Die Unternehmen von heute sind datenzentriert. Unternehmen finden Wege, um Daten aus verschiedenen Quellen effizient zu nutzen und zu analysieren und so ihre Umsätze und Gewinne zu steigern.
Aber was ist der sicherste Ort, um Daten aus verschiedenen Quellen zu speichern und zu integrieren und das Beste daraus zu machen?
Sowohl Data Lakes als auch Data Warehouses sind beliebte Methoden, um große Mengen an Big Data zu verwalten. Die Unterschiede zwischen ihnen liegen darin, wie Unternehmen die Daten aufnehmen, speichern und nutzen. Lesen Sie weiter, um mehr zu erfahren.
Was ist ein Data Lake?
Ein Data Lake ist ein zentraler Speicher, in dem Daten aus verschiedenen Quellen – in jedem Format (strukturiert oder unstrukturiert) – gespeichert werden. Er ist wie ein Pool von Rohdaten, deren Zweck noch unbekannt ist. Unternehmen speichern in einem Data Lake in der Regel Daten, die für zukünftige Analysen von Nutzen sein könnten.
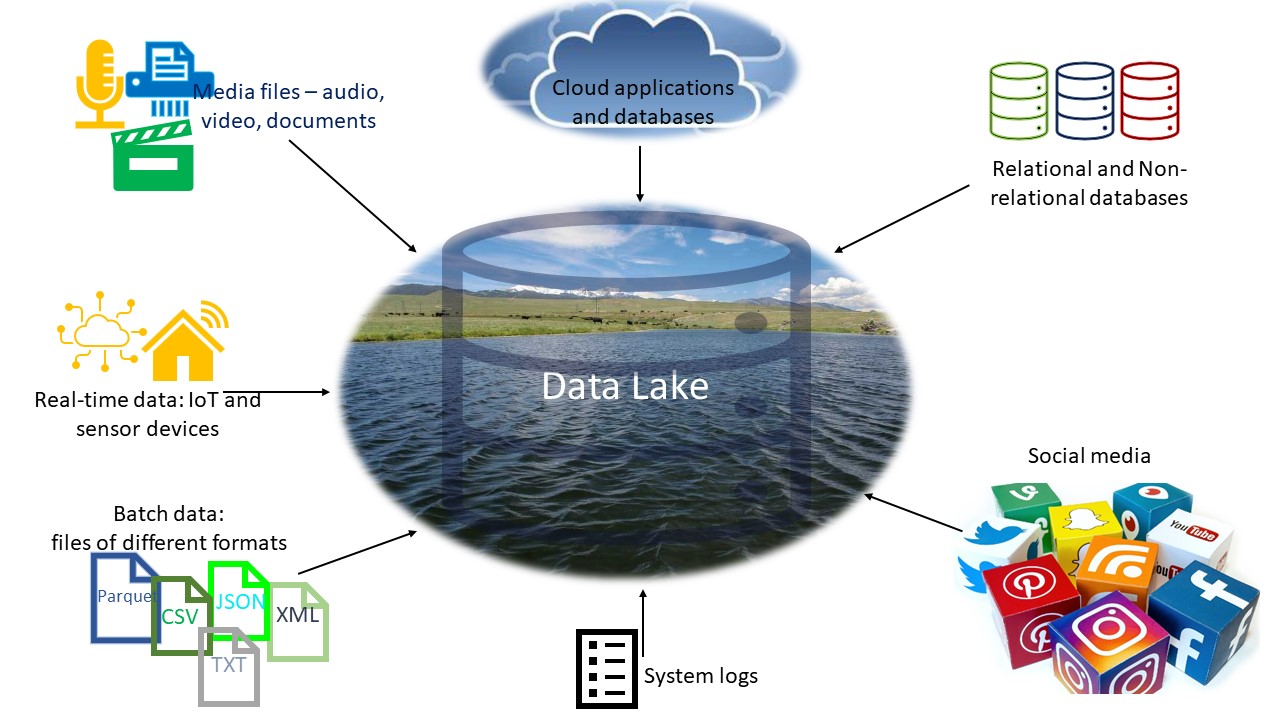
Hauptmerkmale eines Data Lake:
- Er enthält eine Mischung aus nützlichen und nicht nützlichen Daten und benötigt daher eine Menge Speicherplatz.
- Er speichert sowohl Echtzeit- als auch Stapeldaten – Sie können z.B. Echtzeitdaten von IoT-Geräten, sozialen Medien oder Cloud-Anwendungen und Stapeldaten aus Datenbanken oder Datendateien speichern.
- Hat eine flache Architektur.
- Da die Daten erst verarbeitet werden, wenn sie für die Analyse benötigt werden, müssen sie gut verwaltet und gepflegt werden, da sie sonst zu einem Datensumpf werden können.
