Un modèle de données physique est un cadre ou un schéma qui décrit la manière dont les données sont conservées dans une base de données.
Avant d’aborder le modèle physique de données, il convient de comprendre ce qu’est la modélisation des données.
Quelles sont les caractéristiques qui permettent aux utilisateurs d’utiliser efficacement une base de données ? Comment pouvez-vous être certain que la base de données que vous développez répondra à toutes vos exigences ? Considérez le concept de modélisation des données comme la réponse à l’obtention de données et à leur conversion en une base de données utilisable.
Qu’est-ce que la modélisation des données ?
La modélisation des données est le processus qui consiste à générer une représentation simplifiée d’une application logicielle et des composants de données qu’elle inclut, en utilisant du texte et des symboles pour décrire les informations et la manière dont elles circulent.

Il s’agit d’une technique permettant de décrire et de visualiser les différents endroits où un logiciel ou une application conserve des données et la manière dont ces différentes sources d’information s’intègrent les unes aux autres.
La modélisation des données est un aspect important de la gestion des données. Elle facilite l’identification des besoins en informations pour les flux de travail en donnant une représentation visuelle des points de données et de leur modèle de comportement.
Elle permet de déterminer et de comprendre comment les données seront gérées, modifiées, visualisées et distribuées au sein d’une organisation.
Importance de la modélisation des données
Les organisations modernes rassemblent une grande quantité de données provenant de nombreuses sources. Pour prendre des décisions stratégiques efficaces, vous devez examiner les données pour en tirer des enseignements pratiques.
Une collecte, un stockage et un calcul efficaces des données sont nécessaires pour une analyse précise des données. De nombreux outils sont utilisés pour une analyse efficace en fonction du type de données, telles que structurées, semi-structurées, ordinales, etc.

La modélisation des données vous permet de comprendre vos données et de choisir la meilleure solution pour les gérer et les contrôler. Les entreprises créent un modèle de données avant de développer des systèmes de base de données pour leurs opérations, tout comme un architecte crée un plan avant de construire une maison.
Les principaux avantages de la modélisation des données sont les suivants :
- Elle fournit des solutions rapides et efficaces pour le processus de conception et de déploiement des bases de données.
- elle favorise l’uniformité des rapports sur les données et du travail de développement dans l’ensemble de l’entreprise
En outre, la mise en œuvre d’un concept de modélisation des données facilite l’interaction entre les équipes d’analyse et les ingénieurs de base de données.
Types de modélisation des données
Les modélisateurs de données utilisent trois types distincts de modèles de données pour décrire les concepts et les procédures de marketing, les éléments de données pertinents et leurs attributs et relations, ainsi que les cadres pratiques de gestion des données.
Au fur et à mesure que les entreprises créent des programmes fonctionnels et des bases de données, les modèles de données sont souvent développés étape par étape. Voici les différents types de modèles de données et ce qu’ils impliquent :
#1. Modélisation conceptuelle des données
Il s’agit essentiellement d’une vue organisée ou d’une représentation visuelle des concepts de la base de données et de leurs relations. Il sert de point de départ conventionnel à la modélisation des données, en définissant les différentes sources de données et le flux de données au sein de l’organisation.
Il sert de ligne directrice de haut niveau pour la création de modèles logiques et physiques et constitue un élément essentiel de la preuve documentaire de l’architecture des données.
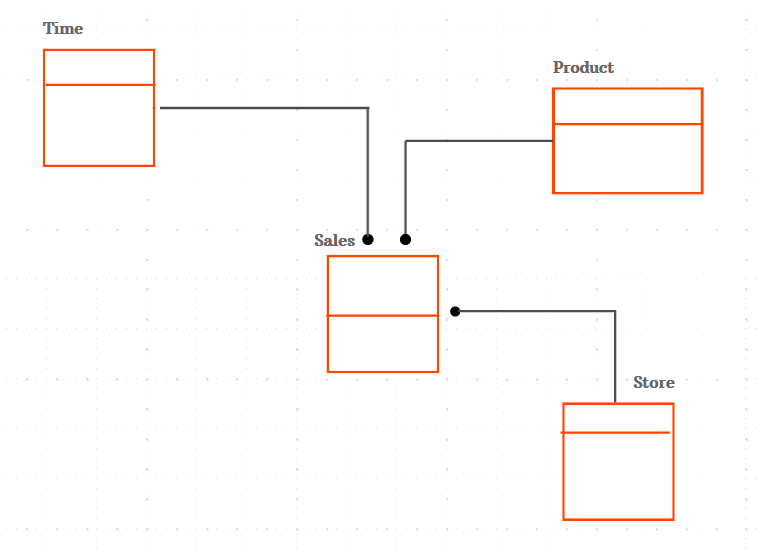
Le modèle conceptuel de données ne décrit que la disposition et le contenu globaux, et non les spécificités de chaque objet. L’ensemble de la structure organisationnelle et des données de votre entreprise est décrit par un modèle conceptuel de données.
