Hier erfahren Sie alles über Deepfakes und wie Sie sie mit Faceswap einfach erstellen können.
Bei Deepfakes werden künstliche Intelligenz und auf Deep Learning basierende Techniken eingesetzt, um Audio- oder Videoinhalte in einem Video durch Manipulation derselben zu verändern. Künstliche Intelligenz ist nicht mehr so ‘künstlich’. In der heutigen Zeit ist sie uns Menschen gefährlich nahe gekommen.
Sie kann Vorschläge machen, schreiben, Kunst schaffen und sieht jetzt aus und spricht wie ein Mensch.
Dies ist eine der jüngsten Entwicklungen in diesem Bereich, die wir uns zunutze machen sollten. Aber es ist auch eine, vor der wir uns in Acht nehmen müssen.
Was sind Deepfakes?
Das Wort Deepfake wurde durch die Kombination von Deep Learning und Fake geprägt. Einfach ausgedrückt, können Sie davon ausgehen, dass es sich um fachmännisch manipulierte oder gefälschte Medien handelt.
Laut Wikipedia ist dies auch als synthetische Medien bekannt, bei denen ein bestehendes Bild, Audio oder Video so verändert wird, dass es eine völlig andere Person darstellt.
Typischerweise lassen Deepfakes bekannte Persönlichkeiten etwas sagen, was sie sonst nicht sagen würden.
Je nach den Fähigkeiten des Urhebers kann es extrem schwierig sein, zu erkennen, ob es sich um eine echte oder eine gefälschte Version handelt.
Wie funktionieren Deepfakes?
Vereinfacht gesagt, wird ein Teil des Originalvideos (z. B. ein Gesicht) durch eine ähnlich aussehende Fälschung ersetzt. In einem solchen Fall kann man auch von einem Faceswap sprechen, wie in diesem Deepfake ‘Obama’ Video.
Es ist jedoch nicht nur auf Videos beschränkt, sondern es gibt auch Deepfakes von Bildern und Audio (und wer weiß, in naher Zukunft auch von VR-Avataren).

Die Arbeitsmethodik hinter solchen Tricksereien hängt in erster Linie von der Anwendung und dem zugrunde liegenden Algorithmus ab.
Laut diesem Forschungspapier von Disney gibt es verschiedene Techniken, darunter Encoder/Decoder, Generative Adversarial Networks (GANs), Geometrie-basierte Deepfakes usw.
In den folgenden Abschnitten geht es jedoch vor allem darum, wie es mit Facewap funktioniert. Dies ist eine kostenlose und quelloffene Deepfake-Software, die mehrere Algorithmen zulässt, um das erwartete Ergebnis zu erzielen.
Es gibt drei Hauptprozesse zur Erzeugung von Deepfakes: Extraktion, Training und Konvertierung.
#1. Extraktion
Hier geht es um die Erkennung und das Herausfiltern des interessierenden Themenbereichs aus den Medienproben, dem Original und dem für den Tausch bestimmten.
Je nach den Möglichkeiten der Hardware gibt es viele Algorithmen, die für eine effiziente Erkennung eingesetzt werden können.
Faceswap bietet beispielsweise verschiedene Optionen für die Extraktion, die Ausrichtung und die Maskierung, je nach CPU- oder GPU-Effizienz.
Die Extraktion identifiziert einfach das Gesicht im gesamten Video. Bei der Ausrichtung werden wichtige Merkmale eines jeden Gesichts (Augen, Nase, Kinn usw.) erkannt. Und schließlich werden durch die Maskierung andere Elemente des Bildes mit Ausnahme des interessierenden Bereichs ausgeblendet.
Die Gesamtzeit, die für die Ausgabe benötigt wird, ist bei der Auswahl einer Option wichtig, da die Wahl von ressourcenintensiven Algorithmen auf mittelmäßiger Hardware zu Fehlern führen kann oder es sehr lange dauert, bis akzeptable Ergebnisse geliefert werden.
