
Le web scraping consiste à extraire des informations d’un site web et à les utiliser pour un cas d’utilisation particulier.
Disons que vous essayez d’extraire un tableau d’une page web, de le convertir en fichier JSON et d’utiliser ce fichier JSON pour créer des outils internes. Avec l’aide du web scraping, vous pouvez extraire les données que vous souhaitez en ciblant les éléments spécifiques d’une page web. Le web scraping utilisant Python est un choix très populaire car Python fournit de nombreuses bibliothèques comme BeautifulSoup ou Scrapy pour extraire des données de manière efficace.

Il est également très important pour un développeur ou un data scientist de savoir extraire des données de manière efficace.
Découvrez ces bibliothèques Python pour les data scientists.
Cet article vous aidera à comprendre comment gratter un site web efficacement et obtenir le contenu nécessaire pour le manipuler selon vos besoins. Pour ce tutoriel, nous utiliserons le package BeautifulSoup. Il s’agit d’un package à la mode pour le scraping de données en Python.
Pourquoi utiliser Python pour le Web Scraping ?
Python est le premier choix de nombreux développeurs lorsqu’ils construisent des scrappeurs web. Il y a de nombreuses raisons pour lesquelles Python est le premier choix, mais pour cet article, nous allons discuter de trois raisons principales pour lesquelles Python est utilisé pour le scraping de données.
Bibliothèque et soutien de la communauté : Il existe plusieurs grandes bibliothèques, comme BeautifulSoup, Scrapy, Selenium, etc., qui fournissent d’excellentes fonctions pour le scraping de pages web. Python a construit un excellent écosystème pour le web scraping, et aussi parce que de nombreux développeurs dans le monde entier utilisent déjà Python, vous pouvez rapidement obtenir de l’aide lorsque vous êtes bloqué.
Automatisation : Python est réputé pour ses capacités d’automatisation. Si vous essayez de créer un outil complexe qui repose sur le scraping, il vous faudra plus que du web scraping. Par exemple, si vous voulez construire un outil qui suit le prix des articles dans un magasin en ligne, vous devrez ajouter une capacité d’automatisation afin qu’il puisse suivre les taux quotidiennement et les ajouter à votre base de données. Python vous permet d’automatiser facilement de tels processus.
Visualisation des données : Le web scraping est très utilisé par les data scientists. Ces derniers ont souvent besoin d’extraire des données de pages web. Grâce à des bibliothèques comme Pandas, Python simplifie la visualisation des données à partir de données brutes.
Bibliothèques pour le Web Scraping en Python
Il existe plusieurs bibliothèques disponibles en Python pour simplifier le web scraping. Nous allons examiner ici les trois bibliothèques les plus populaires.
#1. BeautifulSoup
L’une des bibliothèques les plus populaires pour le web scraping. BeautifulSoup aide les développeurs à scraper des pages web depuis 2004. Elle fournit des méthodes simples pour naviguer, rechercher et modifier l’arbre d’analyse. BeautifulSoup se charge également de l’encodage des données entrantes et sortantes. Il est bien entretenu et dispose d’une grande communauté.
#2. Scrapy
Un autre framework populaire pour l’extraction de données. Scrapy a plus de 43000 étoiles sur GitHub. Il peut également être utilisé pour extraire des données des API. Il dispose également de quelques supports intégrés intéressants, comme l’envoi d’emails.
#3. Selenium
Selenium n’est pas principalement une bibliothèque de web scraping. Il s’agit plutôt d’un logiciel d’automatisation de navigateur. Mais nous pouvons facilement étendre ses fonctionnalités pour le scraping de pages web. Il utilise le protocole WebDriver pour contrôler différents navigateurs. Selenium est présent sur le marché depuis près de 20 ans. Mais avec Selenium, vous pouvez facilement automatiser et extraire des données de pages web.
