Le SERP scraping est de plus en plus populaire dans la communauté informatique, mais de quoi s’agit-il exactement ? Suivez ce guide et découvrez-le ! Vous apprendrez à construire un SERP scraper en Python et à extraire automatiquement les données des résultats de recherche de Google.
Plongeons dans le vif du sujet !
Qu’est-ce que le SERP ?
SERP, abréviation de “Search Engine Results Page“, est la page affichée par les moteurs de recherche tels que Google lorsqu’un utilisateur saisit une requête. Elle comprend généralement une liste de liens vers des pages web et des extraits de texte décrivant leur contenu.
La SERP est le principal moyen pour les utilisateurs de découvrir des informations en ligne. C’est pourquoi les entreprises cherchent à apparaître en première position dans les pages de recherche afin de bénéficier d’une meilleure visibilité et d’un trafic organique plus important. L’obtention de données SERP est cruciale pour le SEO(Search Engine Optimization), en particulier lorsqu’il s’agit d’étudier les pages de vos concurrents et la manière dont ils abordent un mot-clé particulier.
Apprenez à récupérer ces données !
Comment construire un SERP Scraper de Google : Tutoriel étape par étape
Suivez cette section guidée et apprenez à construire un script de récupération des SERP de Google en Python.
Étape 1 : Configuration du projet
Tout d’abord, assurez-vous que Python 3 est installé sur votre machine. Sinon, téléchargez le programme d’installation, lancez-le et suivez l’assistant. Un IDE Python vous sera également utile. Nous vous recommandons PyCharm Community Edition ou Visual Studio Code avec l’extension Python.
Ensuite, initialisez un projet Python avec un environnement virtuel en utilisant les commandes ci-dessous :
mkdir serp-scraper
cd youtube-scraper
python -m venv envLe répertoire serp-scraper créé ci-dessus représente le dossier du projet de votre script Python.
Pour activer l’environnement, exécutez la commande suivante sous Linux ou macOS :
./env/bin/activateSous Windows, par contre, exécutez :
env/Scripts/activateOuvrez le dossier du projet dans votre IDE et créez un fichier scraper.py. Il s’agit d’un fichier vierge, mais il contiendra bientôt la logique de scraping SERP.
Génial, vous avez maintenant un environnement Python pour votre SERP scraper !
Étape 2 : Installer les bibliothèques de scraping
Google est une plateforme qui nécessite une interaction avec l’utilisateur pour fonctionner correctement. Il n’est pas facile de forger une URL de recherche Google correcte, et la meilleure façon de traiter avec le moteur de recherche est de le faire dans le navigateur. Par conséquent, le scraping des données SERP nécessite un outil capable de rendre des pages web dans un navigateur contrôlable, tout comme Selenium!
Dans un environnement virtuel Python activé, exécutez la commande ci-dessous pour ajouter le paquetage selenium aux dépendances de votre projet :
pip install seleniumCette instruction peut prendre un certain temps, soyez patient.
Pour commencer à utiliser Selenium dans scraper.py, ajoutez-y les lignes suivantes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# pour contrôler une fenêtre Chrome en mode headless
options = Options()
options.add_argument('--headless=new') # commentez-le pour les tests
# initialiser une instance de pilote web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options
)
# se connecter à la page cible
driver.get("https://google.com/")
# logique de scraping...
# fermer le navigateur et libérer les ressources
driver.quit()Ce script crée une instance de Chrome WebDriver, l’objet qui vous permet de contrôler par programme une fenêtre Chrome. L’option --headless=new configure Chrome pour qu’il fonctionne en mode headless. À des fins de débogage, il est préférable de commenter cette ligne afin que vous puissiez suivre en direct ce que fait le script automatisé.
Merveilleux ! Vous pouvez maintenant récupérer des sites web dynamiques!
Étape 3 : Se connecter à Google
Utilisez la fonction get() exposée par l’objet driver pour vous connecter à la page cible :
driver.get("https://google.com/")Cela demande au navigateur contrôlé d’ouvrir la page identifiée par l’URL donnée dans l’onglet principal.
Voici à quoi ressemble votre SERP scraper jusqu’à présent :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# pour contrôler une fenêtre Chrome en mode headless
options = Options()
options.add_argument('--headless=new') # commentez-le pour les tests
# initialiser une instance de pilote web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options
)
# se connecter à la page cible
driver.get("https://google.com/")
