Regression und Klassifizierung sind zwei der grundlegendsten und wichtigsten Bereiche des maschinellen Lernens.
Es kann schwierig sein, zwischen Regressions- und Klassifizierungsalgorithmen zu unterscheiden, wenn Sie gerade erst in das maschinelle Lernen einsteigen. Zu verstehen, wie diese Algorithmen funktionieren und wann sie zu verwenden sind, kann entscheidend sein, um genaue Vorhersagen zu machen und effektive Entscheidungen zu treffen.
Lassen Sie uns zunächst etwas über maschinelles Lernen erfahren.
Was ist maschinelles Lernen?

Maschinelles Lernen ist eine Methode, um Computern beizubringen, zu lernen und Entscheidungen zu treffen, ohne explizit programmiert zu werden. Dabei wird ein Computermodell mit einem Datensatz trainiert, so dass das Modell auf der Grundlage von Mustern und Beziehungen in den Daten Vorhersagen oder Entscheidungen treffen kann.
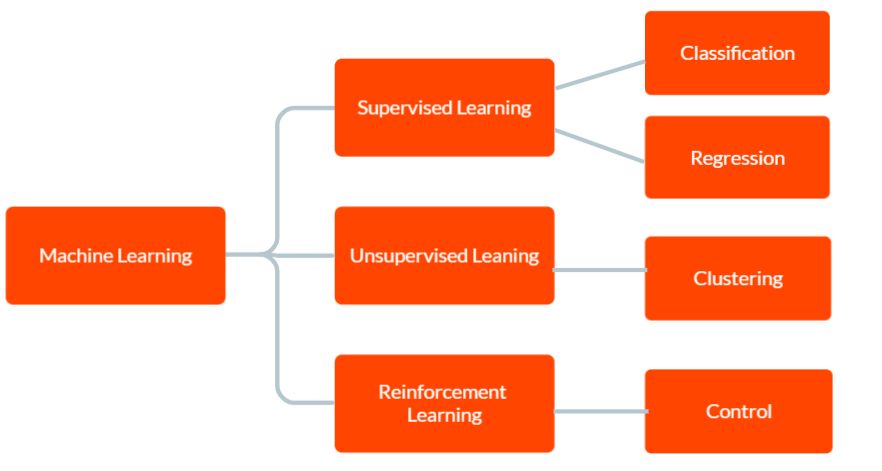
Es gibt drei Hauptarten des maschinellen Lernens: überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen.
Beim überwachten Lernen werden dem Modell markierte Trainingsdaten zur Verfügung gestellt, darunter Eingabedaten und die entsprechenden korrekten Ausgaben. Das Ziel besteht darin, dass das Modell auf der Grundlage der aus den Trainingsdaten gelernten Muster Vorhersagen über die Ausgabe für neue, noch nicht gesehene Daten trifft.
Beim unüberwachten Lernen erhält das Modell keine markierten Trainingsdaten. Stattdessen wird es ihm überlassen, selbständig Muster und Beziehungen in den Daten zu entdecken. Dies kann dazu verwendet werden, Gruppen oder Cluster in den Daten zu identifizieren oder Anomalien oder ungewöhnliche Muster zu finden.
Und beim Reinforcement Learning lernt ein Agent, mit seiner Umgebung zu interagieren, um eine Belohnung zu maximieren. Dabei wird ein Modell trainiert, das auf der Grundlage des Feedbacks, das es aus der Umgebung erhält, Entscheidungen trifft.
Maschinelles Lernen wird in verschiedenen Anwendungen eingesetzt, darunter Bild- und Spracherkennung, Verarbeitung natürlicher Sprache, Betrugserkennung und selbstfahrende Autos. Es hat das Potenzial, viele Aufgaben zu automatisieren und die Entscheidungsfindung in verschiedenen Branchen zu verbessern.
Dieser Artikel befasst sich hauptsächlich mit den Konzepten Klassifizierung und Regression, die zum überwachten maschinellen Lernen gehören. Lassen Sie uns beginnen!
Klassifizierung beim maschinellen Lernen