Neben der Hardware hängt die Wahl auch von Parametern ab, wie z.B. davon, ob das Eingabevideo durch Gesichtsbehinderungen wie Handbewegungen oder Brillen beeinträchtigt wird.
Ein notwendiges Element ist schließlich die Reinigung (wird später erklärt) der Ausgabe, da die Extraktionen einige falsch-positive Ergebnisse aufweisen werden.
Letztendlich wird die Extraktion für das Originalvideo und das gefälschte Video (das für den Austausch verwendet wird) wiederholt.
#2. Training
Dies ist das Herzstück der Erstellung von Deepfakes.
Beim Training geht es um das neuronale Netzwerk, das aus dem Encoder und dem Decoder besteht. Hier werden die Algorithmen mit den extrahierten Daten gefüttert, um ein Modell für die spätere Umwandlung zu erstellen.
Der Encoder wandelt die Eingaben in eine Vektordarstellung um, um den Algorithmus darauf zu trainieren, die Gesichter wieder aus Vektoren zu erstellen, wie es der Decoder tut.
Anschließend wertet das neuronale Netzwerk seine Iterationen aus und vergleicht sie mit dem Original, indem es einen Verlustwert zuweist. Dieser Verlustwert sinkt im Laufe der Zeit, wenn der Algorithmus weiter iteriert, und Sie hören auf, wenn die Vorschauen akzeptabel sind.
Das Training ist ein zeitaufwändiger Prozess, und die Ergebnisse verbessern sich im Allgemeinen je nach den durchgeführten Iterationen und der Qualität der Eingabedaten.
Faceawap schlägt beispielsweise ein Minimum von jeweils 500 Bildern vor, sowohl für das Original als auch für die Vertauschung. Außerdem sollten sich die Bilder untereinander deutlich unterscheiden und alle möglichen Winkel bei einzigartiger Beleuchtung abdecken, um eine optimale Wiedergabe zu gewährleisten.
Je nach Länge des Trainings erlauben einige Anwendungen (wie Faceswap), das Training auf halbem Wege zu stoppen oder später fortzusetzen.
Der Fotorealismus der Ausgabe hängt natürlich auch von der Effizienz des Algorithmus und der Eingabe ab. Und auch hier ist man wieder durch die Hardware-Fähigkeiten eingeschränkt.
#3. Konvertierung
Dies ist das letzte Kapitel bei der Deepfake-Erstellung. Die Konvertierungsalgorithmen benötigen das Quellvideo, das trainierte Modell und die Quellausrichtungsdatei.
Anschließend können Sie einige Optionen für die Farbkorrektur, den Maskentyp, das gewünschte Ausgabeformat usw. ändern.
Nachdem Sie diese Optionen konfiguriert haben, müssen Sie nur noch auf das endgültige Rendering warten.
Wie bereits erwähnt, arbeitet Faceswap mit vielen Algorithmen, zwischen denen Sie hin- und herspielen können, um einen akzeptablen Faceswap zu erhalten.
Ist das alles?
Nein!
Das war nur das Face Swapping, eine Untergruppe der Deepfake-Technologie. Beim Gesichtstausch wird, wie bei der wörtlichen Bedeutung, nur ein Teil des Gesichts ersetzt, um eine schwache Vorstellung davon zu vermitteln, was Deepfakes leisten können.
Für einen glaubwürdigen Austausch müssen Sie möglicherweise auch den Ton (besser bekannt als Stimmenklonen) und den gesamten Körperbau imitieren, einschließlich allem, was in den Rahmen passt, wie dieses Deepfake-Video von Morgan Freeman.
Also, was ist hier im Spiel?
Es könnte sein, dass der Autor des Deepfake-Videos das Video selbst aufgenommen hat (wie in den letzten Sekunden angedeutet), den Dialog mit Morgan Freemans synthetischer Stimme lippensynchronisiert und seinen Kopf ersetzt hat.

