Im Informationszeitalter sammeln Rechenzentren große Mengen an Daten. Die gesammelten Daten stammen aus verschiedenen Quellen wie Finanztransaktionen, Kundeninteraktionen, sozialen Medien und vielen anderen Quellen, und – was noch wichtiger ist – sie sammeln sich immer schneller an.
Daten können vielfältig und sensibel sein und erfordern die richtigen Tools, um sie sinnvoll zu nutzen, denn sie haben ein unbegrenztes Potenzial, Geschäftsstatistiken und Informationen zu modernisieren und das Leben zu verändern.
Lassen Sie uns daher die besten Big Data-Tools kennenlernen.
Apache Hadoop
ApacheHadoop ist eine Open-Source-Java-Plattform, die große Mengen an Daten speichert und verarbeitet.

Hadoop funktioniert, indem es große Datensätze (von Terabyte bis Petabyte) abbildet, Aufgaben zwischen Clustern analysiert und sie in kleinere Brocken (64MB bis 128MB) aufteilt, was zu einer schnelleren Datenverarbeitung führt.
Um Daten zu speichern und zu verarbeiten, werden die Daten an den Hadoop-Cluster gesendet, HDFS (Hadoop Distributed File System) speichert die Daten, MapReduce verarbeitet die Daten und YARN (Yet another resource negotiator) teilt die Aufgaben auf und weist die Ressourcen zu.
Es eignet sich für Datenwissenschaftler, Entwickler und Analysten aus verschiedenen Unternehmen und Organisationen für Forschung und Produktion.
Funktionen
- Datenreplikation: Mehrere Kopien des Blocks werden in verschiedenen Knoten gespeichert und dienen als Fehlertoleranz im Falle eines Fehlers.
- Hochgradig skalierbar: Bietet vertikale und horizontale Skalierbarkeit
- Integration mit anderen Apache-Modellen, Cloudera und Hortonworks
Nehmen Sie an diesem hervorragenden Online-Kurs teil, um Big Data mit Apache Spark zu lernen.
Rapidminer
Auf der Website von Rapidminer wird behauptet, dass etwa 40.000 Unternehmen weltweit ihre Software nutzen, um den Umsatz zu steigern, Kosten zu senken und Risiken zu vermeiden.

Die Software hat mehrere Auszeichnungen erhalten: Gartner Vision Awards 2021 für Data-Science- und Machine-Learning-Plattformen, multimodale prädiktive Analysen und Machine-Learning-Lösungen von Forrester und Crowd’s benutzerfreundlichste Machine-Learning- und Data-Science-Plattform im Frühjahrs-G2-Report 2021.
Es handelt sich um eine End-to-End-Plattform für den wissenschaftlichen Lebenszyklus, die nahtlos integriert und für die Erstellung von ML-Modellen (maschinelles Lernen) optimiert ist. Sie dokumentiert automatisch jeden Schritt der Vorbereitung, Modellierung und Validierung für vollständige Transparenz.
Es handelt sich um eine kostenpflichtige Software, die in drei Versionen erhältlich ist: Prep Data, Create and Validate und Deploy Model. Für Bildungseinrichtungen ist sie sogar kostenlos erhältlich. RapidMiner wird von mehr als 4.000 Universitäten weltweit genutzt.
Funktionen
- Es prüft Daten, um Muster zu erkennen und Qualitätsprobleme zu beheben
- Es verwendet einen kodierungsfreien Workflow-Designer mit 1500 Algorithmen
- Integration von maschinellen Lernmodellen in bestehende Geschäftsanwendungen
Tableau
Tableau bietet die Flexibilität, Plattformen visuell zu analysieren, Probleme zu lösen und Menschen und Organisationen zu unterstützen. Es basiert auf der VizQL-Technologie (visuelle Sprache für Datenbankabfragen), die über eine intuitive Benutzeroberfläche Drag & Drop in Datenabfragen umwandelt.
