
Stellen Sie sich vor, Sie haben eine große Infrastruktur mit verschiedenen Arten von Geräten, die Sie regelmäßig warten oder sicherstellen müssen, dass sie keine Gefahr für die Umgebung darstellen.
Eine Möglichkeit, dies zu erreichen, besteht darin, regelmäßig Leute an jeden Ort zu schicken, um zu überprüfen, ob alles in Ordnung ist. Das ist irgendwie machbar, aber auch ziemlich zeit- und ressourcenaufwendig. Und wenn die Infrastruktur groß genug ist, können Sie sie möglicherweise nicht innerhalb eines Jahres vollständig abdecken.
Eine andere Möglichkeit ist, diesen Prozess zu automatisieren und die Jobs in der Cloud für Sie überprüfen zu lassen. Dazu müssen Sie Folgendes tun:
👉 Ein schneller Prozess, wie Sie Bilder der Geräte erhalten. Dies kann immer noch von Personen durchgeführt werden, da es immer noch viel schneller ist, nur ein Bild zu machen, als alle Geräteverifizierungsprozesse durchzuführen. Es kann aber auch durch Fotos aus Autos oder sogar Drohnen erfolgen. In diesem Fall wird es ein viel schnellerer und automatisierter Prozess der Bilderfassung.
👉 Dann müssen Sie alle gesammelten Bilder an einen speziellen Ort in der Cloud senden.
👉 In der Cloud benötigen Sie einen automatisierten Job, der die Bilder aufnimmt und sie mit Hilfe von Machine-Learning-Modellen verarbeitet, die darauf trainiert sind, Geräteschäden oder Anomalien zu erkennen.
👉 Schließlich müssen die Ergebnisse für die gewünschten Benutzer sichtbar sein, damit die Reparatur von Geräten mit Problemen geplant werden kann.
Schauen wir uns an, wie wir die Erkennung von Anomalien anhand der Bilder in der AWS-Cloud erreichen können. Amazon hat einige vorgefertigte Machine-Learning-Modelle, die wir zu diesem Zweck verwenden können.
So erstellen Sie ein Modell für die Erkennung visueller Anomalien
Um ein Modell für die Erkennung visueller Anomalien zu erstellen, müssen Sie mehrere Schritte befolgen:
Schritt 1: Definieren Sie klar das Problem, das Sie lösen möchten, und die Arten von Anomalien, die Sie erkennen möchten. Dies wird Ihnen helfen, den geeigneten Testdatensatz zu bestimmen, den Sie zum Trainieren des Modells benötigen.
Schritt 2 : Sammeln Sie einen großen Datensatz von Bildern, die normale und anomale Bedingungen repräsentieren. Beschriften Sie die Bilder, um anzugeben, welche Bilder normal sind und welche Anomalien enthalten.
Schritt 3 : Wählen Sie eine Modellarchitektur, die für die Aufgabe geeignet ist. Dies kann bedeuten, dass Sie ein bereits trainiertes Modell auswählen und es für Ihren speziellen Anwendungsfall feinabstimmen oder ein eigenes Modell von Grund auf erstellen.
Schritt 4: Trainieren Sie das Modell mit dem vorbereiteten Datensatz und dem ausgewählten Algorithmus. Dies bedeutet, dass Sie Transfer Learning einsetzen, um bereits trainierte Modelle zu nutzen, oder das Modell mit Techniken wie Faltungsneuronalen Netzen (CNNs) von Grund auf trainieren.
