Lernen Sie die Grundlagen der Arbeit mit pandas DataFrames: die grundlegende Datenstruktur in pandas, einer leistungsstarken Bibliothek zur Datenmanipulation.
Wenn Sie mit der Datenanalyse in Python beginnen möchten, ist pandas eine der ersten Bibliotheken, mit der Sie arbeiten sollten. Vom Importieren von Daten aus verschiedenen Quellen wie CSV-Dateien und Datenbanken bis hin zum Umgang mit fehlenden Daten und deren Analyse, um Erkenntnisse zu gewinnen – mit pandas können Sie all das tun.
Um mit der Analyse von Daten mit Pandas zu beginnen, sollten Sie die grundlegende Datenstruktur in Pandas verstehen: Datenrahmen.
In diesem Lernprogramm lernen Sie die Grundlagen von Pandas Dataframes und gängige Methoden zur Erstellung von Dataframes kennen. Anschließend lernen Sie, wie Sie Zeilen und Spalten aus einem Datenrahmen auswählen, um Teilmengen von Daten abzurufen.
Für all dies und mehr, lassen Sie uns beginnen.
Installieren und Importieren von Pandas
Da Pandas eine Datenanalysebibliothek eines Drittanbieters ist, sollten Sie sie zunächst installieren. Es wird empfohlen, externe Pakete in einer virtuellen Umgebung für Ihr Projekt zu installieren.
Wenn Sie die Anaconda-Distribution von Python verwenden, können Sie conda für die Paketverwaltung nutzen.
conda installieren pandasSie können pandas auch mit pip installieren:
pip install pandasdie pandas Bibliothek benötigt NumPy als Abhängigkeit. Wenn NumPy also nicht bereits installiert ist, wird es während des Installationsvorgangs ebenfalls installiert.
Nachdem Sie pandas installiert haben, können Sie es in Ihre Arbeitsumgebung importieren. Im Allgemeinen wird pandas unter dem Alias pd importiert:
import pandas as pdWas ist ein DataFrame in Pandas?

Die grundlegende Datenstruktur in Pandas ist der Datenrahmen. Ein Datenrahmen ist ein zweidimensionales Array von Daten mit einem beschrifteten Index und benannten Spalten. Jede Spalte des Datenrahmens, eine so genannte Pandas-Serie, hat einen gemeinsamen Index.
Hier ist ein Beispiel für einen Datenrahmen, den wir in den nächsten Minuten von Grund auf neu erstellen werden. Dieser Datenrahmen enthält Daten darüber, wie viel sechs Studenten in vier Wochen ausgeben.

Die Namen der Studenten sind die Zeilenbeschriftungen. Und die Spalten heißen ‘Woche1’ bis ‘Woche4’. Beachten Sie, dass alle Spalten denselben Satz von Zeilenbeschriftungen, auch Index genannt, haben.
Wie man einen Pandas DataFrame erstellt
Es gibt mehrere Möglichkeiten, einen Pandas DataFrame zu erstellen. In diesem Lernprogramm werden wir die folgenden Methoden besprechen:
- Erstellen eines Datenrahmens aus NumPy-Arrays
- Erstellen eines Datenrahmens aus einem Python-Wörterbuch
- Erstellen eines Datenrahmens durch Einlesen von CSV-Dateien
Aus NumPy-Arrays
Lassen Sie uns einen Datenrahmen aus einem NumPy-Array erstellen.
Erstellen wir ein Datenarray der Form (6,4) unter der Annahme, dass jeder Student in einer bestimmten Woche zwischen $0 und $100 ausgibt. Die Funktion randint() aus dem Modul random von NumPy liefert ein Array mit zufälligen ganzen Zahlen in einem bestimmten Intervall [low,high).
import numpy as np
np.random.seed(42)
daten = np.random.randint(0,101,(6,4))
print(daten)array([[51, 92, 14, 71],
[60, 20, 82, 86],
[74, 74, 87, 99],
[23, 2, 21, 52],
[ 1, 87, 29, 37],
[ 1, 63, 59, 20]])Um einen Pandas-Datenrahmen zu erstellen, können Sie den DataFrame-Konstruktor verwenden und das NumPy-Array als Datenargument übergeben, wie gezeigt:
students_df = pd.DataFrame(data=data)Jetzt können wir die integrierte Funktion type() aufrufen, um den Typ von students_df zu überprüfen. Wir sehen, dass es sich um ein DataFrame-Objekt handelt.