Tableau wurde im Jahr 2019 von Salesforce übernommen. Es ermöglicht die Verknüpfung von Daten aus Quellen wie SQL-Datenbanken, Tabellenkalkulationen oder Cloud-Anwendungen wie Google Analytics und Salesforce.
Benutzer können die Versionen Creator, Explorer und Viewer je nach geschäftlichen oder individuellen Präferenzen erwerben, da jede Version ihre eigenen Merkmale und Funktionen hat.
Es ist ideal für Analysten, Datenwissenschaftler, den Bildungssektor und Geschäftsanwender, um eine datengesteuerte Kultur zu implementieren, auszugleichen und anhand von Ergebnissen zu bewerten.
Funktionen
- Dashboards bieten einen vollständigen Überblick über Daten in Form von visuellen Elementen, Objekten und Text.
- Große Auswahl an Datendiagrammen: Histogramme, Gantt-Diagramme, Charts, Bewegungsdiagramme und viele mehr
- Filterschutz auf Zeilenebene, um Daten sicher und stabil zu halten
- Seine Architektur bietet vorhersehbare Analysen und Prognosen
Tableau ist leicht zuerlernen.
Cloudera
Cloudera bietet eine sichere Plattform für Clouds und Rechenzentren für Big Data Management. Sie nutzt Datenanalysen und maschinelles Lernen, um komplexe Daten in klare, umsetzbare Erkenntnisse zu verwandeln.
Cloudera bietet Lösungen und Tools für private und hybride Clouds, Data Engineering, Datenfluss, Datenspeicherung, Data Science für Data Scientists und mehr.

Eine einheitliche Plattform und multifunktionale Analysen verbessern den Prozess der datengesteuerten Erkenntnisgewinnung. Seine Data Science bietet Konnektivität zu jedem System, das das Unternehmen verwendet, nicht nur zu Cloudera und Hortonworks (beide Unternehmen sind Partnerschaften eingegangen).
Datenwissenschaftler verwalten ihre eigenen Aktivitäten wie Analyse, Planung, Überwachung und E-Mail-Benachrichtigungen über interaktive Datenwissenschaft-Arbeitsblätter. Standardmäßig handelt es sich um eine sicherheitskonforme Plattform, die es Datenwissenschaftlern ermöglicht, auf Hadoop-Daten zuzugreifen und Spark-Abfragen einfach auszuführen.
Die Plattform eignet sich für Dateningenieure, Datenwissenschaftler und IT-Experten in verschiedenen Branchen wie Krankenhäusern, Finanzinstituten, Telekommunikation und vielen anderen.
Funktionen
- Unterstützt alle wichtigen privaten und öffentlichen Clouds, während die Data Science Workbench den Einsatz vor Ort unterstützt
- Automatisierte Datenkanäle konvertieren Daten in nutzbare Formen und integrieren sie mit anderen Quellen.
- Einheitliche Arbeitsabläufe ermöglichen eine schnelle Modellerstellung, Schulung und Implementierung.
- Sichere Umgebung für die Authentifizierung, Autorisierung und Verschlüsselung von Hadoop.
Apache Hive
Apache Hive ist ein Open-Source-Projekt, das auf der Grundlage von Apache Hadoop entwickelt wurde. Es ermöglicht das Lesen, Schreiben und Verwalten großer Datensätze, die in verschiedenen Repositories verfügbar sind, und erlaubt es Benutzern, ihre eigenen Funktionen für benutzerdefinierte Analysen zu kombinieren.
Hive wurde für traditionelle Speicheraufgaben entwickelt und ist nicht für Online-Verarbeitungsaufgaben gedacht. Seine robusten Batch-Frames bieten Skalierbarkeit, Leistung, Skalierbarkeit und Fehlertoleranz.
Es eignet sich für die Datenextraktion, prädiktive Modellierung und Indizierung von Dokumenten. Es wird nicht für die Abfrage von Echtzeitdaten empfohlen, da es zu Latenzzeiten beim Abrufen von Ergebnissen kommt.