Wie man ein Modell für maschinelles Lernen trainiert
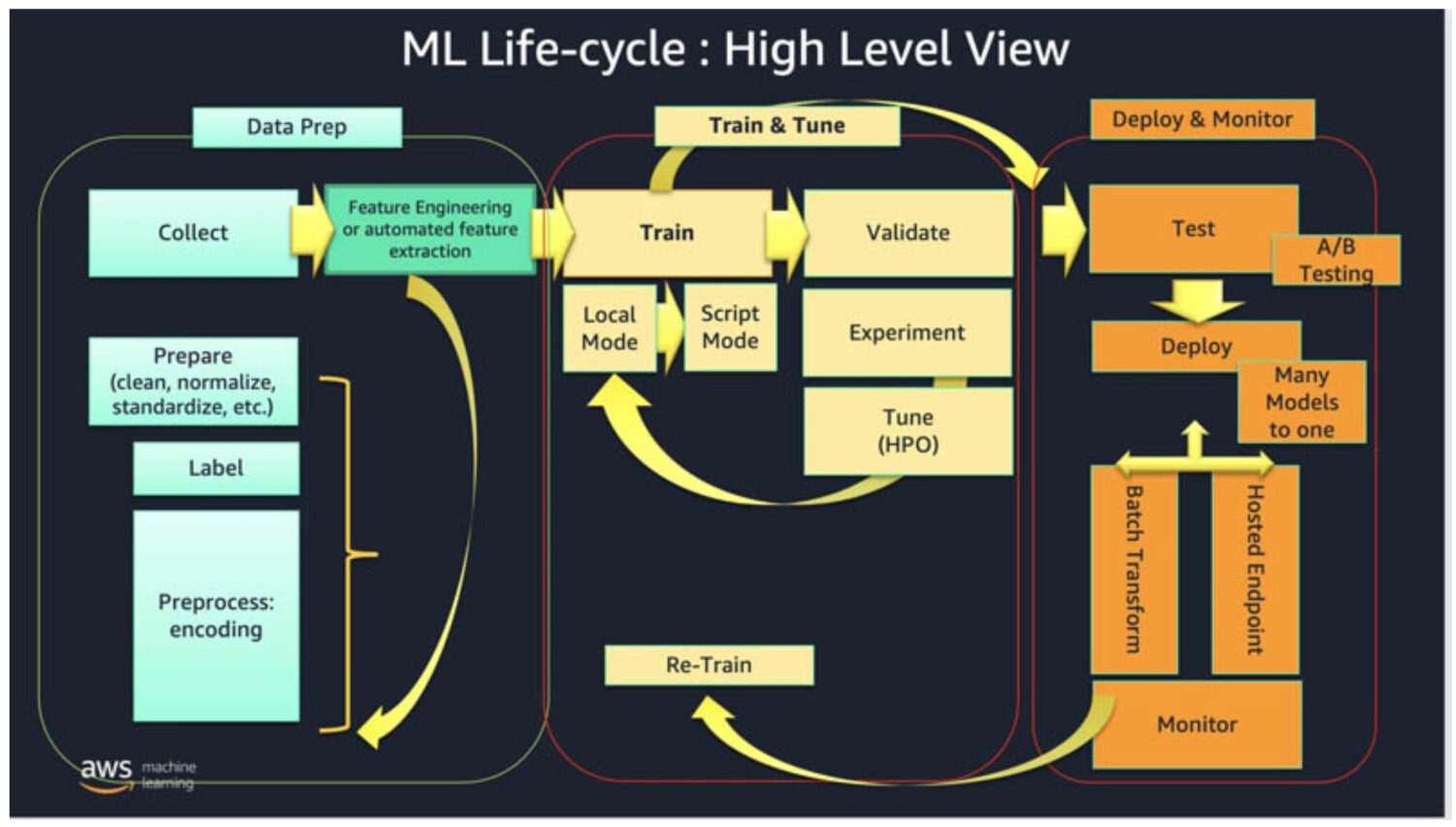
Das Training von AWS-Modellen für maschinelles Lernen zur Erkennung visueller Anomalien umfasst in der Regel mehrere wichtige Schritte.
#1. Sammeln der Daten
Zu Beginn müssen Sie einen großen Datensatz von Bildern sammeln und beschriften, die sowohl normale als auch anomale Bedingungen darstellen. Je größer der Datensatz ist, desto besser und präziser kann das Modell trainiert werden. Aber es bedeutet auch, dass Sie viel mehr Zeit für das Training des Modells aufwenden müssen.
Normalerweise sollten Sie etwa 1000 Bilder in einem Testsatz haben, um einen guten Anfang zu machen.
