
Découvrons en détail l’architecture de Kubernetes.
Je suppose que vous avez une connaissance de base de Kubernetes. Si ce n’est pas le cas, consultez les articles d’introduction et d’installation suivants.
https://geekflare.com/fr/kubernetes-introduction/
https://geekflare.com/fr/install-kubernetes-on-ubuntu/
Kubernetes suit une architecture maître-esclave. L’architecture Kubernetes comprend un nœud maître et des nœuds de travail. Le nœud maître se compose de quatre éléments.
- Serveur API Kube
- contrôleur
- planificateur
- etcd
Le nœud de travail est composé de trois éléments.
- kubelet
- kube-proxy
- le conteneur d’exécution
Voici à quoi ressemble une architecture Kubernetes :
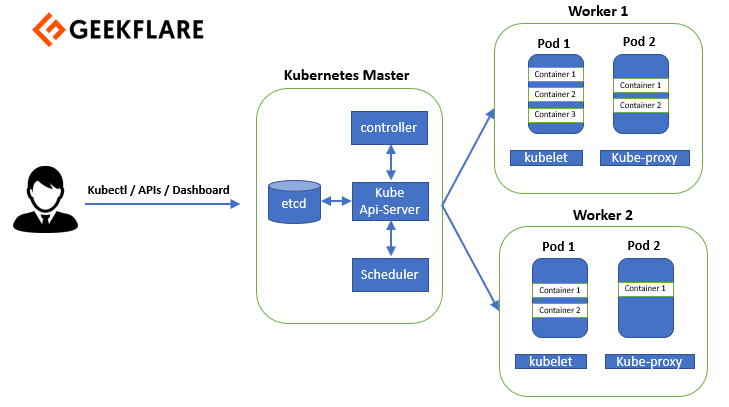
Permettez-moi de vous présenter en détail les composants du nœud maître et des nœuds de travail.
Nœud maître
Le nœud maître gère le cluster Kubernetes et constitue le point d’entrée pour toutes les tâches administratives. Vous pouvez communiquer avec le nœud maître via la CLI, l’interface graphique ou l’API. Pour assurer la tolérance aux pannes, il peut y avoir plus d’un nœud maître dans le cluster. Lorsque nous avons plus d’un nœud maître, il y a un mode de haute disponibilité et un leader qui effectue toutes les opérations. Tous les autres nœuds maîtres sont les suiveurs de ce nœud maître.
Par ailleurs, pour gérer l’état du cluster, Kubernetes utilise etcd. Tous les nœuds maîtres se connectent à etcd, qui est un magasin de valeurs clés distribué.
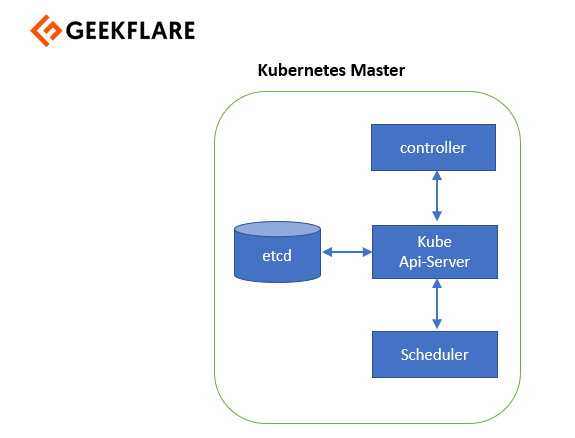
Laissez-moi vous expliquer tous ces composants un par un.
Serveur API
Le serveur API exécute toutes les tâches administratives sur le nœud principal. Un utilisateur envoie les commandes restantes au serveur API, qui valide les demandes, puis les traite et les exécute. etcd enregistre l’état résultant du cluster sous la forme d’un magasin de valeurs clés distribué.
Planificateur
Ensuite, nous avons un planificateur. Comme son nom l’indique, l’ordonnanceur planifie le travail sur différents nœuds de travail. Il dispose des informations relatives à l’utilisation des ressources pour chaque nœud de travail. L’ordonnanceur tient également compte des exigences de qualité de service, de la localité des données et de nombreux autres paramètres de ce type. Il planifie ensuite le travail en termes de pods et de services.
Gestionnaire de contrôleur
Les boucles de contrôle non terminées qui régulent l’état du cluster Kubernetes sont gérées par le gestionnaire de contrôle. Chacune de ces boucles de contrôle connaît l’état souhaité de l’objet qu’elle gère, puis examine son état actuel par l’intermédiaire des serveurs API.