# logique de scraping...
# fermer le navigateur et libérer les ressources
driver.quit()Si vous exécutez le script en mode tête, vous verrez la fenêtre de navigateur suivante pendant une fraction de seconde avant que l’instruction quit() ne la ferme :
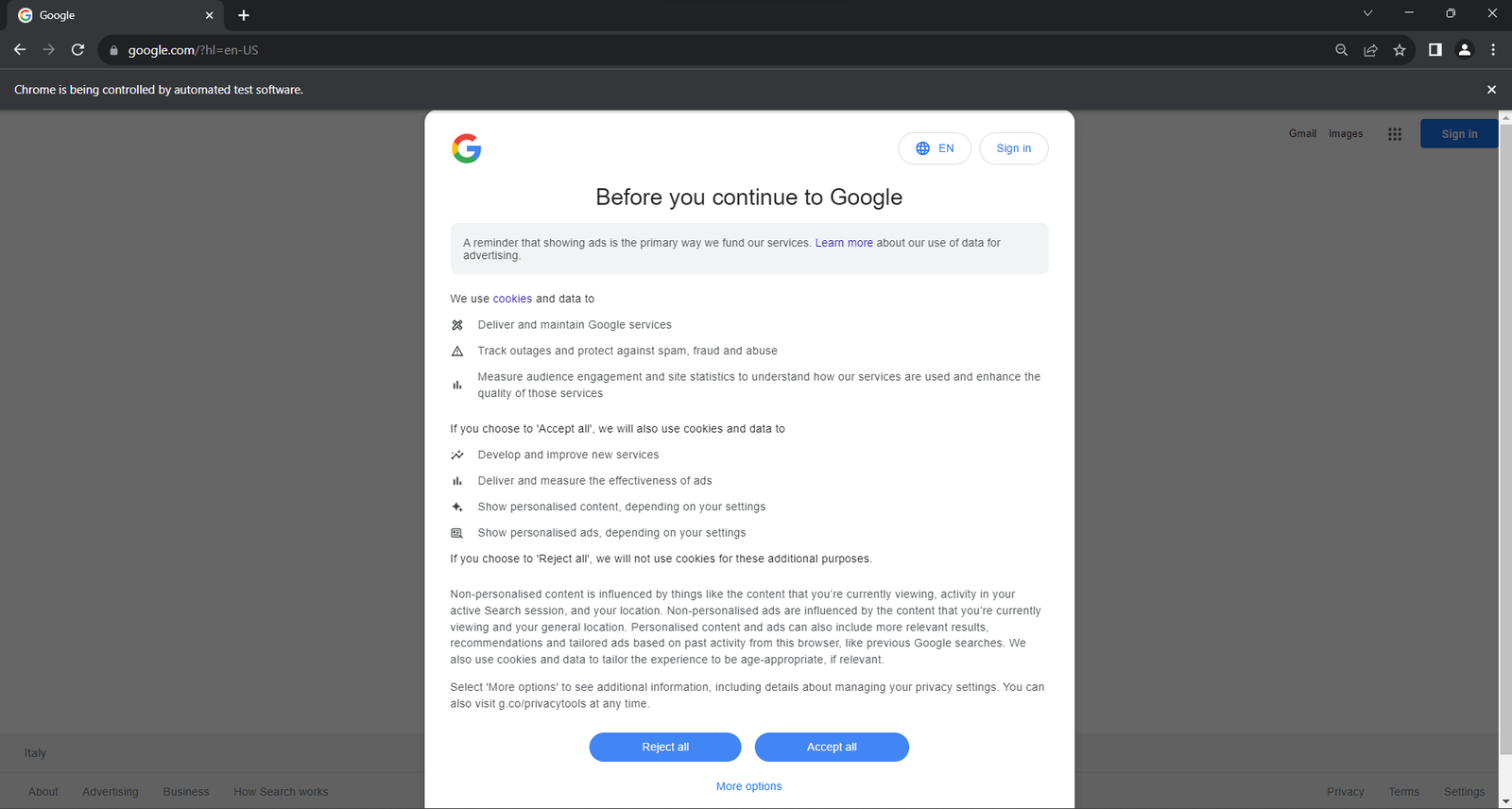
Le message “Chrome est contrôlé par un logiciel de test automatisé” garantit que Selenium contrôle Chrome comme souhaité.
Si le script est exécuté à partir d’un serveur ou d’une machine dans l’UE (Union européenne), Google affichera la boîte de dialogue relative à la politique en matière de cookies pour des raisons liées au GDPR. Dans ce cas, passez à l’étape suivante. Sinon, vous pouvez passer à l’étape 5.
La boîte de dialogue suivante sur les cookies GDPR peut ou non apparaître en fonction de l’emplacement de votre adresse IP.
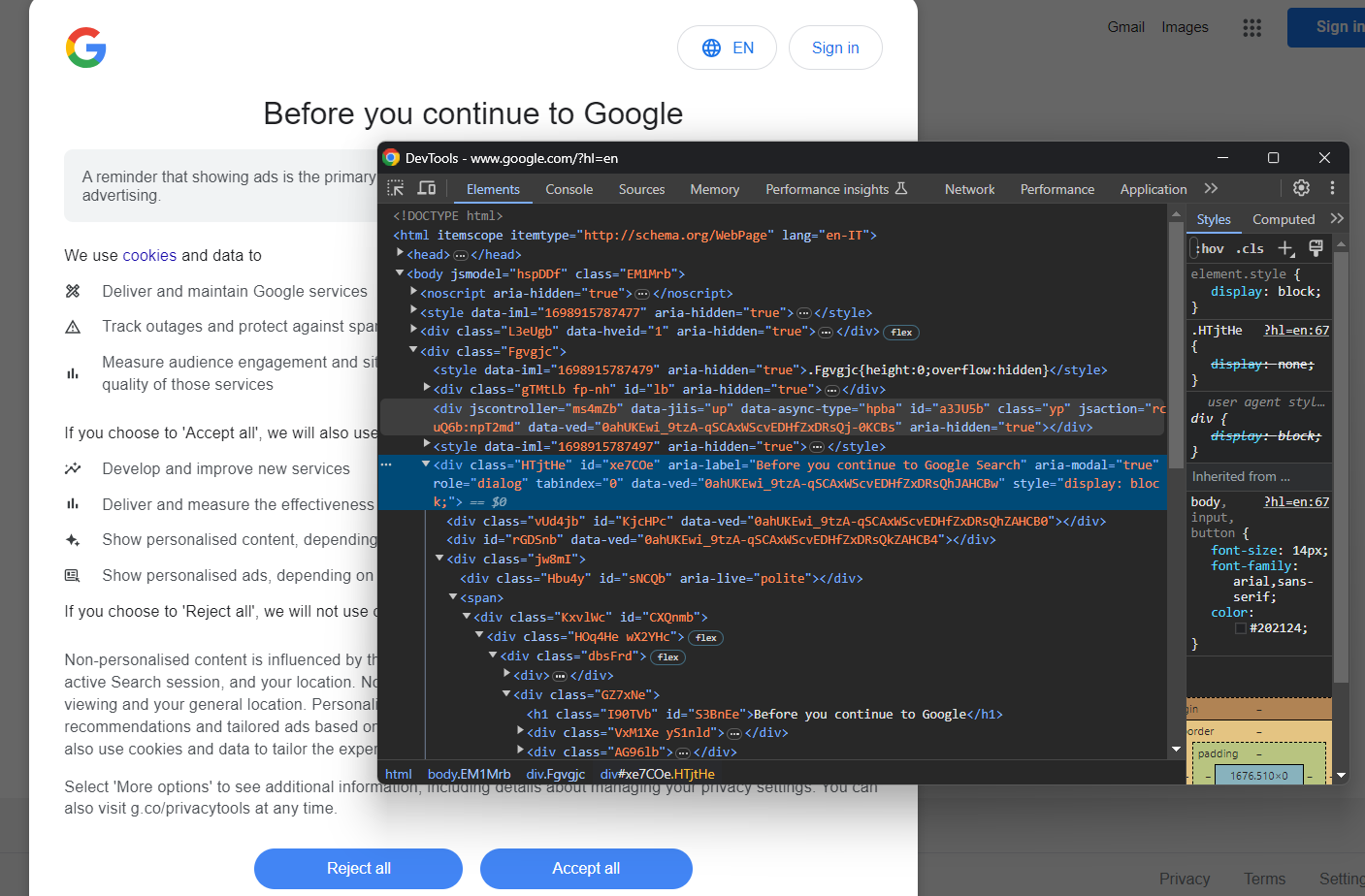
En l’inspectant, vous remarquerez que vous pouvez localiser l’élément HTML de dialogue avec :
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")find_element() est une méthode Selenium qui vous permet de sélectionner des éléments HTML sur la page à l’aide de différentes stratégies. Dans le cas présent, c’est la stratégie CSS Selector qui a été utilisée.
N’oubliez pas d’importer By comme suit :