type(students_df)
# pandas.core.frame.DataFrameprint(schueler_df)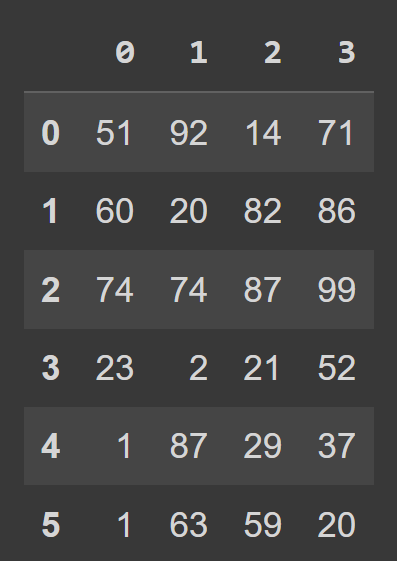
Wir sehen, dass wir standardmäßig eine Bereichsindizierung haben, die von 0 bis numRows – 1 reicht, und die Spaltenbeschriftungen lauten 0, 1, 2, …, numCols -1. Dies verringert jedoch die Lesbarkeit. Es ist hilfreich, dem Datenrahmen beschreibende Spaltennamen und Zeilenbeschriftungen hinzuzufügen.
Lassen Sie uns zwei Listen erstellen: eine für die Namen der Schüler und eine für die Spaltenbezeichnungen.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny']
cols = ['Woche1','Woche2','Woche3','Woche4']Wenn Sie den DataFrame-Konstruktor aufrufen, können Sie index und columns auf die zu verwendenden Listen der Zeilen- bzw. Spaltenbeschriftungen setzen.
students_df = pd.DataFrame(data = Daten,index = students,columns = cols)Wir haben nun den Datenrahmen students_df mit beschreibenden Zeilen- und Spaltenbeschriftungen.
print(schueler_df)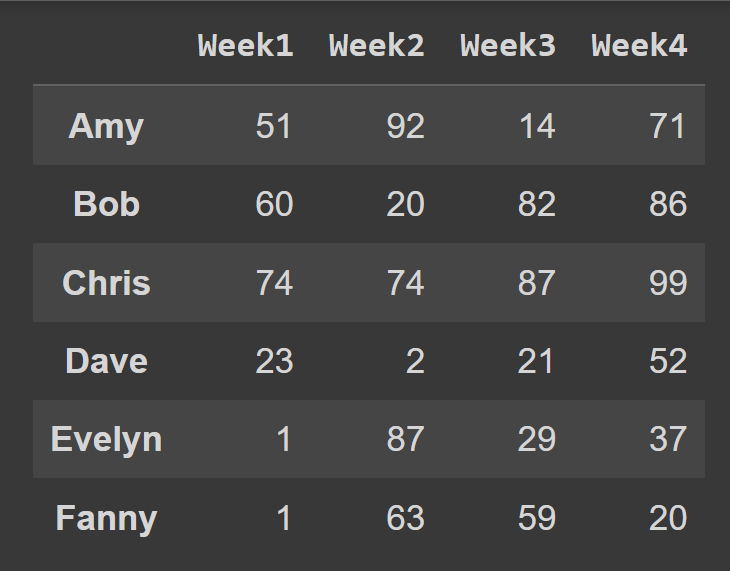
Um einige grundlegende Informationen über den Datenrahmen zu erhalten, wie z.B. fehlende Werte und Datentypen, können Sie die Methode info() für das Datenrahmenobjekt aufrufen.