#2. Bereiten Sie die Daten vor
Die Bilddaten müssen zunächst vorverarbeitet werden, damit die Modelle für maschinelles Lernen sie erfassen können. Vorverarbeitung kann verschiedene Dinge bedeuten, wie z.B.:
- Bereinigung der eingegebenen Bilder in separate Unterordner, Korrektur der Metadaten usw.
- Ändern der Größe der Bilder, um die Auflösungsanforderungen des Modells zu erfüllen.
- Aufteilung der Bilder in kleinere Teile, um eine effektivere und parallele Verarbeitung zu ermöglichen.
#3. Wählen Sie das Modell
Wählen Sie nun das richtige Modell für die richtige Aufgabe. Wählen Sie entweder ein bereits trainiertes Modell oder erstellen Sie ein benutzerdefiniertes Modell, das für die Erkennung visueller Anomalien auf dem Modell geeignet ist.
#4. Bewerten Sie die Ergebnisse
Sobald das Modell Ihren Datensatz verarbeitet hat, sollten Sie seine Leistung validieren. Außerdem möchten Sie überprüfen, ob die Ergebnisse für Ihre Bedürfnisse zufriedenstellend sind. Das kann z.B. bedeuten, dass die Ergebnisse bei mehr als 99% der Eingabedaten korrekt sind.
#5. Setzen Sie das Modell ein
Wenn Sie mit den Ergebnissen und der Leistung zufrieden sind, stellen Sie das Modell mit einer bestimmten Version in der AWS-Kontoumgebung bereit, damit die Prozesse und Services es nutzen können.
#6. Überwachen und Verbessern
Lassen Sie das Modell verschiedene Testaufträge und Bilddatensätze durchlaufen und bewerten Sie ständig, ob die erforderlichen Parameter für die Korrektheit der Erkennung noch gegeben sind.
Falls nicht, trainieren Sie das Modell neu, indem Sie die neuen Datensätze einbeziehen, bei denen das Modell die falschen Ergebnisse geliefert hat.
AWS Modelle für maschinelles Lernen
Sehen wir uns nun einige konkrete Modelle an, die Sie in der Amazon Cloud nutzen können.
AWS Rekognition
Rekognition ist ein universeller Bild- und Videoanalysedienst, der für verschiedene Anwendungsfälle wie Gesichtserkennung, Objekterkennung und Texterkennung eingesetzt werden kann. In den meisten Fällen werden Sie das Rekognition-Modell für eine erste Rohgenerierung von Erkennungsergebnissen verwenden, um einen Datensee mit identifizierten Anomalien zu bilden.
Es bietet eine Reihe von vorgefertigten Modellen, die Sie ohne Training verwenden können. Rekognition liefert auch Echtzeitanalysen von Bildern und Videos mit hoher Genauigkeit und geringer Latenz.
Hier sind einige typische Anwendungsfälle, bei denen Rekognition eine gute Wahl für die Erkennung von Anomalien ist:
- Sie haben einen allgemeinen Anwendungsfall für die Erkennung von Anomalien, z. B. die Erkennung von Anomalien in Bildern oder Videos.
- Führen Sie Anomalie-Erkennung in Echtzeit durch.
- Integrieren Sie Ihr Anomalieerkennungsmodell mit AWS-Services wie Amazon S3, Amazon Kinesis oderAWSLambda.
Und hier sind einige konkrete Beispiele für Anomalien, die Sie mit Rekognition erkennen können:
- Anomalien in Gesichtern, z. B. die Erkennung von Gesichtsausdrücken oder Emotionen außerhalb des normalen Bereichs.
- Fehlende oder falsch platzierte Objekte in einer Szene.
- Falsch geschriebene Wörter oder ungewöhnliche Muster im Text.
- Ungewöhnliche Lichtverhältnisse oder unerwartete Objekte in einer Szene.
- Unangemessene oder anstößige Inhalte in Bildern oder Videos.
- Plötzliche Änderungen in der Bewegung oder unerwartete Bewegungsmuster.