Funktionen
- Unterstützt MapReduce, Tez und Spark Computing Engine
- Verarbeitet riesige Datensätze, die mehrere Petabytes groß sind
- Sehr einfach zu programmieren im Vergleich zu Java
- Bietet Fehlertoleranz durch Speicherung der Daten im verteilten Dateisystem von Apache Hadoop
Apache Storm
Apache Storm ist eine kostenlose Open-Source-Plattform für die Verarbeitung unbegrenzter Datenströme. Sie bietet den kleinsten Satz von Verarbeitungseinheiten, die zur Entwicklung von Anwendungen verwendet werden, die sehr große Datenmengen in Echtzeit verarbeiten können.
Ein Storm ist schnell genug, um eine Million Tupel pro Sekunde pro Knoten zu verarbeiten, und er ist einfach zu bedienen.
Mit Apache Storm können Sie weitere Knoten zu Ihrem Cluster hinzufügen und die Verarbeitungsleistung Ihrer Anwendung erhöhen. Die Verarbeitungskapazität kann durch Hinzufügen von Knoten verdoppelt werden, da die horizontale Skalierbarkeit erhalten bleibt.
Datenwissenschaftler können Storm für DRPC (Distributed Remote Procedure Calls), ETL-Analysen (Retrieval-Conversion-Load) in Echtzeit, kontinuierliche Berechnungen, maschinelles Online-Lernen usw. verwenden. Storm ist so konzipiert, dass es die Echtzeitverarbeitungsanforderungen von Twitter, Yahoo und Flipboard erfüllt.
Merkmale
- Einfach zu verwenden mit jeder Programmiersprache
- Es ist in jedes Warteschlangensystem und jede Datenbank integriert
- Storm verwendet Zookeeper zur Verwaltung von Clustern und skaliert zu größeren Clustern
- Garantierte Datensicherung ersetzt verlorene Tupel, wenn etwas schief geht
Snowflake
Die größte Herausforderung für Datenwissenschaftler ist die Aufbereitung von Daten aus verschiedenen Ressourcen, da die meiste Zeit mit dem Abrufen, Konsolidieren, Bereinigen und Aufbereiten von Daten verbracht wird. Diesem Problem begegnet Snowflake.
Es bietet eine einzige Hochleistungsplattform, die den Ärger und die Verzögerung durch ETL (Load Transformation and Extraction) eliminiert. Snowflake kann auch mit den neuesten Tools und Bibliotheken für maschinelles Lernen (ML) integriert werden, wie z.B. Dask und Saturn Cloud.
Snowflake bietet eine einzigartige Architektur mit dedizierten Compute-Clustern für jeden Workload, um solche High-Level-Computing-Aktivitäten durchzuführen, so dass es keine gemeinsame Nutzung von Ressourcen zwischen Data Science- und BI- (Business Intelligence-) Workloads gibt.
Es unterstützt Datentypen aus strukturierten, halbstrukturierten (JSON, Avro, ORC, Parquet oder XML) und unstrukturierten Daten. Es verwendet eine Data Lake-Strategie, um den Datenzugriff, die Leistung und die Sicherheit zu verbessern.
Datenwissenschaftler und Analysten nutzen Snowflakes in verschiedenen Branchen, darunter Finanzen, Medien und Unterhaltung, Einzelhandel, Gesundheit und Biowissenschaften, Technologie und der öffentliche Sektor.
Merkmale
- Hohe Datenkomprimierung zur Senkung der Speicherkosten
- Bietet Datenverschlüsselung im Ruhezustand und bei der Übertragung
- Schnelle Verarbeitungs-Engine mit geringer operativer Komplexität
- Integrierte Datenprofilierung mit Tabellen-, Diagramm- und Histogramm-Ansichten
DataRobot
DataRobot ist ein weltweit führender Anbieter von Cloud-Lösungen mit KI (Künstlicher Intelligenz). Seine einzigartige Plattform wurde entwickelt, um alle Branchen zu bedienen, einschließlich der Benutzer und der verschiedenen Arten von Daten.