students_df.info()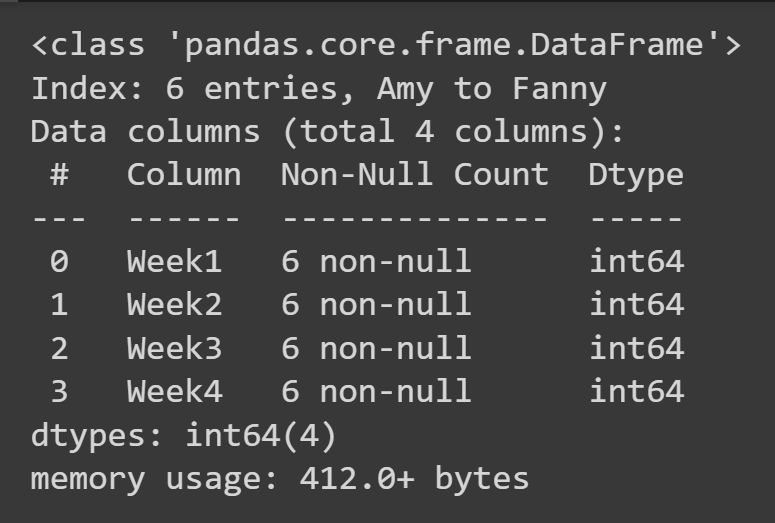
Aus einem Python-Wörterbuch
Sie können auch einen Pandas-Datenrahmen aus einem Python-Wörterbuch erstellen.
Hier ist data_dict das Wörterbuch mit den Studentendaten:
- Die Namen der Studenten sind die Schlüssel.
- Jeder Wert ist eine Liste der Ausgaben jedes Schülers für die Wochen eins bis vier.
data_dict = {}
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny']
for student,student_data in zip(students,data):
data_dict[student] = student_dataUm einen Datenrahmen aus einem Python-Wörterbuch zu erstellen, verwenden Sie from_dict, wie unten gezeigt. Das erste Argument entspricht dem Wörterbuch, das die Daten enthält(data_dict). Standardmäßig werden die Schlüssel als Spaltennamen des Datenrahmens verwendet. Da wir die Schlüssel als Zeilenbeschriftungen festlegen möchten, setzen Sie orient= 'index'.
students_df = pd.DataFrame.from_dict(data_dict,orient='index')
print(studenten_df)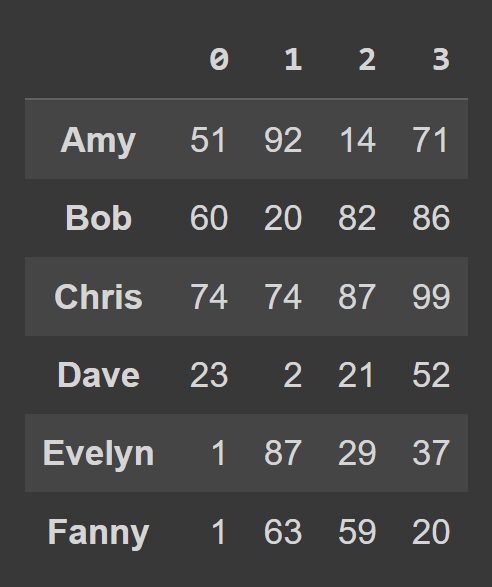
Um die Spaltennamen in die Wochennummer zu ändern, setzen wir columns auf die Liste cols:
students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols)
print(schueler_df)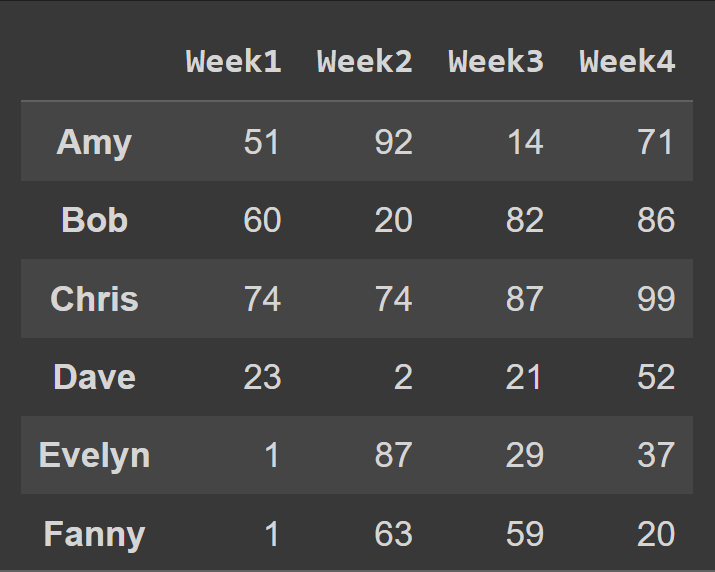
Einlesen einer CSV-Datei in ein Pandas DataFrame
Angenommen, die Schülerdaten liegen in einer CSV-Datei vor. Sie können die Funktion read_csv() verwenden, um die Daten aus der Datei in einen Pandas-Datenrahmen einzulesen. pd.read_csv('file-path') ist die allgemeine Syntax, wobei file-path der Pfad zur CSV-Datei ist. Wir können den Parameter names auf die Liste der zu verwendenden Spaltennamen setzen.