Les défis du Web Scraping en Python
Vous pouvez être confronté à de nombreux défis lorsque vous essayez de récupérer des données sur des sites web. Il y a des problèmes comme les réseaux lents, les outils anti-scraping, le blocage basé sur l’IP, le blocage captcha, etc. Ces problèmes peuvent entraîner d’énormes difficultés lorsque l’on tente de récupérer des données sur un site web.
Mais vous pouvez contourner efficacement les difficultés en suivant certaines méthodes. Par exemple, dans la plupart des cas, une adresse IP est bloquée par un site web lorsqu’il y a plus d’un certain nombre de requêtes envoyées dans un intervalle de temps spécifique. Pour éviter ce blocage, vous devez coder votre scraper de manière à ce qu’il se refroidisse après avoir envoyé des requêtes.

Les développeurs ont également tendance à mettre en place des pièges à miel pour les scrapeurs. Ces pièges sont généralement invisibles à l’œil nu mais peuvent être explorés par un scraper. Si vous scrapez un site web qui met en place un tel piège, vous devrez coder votre scraper en conséquence.
Le captcha est un autre problème grave pour les scrapeurs. La plupart des sites web utilisent aujourd’hui un captcha pour protéger l’accès des robots à leurs pages. Dans ce cas, vous devrez peut-être utiliser un résolveur de captcha.
Scraping d’un site web avec Python
Comme nous l’avons dit, nous allons utiliser BeautifulSoup pour scraper un site web. Dans ce tutoriel, nous allons récupérer les données historiques d’Ethereum à partir de Coingecko et sauvegarder les données de la table dans un fichier JSON. Passons maintenant à la construction du scraper.
La première étape consiste à installer BeautifulSoup et Requests. Pour ce tutoriel, j’utiliserai Pipenv. Pipenv est un gestionnaire d’environnement virtuel pour Python. Vous pouvez également utiliser Venv si vous le souhaitez, mais je préfère Pipenv. Discuter de Pipenv dépasse le cadre de ce tutoriel. Mais si vous voulez apprendre comment Pipenv peut être utilisé, suivez ce guide. Ou, si vous voulez comprendre les environnements virtuels Python, suivez ce guide.
Lancez le shell Pipenv dans le répertoire de votre projet en exécutant la commande pipenv shell. Cela lancera un sous-shell dans votre environnement virtuel. Maintenant, pour installer BeautifulSoup, exécutez la commande suivante :
pipenv install beautifulsoup4Et pour installer requests, exécutez la commande similaire à la précédente :
pipenv install requestsUne fois l’installation terminée, importez les paquets nécessaires dans le fichier principal. Créez un fichier appelé main.py et importez les paquets comme ci-dessous :
from bs4 import BeautifulSoup
import requests
import jsonL’étape suivante consiste à récupérer le contenu de la page de données historiques et à l’analyser en utilisant l’analyseur HTML disponible dans BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')Dans le code ci-dessus, la page est accédée en utilisant la méthode get disponible dans la bibliothèque requests. Le contenu analysé est ensuite stocké dans une variable appelée soup.
La partie originale du scraping commence maintenant. Tout d’abord, vous devez identifier correctement le tableau dans le DOM. Si vous ouvrez cette page et l’inspectez en utilisant les outils de développement disponibles dans le navigateur, vous verrez que le tableau a ces classes table table-striped text-sm text-lg-normal.
