
Vor Jahren, als es noch Unix-Server mit großen Dateisystemen vor Ort gab, haben Unternehmen umfangreiche Regeln für die Ordnerverwaltung und Strategien für die Verwaltung von Zugriffsrechten auf verschiedene Ordner für verschiedene Personen entwickelt.
In der Regel bedient die Plattform eines Unternehmens verschiedene Benutzergruppen mit völlig unterschiedlichen Interessen, Vertraulichkeitsbeschränkungen oder Inhaltsdefinitionen. Im Falle globaler Organisationen könnte dies sogar bedeuten, dass Inhalte nach dem Standort getrennt werden, also im Grunde genommen zwischen Benutzern aus verschiedenen Ländern.

Weitere typische Beispiele könnten sein:
- die Trennung von Daten zwischen Entwicklungs-, Test- und Produktionsumgebungen
- vertriebsinhalte, die nicht für ein breites Publikum zugänglich sind
- länderspezifische gesetzgeberische Inhalte, die von einer anderen Region aus nicht eingesehen oder abgerufen werden können
- projektbezogene Inhalte, bei denen “Führungsdaten” nur einer begrenzten Gruppe von Personen zur Verfügung gestellt werden sollen usw.
Es gibt eine potentiell endlose Liste solcher Beispiele. Der Punkt ist, dass es immer notwendig ist, die Zugriffsrechte auf Dateien und Daten zwischen allen Benutzern, denen die Plattform Zugriff gewährt, zu koordinieren.
Im Falle von On-Premise-Lösungen war dies eine Routineaufgabe. Der Administrator des Dateisystems stellte einfach ein paar Regeln auf, verwendete ein Tool seiner Wahl und ordnete dann die Personen den Benutzergruppen zu und die Benutzergruppen einer Liste von Ordnern oder Einhängepunkten, auf die sie zugreifen können sollten. Dabei wurde die Zugriffsebene als reiner Lese- oder Lese- und Schreibzugriff definiert.
Wenn man sich nun die AWS-Cloud-Plattformen ansieht, liegt es auf der Hand, dass die Menschen ähnliche Anforderungen an die Zugriffsbeschränkungen für Inhalte haben. Die Lösung für dieses Problem muss jetzt jedoch anders aussehen. Dateien befinden sich nicht mehr auf Unix-Servern, sondern in der Cloud (und sind möglicherweise nicht nur für das gesamte Unternehmen, sondern sogar für die ganze Welt zugänglich), und die Inhalte werden nicht in Ordnern, sondern in S3-Buckets gespeichert.

Nachfolgend wird eine Alternative beschrieben, um dieses Problem anzugehen. Sie basiert auf den Erfahrungen, die ich in der Praxis gemacht habe, als ich solche Lösungen für ein konkretes Projekt entwickelt habe.
Einfacher, aber sehr manueller Ansatz
Eine Möglichkeit, dieses Problem ohne jegliche Automatisierung zu lösen, ist relativ geradlinig und einfach:
- Erstellen Sie einen neuen Bereich für jede einzelne Gruppe von Personen.
- Weisen Sie dem Bucket Zugriffsrechte zu, so dass nur diese spezielle Gruppe auf den S3-Bucket zugreifen kann.
Das ist sicherlich möglich, wenn Sie eine sehr einfache und schnelle Lösung anstreben. Es gibt jedoch einige Grenzen, die Sie beachten müssen.
Standardmäßig können nur bis zu 100 S3-Buckets unter einem AWS-Konto erstellt werden. Dieses Limit kann auf 1000 erweitert werden, indem Sie eine Service-Limit-Erhöhung für das AWS-Ticket einreichen. Wenn diese Begrenzungen für Ihren speziellen Implementierungsfall nicht von Belang sind, können Sie jeden Ihrer verschiedenen Domain-Benutzer mit einem separaten S3-Bucket arbeiten lassen und das war’s.
Problematisch wird es, wenn es einige Personengruppen mit funktionsübergreifenden Verantwortlichkeiten gibt oder einfach einige Personen, die gleichzeitig Zugriff auf die Inhalte mehrerer Domänen benötigen. Zum Beispiel:
- Datenanalysten, die die Dateninhalte für mehrere verschiedene Bereiche, Regionen usw. auswerten.
- Das Testteam, das für verschiedene Entwicklungsteams gemeinsame Dienste erbringt.
- Reporting-Benutzer, die Dashboard-Analysen über verschiedene Länder innerhalb derselben Region erstellen müssen.
