Un guide détaillé sur le web scraping en utilisant ChatGPT Code Interpreter et ses plugins.
Si vous n’avez pas l’intention de créer une nouveauté, il est probable que vous ayez besoin d’informations préalables pour commencer. Ou alors, vous voudrez peut-être vous tourner vers la concurrence pour obtenir des informations précieuses. En outre, il peut y avoir d’innombrables raisons pour lesquelles quelqu’un s’intéresse au contenu d’un site web spécifique.
Le web scraping est le processus qui permet de répondre à ces cas d’utilisation.
Et il y a plusieurs façons de procéder. Il existe des outils lourds auxquels vous pouvez souscrire pour le scraping professionnel de grands sites web. Vous pouvez aussi avoir besoin d’une configuration spécifique pour un traitement sur site.
Dans tous les cas, l’approche est coûteuse, longue et fastidieuse pour les débutants, en particulier pour le scraping de quelques pages web.
Vue d’ensemble de ChatGPT pour le Web Scraping
Je ne suis pas censé vous présenter ChatGPT. Je ne suis pas censé vous présenter ChatGPT, n’est-ce pas ?
En bref, ChatGPT est une IA générative qui réagit comme les humains. Vous disposez d’une interface de chat pour lui demander d’effectuer diverses tâches, telles que s’informer sur des événements historiques, rédiger des essais, résumer, traduire, coder, etc.
ChatGPT répond en texte. Cependant, il existe des plugins ChatGPT qui améliorent ses capacités de nombreuses façons. Nous utiliserons l’un de ces plugins. De plus, nous utiliserons son interprète de code pour le scraping de sites web ayant des structures de pages web compliquées ou avec des protocoles anti-scraping actifs.
Sachez que ChatGPT a des versions gratuites et payantes. Mais vous aurez besoin de l’abonnement payant (actuellement, 20 $ par mois) pour utiliser le plugin web scraper ou son moteur Code Interpreter.
Dans les sections suivantes, j’illustrerai le processus étape par étape.
Clause de non-responsabilité: avant de procéder vous-même, vérifiez que le site web concerné autorise le scraping de son contenu. Si ce n’est pas le cas, vous pouvez contacter leur administrateur et voir s’ils l’autorisent pour vous afin d’éviter tout problème juridique.
Scraping Web à l’aide du plugin ChatGPT
Connectez-vous à votre compte OpenAI, survolez GPT-4 (sa version payante actuelle) et cliquez sur Plugins.
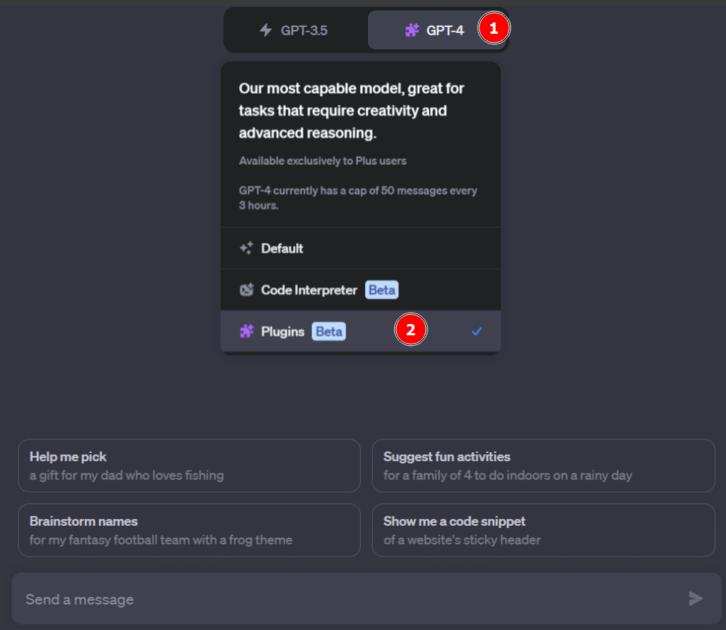
Ensuite, cliquez sur Aucun plugin activé, défilez vers le bas et cliquez sur Magasin de plugins.