Il est utilisé pour organiser les concepts d’entreprise que vos ingénieurs de données ont spécifiés. Il se concentre sur la conception des entités, la définition des attributs d’une entité et la définition des relations entre les objets, plutôt que sur les spécificités de la structure de la base de données.
Par exemple, vous pouvez avoir des données sur les magasins, l’heure et les produits. Ces ensembles de données, ou entités, sont tous reliés à d’autres entités. Dans ce modèle conceptuel de données, les entités et les connexions entre entités sont spécifiées.
#2. Modélisation logique des données
Un modèle logique de données développe le modèle conceptuel en précisant les propriétés du contenu de chaque entité et les connexions détaillées entre ces attributs. La création d’un modèle logique de données peu complexe peut se faire en utilisant le modèle conceptuel de données comme ligne directrice.
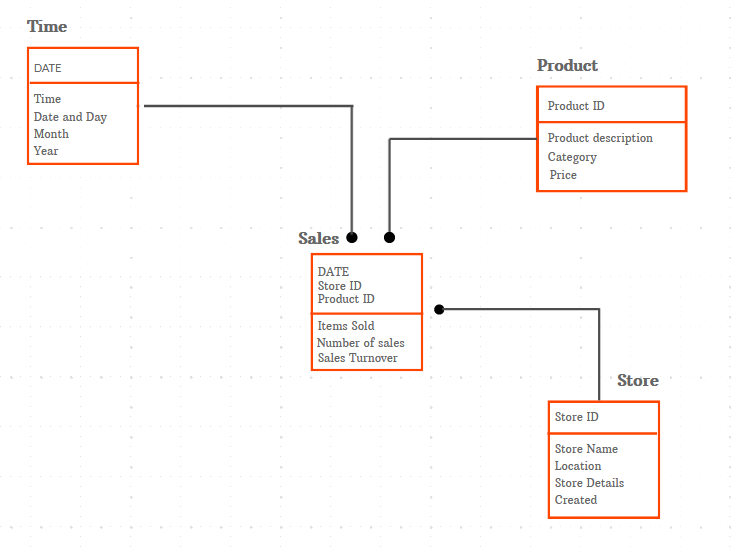
Les relations entre les éléments de données sont affichées dans les modèles de données logiques, qui fournissent également une description technique des données. Par exemple, le client A achète l’article B au magasin C.
La disposition des objets de données et les connexions entre eux sont définies plus précisément par ce modèle. L’objectif étant de créer un diagramme détaillé des normes et des structures de données, les modèles logiques de données sont généralement utilisés pour un projet particulier.
Le modèle logique de données fournit davantage d’informations sur l’ensemble de la conception du modèle conceptuel, mais il néglige les détails de la base de données elle-même, car le modèle peut être utilisé pour décrire divers produits et services de base de données.
Il s’agit d’un modèle technique des principes et des structures de données établis par les ingénieurs de données, qui aide à prendre des décisions sur le modèle de données physique nécessaire pour répondre à vos exigences en matière d’exploitation et de données.
#3. Modélisation physique des données
En règle générale, la mise en œuvre d’un modèle de données dans une base de données est décrite par un modèle de données physique. Les modèles de données physiques sont utilisés par les ingénieurs de bases de données pour développer les schémas et l’architecture des bases de données.
En simulant les composants du SGBDR, notamment les tables, les champs, les index, les clés de colonne, les contraintes, les déclencheurs et autres, le modèle de données physique facilite grandement la visualisation de la conception des bases de données.