from selenium.webdriver.common.by import ByComme vous pouvez le constater en inspectant le bouton “Accept all”, il n’y a pas de moyen facile de le sélectionner :
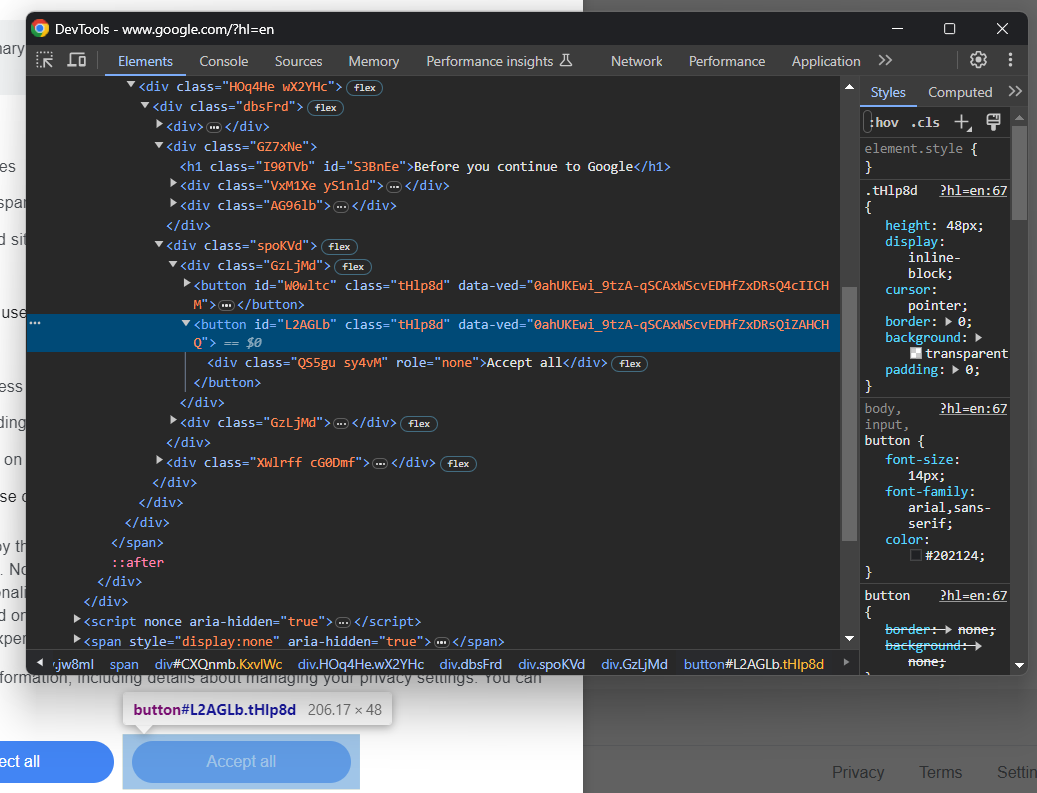
Sa classe CSS semble être générée aléatoirement, vous devez donc cibler son contenu via une expression XPath :
accept_button = cookie_dialog.find_element(By.XPATH, ".//button[contains(., 'Accept')]")Cette instruction localisera le premier bouton de la boîte de dialogue dont le texte contient la chaîne “Accept”.
Mettez tout cela ensemble, et vous pouvez traiter la boîte de dialogue optionnelle des cookies de Google comme suit :
essayez :
# sélectionnez la boîte de dialogue et acceptez la politique en matière de cookies
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, ".//button[contains(., 'Accept')]")
si accept_button n'est pas None :
accept_button.click()
except NoSuchElementException :
print("Dialogue sur les cookies non présent")L’instruction click() clique sur le bouton “Accepter tout” et ferme la boîte de dialogue relative à la politique en matière de cookies. Si la boîte de dialogue n’est pas présente, une exception NoSuchElementException sera levée à la place, et le script l’attrapera et continuera.