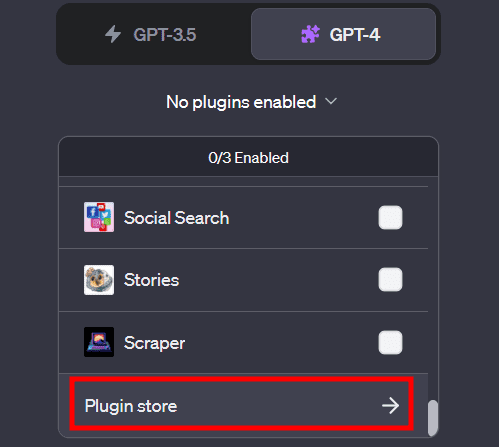
Veuillez noter qu’au lieu de No plugins enabled, vous aurez une icône de plugin si un plugin est actif. Dans ce cas, vous devez cliquer sur cette icône pour ouvrir le menu déroulant et cliquer sur Plugin store en bas.
Cela ouvrira le magasin de plugins. Recherchez Scraper et cliquez sur Installer.
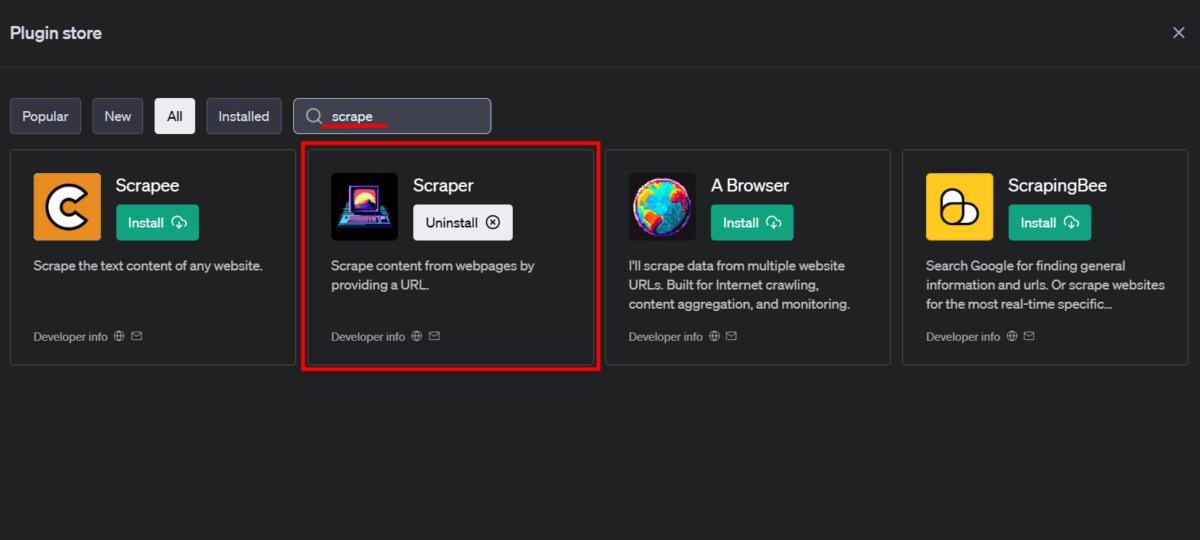
Sélectionnez ce plugin dans l’interface de ChatGPT.
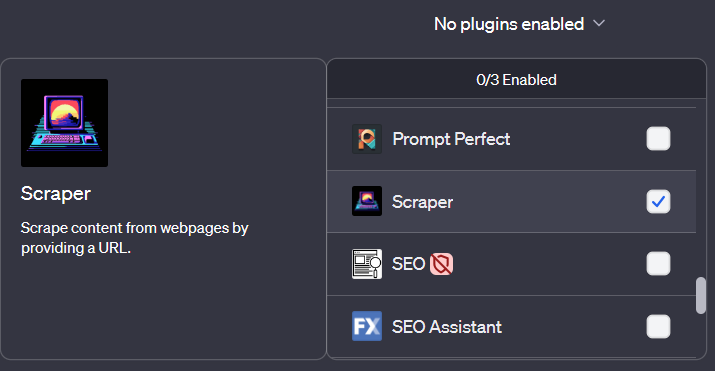
Une fois le plugin sélectionné, vous devez demander à ChatGPT de mentionner l’URL du sujet et le contenu à scraper.
C’est ce que j’ai fait pour quelques sites web. Jetez un coup d’œil à ce qui suit.