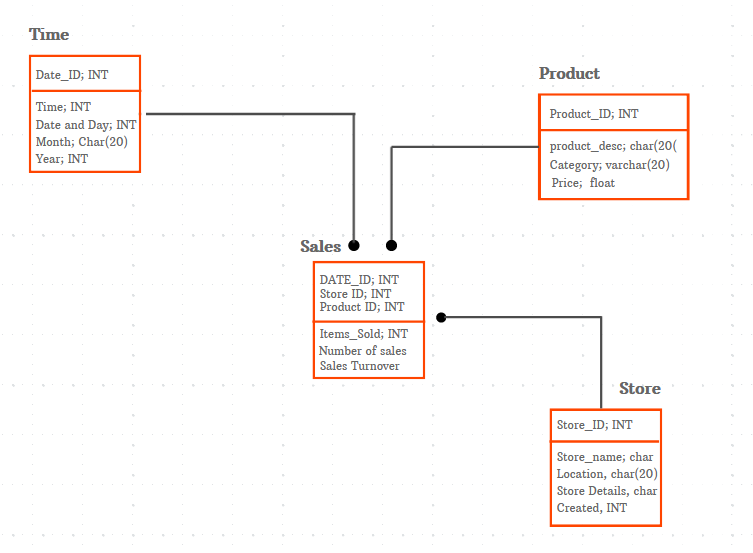
Il spécifie les processus organisationnels qu’une base de données ou un système de fichiers utilise pour capturer et traiter les données. Le modèle physique des données explique les détails pertinents de la manière dont le modèle logique sera mis en œuvre.
Il fournit une abstraction de la base de données et aide à créer le schéma ou la présentation. Ceci est dû aux méta-données étendues qu’un modèle de données physique fournit.
Cet article traitera principalement du concept de modélisation physique des données.
C’est parti !
Qu’est-ce qu’un modèle physique de données ?
Un modèle de données physique est un cadre ou une architecture qui décrit la manière dont les données sont conservées dans une base de données. Le schéma réel d’une base de données est conçu à l’aide de ce modèle de données physique. Il comprend toutes les tables, leurs colonnes et les connexions entre elles.
Le schéma interne d’une base de données est conçu à l’aide d’un modèle physique. L’objectif est de mettre la base de données en service. Ce modèle physique peut être directement converti en une conception de base de données réelle, ce qui favorise l’évolution de la gestion de l’information. Lorsque plusieurs systèmes de base de données sont utilisés, il est possible de créer différents modèles physiques à partir du même modèle logique de données.
Caractéristiques d’un modèle de données physique
- Il couvre les besoins en données d’un projet ou d’un programme spécifique, bien qu’il puisse être combiné à d’autres modèles physiques en fonction des objectifs du projet.
- Les types de données spécifiques, les tailles allouées et les valeurs par défaut des colonnes doivent être spécifiés.
- Les vues (table virtuelle basée sur l’ensemble des résultats), les index, les transactions et d’autres concepts sont définis, y compris les clés primaires et étrangères.
Les ingénieurs de base de données construisent le modèle de données physique avant d’appliquer le schéma de base de données final. Pour s’assurer que chaque composant de l’architecture a été pris en compte, ils utilisent également des approches complètes de modélisation des données.
Étapes nécessaires à la conception d’un modèle physique de données
Voici les étapes à suivre pour créer un modèle de données physique.
- Construisez un modèle de données physique en utilisant le modèle de données logique qui existe déjà.
- Ajoutez au modèle de données physique les attributs et les propriétés de la base de données.
- Convertissez les entités en tables et les relations entre entités en clés étrangères.
- Convertissez les attributs en colonnes.
- Vérifiez que tout est en ordre en comparant la base de données et le modèle de données.
- S’il y a des changements entre l’itération actuelle et les itérations précédentes du modèle de données, générez un enregistrement du journal des changements.
Composants clés d’un modèle de données physique
Un modèle physique de données (MPD) décrit la manière dont un modèle de données doit être structuré dans une base de données :
- Table : Le PDM établit des tables définissant des instances de concepts réels tels que les clients, les produits et les commandes, ainsi que les relations entre eux, tout en décrivant ce qui est nécessaire pour stocker les informations pertinentes.
- Colonne : Chaque base de données possède des tables individuelles, qui sont divisées en colonnes représentant les attributs de l’entité ou peut-être des caractéristiques, chacune avec son nom, son type de données unique et ses contraintes telles que les clés primaires/étrangères. Enfin, chaque ligne contient un enregistrement avec des données réelles.