students_df = pd.read_csv('/Inhalt/Studenten.csv',names=cols)Da wir nun wissen, wie man einen Datenrahmen erstellt, wollen wir nun lernen, wie man Zeilen und Spalten auswählt.
Spalten aus einem Pandas DataFrame auswählen
Es gibt mehrere eingebaute Methoden, die Sie verwenden können, um Zeilen und Spalten aus einem Datenrahmen auszuwählen. In diesem Tutorial lernen Sie die gängigsten Methoden kennen, um Spalten, Zeilen oder sowohl Zeilen als auch Spalten aus einem Datenframe auszuwählen.
Auswählen einer einzelnen Spalte
Um eine einzelne Spalte auszuwählen, können Sie df_name<x>[spaltenname]</x> verwenden, wobei spaltenname die Zeichenfolge ist, die den Namen der Spalte angibt.
Hier wählen wir nur die Spalte ‘Woche1’ aus.
week1_df = students_df['Week1']
print(woche1_df)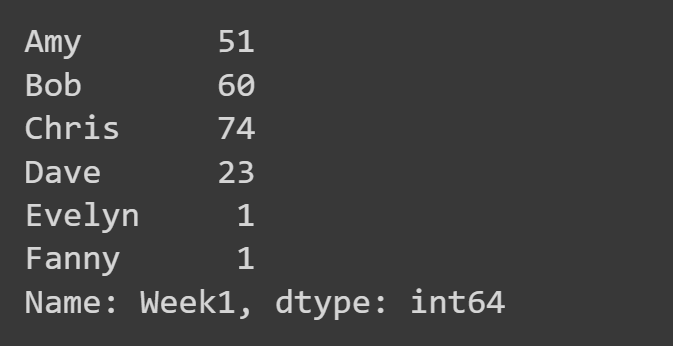
Auswählen mehrerer Spalten
Um mehrere Spalten aus dem Datenrahmen auszuwählen, geben Sie die Liste aller auszuwählenden Spaltennamen an.
ungerade_Wochen = students_df[['Woche1','Woche3']]
print(ungerade_Wochen)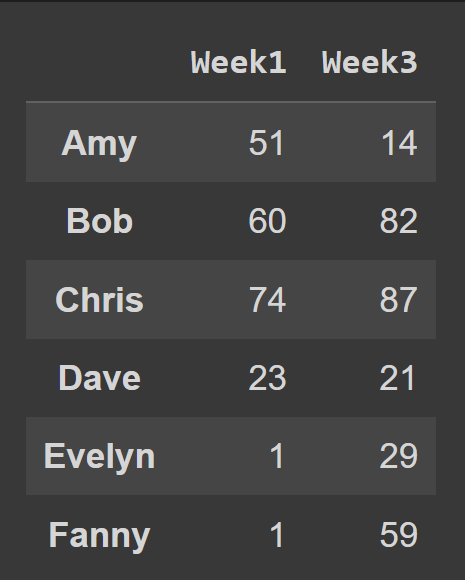
Zusätzlich zu dieser Methode können Sie auch die Methoden iloc() und loc() verwenden, um Spalten auszuwählen. Wir werden später ein Beispiel programmieren.