Scraping d’une publication
Nous sommes une publication axée sur la technologie, et j’ai choisi notre page d’accueil, geekflare.com/fr/, pour cette illustration.
Voici l’exercice :
vérifiez cette page web : https://geekflare.com/fr/ et préparez un tableau indiquant le titre de l'article, l'auteur, la date de publication et l'extrait pour les 10 premiers articles.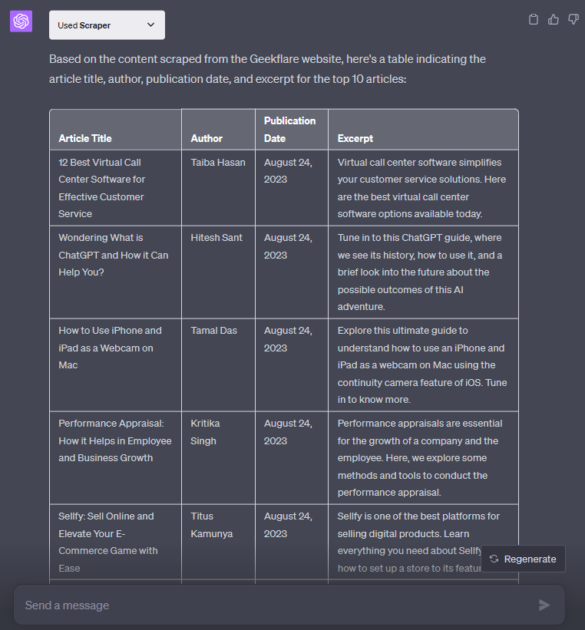
Vous pouvez également demander à nouveau de convertir les données au format CSV, de les coller dans un fichier texte portant l’extension .csv et de l’ouvrir dans un tableur tel que MS Excel.
Récupération d’une page Web d’offres ou de coupons
La section des offres de Geekflare est l’endroit où nous avons trié sur le volet des offres sur des projets de haute technologie. Que diriez-vous de récupérer chaque offre sous forme de tableau ?
Préparez une liste d'offres à partir de cette page web : https://geekflare.com/fr/deals/. Présentez le résultat sous forme de tableau.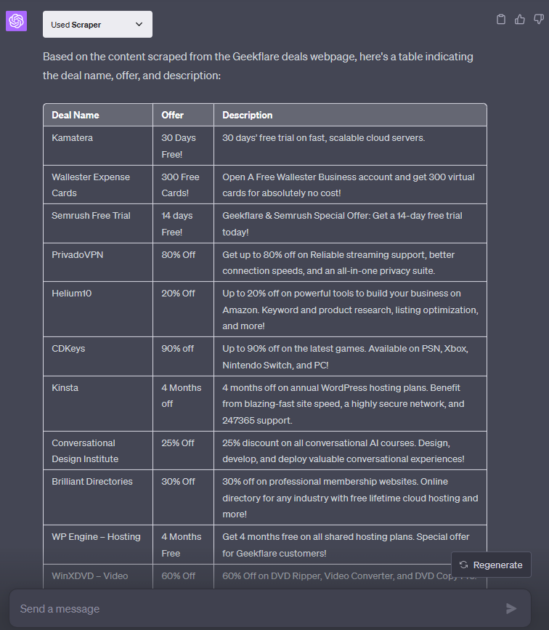
Récupération de Wikipedia
Résumez sous forme de tableau les dernières nouvelles de la section "in the news" de cette page wikipedia : https://en.wikipedia.org/wiki/Main_Page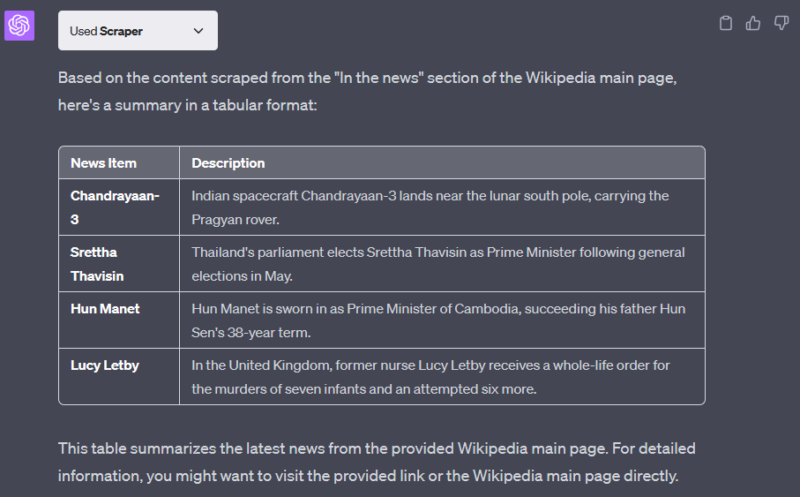