Wie können wir also schnell Daten aus einem so großen und scheinbar unübersichtlichen Speicher abrufen? Nun, ein Data Lake verwendet zu diesem Zweck Metadaten-Tags und Identifikatoren!
Was ist ein Data Warehouse?
Ein besser organisiertes und strukturiertes Repository – ein Data Warehouse enthält Daten, die für die Analyse bereitstehen. Strukturierte, halbstrukturierte oder unstrukturierte Daten aus verschiedenen Quellen werden aufgenommen, integriert, bereinigt, sortiert, umgewandelt und für die Verwendung fit gemacht.
Das Data Warehouse enthält große Mengen an vergangenen und aktuellen Daten. Normalerweise werden die Daten für ein bestimmtes Geschäftsproblem (Analyse) verarbeitet. Solche Informationen werden von Business Intelligence (BI)-Systemen für Analysen, Berichte und Erkenntnisse abgefragt.
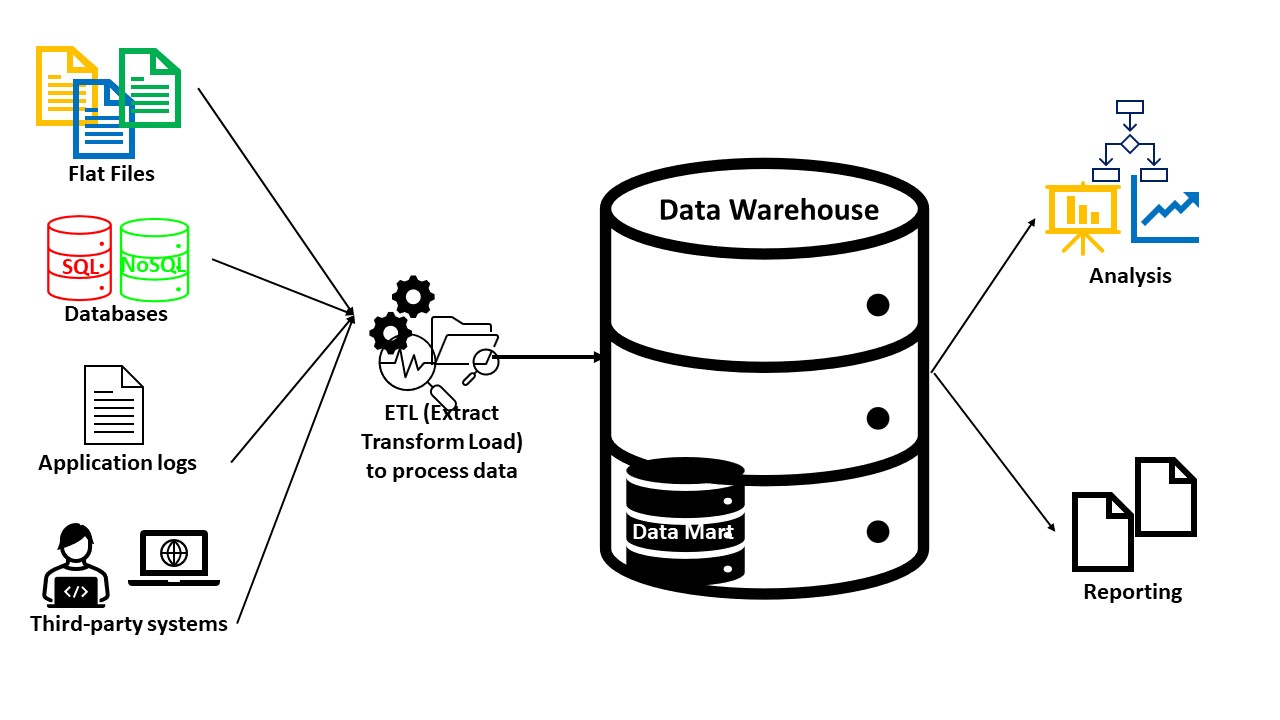
Data Warehouses bestehen in der Regel aus Folgendem:
- Eine Datenbank (SQL oder NoSQL) zum Speichern und Verwalten von Daten
- Datenumwandlungs- und Analysetools zur Aufbereitung der Daten
- BI-Tools für Data Mining, statistische Analysen, Berichte und Visualisierung
Da Data Warehouses einem bestimmten Zweck dienen, werden Sie immer über relevante Daten verfügen. Sie können auch zusätzliche Tools in Data Warehouses verwenden, um erweiterte Funktionen wie künstliche Intelligenz und räumliche oder grafische Funktionen zu nutzen. Data Warehouses, die für einen bestimmten Bereich erstellt werden, nennt man Data Marts.