Es handelt sich also nicht nur um einen Faceswap, sondern um das gesamte Bild, einschließlich des Tons.
Auf YouTube finden Sie tonnenweise Fälschungen, so dass es beängstigend ist, worauf man vertrauen kann. Und alles, was Sie brauchen, ist ein leistungsstarker Computer mit einer effizienten Grafikkarte, um loszulegen.
Perfektion ist jedoch schwer zu erreichen, und das gilt besonders für Deepfakes.
Für einen überzeugenden Deepfake, der das Publikum in die Irre führen oder begeistern kann, braucht es Geschick und ein paar Tage bis Wochen der Bearbeitung für ein oder zwei Minuten eines Videos, auch wenn Tools der künstlichen Intelligenz, die Gesichter austauschen, diese Aufgabe erleichtern.
Interessanterweise sind diese Algorithmen im Moment so leistungsfähig. Aber was die Zukunft bringt, einschließlich der Frage, wie effektiv diese Anwendungen auf weniger leistungsfähiger Hardware sein können, ist etwas, das ganze Regierungen nervös gemacht hat.
Wir werden uns jedoch nicht mit den zukünftigen Auswirkungen befassen. Sehen wir uns stattdessen an, wie Sie es selbst tun können, um ein wenig Spaß zu haben.
Erstellen von (einfachen) Deepfake-Videos
Es gibt viele Anwendungen, mit denen Sie Deepfake-Videos erstellen können. Eines davon ist Faceswap, das wir verwenden werden.
Bevor wir fortfahren, müssen wir ein paar Dinge sicherstellen. Zunächst sollten wir ein Video der Zielperson in guter Qualität haben, das verschiedene Emotionen zeigt. Als nächstes benötigen wir ein Quellvideo, das wir auf das Ziel übertragen können.
Außerdem sollten Sie alle grafikkartenintensiven Anwendungen wie Browser oder Spiele schließen, bevor Sie mit Faceswap fortfahren. Dies gilt insbesondere, wenn Sie weniger als 2 Gigabyte VRAM (Video-RAM) haben.