Récupération de sites de commerce électronique
Enfin, j’ai essayé de récupérer les ordinateurs portables sur Amazon.com en appliquant quelques filtres et en envoyant l’URL à ChatGPT. Voici ce que j’ai obtenu :
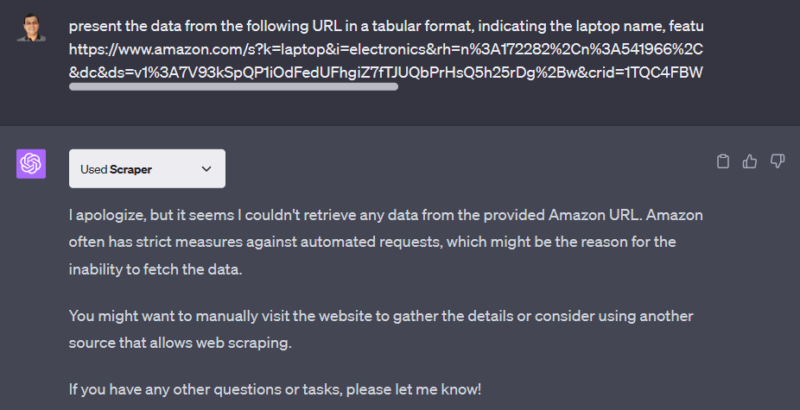
Le problème est qu’il ne s’agit pas d’un cas unique. Vous trouverez de nombreux exemples de ce type lorsque les sites web ont mis en place des mesures anti-scraping. Dans ce cas, vous devrez trouver une alternative pour obtenir les données si vous ne pouvez pas vous abonner à des scrapers standard.
Les sections suivantes décrivent l’une de ces solutions.
Récupération de données sur le Web à l’aide de ChatGPT Code Interpreter
Code Interpreter est un moteur ChatGPT récemment lancé pour répondre aux tâches liées à la programmation. Alors que le moteur par défaut s’appuie fortement sur les réponses textuelles, Code Interpreter peut aider à visualiser les résultats, analyser, déboguer et exécuter du code, s’intégrer à des logiciels binaires et faire bien d’autres choses centrées sur la programmation.
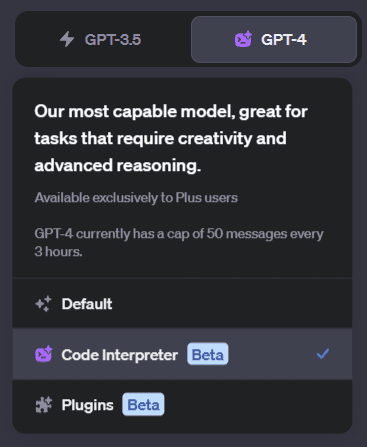
Dans ce processus, nous allons télécharger la source HTML, l’envoyer à ChatGPT Code Interpreter, et procéder au scraping.