AWS Lookout für Vision
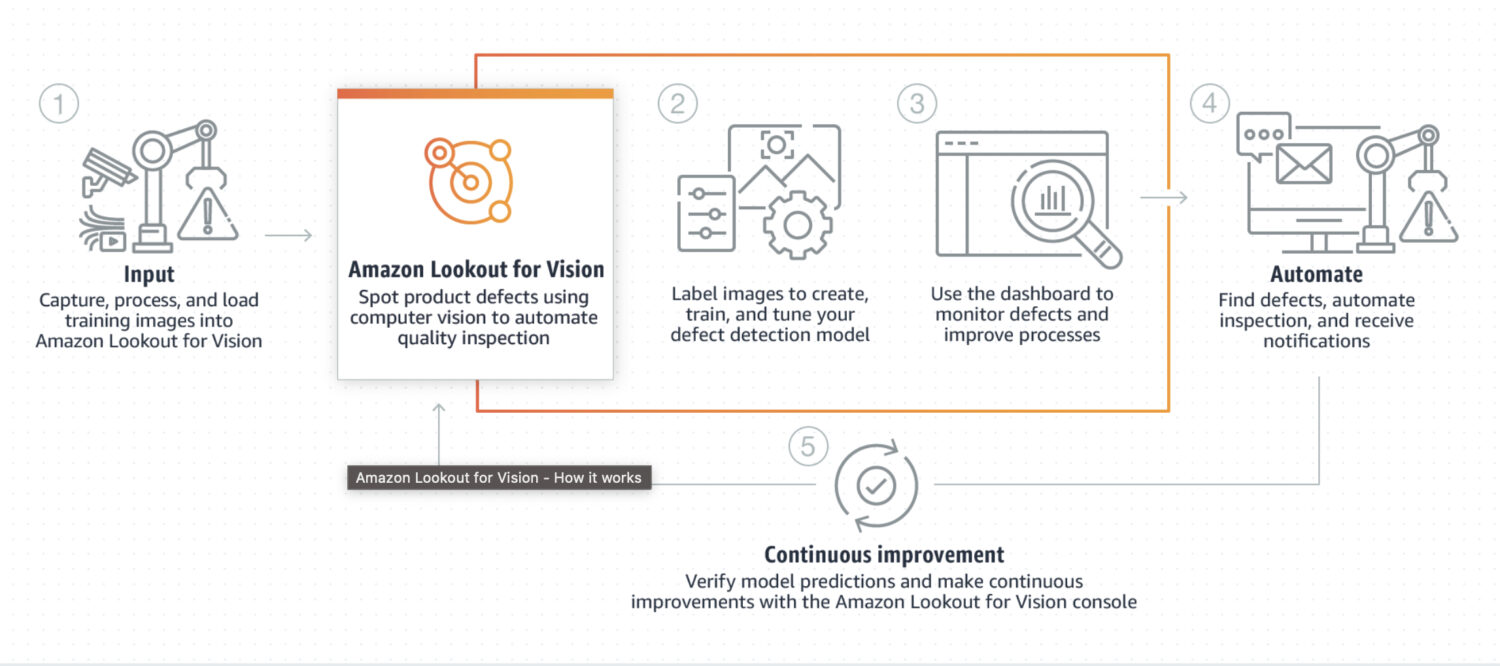
Lookout for Vision ist ein Modell, das speziell für die Erkennung von Anomalien in industriellen Prozessen, z.B. in der Fertigung und in Produktionslinien, entwickelt wurde. Es erfordert in der Regel einen benutzerdefinierten Code zur Vor- und Nachbearbeitung eines Bildes oder eines konkreten Bildausschnitts, der in der Regel mit einer Python-Programmiersprache erstellt wird. Meistens handelt es sich dabei um eine Spezialisierung auf einige sehr spezielle Probleme im Bild.
Es erfordert ein individuelles Training auf einem Datensatz mit normalen und anomalen Bildern, um ein individuelles Modell für die Erkennung von Anomalien zu erstellen. Es ist nicht so sehr auf Echtzeit ausgerichtet. Vielmehr ist es für die Stapelverarbeitung von Bildern konzipiert und konzentriert sich auf Genauigkeit und Präzision.