Das Unternehmen behauptet, dass die Software von einem Drittel der Fortune 50-Unternehmen genutzt wird und mehr als eine Billion Schätzungen in verschiedenen Branchen liefert.
DataRobot verwendet automatisiertes maschinelles Lernen (ML) und wurde für Datenexperten in Unternehmen entwickelt, um schnell genaue Prognosemodelle zu erstellen, anzupassen und einzusetzen.
Es bietet Wissenschaftlern einen einfachen Zugang zu vielen der neuesten Algorithmen für maschinelles Lernen mit vollständiger Transparenz, um die Datenvorverarbeitung zu automatisieren. Die Software hat spezielle R- und Python-Clients für Wissenschaftler entwickelt, um komplexe Data Science-Probleme zu lösen.
Sie hilft bei der Automatisierung von Datenqualität, Feature-Engineering und Implementierungsprozessen, um die Arbeit von Datenwissenschaftlern zu erleichtern. Es handelt sich um ein Premium-Produkt und der Preis ist auf Anfrage erhältlich.
Funktionen
- Erhöht den Geschäftswert in Bezug auf Rentabilität, vereinfachte Prognosen
- Implementierungsprozesse und Automatisierung
- Unterstützt Algorithmen aus Python, Spark, TensorFlow und anderen Quellen.
- Dank der API-Integration können Sie aus Hunderten von Modellen wählen
TensorFlow
TensorFlow ist eine auf KI (künstliche Intelligenz) basierende Bibliothek, die Datenflussdiagramme verwendet, um Anwendungen für maschinelles Lernen (ML) zu erstellen, zu trainieren und einzusetzen. Damit können Entwickler große geschichtete neuronale Netzwerke erstellen.

Sie umfasst drei Modelle – TensorFlow.js, TensorFlow Lite und TensorFlow Extended (TFX). Der Javascript-Modus wird für das Training und den Einsatz von Modellen im Browser und gleichzeitig auf Node.js verwendet. Der Lite-Modus ist für die Bereitstellung von Modellen auf mobilen und eingebetteten Geräten gedacht, und das TFX-Modell dient der Vorbereitung von Daten, der Validierung und der Bereitstellung von Modellen.
Aufgrund seiner robusten Plattform kann es unabhängig von der Programmiersprache auf Servern, Edge-Geräten oder im Web eingesetzt werden.
TFX enthält Mechanismen zur Durchsetzung von ML-Pipelines, die aufsteigend sein können und robuste Gesamtleistungsaufgaben bieten. Die Data-Engineering-Pipelines wie Kubeflow und Apache Airflow unterstützen TFX.
Die Tensorflow-Plattform ist für Anfänger geeignet. Fortgeschrittene und Experten können mit Keras ein generatives adversariales Netzwerk trainieren, um Bilder von handgeschriebenen Ziffern zu generieren.
Merkmale
- ML-Modelle können vor Ort, in der Cloud, im Browser und unabhängig von der Sprache eingesetzt werden
- Einfache Modellerstellung über angeborene APIs zur schnellen Wiederholung von Modellen
- Seine verschiedenen Zusatzbibliotheken und Modelle unterstützen Forschungsaktivitäten zum Experimentieren
- Einfache Modellerstellung auf mehreren Abstraktionsebenen
Matplotlib
Matplotlib ist eine umfassende Community-Software zur Visualisierung von animierten Daten und grafischen Darstellungen für die Programmiersprache Python. Ihr einzigartiges Design ist so aufgebaut, dass mit wenigen Zeilen Code ein visuelles Datendiagramm erzeugt wird.
Es gibt verschiedene Anwendungen von Drittanbietern wie Zeichenprogramme, grafische Benutzeroberflächen, Farbkarten, Animationen und vieles mehr, die für die Integration mit Matplotlib konzipiert sind.
Die Funktionalität von Matplotlib kann mit vielen Tools wie Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn und anderen erweitert werden.