Schritt 1: Gesichter extrahieren
Der erste Schritt in diesem Prozess ist das Extrahieren der Gesichter aus dem Video. Dazu müssen wir das Zielvideo im Eingabeverzeichnis auswählen und ein Ausgabeverzeichnis für die Extraktionen angeben.
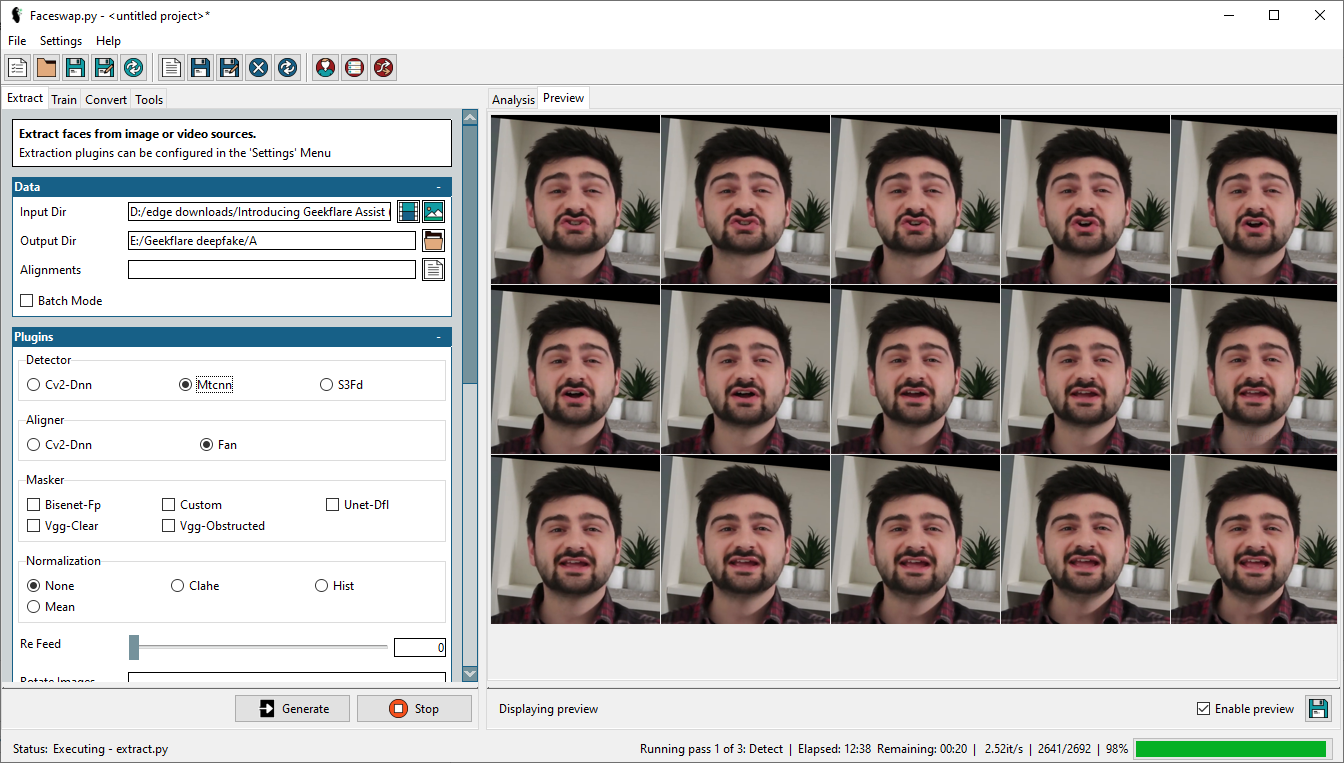
Außerdem gibt es einige Optionen, darunter Detektor, Aligner, Masker usw. Die Erklärungen zu den einzelnen Optionen finden Sie in den Faceawap-FAQs, und es wäre Zeitverschwendung, die Informationen hier wiederzugeben.
Es ist generell gut, die Dokumentation zu lesen, um ein besseres Verständnis und eine anständige Ausgabe zu erhalten. Es gibt jedoch auch hilfreiche Texte in Faceswap, die Sie finden können, wenn Sie mit dem Mauszeiger über eine bestimmte Option fahren.
Einfach ausgedrückt: Es gibt keinen universellen Weg, und man sollte mit den besten Algorithmen beginnen und sich erfolgreich nach unten durcharbeiten, um ein überzeugendes Deepfake zu erstellen.
Für den Kontext habe ich Mtcnn (Detektor), Fan (Aligner) und Bisenet-Fp (Masker) verwendet, während ich alle anderen Optionen unverändert gelassen habe.
Ursprünglich hatte ich es mit S3Fd (bester Detektor) und ein paar anderen Masken kombiniert versucht. Aber meine 2Gb Nvidia GeForce GTX 750Ti war der Belastung nicht gewachsen, und der Prozess schlug wiederholt fehl.
Schließlich dämpfte ich meine Erwartungen und die Einstellungen, um es durchzuziehen.
Neben der Auswahl des geeigneten Detektors, Maskierers usw. gibt es unter Einstellungen > Einstellungen konfigurieren noch ein paar weitere Optionen, mit denen Sie die einzelnen Einstellungen weiter optimieren können, um der Hardware zu helfen.