Wie Sie sich vielleicht vorstellen können, kann diese Liste noch viel länger werden, und die Bedürfnisse der Unternehmen können alle möglichen Anwendungsfälle hervorbringen.
Je komplexer diese Liste wird, desto komplexer wird die Orchestrierung der Zugriffsrechte, um all diesen verschiedenen Gruppen unterschiedliche Zugriffsrechte auf verschiedene S3-Buckets im Unternehmen zu gewähren. Es werden zusätzliche Tools und vielleicht sogar eine spezielle Ressource (Administrator) benötigt, um die Zugriffsrechtslisten zu pflegen und zu aktualisieren, sobald eine Änderung erforderlich ist (was sehr häufig der Fall sein wird, vor allem wenn das Unternehmen groß ist).
Wie lässt sich also dasselbe auf organisierte und automatisierte Weise erreichen?
Wenn der Bucket-per-Domain-Ansatz nicht funktioniert, führt jede andere Lösung zu gemeinsamen Buckets für mehrere Benutzergruppen. In solchen Fällen ist es notwendig, die gesamte Logik der Zuweisung von Zugriffsrechten in einem Bereich zu verankern, der sich leicht ändern oder dynamisch aktualisieren lässt.
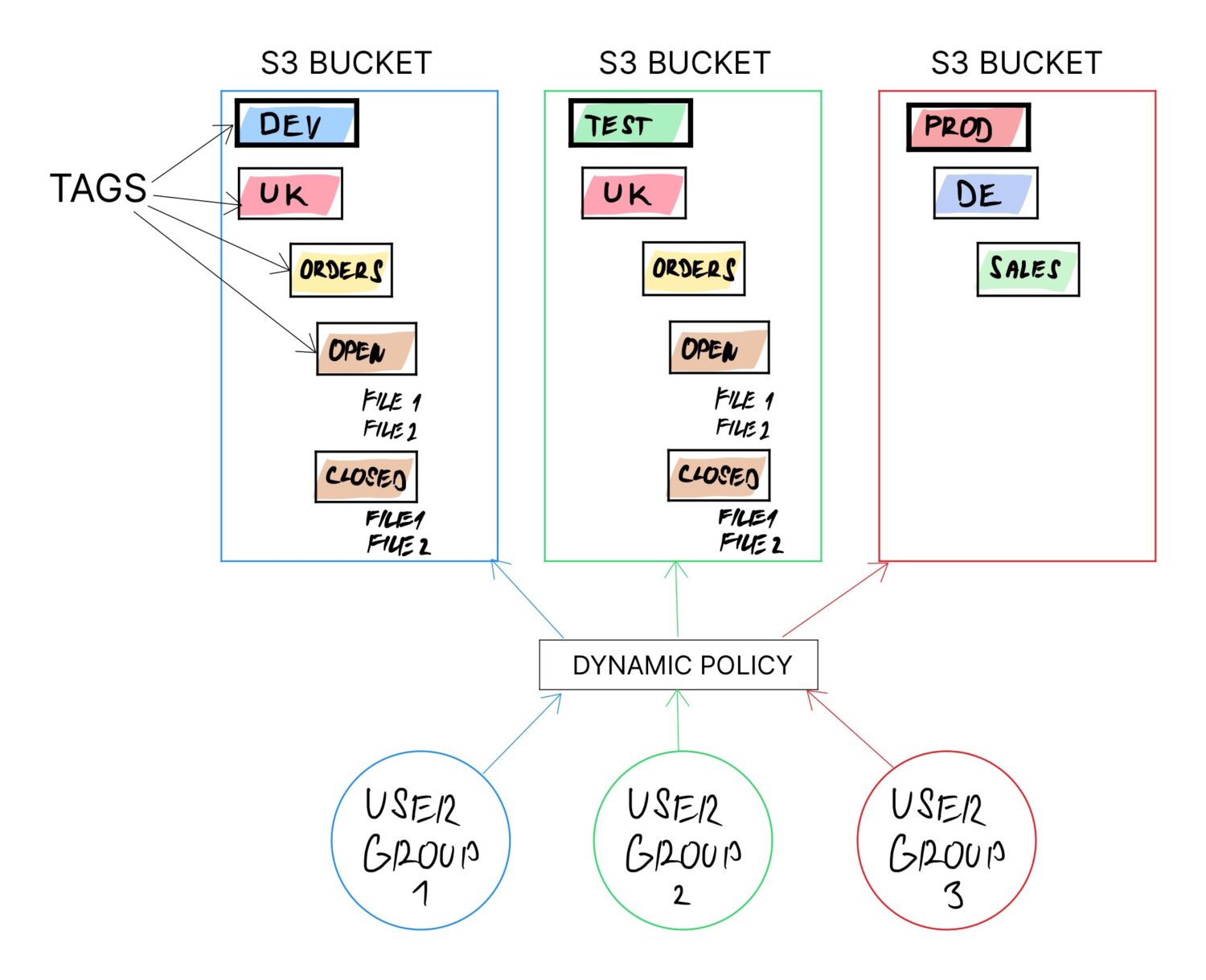
Eine der Möglichkeiten, dies zu erreichen, ist die Verwendung von Tags für die S3-Buckets. Die Verwendung von Tags wird in jedem Fall empfohlen (und sei es nur, um die Kategorisierung von Rechnungen zu erleichtern). Das Tag kann jedoch jederzeit in der Zukunft für jeden Bucket geändert werden.