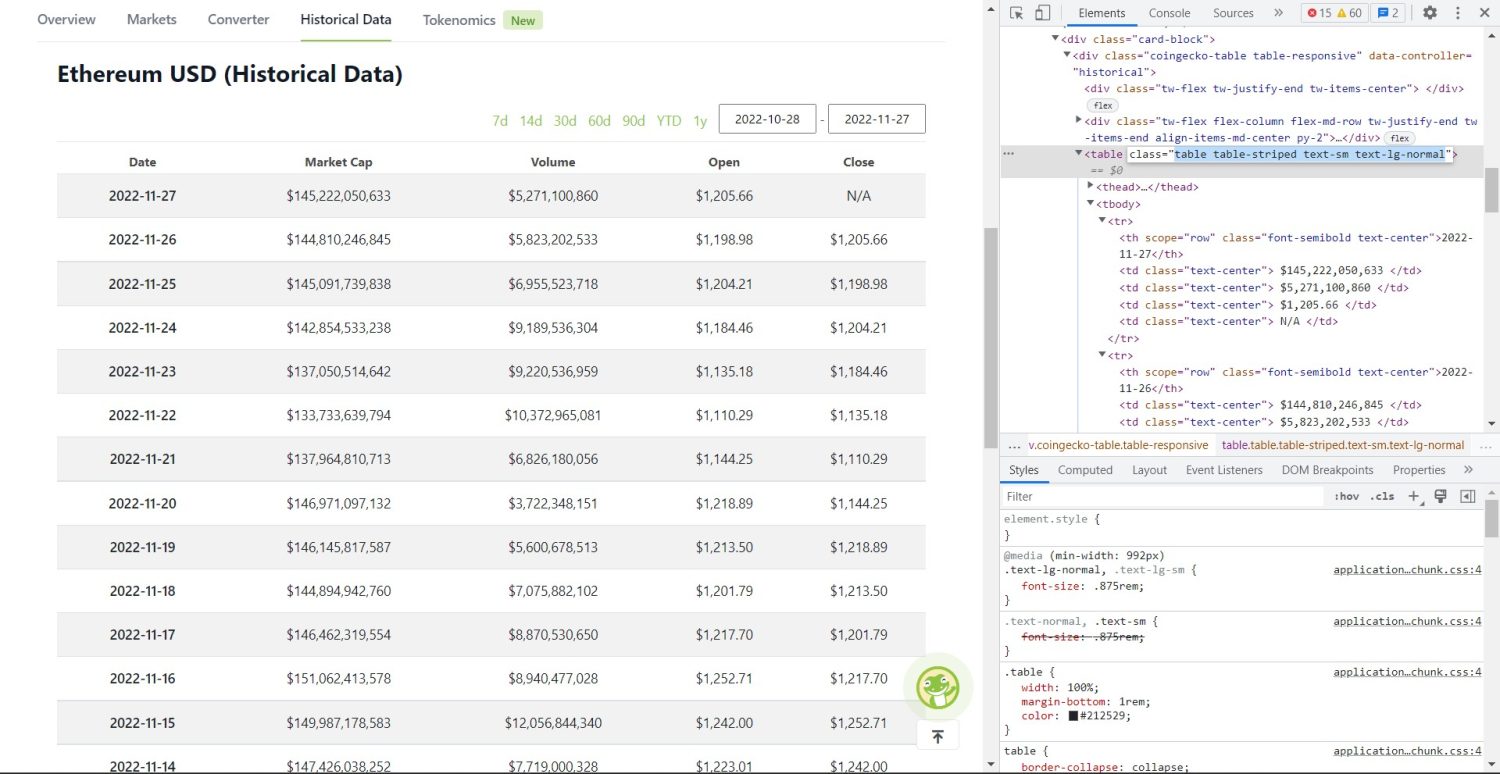
Pour cibler correctement ce tableau, vous pouvez utiliser la méthode find.
table = soup.find('table', attrs={'class' : 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th') :
table_headings.append(th.text)Dans le code ci-dessus, le tableau est d’abord trouvé à l’aide de la méthode soup.find, puis à l’aide de la méthode find_all, tous les éléments tr à l’intérieur du tableau sont recherchés. Ces éléments sont stockés dans une variable appelée table_data. Le tableau comporte quelques éléments th pour le titre. Une nouvelle variable appelée table_headings est initialisée pour conserver les titres dans une liste.