- Types de données : Les informations d’une colonne définissent les données qu’elle doit stocker, ainsi que les exigences en matière de stockage et les performances associées. Le type d’informations qu’une colonne contient détermine les besoins de précision, les capacités de traitement et la capacité, entre autres. Les différents types de données ont des besoins différents en termes de précision, de capacité de traitement et de capacité, entre autres considérations.
- Clés primaires : Elles garantissent l’intégrité des données grâce à des colonnes distinctes, non annulables, qui identifient de manière unique chaque ligne d’une table.
- Clés étrangères : Elles garantissent un échange de données précis pour la protection de l’intégrité entre les tables ayant des clés étrangères avec des associations garanties, fiables et puissantes.
- Index : La structure des données permet d’améliorer les performances de la requête en identifiant rapidement les lignes qui répondent à certains critères.
- Contraintes : Les contraintes sont des ensembles de règles qui garantissent que vos données dans la base de données restent propres, valides et cohérentes. Les contraintes les plus courantes sont les suivantes
- NOT NULL : garantit qu’aucune valeur nulle ne sera stockée dans une colonne.
- UNIQUE : elle impose que toutes les valeurs d’une colonne soient uniques et distinctes.
- CHECK : une contrainte de ce type exige qu’une condition particulière soit remplie par les données contenues dans les colonnes.
- Informations sur le stockage : Mécanismes physiques qu’un système de gestion des données produit utilise pour le stockage des données. Il peut s’agir de moteurs de base de données, de systèmes de fichiers ou de dispositifs de stockage sur disque.
Modèle de données physique, conceptuel ou logique
Nous comparons ici ces trois catégories différentes de modèles de données. Les différentes caractéristiques sont comparées dans le tableau ci-dessous.
| Caractéristique | Conceptuelle | Logique | Physique |
|---|---|---|---|
| Noms d’entités | ✓ | ✓ | |
| Relations entre les entités | ✓ | ✓ | |
| Attributs | ✓ | ||
| Clés primaires | ✓ | ✓ | |
| Clés étrangères | ✓ | ✓ | |
| Noms de table | ✓ | ||
| Noms des colonnes | ✓ | ||
| Types de données des colonnes | ✓ |
Les entités et les connexions sont représentées dans un modèle conceptuel de données. Les caractéristiques et la clé primaire ne sont pas mentionnées. Il couvre simplement la conception de haut niveau, y compris les tables qui doivent exister et leurs liens.
Le modèle logique est créé à la suite du modèle conceptuel. Les relations entre les éléments de données sont affichées dans les modèles de données logiques, qui donnent également une description technique des données. En outre, il existe un modèle de données physiques qui développe le modèle de données logiques et attribue à chaque champ son type de données, sa taille, etc.
Bonnes pratiques en matière de modélisation physique des données
Vous trouverez ci-dessous quelques lignes directrices ou meilleures pratiques pour la modélisation physique des données, qui peuvent être modifiées en fonction de l’activité de l’entreprise :
Objectif de l’entreprise : La clé consiste à aligner votre modèle de données physiques sur les objectifs commerciaux et les besoins en données de votre organisation. Le modèle doit refléter de manière simple mais efficace les données nécessaires aux processus critiques et aux bonnes décisions, et ne doit pas être trop compliqué.
Conception et évolutivité : Pour commencer, il est important de créer un modèle de données logique bien défini qui servira de base à toute base de données physique. Il est important de planifier à l’avance et de concevoir votre système avec suffisamment de flexibilité et d’adaptabilité pour que tout changement futur puisse être effectué sans trop de perturbation ou de retard dans le processus. Les bases de données modulaires, qui mettent l’accent sur la réutilisation, sont essentielles à la mise en place de structures durables qui répondent aux besoins des entreprises, qui varient et changent considérablement avec le temps.
Technique de modélisation des données : Les facteurs à prendre en compte, tels que la taille des données, les exigences de performance, la structure des données et l’évolutivité, entre autres, aident à faire le bon choix lors de la sélection d’une technique de modélisation des données. Vos besoins spécifiques dépendront toutefois, par exemple, du type de base de données que vous utilisez pour tirer le meilleur parti de la solution choisie.