Hauptunterschiede zwischen Data Lakes und Data Warehouses
Um noch einmal zu wiederholen, was wir oben gelesen haben: Der Data Lake enthält Rohdaten, deren Zweck nicht definiert ist. Im Gegensatz dazu enthält ein Data Warehouse Daten, die für die Analyse bereit sind und bereits in ihrer besten Form vorliegen.

Einige Unterschiede zwischen einem Data Lake und einem Data Warehouse sind:
| Data Lake | Data Warehouse |
| Rohdaten oder verarbeitete Daten in beliebigem Format werden aus verschiedenen Quellen aufgenommen | Die Daten werden aus verschiedenen Quellen für Analysen und Berichte bezogen. Sie sind strukturiert |
| Das Schema wird bei Bedarf im laufenden Betrieb erstellt (Schema-on-read) | Vordefiniertes Schema beim Schreiben in das Warehouse (Schema-on-write) |
| Neue Daten können leicht hinzugefügt werden | Die Daten sind nach der Verarbeitung fertig, so dass jede neue Änderung mehr Zeit und Aufwand erfordert. |
| Daten müssen aktualisiert und verwaltet werden, um relevant zu sein | Die Daten sind bereits in ihrer besten Form vorhanden, so dass sie keine besondere Pflege benötigen |
| Sie bestehen aus riesigen Mengen an Big Data (Petabytes) | Die Datenmenge ist in der Regel geringer als die im Data Lake (Terabytes). Das Data Warehouse kann operative Daten eines gesamten Unternehmens, analytische Daten oder Daten, die für einen bestimmten Bereich relevant sind, enthalten |
| Wird von Datenwissenschaftlern für verschiedene Zwecke wie Streaming-Analysen, künstliche Intelligenz, prädiktive Analysen und viele andere Anwendungsfälle verwendet. | Von Geschäftsanalysten für die Transaktionsverarbeitung (OLTP), operative Analysen (OLAP), Berichte und die Erstellung von Visualisierungen |
| Daten können über einen längeren Zeitraum gespeichert und archiviert werden, um jederzeit analysiert werden zu können. | Die Daten müssen häufig bereinigt werden, um die neuesten Daten aufzunehmen |
| Die Speicherung ist kostengünstig. | Speicherung und Verarbeitung sind teuer und zeitaufwändig, daher sollten sie mit Bedacht geplant werden. |
| Datenwissenschaftler können neue Probleme und Lösungen entwickeln, indem sie sich die Daten ansehen. | Der Umfang der Daten ist auf ein bestimmtes Geschäftsproblem beschränkt. |
| Da Daten nicht auf eine bestimmte Art und Weise organisiert sind, können sowohl relationale als auch nicht-relationale Datenbanken zum Speichern von Daten verwendet werden. | Data Warehouses verwenden in der Regel relationale Datenbanken, weil die Daten in einem bestimmten Format vorliegen müssen. |
Anwendungsfälle für Data Lake und Data Warehouse
Es ist einfach, sich einen Data Lake als die bequemere Wahl vorzustellen, weil er skalierbarer, flexibler und preisgünstiger ist. Ein Data Warehouse kann jedoch eine gute Idee sein, wenn Sie relevantere und strukturiertere Daten für spezifische Analysen benötigen.
Einige Anwendungsfälle für Data Lake sind die folgenden:
#1. Lieferkette und Management
Die enorme Menge an Big Data in Data Lakes hilft bei prädiktiven Analysen für Transport und Logistik. Anhand historischer und aktueller Daten können Unternehmen ihre täglichen Abläufe reibungslos planen, Lagerbewegungen in Echtzeit überprüfen und Kosten optimieren.
#2. Gesundheitswesen
Der Datensee enthält alle früheren und aktuellen Informationen über Patienten. Dies ist hilfreich für die Forschung, das Auffinden von Mustern, die bessere und frühzeitige Behandlung von Krankheiten, die Automatisierung von Diagnosen und die Erfassung der aktuellsten Details über den Gesundheitszustand eines Patienten.
#3. Streaming-Daten und IoT
Data Lakes können kontinuierlich Streaming-Daten empfangen, die an Analysepipelines weitergeleitet werden, um kontinuierlich Berichte zu erstellen und ungewöhnliche Aktivitäten und Bewegungen zu erkennen. Möglich wird dies durch die Fähigkeit des Data Lakes, Daten (fast) in Echtzeit zu sammeln.
Einige Anwendungsfälle für Data Warehouses sind:
#1. Finanzen
Die Finanzinformationen eines Unternehmens eignen sich möglicherweise besser für ein Data Warehouse. Die Mitarbeiter können leicht auf organisierte und strukturierte Informationen in Form von Diagrammen und Berichten zugreifen, um die Finanzprozesse zu verwalten, Risiken zu bewältigen und strategische Entscheidungen zu treffen.