Importez l’exception :
from selenium.common import NoSuchElementExceptionVoilà, c’est fait ! Vous êtes prêt à commencer à récupérer des données SERP !
Étape 5 : Remplir le formulaire de recherche
Concentrez-vous maintenant sur le formulaire de recherche :
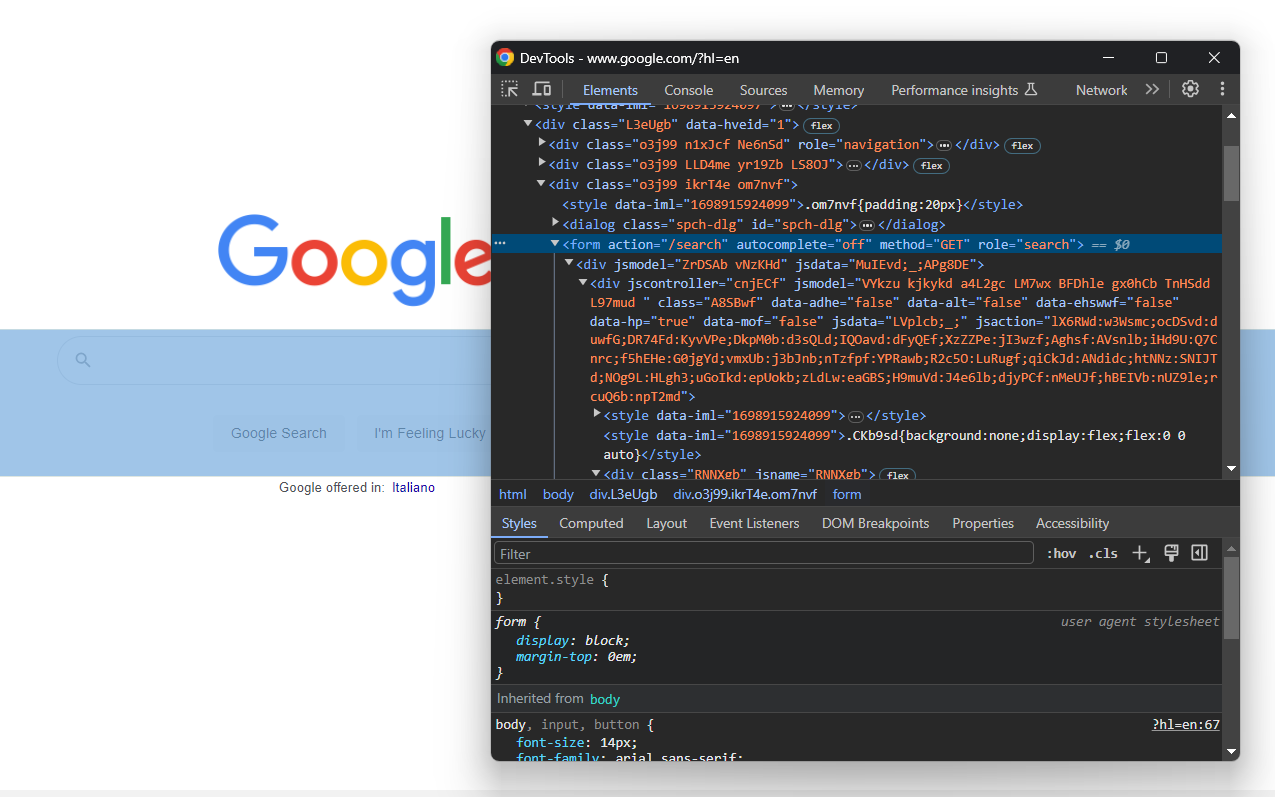
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")En creusant dans le code HTML, vous trouverez la zone de texte de recherche :
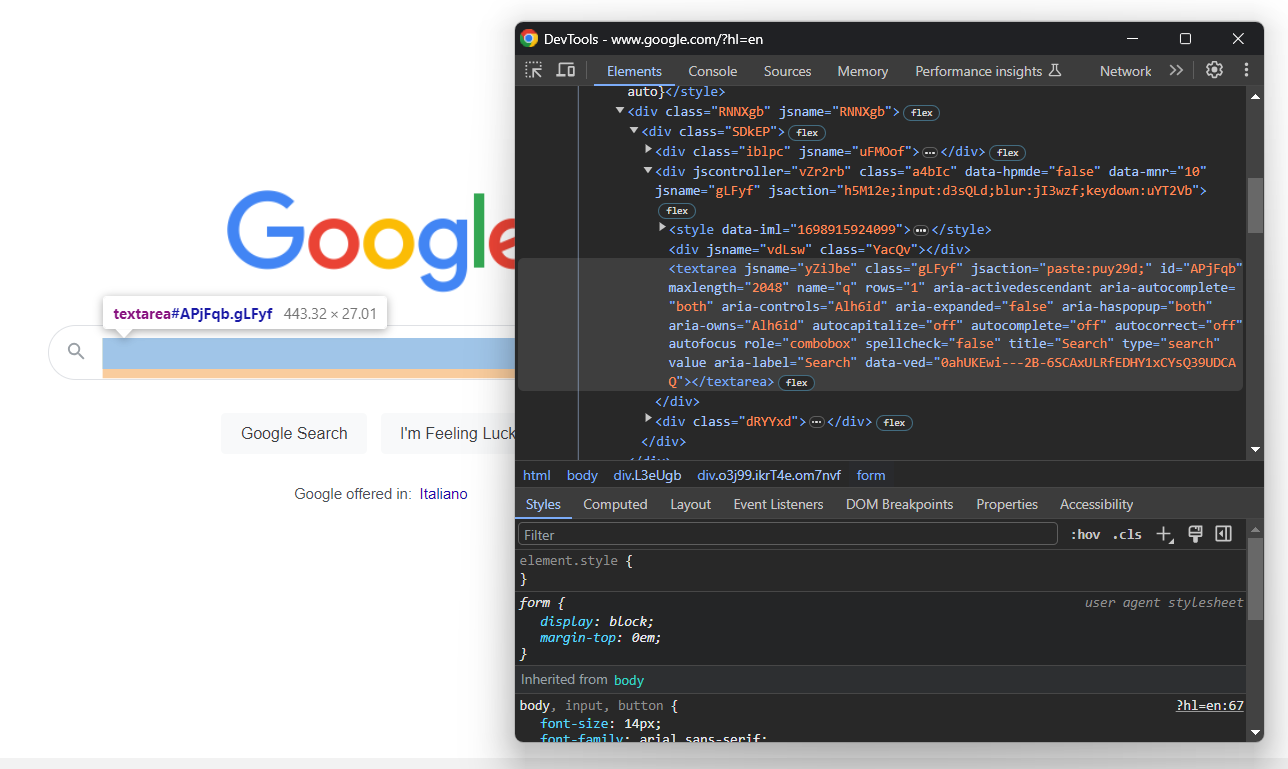
Là encore, la classe CSS est générée de manière aléatoire. Localisez-la donc grâce à ses attributs, utilisez le bouton send_keys() pour taper le mot-clé SERP cible :
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
kw = "meilleure bibliothèque python"
search_textarea.send_keys(kw)Dans cet exemple, le mot clé est “meilleure bibliothèque python”, mais vous pouvez effectuer une recherche à partir de n’importe quelle requête.