Convention d’appellation : La création de noms significatifs pour les entités, les attributs et les autres caractéristiques de votre modèle de données physique. Cela facilite la clarté dans la confusion parmi les parties prenantes pour communiquer et bien travailler ensemble. Des noms simples mais clairs sont choisis de manière à ce que chaque élément reflète sa raison d’être.
Normalisation des types de données : Utilisez des types de données normalisés dans l’ensemble de votre modèle de données physiques pour une performance uniforme et efficace. Cela simplifiera leur manipulation, garantira leur intégrité et permettra un échange efficace entre les différents systèmes en choisissant les types adéquats, en tenant compte des exigences en matière de stockage et d’autres aspects.
Règles d’intégrité des données : Elles doivent maintenir la cohérence et l’exactitude de toutes les entrées des clés primaires et étrangères, ainsi que des contraintes telles que NOT NULL, UNIQUE et CHECK dans les modèles physiques.
Indexation : L’indexation des tables doit être conçue de manière stratégique pour améliorer les performances des requêtes. Les index accélèrent l’accès aux données en permettant une recherche basée sur des critères et en optimisant l’indexation, ce qui implique une analyse efficace des requêtes et la détection des colonnes qui apparaissent fréquemment dans la requête.
Optimisation : Outre l’amélioration de l’intégrité des données, les administrateurs peuvent optimiser les performances globales de votre base de données, en utilisant intelligemment la normalisation et la dénormalisation, le partitionnement, les index en grappe et non en grappe, ainsi que des périphériques de stockage plus rapides pour les tables/index fréquemment utilisés.
Contrôle : Le contrôle est l’une des dernières étapes réalisées. Son objectif est d’évaluer les performances du modèle de données physique, d’identifier les goulets d’étranglement potentiels, de détecter les problèmes éventuels, d’explorer les domaines d’amélioration et de collecter les informations nécessaires à l’aide d’outils de contrôle des performances afin de prendre la meilleure décision.
Maintenance : Évaluer périodiquement le modèle de données physique pour confirmer qu’il reste efficace et l’adapter en fonction de l’évolution des besoins de l’entreprise et des exigences en matière de données.
Documentation : Développez le modèle de données physique dans des diagrammes, des descriptions, des tableaux et bien d’autres détails de ce qui est mis en œuvre. Utilisez un langage détaillé mais, en même temps, facile à comprendre par toutes les parties prenantes, qu’elles soient de nature technique ou non.
De cette manière, le modèle de données physique peut être formé de manière optimisée et efficace
Ressources pédagogiques sur la modélisation des données
Vous pouvez trouver de nombreuses ressources en ligne pour vous aider à comprendre la modélisation des données, mais il peut être difficile de choisir les bonnes. La modélisation des données est un talent précieux, mais il faut l’apprendre de la bonne manière.

Si vous essayez d’améliorer votre gestion des données ou vos compétences analytiques à des fins personnelles ou professionnelles, jetez un coup d’œil à cette liste des meilleurs cours et livres sur la modélisation des données.
#1. Maîtriser les fondamentaux de la modélisation des données
Grâce à ce cours Udemy, vous pouvez apprendre les méthodes nécessaires pour créer des modèles de données pour votre organisation contenant des entités, des caractéristiques, des associations, des structures et d’autres éléments de modélisation qui sont sémantiquement exacts.

Les apprenants ont juste besoin d’une compréhension fondamentale des termes et des structures de gestion des données, tels que les tables RDBMS et la façon dont les différents ensembles de données se rapportent conceptuellement les uns aux autres.
#2. Modélisation avancée des données
Ce cours Coursera est fantastique pour ceux qui cherchent à faire progresser leur carrière. À la fin de ce cours, vous aurez une solide compréhension de la façon d’utiliser les techniques fondamentales de modélisation des données et de parcourir les solutions de stockage contemporaines pour un système de base de données. Aucune connaissance préalable de l’ingénierie des bases de données n’est requise pour les apprenants.
#3. Cours sur la modélisation des données OBIEE 12c
Ce cours Udemy est destiné à toute personne intéressée par une carrière dans la modélisation des données OBIEE, y compris les étudiants, les professionnels de l’informatique et les chefs de projet.

A la fin de ce cours, vous serez en mesure de mettre en œuvre plusieurs fonctions de séries temporelles et des concepts de modélisation des données, y compris la dénormalisation des données, la modélisation des données dimensionnelles, et la modélisation des schémas en étoile.