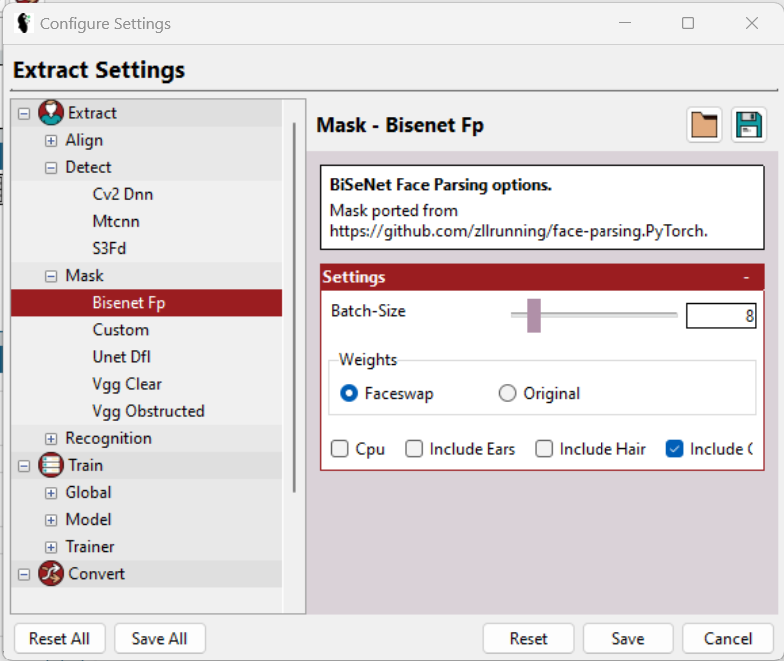
Einfach ausgedrückt: Wählen Sie die niedrigstmögliche Stapelgröße, Eingabegröße und Ausgabegröße und aktivieren Sie LowMem usw. Diese Optionen sind nicht universell verfügbar, sondern beziehen sich auf einen bestimmten Abschnitt. Außerdem helfen Ihnen die Hilfetexte bei der Auswahl der besten Optionen weiter.
Obwohl dieses Tool beim Extrahieren von Gesichtern hervorragende Arbeit leistet, können die ausgegebenen Bilder viel mehr enthalten, als zum Trainieren des Modells erforderlich ist (dazu später). Zum Beispiel enthält es alle Gesichter (wenn das Video mehr als eines hat) und einige falsche Erkennungen, die das Zielgesicht gar nicht enthalten.
Dies führt zu einer Bereinigung der Datensätze. Sie können entweder den Ausgabeordner überprüfen und sich selbst löschen oder die Faceswap-Sortierung verwenden, um Hilfe zu erhalten.
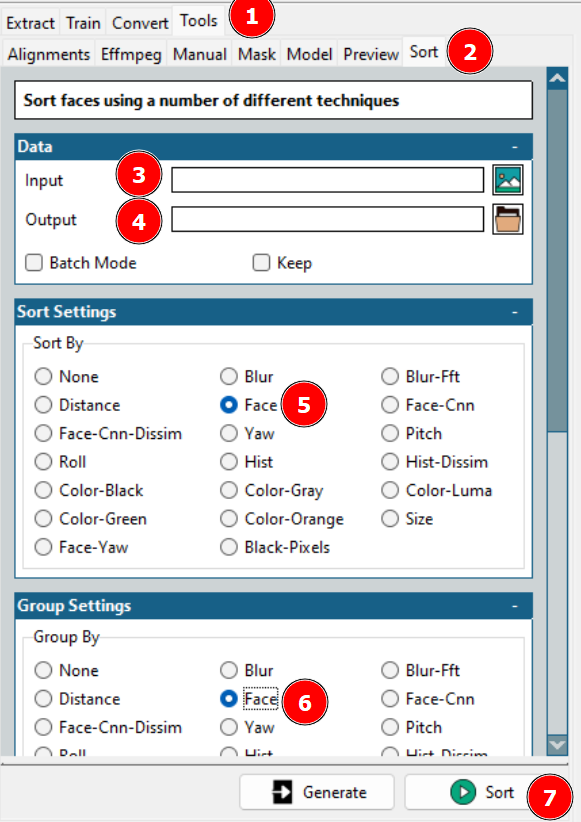
Mit dem oben erwähnten Tool werden die verschiedenen Gesichter in eine Reihenfolge gebracht, aus der Sie die benötigten in einem einzigen Ordner zusammenfassen und den Rest löschen können.