Soumettez le formulaire pour déclencher un changement de page :
search_form.submit()C’est parti ! La page Google du navigateur contrôlé sera désormais redirigée vers la page de résultats du moteur de recherche, comme vous le souhaitez.
Étape 6 : Sélectionnez les éléments de la SERP
Inspectez la SERP de Google :
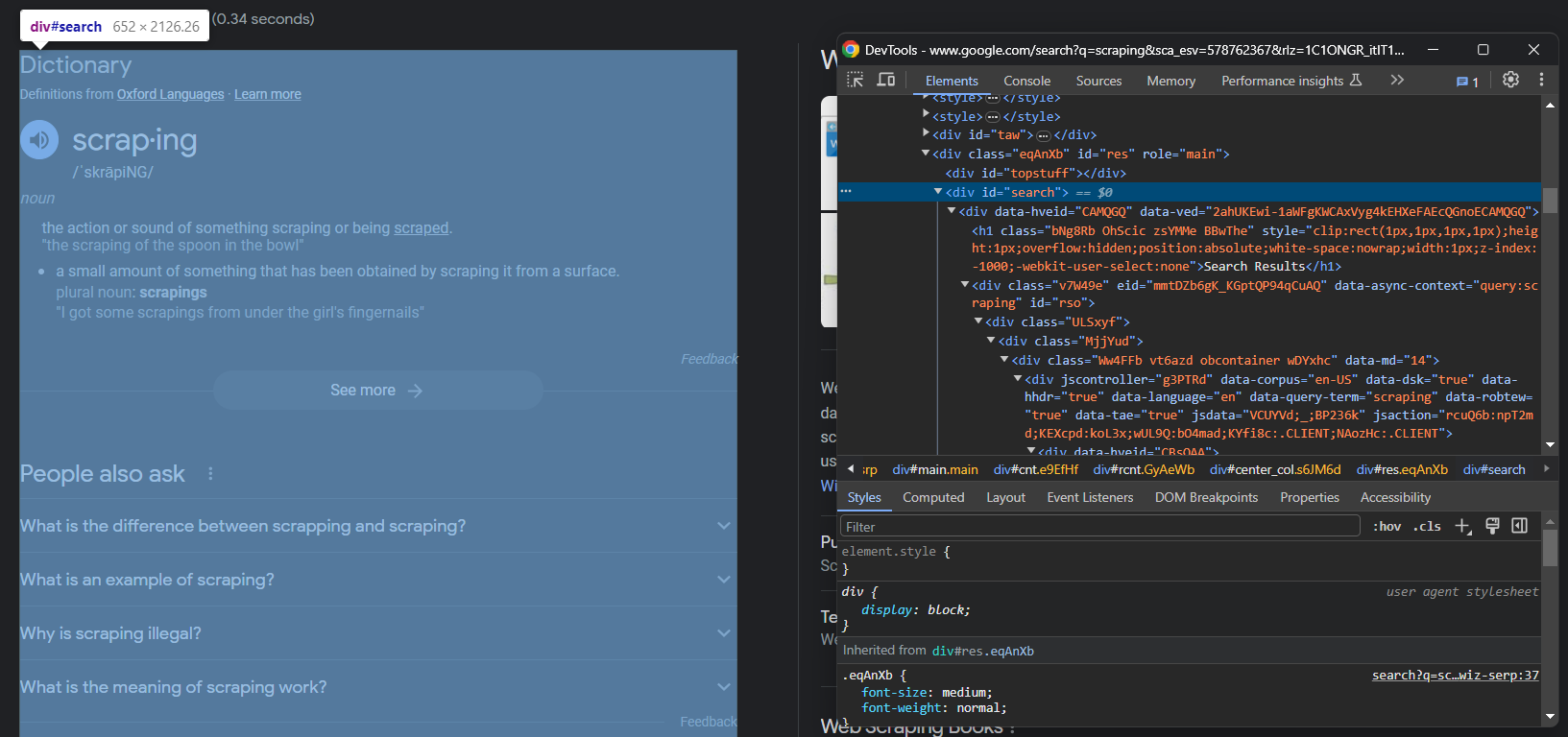
Notez que le conteneur principal est un
search_div = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search'))) WebDriverWait() est une classe spéciale proposée par Selenium pour attendre qu’un événement spécifique se produise sur la page. Dans ce cas, le script attendra jusqu’à 5 secondes que l’élément HTML #search soit présent. C’est une bonne façon de laisser la page se charger.