#4. Excel Business Intelligence : Modélisation des données 101
Dans ce cours LinkedIn, le formateur couvre les fondamentaux de l’architecture et de la normalisation des bases de données, parcourt l’interface du modèle de données d’Excel et fournit des techniques testées.

Vous pouvez améliorer votre connaissance des liens entre les tables, des topologies et d’autres concepts en étudiant les sujets présentés dans ce cours. Aucun prérequis n’est nécessaire pour commencer ce cours.
#5. La boîte à outils de l’entrepôt de données
Dans ce livre, les auteurs présentent aux étudiants des approches de modélisation dimensionnelle telles que la facturation, les interactions avec les clients et la construction de bases de données de base. Ils abordent également les modèles de modélisation dimensionnelle nouveaux et améliorés que sont les schémas en étoile.
| Preview | Product | Rating | |
|---|---|---|---|

|
The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling | Buy on Amazon |
En outre, ce livre comprend des lignes directrices pour les réunions de simulation avancées avec les parties prenantes de l’entreprise. Aucune connaissance préalable de la modélisation des données n’est requise. Même les débutants se sentent à l’aise pour apprendre les concepts de modélisation des données en lisant ce livre.
#6. La modélisation des données en toute simplicité, 2e édition
Ce livre est écrit d’une manière qui inspire les utilisateurs à apprendre les objectifs clés, tels que comprendre quand un modèle de données est nécessaire et quelle forme sera la plus bénéfique, créer un système de base de données relationnel normalisé, utiliser des méthodes pour transformer un modèle de données en une disposition physique ayant un impact sur la base de données.
| Preview | Product | Rating | |
|---|---|---|---|

|
Data Modeling Made Simple, 2nd Edition: A Practical Guide for Business and IT Professionals | Buy on Amazon |
Ce livre offre une compréhension fonctionnelle réaliste des principes de modélisation des données et des meilleures pratiques à des fins commerciales ou informatiques.
#7. L’essentiel de la modélisation des données, troisième édition
Ce livre enseigne les principes fondamentaux de la modélisation des données tout en mettant l’accent sur le développement de techniques plutôt que sur la connaissance des “principes”
| Preview | Product | Rating | |
|---|---|---|---|

|
Data Modeling Essentials | Buy on Amazon |
Ce livre examine les complexités de la création de systèmes dans des circonstances réelles en pesant le pour et le contre de diverses alternatives et en utilisant un langage et des techniques d’analyse graphique qui reflètent les normes de l’industrie. Il encourage les apprenants à appliquer les principes fondamentaux de la modélisation des données à des modèles réels.
Tendances futures de la modélisation physique des données
Avec une concurrence accrue et la nécessité de différencier les produits ou les services qu’elles offrent, les organisations se tournent de plus en plus vers la modélisation des données comme moyen de gagner un avantage concurrentiel et d’améliorer l’expérience de leurs clients.
Avec ces stratégies de réduction des coûts en place, les entreprises vont maintenant tirer parti des technologies numériques telles que l’intelligence artificielle (IA), l’apprentissage automatique (ML) et l’automatisation pour tirer le meilleur parti de leurs investissements informatiques tout en obtenant de meilleurs résultats des activités de modélisation des données.

Et, en fait, en période d’incertitude, les entreprises propageront l’analyse prédictive pour prévoir les tendances de manière à garantir une meilleure planification. Pour une exécution efficace de ces tendances, il est essentiel que les entreprises et les organisations définissent correctement les objectifs des tâches pour lesquelles elles ont besoin de solutions de modélisation des données et qu’elles les alignent sur la stratégie globale de l’entreprise.
Certaines de ces tendances sont parmi les plus fondamentales et ont le plus grand impact sur l’avenir de la modélisation des données physiques :
#1. Automatisation et IA
L’IA et la ML ont une portée considérable. Les professionnels des données pourront utiliser l’IA et les algorithmes d’apprentissage automatique pour les solutions les plus complexes de modélisation des données, comme l’analyse prédictive. Cela fournira des informations qui aideront à prendre de meilleures décisions et, en retour, permettront aux entreprises d’améliorer leur efficacité.
Au fil des ans, l’IA et la ML seront de plus en plus utilisées pour automatiser une plus grande partie du processus de modélisation physique des données, comme la transformation des données, l’ingestion des données et l’automatisation du nettoyage des données de type “zero-day”. Cela permettra aux modélisateurs de données de se concentrer sur des tâches plus stratégiques, telles que la gouvernance et la qualité des données.