J’ai pris cette page pour l’extraire :
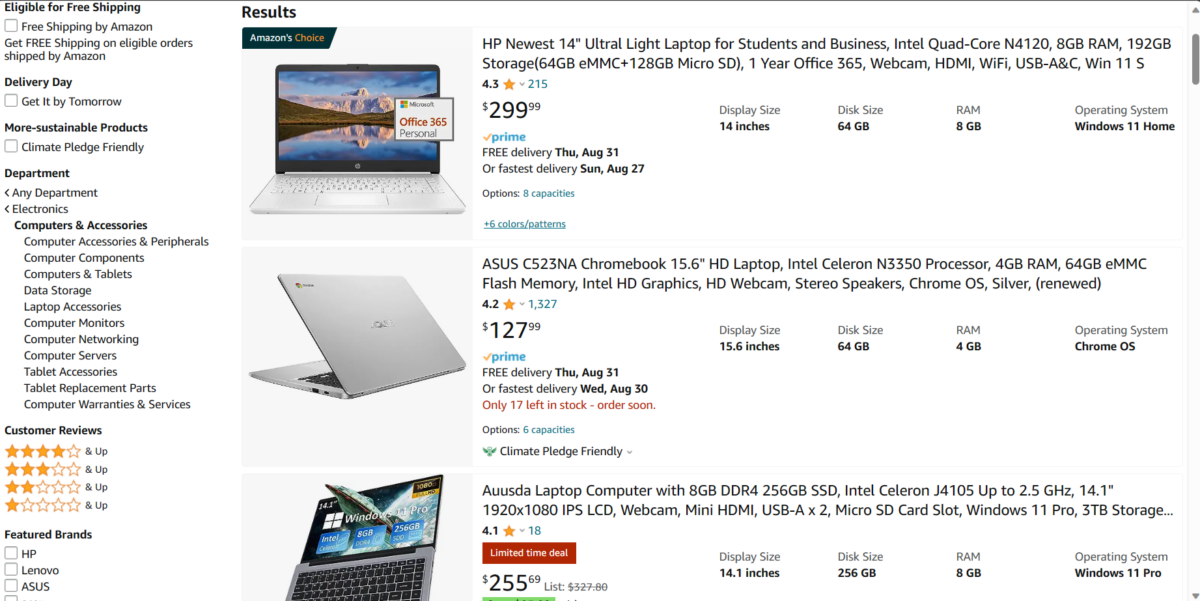
Nous commencerons par enregistrer la page web au format HTML. Pour cela, allez sur la page web et appuyez sur Ctrl S.
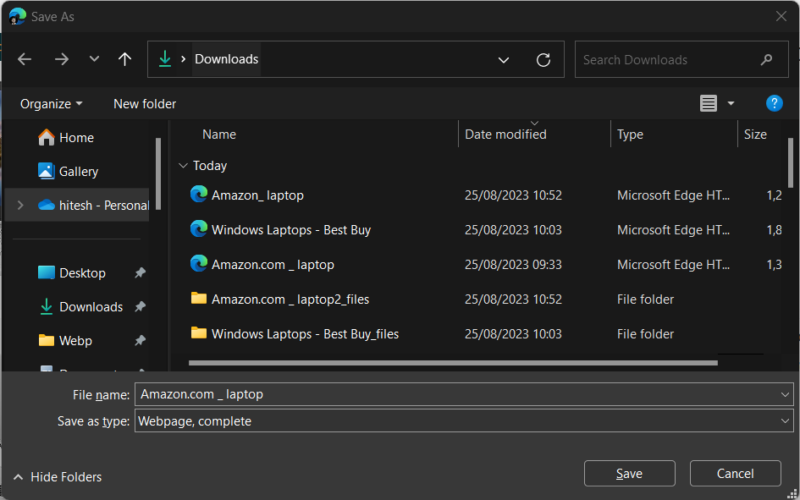
Nous avons maintenant le fichier à extraire. Découvrons l’invite.
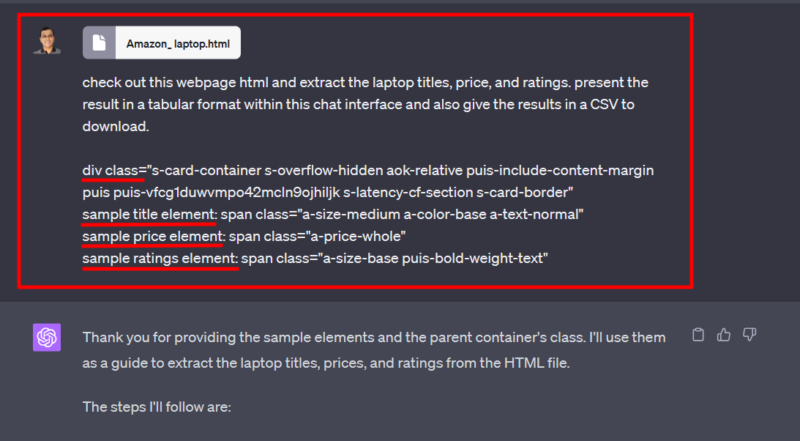
En plus de l’invite textuelle, vous pouvez voir que je lui ai donné des exemples d’éléments pour accélérer le scraping. Les structures des pages web d’Amazon étant complexes, sans ces exemples, la tentative de scraping risque d’échouer ou de ne rien donner.