Zu seinen besten Funktionen gehört das Zeichnen von Diagrammen und Karten mit strukturierten und unstrukturierten Daten.
BigML
BigML ist eine gemeinsame und transparente Plattform für Ingenieure, Datenwissenschaftler, Entwickler und Analysten. Sie führt eine durchgängige Datentransformation in umsetzbare Modelle durch.

Sie erstellt, experimentiert, automatisiert und verwaltet effektiv ML-Workflows und trägt so zu intelligenten Anwendungen in einer Vielzahl von Branchen bei.
Diese programmierbare ML-Plattform (maschinelles Lernen) hilft bei der Sequenzierung, Zeitreihenvorhersage, Assoziationserkennung, Regression, Clusteranalyse und mehr.
Die vollständig verwaltbare Version mit einzelnen und mehreren Mandanten und einer möglichen Bereitstellung für jeden Cloud-Anbieter macht es Unternehmen leicht, allen den Zugang zu Big Data zu ermöglichen.
Der Preis beginnt bei 30 $, ist für kleine Datensätze und Bildungszwecke kostenlos und wird in über 600 Universitäten eingesetzt.
Dank seiner robusten ML-Algorithmen eignet es sich für verschiedene Branchen wie Pharmazeutik, Unterhaltung, Automobilbau, Luft- und Raumfahrt, Gesundheitswesen, IoT und viele mehr.
Funktionen
- Automatisieren Sie zeitaufwändige und komplexe Arbeitsabläufe mit einem einzigen API-Aufruf
- Es kann große Datenmengen verarbeiten und parallele Aufgaben durchführen
- Die Bibliothek wird von gängigen Programmiersprachen wie Python, Node.js, Ruby, Java, Swift, etc. unterstützt.
- Seine granularen Details erleichtern die Arbeit bei Audits und regulatorischen Anforderungen
Apache Spark
Es ist eine der größten Open-Source-Engines, die von großen Unternehmen eingesetzt wird. Laut der Website wird Apache Spark von 80% der Fortune 500-Unternehmen verwendet. Es ist mit einzelnen Knoten und Clustern für Big Data und ML kompatibel.

Sie basiert auf fortschrittlichem SQL (Structured Query Language), um große Datenmengen zu unterstützen und mit strukturierten Tabellen und unstrukturierten Daten zu arbeiten.
Die Spark-Plattform ist bekannt für ihre Benutzerfreundlichkeit, die große Community und die blitzschnelle Geschwindigkeit. Die Entwickler verwenden Spark, um Anwendungen zu erstellen und Abfragen in Java, Scala, Python, R und SQL auszuführen.
Funktionen
- Verarbeitet Daten sowohl im Batch als auch in Echtzeit
- Unterstützt große Datenmengen im Petabyte-Bereich ohne Downsampling
- Es macht es einfach, mehrere Bibliotheken wie SQL, MLib, Graphx und Stream in einem einzigen Arbeitsablauf zu kombinieren.
- Funktioniert auf Hadoop YARN, Apache Mesos, Kubernetes und sogar in der Cloud und hat Zugriff auf mehrere Datenquellen
KNIME
KNIME ist eine intuitive Open-Source-Plattform für Data-Science-Anwendungen. Datenwissenschaftler und Analysten können visuelle Workflows ohne Kodierung mit einfachen Drag-and-Drop-Funktionen erstellen.

Die Serverversion ist eine Handelsplattform, die für die Automatisierung, das Data Science Management und die Managementanalyse verwendet wird. KNIME macht Data-Science-Workflows und wiederverwendbare Komponenten für jedermann zugänglich.
Merkmale
- Hochflexibel für die Datenintegration aus Oracle, SQL, Hive und mehr
- Zugriff auf Daten aus verschiedenen Quellen wie SharePoint, Amazon Cloud, Salesforce, Twitter und mehr
- Die Verwendung von ml erfolgt in Form von Modellerstellung, Leistungsoptimierung und Modellvalidierung.