Zur Erinnerung: Sie sollten die Extraktion auch für das Video wiederholen, aus dem Sie stammen.
Schritt 2: Trainieren des Modells
Dies ist der längste Prozess bei der Erstellung eines Deepfakes. Hier bezieht sich Eingabe A auf das Zielgesicht und Eingabe B auf das Quellgesicht. Außerdem werden die Trainingsdateien im Model Dir gespeichert.
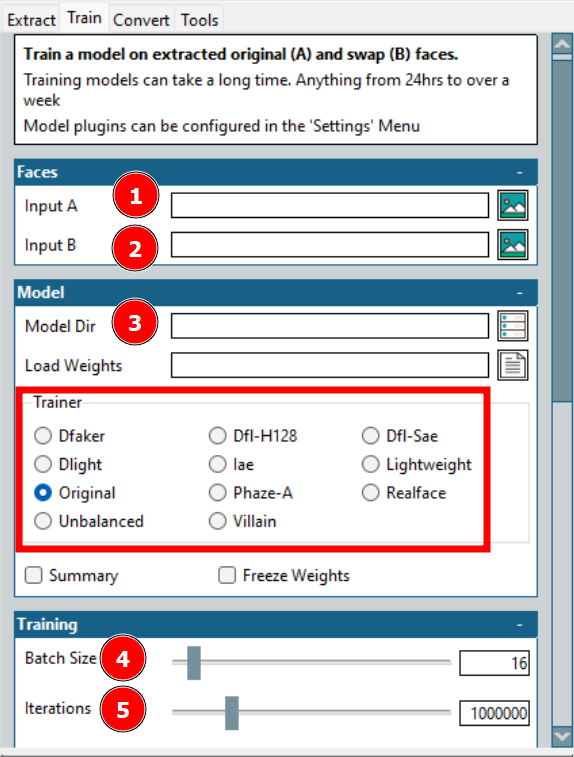
Die wichtigste Option ist hier Trainer. Es gibt viele mit individuellen Skalierungsoptionen; was jedoch bei meiner Hardware funktioniert hat, sind Dfl-H128 und Lightweight Trainer mit den niedrigsten Konfigurationseinstellungen.
Die nächste Option ist die Stapelgröße. Eine höhere Stapelgröße verringert die Gesamttrainingszeit, verbraucht aber mehr VRAM. Iterationen haben keine feste Auswirkung auf das Ergebnis, und Sie sollten einen ausreichend hohen Wert einstellen und das Training beenden, sobald die Vorschauen akzeptabel sind.
Es gibt noch ein paar weitere Einstellungen, darunter die Erstellung eines Zeitraffers mit voreingestellten Intervallen; ich habe das Modell jedoch mit dem absoluten Minimum trainiert.
Schritt 3: Auf das Original umschalten
Dies ist der letzte Schritt bei der Erstellung eines Deepfakes.
Dies nimmt in der Regel nicht so viel Zeit in Anspruch, und Sie können mit vielen Optionen spielen, um schnell das gewünschte Ergebnis zu erzielen.