Ajoutez les importations nécessaires :
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECMaintenant que vous êtes sur la page désirée, inspectez les éléments de la SERP :
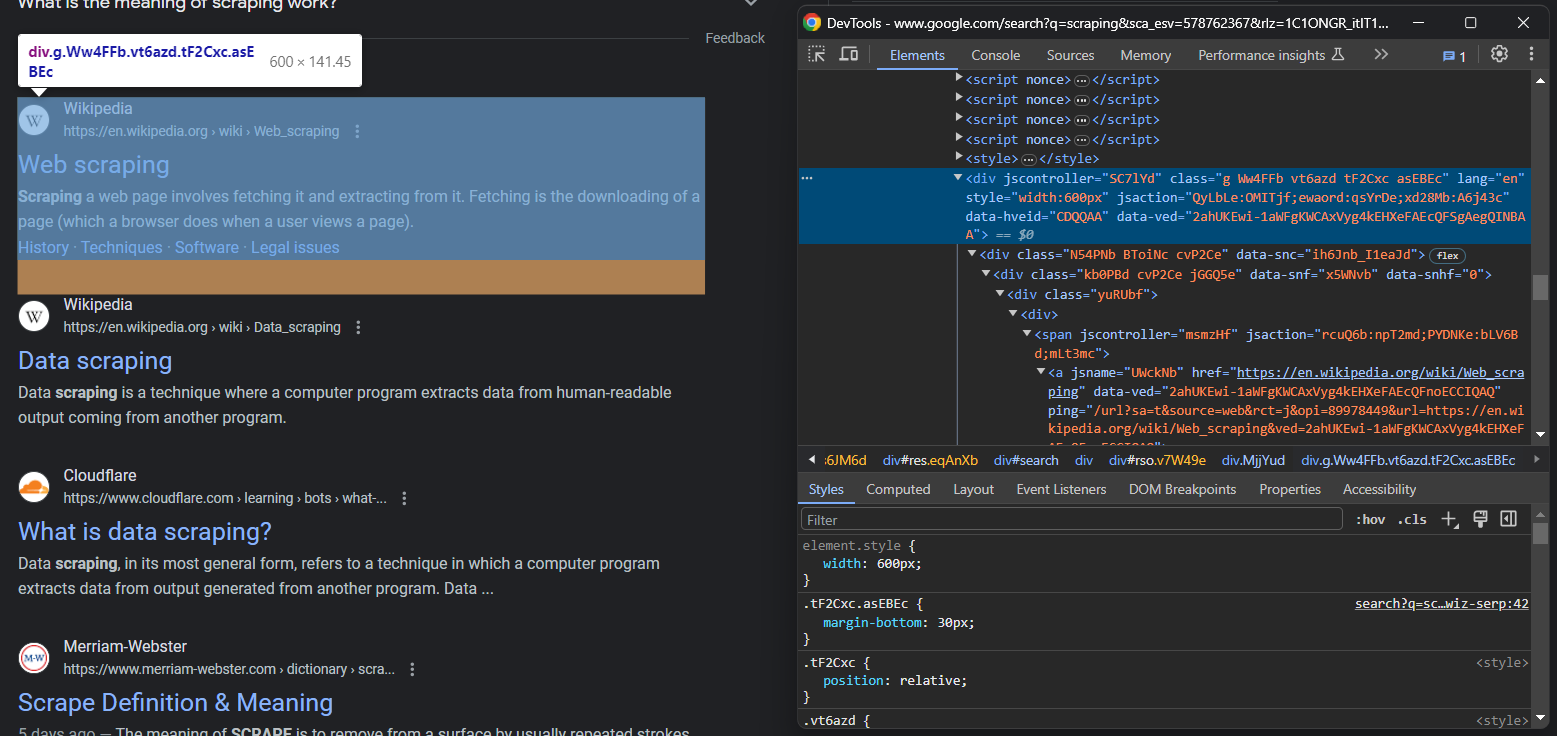
Il n’est pas facile de les sélectionner tous, mais vous pouvez y parvenir grâce à leurs attributs HTML inhabituels :
serp_divs = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][jsaction][data-hveid][data-ved]")Cette instruction identifie toutes les
Vous êtes à deux doigts de faire du “scraping” Vous n’êtes plus qu’à une étape de l’extraction des données SERP en Python.