- Dateneinblicke in Form von Visualisierung, Statistik, Verarbeitung und Berichterstattung
Als nächstes werden wir die Bedeutung von Big-Data-Tools diskutieren.
Big Data-Tools und Datenwissenschaftler spielen in solchen Szenarien eine wichtige Rolle.
Eine so große Menge an unterschiedlichen Daten lässt sich mit herkömmlichen Tools und Techniken wie Excel nur schwer verarbeiten. Excel ist nicht wirklich eine Datenbank und hat eine Grenze (65.536 Zeilen) für die Speicherung von Daten.
Die Datenanalyse in Excel weist eine schlechte Datenintegrität auf. Langfristig gesehen sind in Excel gespeicherte Daten nur begrenzt sicher und regelkonform, die Wiederherstellungsraten im Notfall sind sehr niedrig und es gibt keine angemessene Versionskontrolle.
Um solch große und vielfältige Datensätze zu verarbeiten, benötigen Sie eine einzigartige Reihe von Tools, die so genannten Daten-Tools, um wertvolle Informationen zu untersuchen, zu verarbeiten und zu extrahieren. Mit diesen Tools können Sie tief in Ihre Daten eindringen, um aussagekräftigere Erkenntnisse und Datenmuster zu finden.
Der Umgang mit solch komplexen Technologie-Tools und Daten erfordert natürlich besondere Fähigkeiten, und deshalb spielt der Data Scientist eine wichtige Rolle bei Big Data.
Die Bedeutung von Big-Data-Tools
Daten sind der Grundbaustein eines jeden Unternehmens und werden verwendet, um wertvolle Informationen zu extrahieren, detaillierte Analysen durchzuführen, Möglichkeiten zu schaffen und neue Meilensteine und Visionen für das Unternehmen zu planen.
Jeden Tag werden mehr und mehr Daten erstellt, die effizient und sicher gespeichert und bei Bedarf abgerufen werden müssen. Der Umfang, die Vielfalt und der schnelle Wandel dieser Daten erfordern neue Big-Data-Tools, unterschiedliche Speicher- und Analysemethoden.
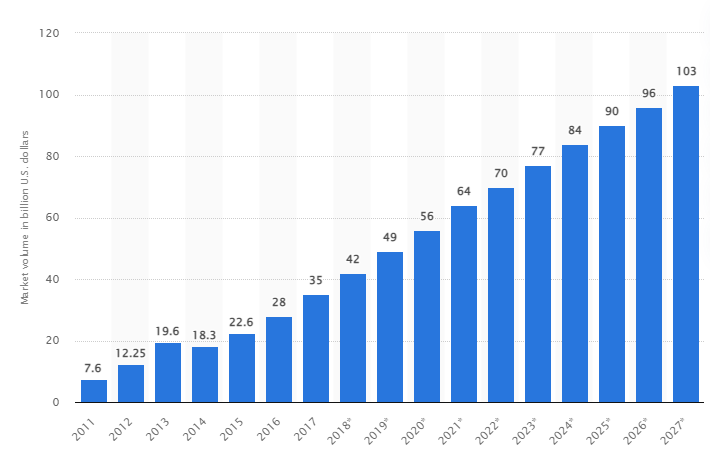
Laut einer Studie wird der globale Big-Data-Markt bis 2027 auf 103 Milliarden US-Dollar anwachsen, was mehr als das Doppelte des für 2018 erwarteten Marktvolumens ist.
Heutige Herausforderungen der Industrie
Der Begriff “Big Data” wird in letzter Zeit für Datensätze verwendet, die so groß geworden sind, dass sie mit herkömmlichen Datenbankmanagementsystemen (DBMS) nur noch schwer zu verarbeiten sind.
Die Datengrößen nehmen ständig zu und reichen heute von einigen zehn Terabytes (TB) bis zu vielen Petabytes (PB) in einem einzigen Datensatz. Die Größe dieser Datensätze übersteigt die Fähigkeit gängiger Software, sie zu verarbeiten, zu verwalten, zu durchsuchen, weiterzugeben und zu visualisieren.