Une boucle for est ensuite exécutée pour la première ligne du tableau. Dans cette ligne, tous les éléments avec th sont recherchés et leur valeur textuelle est ajoutée à la liste table_headings. Le texte est extrait à l’aide de la méthode text. Si vous imprimez maintenant la variable table_headings, vous obtiendrez le résultat suivant :
['Date', 'Market Cap', 'Volume', 'Open', 'Close']L’étape suivante consiste à récupérer le reste des éléments, à générer un dictionnaire pour chaque ligne, puis à ajouter les lignes à une liste.
pour tr dans table_data :
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)) :
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i 1] : td[i].text.replace('\n', '')})
if data.__len__() > 0 :
table_details.append(data)Il s’agit de la partie essentielle du code. Pour chaque tr de la variable table_data, les trois premiers éléments sont recherchés. Ces éléments sont les dates indiquées dans le tableau. Ces éléments th sont stockés dans une variable th. De même, tous les éléments td sont stockés dans la variable td.
Un dictionnaire de données vide est initialisé. Après l’initialisation, nous parcourons en boucle la plage des éléments td. Pour chaque ligne, nous mettons d’abord à jour le premier champ du dictionnaire avec le premier élément de th. Le code table_headings<x><x><x><x>[0]</x></x></x></x>: th<x><x><x><x>[0]</x></x></x></x>.text attribue une paire clé-valeur de date et le premier élément th.
Après l’initialisation du premier élément, les autres éléments sont affectés à l’aide de data.update({table_headings[i 1] : td<x>[i]</x>.text.replace('\N', '')}). Ici, le texte des éléments td est d’abord extrait à l’aide de la méthode text, puis tout \Nest remplacé à l’aide de la méthode replace. La valeur est ensuite attribuée au i 1eélément de la liste table_headings, car le ieélément est déjà attribué.
Ensuite, si la longueur du dictionnaire de données est supérieure à zéro, nous ajoutons le dictionnaire à la liste table_details. Vous pouvez imprimer la liste table_details pour vérifier. Mais nous écrirons les valeurs dans un fichier JSON. Jetons un coup d’œil au code correspondant,
with open('table.json', 'w') as f :
json.dump(table_details, f, indent=2)
print('Données sauvegardées dans un fichier json...')Nous utilisons ici la méthode json.dump pour écrire les valeurs dans un fichier JSON appelé table.json. Une fois l’écriture terminée, nous affichons Data saved to json file… dans la console.
Maintenant, exécutez le fichier à l’aide de la commande suivante,
python run main.pyAprès un certain temps, vous pourrez voir le texte Data saved to JSON file… dans la console. Vous verrez également un nouveau fichier appelé table.json dans le répertoire de travail. Ce fichier ressemblera au fichier JSON suivant :
[
{
"Date" : "2022-11-27",
"Capitalisation boursière" : "$145,222,050,633",
"Volume" : "$5,271,100,860",
"Open" : "$1,205.66",
"Close" : "N/A"
},
{
"Date" : "2022-11-26",
"Market Cap" : "$144,810,246,845",
"Volume" : "$5,823,202,533",
"Open" : "$1,198.98",
"Close" : "$1,205.66"
},
{
"Date" : "2022-11-25",
"Market Cap" : "$145,091,739,838",
"Volume" : "$6,955,523,718",
"Open" : "1 204,21 $", "Volume" : "6 955 523 718 $" : "$1,204.21",
"Close" : "$1,198.98"
},
// ...
// ...
]Vous avez réussi à implémenter un scraper web en utilisant Python. Pour voir le code complet, vous pouvez visiter ce repo GitHub.
Conclusion
Cet article explique comment vous pouvez implémenter un simple scrape en Python. Nous avons vu comment BeautifulSoup pouvait être utilisé pour récupérer rapidement des données d’un site web. Nous avons également discuté des autres bibliothèques disponibles et des raisons pour lesquelles Python est le premier choix de nombreux développeurs pour le scraping de sites web.