Hier sind einige typische Anwendungsfälle, in denen Lookout for Vision eine gute Wahl ist, wenn Sie etwas erkennen müssen:
- Defekte in hergestellten Produkten oder das Erkennen von Gerätefehlern in einer Produktionslinie.
- Einen großen Datensatz von Bildern oder anderen Daten.
- Anomalien in einem industriellen Prozess in Echtzeit.
- Anomalien, die in andere AWS-Services integriert sind, wie Amazon S3 oder AWS IoT.
Und hier sind einige konkrete Beispiele für Anomalien, die Sie mit Lookout for Vision erkennen können:
- Defekte in hergestellten Produkten, wie Kratzer, Dellen oder andere Unvollkommenheiten, können die Qualität des Produkts beeinträchtigen.
- Ausrüstungsfehler in einer Produktionslinie, wie z.B. das Erkennen von defekten oder schlecht funktionierenden Maschinen, die Verzögerungen oder Sicherheitsrisiken verursachen können.
- Zu den Problemen bei der Qualitätskontrolle in einer Produktionslinie gehört die Feststellung von Produkten, die nicht den erforderlichen Spezifikationen oder Toleranzen entsprechen.
- Zu den Sicherheitsrisiken in einer Produktionslinie gehört das Aufspüren von Objekten oder Materialien, die eine Gefahr für die Arbeiter oder die Ausrüstung darstellen können.
- Anomalien in einem Produktionsprozess, wie z.B. das Erkennen unerwarteter Veränderungen im Material- oder Produktfluss in der Produktionslinie.
AWS Sagemaker
Sagemaker ist eine vollständig verwaltete Plattform zum Erstellen, Trainieren und Bereitstellen von benutzerdefinierten Machine-Learning-Modellen.
Es ist eine viel robustere Lösung. Sie bietet nämlich eine Möglichkeit, mehrere mehrstufige Prozesse zu einer Kette von aufeinander folgenden Aufträgen zu verbinden und auszuführen, ähnlich wie es die AWS Step Functions tun können.
Da Sagemaker jedoch ad-hoc EC2-Instanzen für die Verarbeitung verwendet, gibt es keine Begrenzung auf 15 Minuten für die Verarbeitung eines einzelnen Auftrags, wie dies bei den AWS Lambda-Funktionen in den AWS Step Functions der Fall ist.
Sie können mit Sagemaker auch eine automatische Modellabstimmung durchführen, was definitiv eine Funktion ist, die es zu einer herausragenden Option macht. Schließlich kann Sagemaker das Modell mühelos in einer Produktionsumgebung bereitstellen.
Hier sind einige typische Anwendungsfälle, in denen SageMaker eine gute Wahl für die Erkennung von Anomalien ist:
- Ein spezieller Anwendungsfall, der nicht von vorgefertigten Modellen oder APIs abgedeckt wird, und wenn Sie ein maßgeschneidertes Modell für Ihre speziellen Anforderungen erstellen müssen.
- Wenn Sie einen großen Datensatz mit Bildern oder anderen Daten haben. Vorgefertigte Modelle erfordern in solchen Fällen eine gewisse Vorverarbeitung, aber Sagemaker kann dies auch ohne sie tun.
- Wenn Sie die Erkennung von Anomalien in Echtzeit durchführen müssen.
- Wenn Sie Ihr Modell mit anderen AWS-Services wie Amazon S3, Amazon Kinesis oder AWS Lambda integrieren müssen.
Und hier sind einige typische Anomalie-Erkennungen, die Sagemaker durchführen kann:
- Erkennung von Betrug bei Finanztransaktionen, z. B. ungewöhnliche Ausgabenmuster oder Transaktionen außerhalb des normalen Bereichs.
- Cybersicherheit im Netzwerkverkehr, z. B. ungewöhnliche Muster bei der Datenübertragung oder unerwartete Verbindungen zu externen Servern.
