’est-à-dire qu’il y a peut-être quelques observations de cette variable avec des valeurs plus “extrêmes”. La question qui se pose est la suivante : au cours de quelle période ces valeurs ont-elles été observées et quelle est la tendance de la variable ?
La manière la plus directe d’identifier la tendance d’une variable est d’utiliser un graphique linéaire. Ci-dessous, nous générons un graphique linéaire et ajoutons une ligne de lissage :
#Graphique linéaire du chômage
econ %>%
ggplot2::autoplot(uempmed)
ggplot2::geom_smooth()
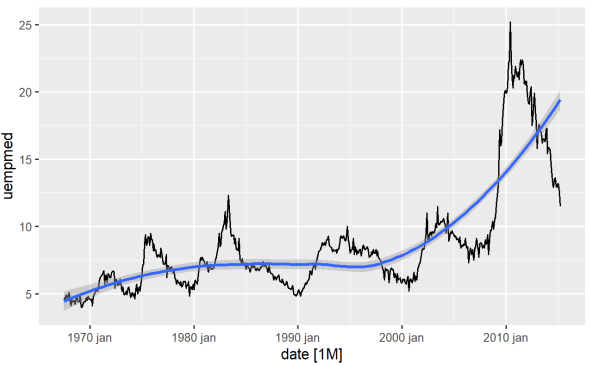
Ce graphique nous permet d’identifier que dans la période la plus récente, dans les dernières observations de 2010, il y a une tendance à l’augmentation du chômage, dépassant l’histoire observée dans les décennies précédentes.
Un autre point important, en particulier dans les contextes de modélisation économétrique, est la stationnarité de la série, c’est-à-dire que la moyenne et la variance sont-elles constantes dans le temps ?
Lorsque ces hypothèses ne sont pas vérifiées dans une variable, on dit que la série a une racine unitaire (non stationnaire), de sorte que les chocs que subit la variable génèrent un effet permanent.
Cela semble avoir été le cas pour la variable en question, la durée du chômage. Nous avons vu que les fluctuations de la variable se sont considérablement modifiées, ce qui a des implications fortes liées aux théories économiques qui traitent des cycles. Mais si l’on s’écarte de la théorie, comment vérifier concrètement si la variable est stationnaire ?
Le progiciel Forecast dispose d’une excellente fonction permettant d’appliquer des tests, tels que ADF, KPSS et autres, qui renvoient déjà le nombre de différences nécessaires pour que la série soit stationnaire :
#Utilisation du test ADF pour vérifier la stationnarité
forecast::ndiffs(
x = econ$uempmed,
test = "adf")
Ici, la valeur p supérieure à 0,05 montre que les données ne sont pas stationnaires.
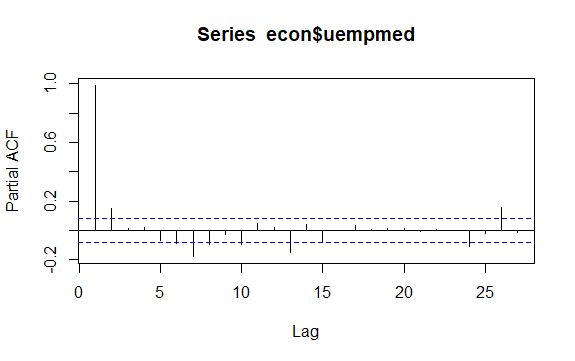
Une autre question importante dans les séries temporelles est l’identification des corrélations possibles (la relation linéaire) entre les valeurs retardées de la série. Les corrélogrammes ACF et PACF permettent de l’identifier.
Comme la série ne présente pas de saisonnalité mais une certaine tendance, les autocorrélations initiales ont tendance à être importantes et positives car les observations proches dans le temps sont également proches en valeur.
Ainsi, la fonction d’autocorrélation (ACF) d’une série temporelle tendancielle a tendance à avoir des valeurs positives qui diminuent lentement au fur et à mesure que les retards augmentent.
#Les données résiduelles du chômage
checkresiduals(econ$uempmed)
pacf(econ$uempmed)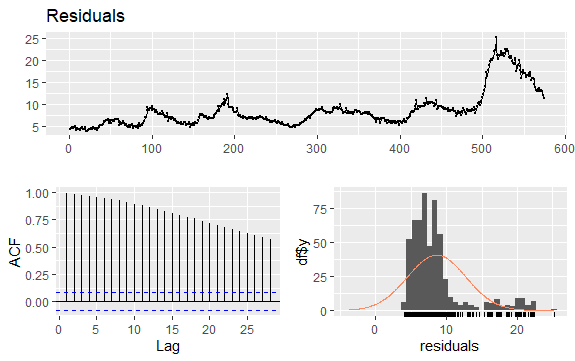
Conclusion
Lorsque l’on met la main sur des données plus ou moins propres, c’est-à-dire déjà nettoyées, on est immédiatement tenté de se plonger dans l’étape de construction du modèle pour en tirer les premiers résultats. Il faut résister à cette tentation et commencer à faire de l’analyse exploratoire de données, qui est simple mais qui permet de tirer des enseignements puissants des données.
Vous pouvez également explorer les meilleures ressources pour apprendre les statistiques pour la science des données.