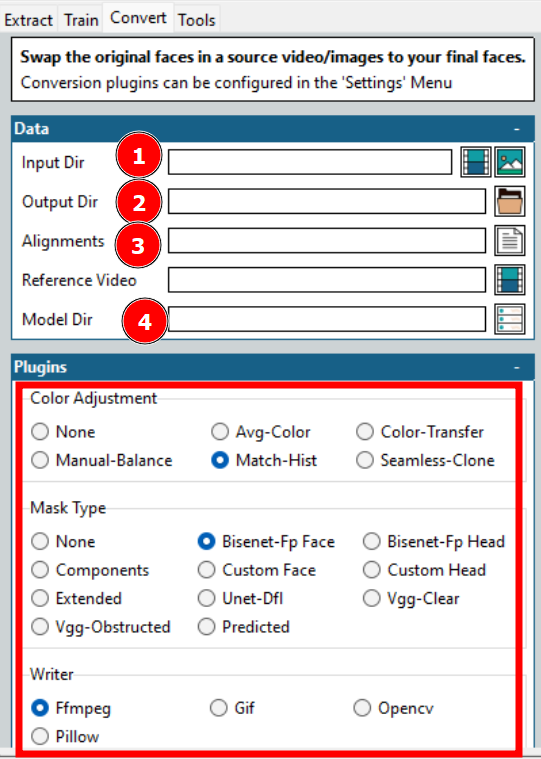
Wie in der obigen Abbildung angedeutet, sind dies einige Optionen, für die man sich entscheiden muss, um die Konvertierung zu starten.
Die meisten Optionen wurden bereits besprochen, wie das Eingabe- und Ausgabeverzeichnis, das Modellverzeichnis usw. Ein entscheidender Punkt sind die Ausrichtungen, die sich auf die Ausrichtungsdatei (.fsa) des Zielvideos beziehen. Sie wird während der Extraktion im Eingabeverzeichnis erstellt.
Das Feld Alignments kann leer gelassen werden, wenn die betreffende Datei nicht verschoben wurde. Andernfalls können Sie die Datei auswählen und mit den anderen Optionen fortfahren. Denken Sie jedoch daran, die Ausrichtungsdatei zu bereinigen, wenn Sie die Extraktionen zuvor bereinigt haben.
Dazu finden Sie dieses Mini-Tool unter Extras > Ausrichtungen.
Beginnen Sie mit der Auswahl von Remove-Faces im Bereich Job, wählen Sie die ursprüngliche Ausrichtungsdatei und den Ordner mit den bereinigten Zielflächen aus und klicken Sie unten rechts auf Alignments.
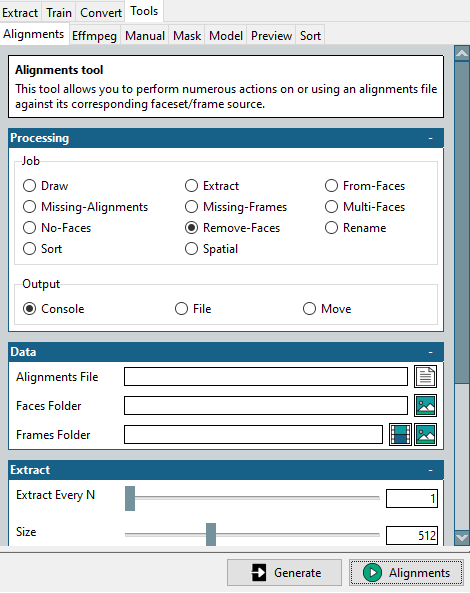
Dadurch wird eine geänderte Ausrichtungsdatei erstellt, die dem Ordner mit den optimierten Flächen entspricht. Bitte denken Sie daran, dass wir diese Datei für das Zielvideo benötigen, in das wir sie austauschen möchten.
Einige weitere Konfigurationen betreffen die Farbanpassung und den Maskentyp. Die Farbanpassung bestimmt die Überblendung der Maske, und Sie können einige ausprobieren, die Vorschau überprüfen und die optimale Option auswählen.
Der Maskentyp ist noch wichtiger. Auch hier hängt es von Ihren Erwartungen und der verfügbaren Hardware ab. In der Regel müssen Sie auch die Eigenschaften des Eingangsvideos berücksichtigen. Vgg-Clear funktioniert beispielsweise gut mit frontalen Gesichtern ohne Hindernisse, während Vgg-Obstructed auch mit Hindernissen wie Handgesten, Brillen usw. zurechtkommt.