Étape 7 : Récupérer les données des SERP
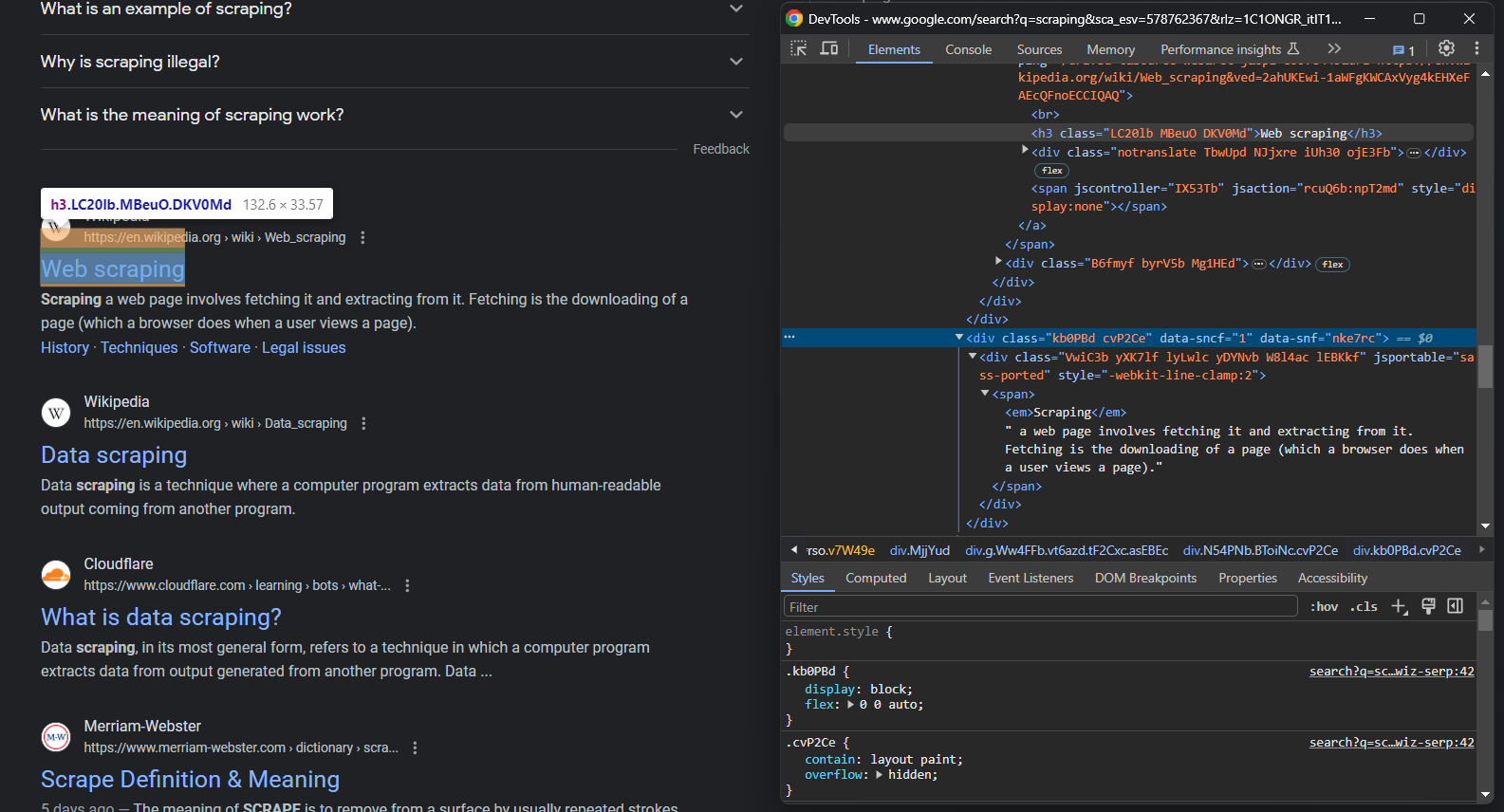
Si vous regardez attentivement l’image précédente et celle-ci, vous remarquerez qu’un élément SERP a :
- Un titre dans un élément
- Une URL dans un élément
<a></a>qui est le parent de. - Une description dans l’élément
[data-sncf='1'].
Étant donné qu’une seule page de recherche comporte plusieurs résultats, initialisez un tableau pour les récupérer :
serp_elements = []Vous aurez également besoin d’une variable “rank” pour garder une trace de leur position dans le classement :
rank = 1Rassemblez-les tous à l’aide de la logique d’extraction de données suivante :
for serp_div in serp_divs :
# pour ignorer les éléments SERP non utiles
essayez :
serp_title_h3 = serp_div.find_element(By.CSS_SELECTOR, "h3")
serp_title_a = serp_title_h3.find_element(By.XPATH, './..')
serp_description_div = serp_div.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
except NoSuchElementException :
continuez
# logique d'extraction des données
url = serp_title_a.get_attribute("href")
title = serp_title_h3.get_attribute("innerText")
description = serp_description_div.get_attribute("innerText")
# remplir un nouvel élément de données SERP et
# l'ajouter à la liste
serp_element = {
'rank' : rank,
'url' : url,
'title' : titre,
'description' : description
}
serp_elements.append(serp_element)
rang = 1Google a tendance à remplir la page de résultats de recherche avec de nombreux éléments de type SERP, et vous devez les filtrer à l’aide de l’instruction try ... catch. Notez que Selenium ne fournit pas de moyen facile d’accéder au parent d’un élément, c’est pourquoi l’expression XPath suivante a été utilisée :
serp_title_a = serp_title_h3.find_element(By.XPATH, './...')Cette expression renvoie l’élément HTML parent du nœud
À la fin de la boucle for, serp_elements stocke toutes les données SERP intéressantes. Vous pouvez le vérifier à l’aide d’une instruction print :
print(serp_elements)Vous obtiendrez ainsi
[
{'rank' : 1, 'url' : 'https://hackr.io/blog/best-python-libraries', 'title' : '24 Best Python Libraries You Should Check in 2023 - Hackr.io', 'description' : 'Oct 10, 2023 - Top 24 Python Libraries : TensorFlow. Scikit-Learn, Numpy, Keras, PyTorch, LightGBM, Requests, SciPy, and more.'},
# omis par souci de concision...
{'rank' : 8, 'url' : 'https://learnpython.com/blog/popular-python-libraries/', 'title' : 'The Most Popular Python Libraries | LearnPython.com', 'description' : "Sep 13, 2022 - 1. pandas. Le package pandas est une bibliothèque d'analyse et de manipulation de données. Compte tenu de la domination de Python dans l'écosystème de la science des données, pandas\xa0..."}
]Fantastique !