Il est assez facile d’obtenir ces éléments. Cliquez avec le bouton droit de la souris n’importe où sur la page web concernée et cliquez sur Inspecter dans la fenêtre contextuelle.
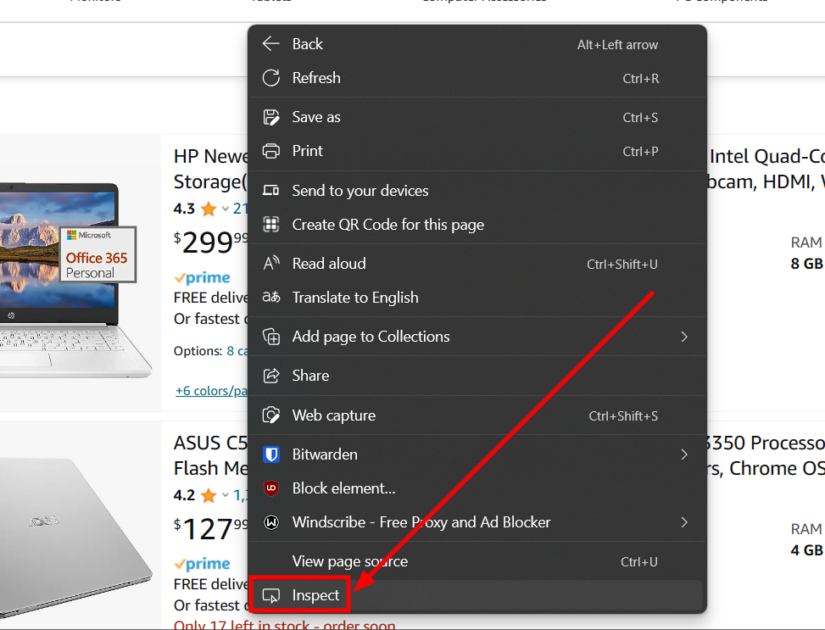
Tout d’abord, cliquez sur l’icône la plus haute (marquée 1). Cela permet de mettre en évidence les détails pendant que vous sélectionnez les éléments de la page. Ensuite, sélectionnez l’élément conteneur d’un produit spécifique.
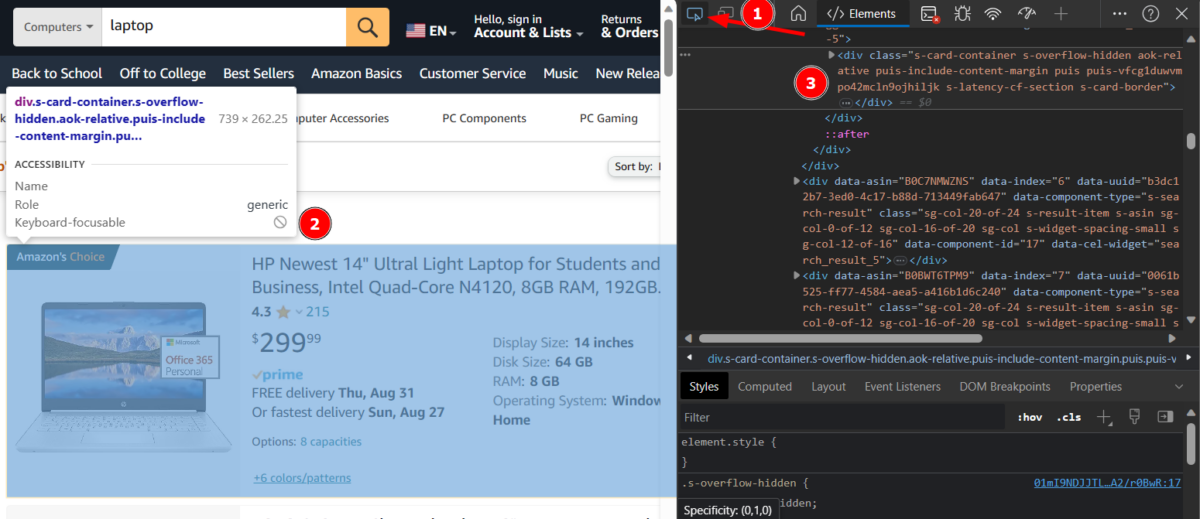
Veillez à sélectionner le conteneur le plus à l’intérieur. Vous pouvez passer la souris dessus et il continuera à s’afficher en surbrillance. Dès que vous obtenez la dernière coquille couvrant ce bloc, vous pouvez cliquer et aller sur le côté droit pour copier la classe div de l’élément.