Wenn die gesamte Logik auf den Eimer-Tags basiert und der Rest der Konfiguration von den Tag-Werten abhängt, ist die dynamische Eigenschaft gewährleistet, da man den Zweck des Eimers einfach durch Aktualisierung der Tag-Werte neu definieren kann.
Welche Art von Tags sollten Sie verwenden, damit dies funktioniert?
Das hängt von Ihrem konkreten Anwendungsfall ab. Zum Beispiel:
- Es kann erforderlich sein, Buckets nach Umgebungstyp zu trennen. In diesem Fall muss einer der Tag-Namen so etwas wie “ENV” mit den möglichen Werten “DEV”, “TEST”, “PROD” usw. lauten.
- Vielleicht möchten Sie das Team nach Land trennen. In diesem Fall lautet ein weiteres Tag “COUNTRY” mit dem Wert eines Ländernamens.
- Oder Sie möchten die Benutzer nach der funktionalen Abteilung trennen, zu der sie gehören, wie z.B. Business-Analysten, Data-Warehouse-Benutzer, Data Scientists, usw. Sie erstellen also ein Tag mit dem Namen “USER_TYPE” und dem entsprechenden Wert.
- Eine andere Möglichkeit wäre, dass Sie explizit eine feste Ordnerstruktur für bestimmte Benutzergruppen definieren möchten, die diese verwenden müssen (damit sie nicht ihr eigenes Ordnergewirr anlegen und sich darin mit der Zeit verlieren). Das können Sie wiederum mit Tags machen, bei denen Sie mehrere Arbeitsverzeichnisse angeben können, wie z.B.: “data/import”, “data/processed”, “data/error”, usw.
Idealerweise definieren Sie die Tags so, dass sie logisch miteinander kombiniert werden können und eine ganze Ordnerstruktur auf dem Bucket bilden.
So können Sie z.B. die folgenden Tags aus den obigen Beispielen kombinieren, um eine spezielle Ordnerstruktur für verschiedene Benutzertypen aus verschiedenen Ländern mit vordefinierten Importordnern zu erstellen, die sie verwenden sollen:
- /
/ / /
Indem Sie den
Dies ermöglicht die Verwendung desselben Buckets für viele verschiedene Benutzer. Buckets unterstützen nicht explizit Ordner, aber sie unterstützen “Labels”. Diese Labels funktionieren letztlich wie Unterordner, da die Benutzer eine Reihe von Labels durchlaufen müssen, um an ihre Daten zu gelangen (genau wie bei Unterordnern).
Nachdem Sie die Tags in einer brauchbaren Form definiert haben, besteht der nächste Schritt darin, S3-Bucket-Richtlinien zu erstellen, die diese Tags verwenden.
Wenn die Richtlinien die Tag-Namen verwenden, erstellen Sie so genannte “dynamische Richtlinien”. Das bedeutet, dass sich Ihre Richtlinie für Buckets mit unterschiedlichen Tag-Werten, auf die sich die Richtlinie in Form von Platzhaltern bezieht, unterschiedlich verhält.
Dieser Schritt erfordert natürlich eine individuelle Kodierung der dynamischen Richtlinien, aber Sie können diesen Schritt vereinfachen, indem Sie das Amazon AWS Richtlinien-Editor-Tool verwenden, das Sie durch den Prozess führt.
In der Richtlinie selbst müssen Sie die konkreten Zugriffsrechte, die auf den Bucket angewendet werden sollen, und die Zugriffsebene dieser Rechte (Lesen, Schreiben) kodieren. Die Logik liest die Tags auf den Buckets und baut die Ordnerstruktur auf dem Bucket auf (indem sie Etiketten auf der Grundlage der Tags erstellt). Auf der Grundlage der konkreten Werte der Tags werden die Unterordner erstellt und die erforderlichen Zugriffsrechte werden entsprechend zugewiesen.