- Medizinische Diagnose in medizinischen Bildern, z.B. die Erkennung von Tumoren.
- Anomalien in der Geräteleistung, z.B. die Erkennung von Vibrations- oder Temperaturänderungen.
- Qualitätskontrolle bei Fertigungsprozessen, z.B. die Erkennung von Produktfehlern oder Abweichungen von den erwarteten Qualitätsstandards.
- Ungewöhnliche Muster der Energienutzung.
Wie Sie die Modelle in die serverlose Architektur einbinden
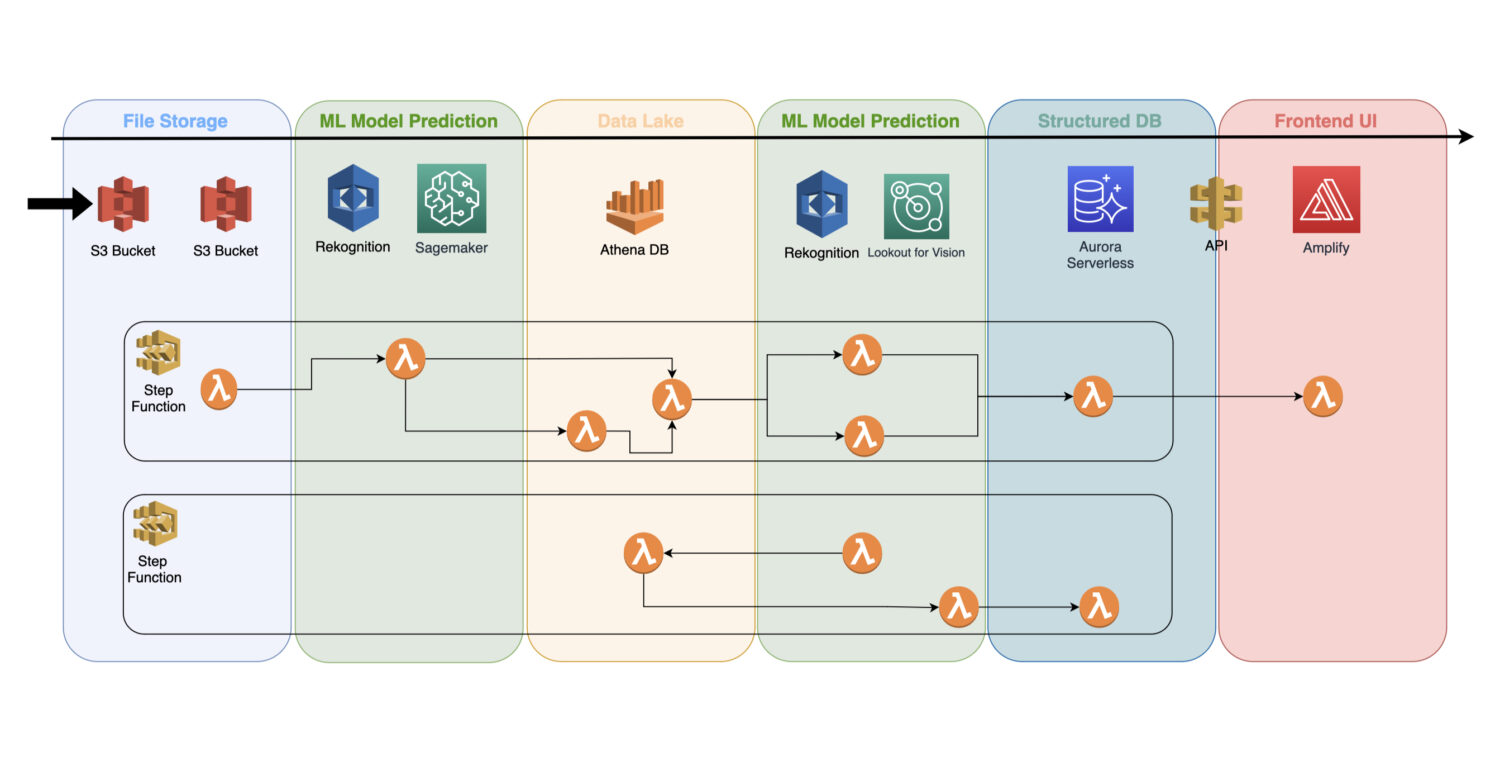
Ein trainiertes Machine-Learning-Modell ist ein Cloud-Service, der keine Cluster-Server im Hintergrund verwendet und daher leicht in eine bestehende serverlose Architektur eingebunden werden kann.