De même, sélectionnez les échantillons pour les autres éléments.

Enfin, téléchargez le code HTML et lancez une invite similaire à celle-ci :
consultez cette page web html et extrayez les titres, les prix et les évaluations des ordinateurs portables. présentez le résultat sous forme de tableau dans cette interface de discussion et donnez les résultats sous forme de fichier CSV à télécharger.
div class="s-card-container s-overflow-hidden aok-relative puis-include-content-margin puis puis-vfcg1duwvmpo42mcln9ojhiljk s-latency-cf-section s-card-border"
exemple d'élément de titre : span class="a-size-medium a-color-base a-text-normal"
exemple d'élément de prix : span class="a-price-whole"
exemple d'élément d'évaluation : span class="a-size-base puis-bold-weight-text"Cela prendra un certain temps, le temps que ChatGPT Code Interpreter fasse son travail. Vous aurez quelques détails, alors que tout sera dans le fichier CSV intégré.
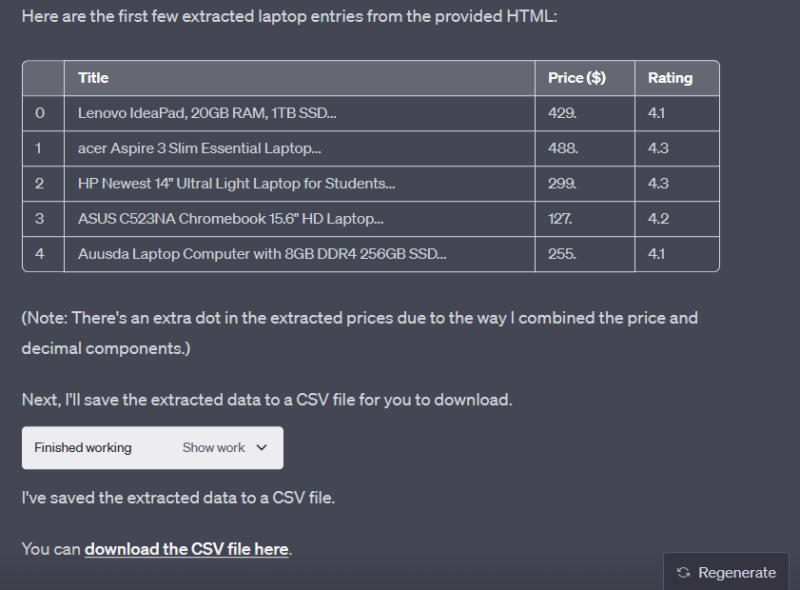
Vous pouvez observer que le tableau a quelques entrées qui ne sont pas présentes sur la page web originale, surtout au début. Dans ce cas, vous devez revérifier et nettoyer les données pour éviter les redondances.
S’il y en a, vous pouvez relancer ChatGPT pour obtenir un fichier CSV propre.
Réflexions finales
ChatGPT fait beaucoup de choses, et le web scraping de base est l’une d’entre elles. D’accord, il n’est peut-être pas adapté à quelqu’un qui scrappe des centaines de pages. Cependant, il vous permettra de démarrer dans la bonne direction et sera idéal pour une courte session de scraping.
Dans ce guide, nous avons utilisé l’un de ses plugins de scraping et Code Interpreter. Alors que les plugins fonctionnent sur de nombreux sites web standard, la seconde méthode est destinée aux structures de pages web personnalisées ou si la page comporte des éléments dynamiques (défilement sans fin, lire plus, etc.).
Et pour le répéter, lisez les termes du site web concerné avant de procéder au scraping.
PS : Découvrez ces solutions de scraping dans le nuage et notre propre API de scraping Geekflare.