Das Schöne an einer solchen dynamischen Richtlinie ist, dass Sie nur eine einzige dynamische Richtlinie erstellen und dieselbe dynamische Richtlinie dann vielen Buckets zuweisen können. Diese Richtlinie wird sich für Buckets mit unterschiedlichen Tag-Werten unterschiedlich verhalten, aber sie wird immer mit Ihren Erwartungen für einen Bucket mit solchen Tag-Werten übereinstimmen.
Auf diese Weise können Sie die Zuweisung von Zugriffsrechten für eine große Anzahl von Buckets auf organisierte, zentralisierte Weise verwalten, wobei Sie davon ausgehen, dass jeder Bucket bestimmten, im Voraus vereinbarten Vorlagenstrukturen folgt, die von Ihren Benutzern im gesamten Unternehmen verwendet werden.
Automatisieren Sie das Onboarding von neuen Entitäten
Nachdem Sie dynamische Richtlinien definiert und den vorhandenen Buckets zugewiesen haben, können die Benutzer dieselben Buckets verwenden, ohne dass die Gefahr besteht, dass Benutzer aus verschiedenen Gruppen nicht auf Inhalte zugreifen können (die im selben Bucket gespeichert sind), die sich unter einer Ordnerstruktur befinden, auf die sie keinen Zugriff haben.
Außerdem wird es für einige Benutzergruppen mit breiterem Zugriff einfach sein, auf die Daten zuzugreifen, da sie alle im selben Bucket gespeichert sind.
Der letzte Schritt besteht darin, das Onboarding neuer Benutzer, neuer Buckets und sogar neuer Tags so einfach wie möglich zu gestalten. Dies führt zu einer weiteren benutzerdefinierten Kodierung, die jedoch nicht übermäßig komplex sein muss, vorausgesetzt, Ihr Onboarding-Prozess hat einige sehr klare Regeln, die mit einer einfachen, geradlinigen Algorithmuslogik gekapselt werden können (zumindest können Sie auf diese Weise beweisen, dass Ihr Prozess eine gewisse Logik hat und nicht auf allzu chaotische Weise abläuft).
Das kann so einfach sein wie die Erstellung eines per AWS CLI-Befehl ausführbaren Skripts mit Parametern, die für das erfolgreiche Onboarding einer neuen Entität in die Plattform erforderlich sind. Es kann sogar eine Reihe von CLI-Skripten sein, die in einer bestimmten Reihenfolge ausgeführt werden, wie z.B.:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - usw.
Sie verstehen, was ich meine. 😃
Ein Pro-Tipp 👨💻
Wenn Sie möchten, gibt es noch einen Pro-Tipp, der sich leicht auf das oben Gesagte anwenden lässt.
Die dynamischen Richtlinien können nicht nur für die Zuweisung von Zugriffsrechten für Ordner verwendet werden, sondern auch für die automatische Zuweisung von Servicerechten für die Buckets und Benutzergruppen!
Sie müssen lediglich die Liste der Tags für die Buckets erweitern und dann dynamische Zugriffsrechte für die Nutzung bestimmter Dienste für konkrete Benutzergruppen hinzufügen.
Zum Beispiel könnte es eine Gruppe von Benutzern geben, die auch Zugriff auf den spezifischen Datenbank-Cluster-Server benötigen. Dies lässt sich zweifellos mit dynamischen Richtlinien erreichen, die Bucket-Tasks nutzen, vor allem, wenn der Zugriff auf die Dienste rollenbasiert erfolgt. Fügen Sie dem dynamischen Richtliniencode einfach einen Teil hinzu, der Tags bezüglich der Spezifikation des Datenbank-Clusters verarbeitet und die Zugriffsrechte der Richtlinie direkt diesem bestimmten DB-Cluster und dieser Benutzergruppe zuweist.
Auf diese Weise lässt sich die Einbindung einer neuen Benutzergruppe allein mit dieser einen dynamischen Richtlinie durchführen. Da es sich um eine dynamische Richtlinie handelt, kann sie außerdem für das Onboarding vieler verschiedener Benutzergruppen wiederverwendet werden (die der gleichen Vorlage folgen sollen, aber nicht unbedingt den gleichen Diensten).
Sie können auch einen Blick auf diese AWS S3-Befehle werfen, um Buckets und Daten zu verwalten.