Als Nächstes bietet Ihnen der Writer einige Auswahlmöglichkeiten für die von Ihnen gewünschte Ausgabe. Wählen Sie z.B. Ffmpeg für eine Videowiedergabe.
Insgesamt liegt der Schlüssel zu einem erfolgreichen Deepfake in der Vorschau einiger Ausgaben und in der Optimierung entsprechend der verfügbaren Zeit und der Leistungsfähigkeit der Hardware.
Anwendungen von Deepfake
Es gibt gute, schlechte und gefährliche Anwendungen von Deepfakes.
Die guten bestehen darin, den Geschichtsunterricht von denjenigen nachspielen zu lassen, die tatsächlich dabei waren, um das Engagement zu erhöhen.
Außerdem werden sie von Online-Lernplattformen genutzt, um Videos aus Texten zu erstellen.
Aber einer der größten Nutznießer wird die Filmindustrie sein. Hier wird es ein Leichtes sein, sich den Hauptdarsteller vorzustellen, der Stunts ausführt, selbst wenn der Stuntman sein Leben riskiert. Außerdem wird es einfacher denn je sein, mehrsprachige Filme zu drehen.
Was die schlechten Seiten angeht, so gibt es leider viele. Die bisher größte Deepfake-Anwendung, nämlich 96% (laut diesem Deeptrace-Bericht), findet in der Pornoindustrie statt, um Gesichter von Prominenten auf Pornodarsteller zu übertragen.
Darüber hinaus werden Deepfakes auch gegen “normale”, nicht prominente Frauen eingesetzt. In der Regel haben diese Opfer hochwertige Fotos oder Videos auf ihren Social Media-Profilen, die für Deepfakes-Betrügereien verwendet werden.
Eine weitere erschreckende Anwendung ist Vishing, auch bekannt als Voice Phishing. In einem solchen Fall überwies der CEO eines britischen Unternehmens 243.000 Dollar auf Anweisung des “CEO” seiner deutschen Muttergesellschaft, nur um später herauszufinden, dass es sich in Wirklichkeit um einen gefälschten Telefonanruf handelte.
Noch gefährlicher ist es jedoch, mit Deepfakes Kriege zu provozieren oder zur Kapitulation aufzufordern. Bei einem der jüngsten Versuche hat der ukrainische Präsident Volodymyr Zelenskyy seine Truppen und sein Volk aufgefordert, sich im laufenden Krieg zu ergeben. Allerdings wurde die Wahrheit dieses Mal durch das minderwertige Video verraten.
Daraus folgt, dass es viele Deepfake-Anwendungen gibt, und dass die Entwicklung gerade erst beginnt.
Das bringt uns zu der Millionen-Dollar-Frage…
Sind Deepfakes legal?
Das hängt in erster Linie von der lokalen Verwaltung ab. Genau definierte Gesetze, die festlegen, was erlaubt ist und was nicht, sind allerdings noch nicht in Sicht.
Klar ist jedoch, dass es darauf ankommt, wofür Sie die Deepfakes verwenden – nämlich für Ihre Absicht. Wenn Sie jemanden unterhalten oder unterrichten wollen, ohne das Tauschziel zu verärgern, ist das kaum ein Problem.
Andererseits sollten böswillige Anwendungen unabhängig von der Rechtsprechung strafbar sein. Eine weitere Grauzone ist die Verletzung des Urheberrechts, die angemessen berücksichtigt werden muss.
Aber um es noch einmal zu sagen: Sie sollten sich bei Ihren örtlichen Behörden über legale Deepfake-Anwendungen informieren.
Halten Sie die Augen offen!
Deepfkaes nutzt künstliche Intelligenz, um jemanden dazu zu bringen, etwas zu sagen.
Trauen Sie nichts, was Sie im Internet sehen, ist der erste Rat, den wir befolgen sollten. Es gibt tonnenweise Fehlinformationen, und ihre Wirksamkeit nimmt nur noch zu.