Die Entstehung von Big Data wird zu Folgendem führen:
- Qualitätsmanagement und -verbesserung
- Lieferketten- und Effizienzmanagement
- Kundenintelligenz
- Datenanalyse und Entscheidungsfindung
- Risikomanagement und Betrugserkennung
In diesem Abschnitt befassen wir uns mit den besten Big Data-Tools und damit, wie Datenwissenschaftler diese Technologien nutzen, um sie zu filtern, zu analysieren, zu speichern und zu extrahieren, wenn Unternehmen eine tiefere Analyse wünschen, um ihr Geschäft zu verbessern und auszubauen.
Welche Bedeutung haben die 5 V’s von Big Data?
Die 5 V’s von Big Data helfen Datenwissenschaftlern, Big Data zu verstehen und zu analysieren, um mehr Erkenntnisse zu gewinnen. Sie helfen auch dabei, mehr Statistiken zu erstellen, die für Unternehmen nützlich sind, um fundierte Entscheidungen zu treffen und einen Wettbewerbsvorteil zu erlangen.
👉 Volumen: Big Data basiert auf dem Volumen. Das Datenvolumen bestimmt, wie groß die Daten sind. In der Regel enthält es eine große Menge an Daten in Terabyte, Petabyte usw. Basierend auf der Größe des Volumens planen Datenwissenschaftler verschiedene Tools und Integrationen für die Analyse von Datensätzen.
👉 Geschwindigkeit: Die Geschwindigkeit der Datenerfassung ist von entscheidender Bedeutung, da einige Unternehmen Dateninformationen in Echtzeit benötigen, während andere es vorziehen, Daten in Paketen zu verarbeiten. Je schneller der Datenfluss, desto mehr Datenwissenschaftler können die Daten auswerten und dem Unternehmen relevante Informationen zur Verfügung stellen.
👉 Vielfältigkeit: Die Daten stammen aus verschiedenen Quellen und, was wichtig ist, nicht in einem festen Format. Die Daten liegen in strukturierten (Datenbankformat), halbstrukturierten (XML/RDF) und unstrukturierten (Binärdaten) Formaten vor. Auf der Grundlage von Datenstrukturen werden Big Data-Tools verwendet, um Daten zu erstellen, zu organisieren, zu filtern und zu verarbeiten.
👉 Wahrhaftigkeit: Die Genauigkeit der Daten und glaubwürdige Quellen definieren den Big Data-Kontext. Der Datensatz stammt aus verschiedenen Quellen wie Computern, Netzwerkgeräten, mobilen Geräten, sozialen Medien usw. Dementsprechend müssen die Daten analysiert werden, bevor sie an ihren Bestimmungsort gesendet werden.
👉 Wert: Und schließlich: Wie viel sind die Big Data eines Unternehmens wert? Die Rolle des Datenwissenschaftlers besteht darin, die Daten bestmöglich zu nutzen, um zu zeigen, wie die Erkenntnisse aus den Daten einen Mehrwert für ein Unternehmen schaffen können.
Schlussfolgerung 👇
Die obige Big Data-Liste enthält kostenpflichtige Tools und Open-Source-Tools. Zu jedem Tool finden Sie kurze Informationen und Funktionen. Wenn Sie ausführliche Informationen suchen, können Sie die entsprechenden Websites besuchen.
Unternehmen, die sich einen Wettbewerbsvorteil verschaffen wollen, nutzen Big Data und verwandte Tools wie KI (künstliche Intelligenz), ML (maschinelles Lernen) und andere Technologien, um taktische Maßnahmen zur Verbesserung von Kundenservice, Forschung, Marketing, Zukunftsplanung usw. zu ergreifen.
Big Data-Tools werden in den meisten Branchen eingesetzt, da kleine Änderungen in der Produktivität zu erheblichen Einsparungen und großen Gewinnen führen können. Wir hoffen, dass der obige Artikel Ihnen einen Überblick über Big Data-Tools und ihre Bedeutung gegeben hat.