Étape 8 : Exporter les données scannées au format CSV
Vous avez maintenant les données SERP scrappées dans un tableau Python, ce qui n’est pas le meilleur format pour les partager avec d’autres membres de l’équipe. Préparez-vous à les exporter vers un fichier CSV.
Tout d’abord, importez le paquetage csv de la bibliothèque standard de Python :
import csvEnsuite, utilisez-le pour remplir un fichier CSV de sortie avec vos données SERP :
csv_file = "serp_results.csv"
header = ['rang', 'url', 'titre', 'description']
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile :
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)Enfin ! Votre script de scraping SERP est prêt.
Etape 9 : Assembler le tout
Voici le code final de scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# pour contrôler une fenêtre Chrome en mode headless
options = Options()
options.add_argument('--headless=new') # commentez-le pour les tests
# initialiser une instance de pilote web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options
)
# se connecter à la page cible
driver.get("https://google.com/")
# traiter la boîte de dialogue du cookie GDPR, si elle est présente
essayez :
# sélectionnez la boîte de dialogue et acceptez la politique en matière de cookies
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, ".//button[contains(., 'Accept')]")
si accept_button n'est pas None :
accept_button.click()
except NoSuchElementException :
print("Le dialogue sur les cookies n'est pas présent")
# soumettez le formulaire de recherche avec le mot-clé
# pour récupérer les données SERP
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
kw = "meilleure bibliothèque python"
search_textarea.send_keys(kw)
search_form.submit()
# attendez le chargement de la nouvelle page
search_div = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# sélectionnez les éléments de la SERP
serp_divs = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][jsaction][data-hveid][data-ved]")
# pour stocker les données SERP à récupérer
serp_elements = []
# pour garder une trace de la position dans le classement
rang = 1
# itère sur chaque élément SERP
# et récupère les données
pour serp_div dans serp_divs :
# ignorer les éléments SERP non utiles
essayez :
serp_title_h3 = serp_div.find_element(By.CSS_SELECTOR, "h3")
serp_title_a = serp_title_h3.find_element(By.XPATH, './..')
serp_description_div = serp_div.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
except NoSuchElementException :
continuez
# logique d'extraction des données
url = serp_title_a.get_attribute("href")
title = serp_title_h3.get_attribute("innerText")
description = serp_description_div.get_attribute("innerText")
# remplir un nouvel élément de données SERP et
# l'ajouter à la liste
serp_element = {
'rank' : rank,
'url' : url,
'title' : titre,
'description' : description
}
serp_elements.append(serp_element)
rang = 1
# Fermez le navigateur et libérez les ressources
driver.quit()
# exporter les données du scrape au format CSV
csv_file = "serp_results.csv"
header = ['rank', 'url', 'title', 'description']
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile :
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)En moins de 100 lignes de code, vous pouvez construire un simple scraper Google SERP Python !
Vérifiez qu’il fonctionne Ouvrez le terminal dans le dossier du projet et lancez la commande ci-dessous pour l’exécuter :
python scraper.pyAttendez que le scraper se termine, et un fichier serp_results.csv apparaîtra dans le répertoire racine du projet. Ouvrez-le et vous verrez :

Félicitations ! Vous venez de faire du SERP scraping 😀
Les défis du SERP Scraping et comment les résoudre
L’extraction des données SERP s’accompagne de plusieurs défis qu’il convient de prendre en compte :
- Technologies anti-bots de Google: Google sait à quel point ses données sont précieuses. Aussi, il souhaite protéger l’expérience utilisateur contre les bots. C’est pourquoi, après quelques requêtes automatisées provenant de la même adresse IP, il affichera un CAPTCHA ou vous bloquera. Il ne s’agit là que de l’une des nombreuses mesures anti-bots adoptées par Google pour empêcher les logiciels automatisés tels que votre scraper d’accéder à ses pages. Il n’est pas facile de contourner ces solutions, ce qui peut facilement compromettre l’ensemble du processus de scraping.
- Complexité de l’architecture: Google modifie fréquemment son algorithme et des millions de pages sont ajoutées/mises à jour chaque jour. Par conséquent, les SERPs changent très souvent, ce qui signifie que vous pourriez avoir besoin d’exécuter votre scraper sur une base régulière. Cela implique la mise en place d’un planificateur et d’un système de battement de cœur pour vérifier que tout fonctionne comme prévu. Vous devrez peut-être aussi conserver les données historiques dans une base de données et surveiller l’ensemble du processus par le biais d’un APM(Application performance monitoring). Cela introduit une complexité considérable dans votre architecture.
- Il est difficile et coûteux d’atteindre l’efficacité: il est facile d’extraire une seule page SERP, mais si vous voulez étendre le processus à plusieurs pages, vous devez exécuter plusieurs scripts en parallèle pour obtenir d’excellentes performances. Contrôler de nombreuses instances de Chrome n’est pas simple. De plus, cela nécessite beaucoup de ressources et implique des coûts d’infrastructure élevés.
Cela signifie-t-il que le SERP scraping en production est impossible ? Pas du tout ! Tout ce dont vous avez besoin, c’est d’une solution avancée qui résout tous ces problèmes pour vous, comme l’API SERP de Bright Data.
Si vous ne connaissez pas cette technologie, l’API SERP n’est rien d’autre qu’un ensemble de points de terminaison dotés de capacités anti-bots et fournissant des données SERP en temps réel à partir des principaux moteurs de recherche. Effectuez un simple appel API et obtenez vos données SERP au format JSON ou HTML !
Conclusion
Dans ce tutoriel, nous avons vu ce qu’est la SERP, pourquoi elle est si importante et comment en extraire des données utiles. En détail, vous avez appris les étapes nécessaires pour construire un SERP scraper en Python. Vous avez également découvert les défis et les limites liés à l’extraction de SERP et comment l’API SERP de Bright Data les surmonte !