Die Automatisierung erfolgt über AWS Lambda-Funktionen, die in einem AWS Step Functions Service zu einem Job mit mehreren Schritten verbunden sind.
In der Regel benötigen Sie eine erste Erkennung direkt nach dem Sammeln der Bilder und deren Vorverarbeitung im S3-Bucket. Hier erzeugen Sie eine atomare Anomalieerkennung auf den Eingabebildern und speichern die Ergebnisse in einem Data Lake, der zum Beispiel durch die Athena-Datenbank repräsentiert wird.
In manchen Fällen ist diese erste Erkennung für Ihren konkreten Anwendungsfall nicht ausreichend. Sie benötigen möglicherweise eine weitere, detailliertere Erkennung. Beispielsweise kann das ursprüngliche Modell (z.B. Erkennung) ein Problem auf dem Gerät erkennen, aber es ist nicht möglich, zuverlässig zu bestimmen, um welche Art von Problem es sich handelt.
Hierfür benötigen Sie möglicherweise ein anderes Modell mit anderen Fähigkeiten. In einem solchen Fall können Sie das andere Modell (z.B. Lookout for Vision) auf die Teilmenge der Bilder anwenden, bei denen das ursprüngliche Modell das Problem erkannt hat.
Dies ist auch eine gute Möglichkeit, Kosten zu sparen, da Sie das zweite Modell nicht auf einer ganzen Reihe von Bildern ausführen müssen. Stattdessen führen Sie es nur auf der sinnvollen Teilmenge aus.
Die AWS Lambda-Funktionen übernehmen die gesamte Verarbeitung mit Python- oder Javascript-Code im Inneren. Es hängt nur von der Art der Prozesse ab und davon, wie viele AWS Lambda-Funktionen Sie in einen Ablauf einbinden müssen. Die 15-Minuten-Grenze für die maximale Dauer eines AWS Lambda-Aufrufs bestimmt, wie viele Schritte ein solcher Prozess enthalten muss.
Lesen Sie auch: Wie Sie die Orchestrierung von Zugriffsrechten in AWS S3-Buckets automatisieren
Letzte Worte
Die Arbeit mit maschinellen Lernmodellen in der Cloud ist eine sehr interessante Aufgabe. Wenn Sie sie aus der Perspektive der Fähigkeiten und Technologien betrachten, werden Sie feststellen, dass Sie ein Team mit einer großen Vielfalt an Fähigkeiten benötigen.
Das Team muss wissen, wie man ein Modell trainiert, sei es ein vorgefertigtes oder ein von Grund auf neu erstelltes. Das bedeutet, dass viel Mathematik oder Algebra im Spiel ist, um die Zuverlässigkeit und Leistung der Ergebnisse auszugleichen.
Außerdem benötigen Sie fortgeschrittene Python- oder Javascript-Kenntnisse sowie Datenbank- und SQL-Kenntnisse. Und nachdem die ganze inhaltliche Arbeit getan ist, brauchen Sie DevOps-Kenntnisse, um sie in eine Pipeline einzubinden, die sie zu einem automatisierten Job macht, der für die Bereitstellung und Ausführung bereit ist.
Die Definition der Anomalie und das Training des Modells ist eine Sache. Aber es ist eine Herausforderung, dies alles in ein funktionales Team zu integrieren, das die Ergebnisse der Modelle verarbeiten und die Daten auf effektive und automatisierte Weise speichern kann, um sie den Endbenutzern zur Verfügung zu stellen.
Lesen Sie als nächstes alles über Gesichtserkennung für Unternehmen.