Dans une boucle de contrôle, si l’état souhaité ne correspond pas à l’état actuel de l’objet, des mesures correctives sont prises par la boucle de contrôle pour que l’état actuel corresponde à l’état souhaité. Ainsi, le gestionnaire de contrôleur s’assure que votre état actuel est le même que l’état souhaité.
etcd
Etcd est un magasin de valeurs clés distribué qui est utilisé pour stocker l’état de la grappe. Il doit donc faire partie du maître Kubernetes ou vous pouvez le configurer en externe. etcd est écrit en goLang et est basé sur l’algorithme de consensus Raft.
Le radeau permet à l’ensemble des machines de fonctionner comme un groupe cohérent qui peut survivre aux défaillances de certains de ses membres. Même si certains membres ne fonctionnent pas, cet algorithme peut encore fonctionner à tout moment. L’un des nœuds du groupe sera le maître et les autres seront les suiveurs.
Il ne peut y avoir qu’un seul maître, et tous les autres maîtres doivent le suivre. Outre le stockage de l’état de la grappe, etcd est également utilisé pour stocker les détails de la configuration tels que les sous-réseaux et les cartes de configuration.
Nœud de travail
Un nœud de travailleur est un serveur virtuel ou physique qui exécute les applications et est contrôlé par le nœud maître. Les pods sont programmés sur les nœuds de travail, qui disposent des outils nécessaires pour les exécuter et les connecter. Les pods ne sont rien d’autre qu’une collection de conteneurs.
Et pour accéder aux applications depuis le monde extérieur, vous devez vous connecter aux worker nodes et non aux master nodes.
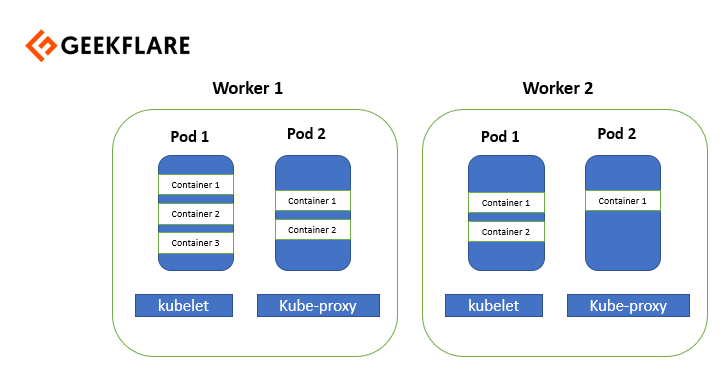
Explorons les composants des nœuds de travail.
Exécution du conteneur
L’exécution du conteneur est essentiellement utilisée pour exécuter et gérer un cycle de vie continu sur le nœud de travail. Quelques exemples d’exécution de conteneurs que je peux vous donner sont les conteneurs rkt, lxc, etc. Il est souvent observé que docker est également appelé “container runtime”, mais pour être précis, laissez-moi vous dire que docker est une plateforme qui utilise des conteneurs comme runtime de conteneur.
Kubelet
Kubelet est essentiellement un agent qui s’exécute sur chaque nœud de travail et communique avec le nœud principal. Ainsi, si vous avez dix nœuds de travail, kubelet s’exécute sur chaque nœud de travail. Il reçoit la définition du pod par différents moyens et exécute les conteneurs associés à ce port. Il s’assure également que les conteneurs qui font partie des pods sont toujours en bonne santé.
Le kubelet se connecte à l’exécution du conteneur à l’aide du cadre gRPC. Le kubelet se connecte à l’interface d’exécution des conteneurs (CRI) pour effectuer des opérations sur les conteneurs et les images. Le service d’image est responsable de toutes les opérations liées à l’image, tandis que le service d’exécution est responsable de toutes les opérations liées aux pods et aux conteneurs. Ces deux services ont deux opérations différentes à effectuer.
Laissez-moi vous dire quelque chose d’intéressant, les runtimes de conteneurs étaient auparavant codés en dur dans Kubernetes, mais avec le développement de CRI, Kubernetes peut maintenant utiliser différents runtimes de conteneurs sans avoir besoin de recompiler. Ainsi, tout moteur d’exécution de conteneur qui implémente CRI peut être utilisé par Kubernetes pour gérer les pods, les conteneurs et les images de conteneurs. Docker shim et les conteneurs CRI sont deux exemples de CRI shim. Avec docker shim, les conteneurs sont créés à l’aide de docker installé sur les nœuds de travail, puis docker utilise en interne un conteneur pour créer et gérer les conteneurs
Kube-proxy
Kube-proxy s’exécute sur chaque nœud de travailleur en tant que proxy réseau. Il écoute le serveur API pour chaque création ou suppression de point de service. Pour chaque point de service, le kube-proxy définit les routes afin de pouvoir y accéder.
Conclusion
J’espère que cela vous aidera à mieux comprendre l’architecture de Kubernetes. Les compétences Kubernetes sont toujours en demande, et si vous cherchez à apprendre pour construire une carrière, alors consultez ce cours Udemy.