Zeilen aus einem Pandas DataFrame auswählen

Verwendung der Methode .iloc()
Um Zeilen mit der Methode iloc () auszuwählen, übergeben Sie die Indizes, die allen Zeilen entsprechen, in Form einer Liste.
In diesem Beispiel wählen wir die Zeilen mit ungeradem Index aus.
ungerade_index_rows = students_df.iloc[[1,3,5]]
print(ungerade_index_rows)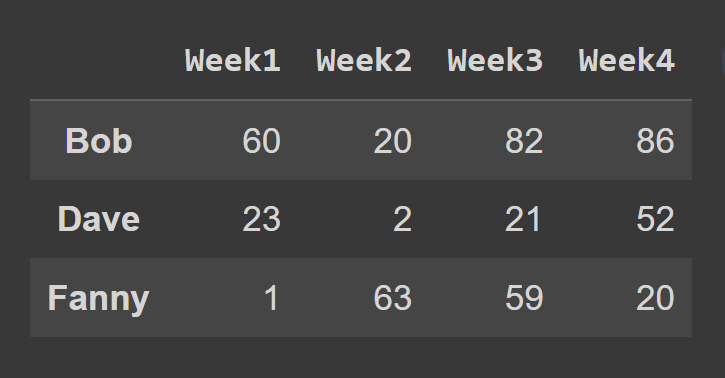
Als nächstes wählen wir eine Teilmenge des Datenrahmens aus, die die Zeilen mit den Indizes 0 bis 2 enthält. Der Endpunkt 3 ist standardmäßig ausgeschlossen.
slice1 = students_df.iloc[0:3]
print(slice1)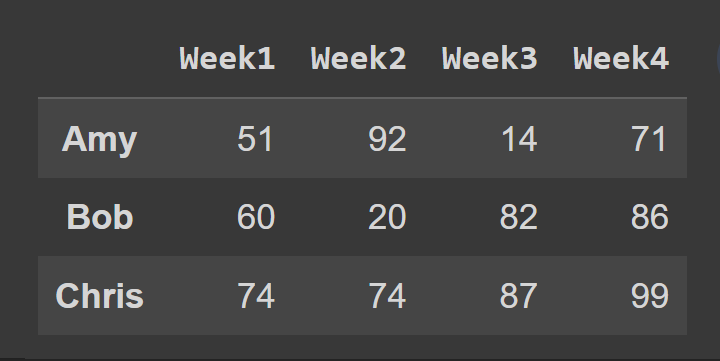
Verwendung der Methode .loc()
Um die Zeilen eines Datenrahmens mit der loc() -Methode auszuwählen, sollten Sie die Beschriftungen angeben, die den Zeilen entsprechen, die Sie auswählen möchten.
some_rows = students_df.loc[['Bob','Dave','Fanny']]
print(einige_zeilen)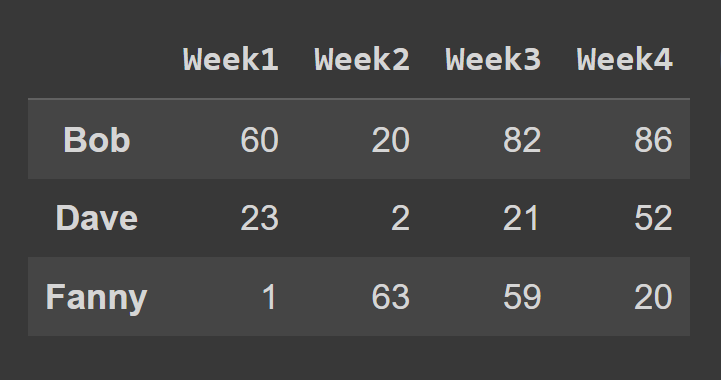
Wenn die Zeilen des Datenrahmens mit dem Standardbereich 0, 1, 2, bis zu
numRows-1 indiziert sind, sindiloc()undloc()gleichwertig.
Zeilen und Spalten aus einem Pandas DataFrame auswählen
Bisher haben Sie gelernt, wie Sie entweder Zeilen oder Spalten aus einem Pandas DataFrame auswählen können. Es kann jedoch vorkommen, dass Sie eine Teilmenge von sowohl Zeilen als auch Spalten auswählen müssen. Wie machen Sie das also? Sie können die Methoden iloc() und loc() verwenden, die wir bereits besprochen haben.