#2. Marketing und Kundensegmentierung
Data Warehouse schafft eine einzige Quelle der ‘Wahrheit’ oder korrekte Daten über Kunden, die aus verschiedenen Quellen gesammelt werden. Unternehmen können diese Daten analysieren, um das Kundenverhalten zu verstehen, maßgeschneiderte Rabatte anzubieten, Kunden anhand ihrer Vorlieben zu segmentieren und mehr Leads zu generieren.
#3. Unternehmens-Dashboards und Berichte
Viele Unternehmen nutzen CRM- und ERP-Data Warehouses, um Daten über externe und interne Kunden zu sammeln. Die Daten sind immer relevant und können für die Erstellung aller Arten von Berichten und Visualisierungen herangezogen werden.
#4. Daten aus Altsystemen migrieren
Mithilfe der ETL-Funktionen von Data Warehouses können Unternehmen Daten aus Altsystemen problemlos in ein besser nutzbares Format umwandeln, das von neuen Systemen analysiert werden kann. Dies hilft Unternehmen, Einblicke in historische Trends zu gewinnen und genaue Geschäftsentscheidungen zu treffen.
Beispiele für Data Lake-Tools
Einige Top Data Lake-Anbieter sind:
- Microsoft Azure – Azure kann Petabytes an Daten speichern und analysieren. Azure erleichtert das Debugging und die Optimierung von Big Data-Programmen.
- Google Cloud – Google Cloud bietet kosteneffiziente Aufnahme, Speicherung und Analyse riesiger Mengen von Big Data jeder Art. Sie lässt sich auch mit Analysetools wie Apache Spark, BigQuery und anderen Analysebeschleunigern integrieren.
- MongoDB Atlas – Atlas Data Lake ist ein vollständig verwalteter Data Lake-Speicher. Er bietet kosteneffiziente Möglichkeiten zur Speicherung großer Datenmengen und kann hochleistungsfähige Abfragen ausführen, die weniger Rechenleistung benötigen und somit Zeit und Kosten sparen.
- Amazon S3 – Die AWS-Cloud bietet die notwendigen Tools für den Aufbau eines flexiblen, sicheren und kostengünstigen Data Lakes. Es verfügt über eine interaktive Konsole zur Verwaltung der Data Lake-Benutzer und zur Kontrolle des Benutzerzugriffs.
Beispiele für Data Warehouse-Tools
Einige der führenden Anbieter von Data Warehouse-Lösungen sind:
- SAP – Mit SAP Data Warehouse können Benutzer semantisch auf umfangreiche Daten aus verschiedenen Quellen zugreifen. Unternehmen können auf sichere Weise Erkenntnisse und Modelle gemeinsam nutzen, die Entscheidungsfindung beschleunigen und externe und interne Daten sicher kombinieren.
- ClicData – Das intelligente und integrierte Data Warehouse von ClicData gewährleistet Datenintegrität, Qualität und einfache Berichterstattung. ClicData bietet sowohl Terminierungssysteme als auch Echtzeit-APIs, so dass Sie jederzeit aktuelle Daten erhalten können.
- Amazon Redshift – Als eines der am weitesten verbreiteten Data Warehouses nutzt Redshift SQL, um alle Arten von Daten zu analysieren, die in verschiedenen Datenbanken, Seen oder anderen Warehouses vorhanden sind. Es bietet ein hervorragendes Gleichgewicht zwischen Kosten und Leistung.
- IBM Db2 warehouse – IBM bietet Inhouse-, Cloud- und integrierte Data-Warehousing-Lösungen. Es integriert auch Tools für maschinelles Lernen und künstliche Intelligenz zur tieferen Datenanalyse und nutzt eine gemeinsame SQL-Engine zur Rationalisierung von Abfragen.
- Oracle Cloud Data Warehouse – Oracle verwendet eine In-Memory-Datenbank und bietet grafische, maschinelle Lern- und räumliche Funktionen, mit denen Sie tief in die Daten eintauchen können, um eine schnellere und umfassendere Datenanalyse durchzuführen.
Letzte Worte
Sowohl Data Lakes als auch Data Warehouses haben ihre eigenen Vorteile und idealen Anwendungsfälle. Während Data Lakes skalierbarer und flexibler sind, verfügen Data Warehouses immer über zuverlässige und strukturierte Informationen. Die Implementierung von Data Lakes ist relativ neu, während Data Warehouses ein etabliertes Konzept sind, das von vielen Unternehmen zur effizienten Verwaltung ihrer internen und externen Daten verwendet wird.