#2. Gouvernance et qualité des données
L’accent étant mis de plus en plus sur la sécurité des données, la réglementation en matière de conformité et la protection de la vie privée, les modèles physiques seront décrits de manière à tenir compte de ces exigences réglementaires. En outre, la conteneurisation et l’orchestration sont des techniques de déploiement émergentes pour les bases de données qui peuvent avoir des répercussions sur la structure et, par conséquent, sur la gestion future de leurs modèles physiques.
#3. Changements dans les modèles de données existants
Étant donné que les entreprises ont tendance à adopter des bases de données de séries temporelles pour inclure la modélisation en temps réel et les modèles pilotés par l’IA autour des données temporelles, il y aura par la suite des changements dans les modèles de données. Séries chronologiques – Elles permettent à l’analyste de repérer les tendances dans la représentation des données pour une meilleure appréciation du contexte. Les modélisateurs utilisent des fenêtres temporelles pour mettre à jour les diagrammes afin d’améliorer les processus et les flux.
#4. Big Data
Les capacités d’analyse en temps réel nécessitent des outils de modélisation tout aussi rationalisés et, par conséquent, les bases de données graphiques développées, avec leur capacité à modéliser des complexes de connexions, deviennent rapidement un choix standard pour les projets de big data, à côté des architectures de maillage de données récemment introduites, qui fournissent des fonctionnalités décentralisées à travers de nombreux systèmes, qui sont devenues ou ont menacé de devenir trop courantes ces derniers temps.
#5. Sécurité des données
La sécurité des données, la confidentialité des données et les considérations éthiques sont des éléments centraux que les entreprises modernes doivent prendre en compte pour assurer leur succès. Dans les entreprises, on s’inquiète des nombreuses réglementations qui protègent les informations personnelles afin qu’elles ne soient pas menacées par des influences extérieures, qu’il s’agisse du cryptage ou des contrôles d’accès.
Par essence, ces mesures fortes reflétant un sens de l’équité et de la transparence aideront les entreprises à protéger leurs intérêts ainsi que les droits des personnes qui sont attachées à l’identité numérique.
#6. Les données en tant que service (DaaS)
Les données en tant que service, également appelées DaaS, retiennent l’attention dans le panorama actuel de la gestion des données, car elles offrent des modèles et des outils accessibles à la demande, en amont de la construction, de la même manière que les logiciels.
Les implications du DaaS vont bien au-delà de la modélisation physique des données puisqu’il simplifie les tâches liées à la gestion d’énormes quantités d’informations en améliorant leur précision et leur qualité, en stimulant l’accessibilité des résultats analytiques et en transformant notre relation avec les points de données, ce qui se traduit par une prise de décision plus rapide grâce à l’analyse de sources de vastes quantités de manière exhaustive.
Les tendances mentionnées ci-dessus ne sont que quelques-unes des principales tendances de la modélisation des données physiques qui devraient façonner l’avenir et la façon dont toutes les organisations se développent.
Grâce à la connaissance et à l’adaptation rapide, les entreprises resteront non seulement efficaces et efficientes, mais seront également en mesure de répondre aux besoins de leurs activités. Les professionnels des données qui peuvent adopter ces tendances et améliorer les technologies et les outils les plus récents veilleront à ce que leurs organisations soient en mesure de répondre aux besoins de leurs clients.
Conclusion
Les organisations et les entreprises tentent continuellement de gagner des clients, et pour ce faire, elles doivent établir des tactiques qui propulseront leurs services vers l’avant. Ces tactiques impliquent l’utilisation de modèles de données pour améliorer les opérations commerciales.
Un bon modèle de données vous permettra d’économiser de l’argent et du temps et d’améliorer la productivité. L’utilisation du concept de modélisation des données peut permettre à une entreprise de devenir compétitive en mettant en œuvre des ajustements basés sur les données qu’elle a recueillies.
De nos jours, la demande de professionnels ayant des compétences en modélisation de données est très forte. Un emploi dans ce secteur peut offrir de nombreuses opportunités, car les données sont toujours disponibles pour être étudiées et stockées. J’espère que cet article vous a aidé à apprendre les concepts liés à la modélisation des données.