Im folgenden Codeschnipsel wählen wir zum Beispiel alle Zeilen und Spalten mit den Indizes 2 und 3 aus.
subset_df1 = students_df.iloc[:,[2,3]]
print(teilmenge_df1)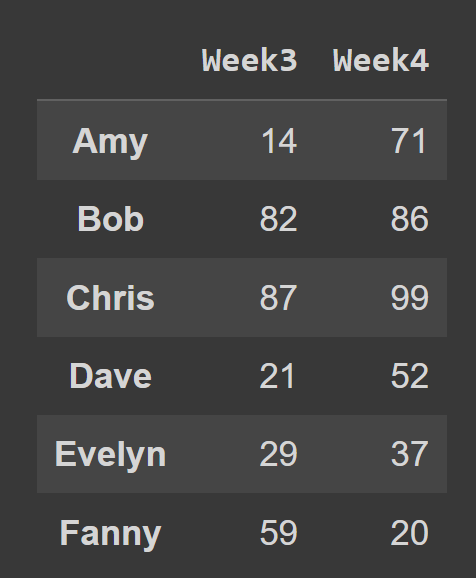
Die Verwendung von start:stop erzeugt einen Ausschnitt von start bis einschließlich stop. Wenn Sie also sowohl die start- als auch die stop-Werte ignorieren, beginnt der Ausschnitt am Anfang und erstreckt sich bis zum Ende des Datenrahmens, wobei alle Zeilen ausgewählt werden.
Wenn Sie die loc() -Methode verwenden, müssen Sie die Beschriftungen der Zeilen und Spalten übergeben, die Sie auswählen möchten, wie in der Abbildung gezeigt:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']]
print(teilmenge_df2)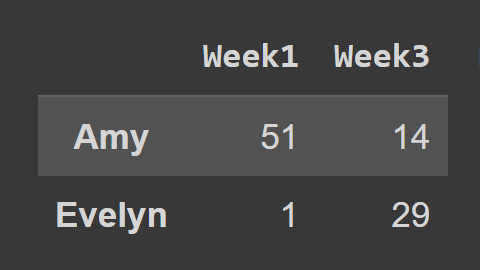
Hier enthält der Datenrahmen subset_df2 die Datensätze von Amy und Evelyn für Woche1 und Woche3.
Fazit
Hier ist ein kurzer Überblick über das, was Sie in diesem Tutorial gelernt haben:
- Nachdem Sie Pandas installiert haben, können Sie es unter dem Alias
pdimportieren. Um ein Pandas-Datenrahmenobjekt zu erstellen, können Sie den Konstruktorpd.DataFrame(data)verwenden, wobeidataauf das N-dimensionale Array oder eine Iterable verweist, die die Daten enthält. Sie können die Zeilen- und Index- sowie die Spaltenbeschriftungen angeben, indem Sie die optionalen Parameter index bzw. columns setzen. - Mit
pd.read_csv(pfad-zur-datei)lesen Sie den Inhalt der Datei in einen Datenrahmen. - Sie können die Methode
info()für das Datenrahmenobjekt aufrufen, um Informationen über die Spalten, die Anzahl der fehlenden Werte, die Datentypen und die Größe des Datenrahmens zu erhalten. - Um eine einzelne Spalte auszuwählen, verwenden Sie
df_name<x>[col_name]</x>, und um mehrere Spalten auszuwählen, particular column,df_name[[col1,col2,...,coln]]. - Sie können Spalten und Zeilen auch mit den Methoden
loc()undiloc()auswählen. - Während die Methode
iloc()den Index (oder die Indexscheibe) der auszuwählenden Zeilen und Spalten aufnimmt, nimmt die Methodeloc()die Zeilen- und Spaltenbezeichnungen auf.
Die in diesem Lernprogramm verwendeten Beispiele finden Sie in diesem Colab-Notizbuch.
Als nächstes sehen Sie sich diese Liste mit kollaborativen Data Science Notebooks an.