Klassifizierung ist eine Technik des maschinellen Lernens, bei der ein Modell trainiert wird, um einer gegebenen Eingabe eine Klassenbezeichnung zuzuweisen. Es handelt sich dabei um eine überwachte Lernaufgabe, d.h. das Modell wird anhand eines markierten Datensatzes trainiert, der Beispiele für die Eingabedaten und die entsprechenden Klassenbezeichnungen enthält.
Ziel des Modells ist es, die Beziehung zwischen den Eingabedaten und den Klassenbezeichnungen zu erlernen, um die Klassenbezeichnung für neue, noch nicht gesehene Eingaben vorherzusagen.
Es gibt viele verschiedene Algorithmen, die für die Klassifizierung verwendet werden können, darunter logistische Regression, Entscheidungsbäume und Support Vector Machines. Die Wahl des Algorithmus hängt von den Eigenschaften der Daten und der gewünschten Leistung des Modells ab.
Einige gängige Klassifizierungsanwendungen sind Spam-Erkennung, Stimmungsanalyse und Betrugserkennung. In jedem dieser Fälle können die Eingabedaten Text, numerische Werte oder eine Kombination aus beidem enthalten. Die Klassenlabels können binär (z.B. Spam oder nicht Spam) oder mehrklassig (z.B. positive, neutrale, negative Stimmung) sein.
Betrachten wir zum Beispiel einen Datensatz mit Kundenrezensionen zu einem Produkt. Bei den Eingabedaten könnte es sich um den Text der Bewertung handeln, und das Klassenlabel könnte eine Bewertung sein (z.B. positiv, neutral, negativ). Das Modell würde auf einem Datensatz mit gekennzeichneten Bewertungen trainiert und wäre dann in der Lage, die Bewertung einer neuen Bewertung vorherzusagen, die es zuvor noch nicht gesehen hat.
Arten von ML-Klassifizierungsalgorithmen
Es gibt mehrere Arten von Klassifizierungsalgorithmen im maschinellen Lernen:
Logistische Regression
Dies ist ein lineares Modell, das für die binäre Klassifizierung verwendet wird. Es wird verwendet, um die Wahrscheinlichkeit des Eintretens eines bestimmten Ereignisses vorherzusagen. Das Ziel der logistischen Regression ist es, die besten Koeffizienten (Gewichte) zu finden, die den Fehler zwischen der vorhergesagten Wahrscheinlichkeit und dem beobachteten Ergebnis minimieren.
Dazu wird ein Optimierungsalgorithmus, wie z.B. der Gradientenabstieg, verwendet, um die Koeffizienten anzupassen, bis das Modell so gut wie möglich zu den Trainingsdaten passt.
Entscheidungsbäume
Dies sind baumartige Modelle, die Entscheidungen auf der Grundlage von Merkmalswerten treffen. Sie können sowohl für binäre als auch für Mehrklassen-Klassifizierungen verwendet werden. Entscheidungsbäume haben mehrere Vorteile, darunter ihre Einfachheit und Interoperabilität.
Sie lassen sich außerdem schnell trainieren und erstellen Vorhersagen und können sowohl numerische als auch kategorische Daten verarbeiten. Sie können jedoch anfällig für eine Überanpassung sein, insbesondere wenn der Baum tief ist und viele Verzweigungen hat.
Random Forest Klassifizierung
Die Random Forest-Klassifizierung ist eine Ensemble-Methode, die die Vorhersagen mehrerer Entscheidungsbäume kombiniert, um eine genauere und stabilere Vorhersage zu treffen. Sie ist weniger anfällig für eine Überanpassung als ein einzelner Entscheidungsbaum, da die Vorhersagen der einzelnen Bäume gemittelt werden, was die Varianz im Modell verringert.
AdaBoost
Hierbei handelt es sich um einen Boosting-Algorithmus, der die Gewichtung von falsch klassifizierten Beispielen in der Trainingsmenge adaptiv ändert. Er wird häufig für die binäre Klassifizierung verwendet.

Naïve Bayes
Naïve Bayes basiert auf dem Bayes-Theorem, einem Verfahren zur Aktualisierung der Wahrscheinlichkeit eines Ereignisses auf der Grundlage neuer Erkenntnisse. Es handelt sich um einen probabilistischen Klassifikator, der häufig für die Textklassifizierung und die Spam-Filterung verwendet wird.
K-Nächster Nachbar
K-Nearest Neighbors (KNN) wird für Klassifizierungs- und Regressionsaufgaben verwendet. Es handelt sich um eine nicht-parametrische Methode, die einen Datenpunkt auf der Grundlage der Klasse seiner nächsten Nachbarn klassifiziert. KNN hat mehrere Vorteile, darunter seine Einfachheit und die Tatsache, dass es leicht zu implementieren ist. Außerdem kann es sowohl mit numerischen als auch mit kategorialen Daten umgehen und macht keine Annahmen über die zugrunde liegende Datenverteilung.
Gradient Boosting
Hierbei handelt es sich um Ensembles von schwachen Lernern, die nacheinander trainiert werden, wobei jedes Modell versucht, die Fehler des vorherigen Modells zu korrigieren. Sie können sowohl für die Klassifizierung als auch für die Regression verwendet werden.
Regression beim maschinellen Lernen

Beim maschinellen Lernen ist die Regression eine Art des überwachten Lernens, bei dem das Ziel darin besteht, eine abhängige Variable auf der Grundlage eines oder mehrerer Eingangsmerkmale (auch Prädiktoren oder unabhängige Variablen genannt) vorherzusagen.
Regressionsalgorithmen werden verwendet, um die Beziehung zwischen den Inputs und dem Output zu modellieren und auf der Grundlage dieser Beziehung Vorhersagen zu treffen. Die Regression kann sowohl für kontinuierliche als auch für kategoriale abhängige Variablen verwendet werden.
Im Allgemeinen besteht das Ziel der Regression darin, ein Modell zu erstellen, das die Ausgabe auf der Grundlage der Eingabemerkmale genau vorhersagen kann und die zugrunde liegende Beziehung zwischen den Eingabemerkmalen und der Ausgabe zu verstehen.
Die Regressionsanalyse wird in verschiedenen Bereichen eingesetzt, darunter Wirtschaft, Finanzen, Marketing und Psychologie, um die Beziehungen zwischen verschiedenen Variablen zu verstehen und vorherzusagen. Sie ist ein grundlegendes Instrument der Datenanalyse und des maschinellen Lernens und wird verwendet, um Vorhersagen zu treffen, Trends zu erkennen und die zugrunde liegenden Mechanismen zu verstehen, die die Daten steuern.
Bei einem einfachen linearen Regressionsmodell könnte das Ziel beispielsweise darin bestehen, den Preis eines Hauses auf der Grundlage seiner Größe, Lage und anderer Merkmale vorherzusagen. Die Größe des Hauses und sein Standort wären die unabhängigen Variablen, und der Preis des Hauses wäre die abhängige Variable.
Das Modell wird mit Eingabedaten trainiert, die die Größe und Lage mehrerer Häuser sowie die entsprechenden Preise enthalten. Sobald das Modell trainiert ist, kann es verwendet werden, um Vorhersagen über den Preis eines Hauses in Abhängigkeit von seiner Größe und Lage zu machen.
Arten von ML-Regressionsalgorithmen
Regressionsalgorithmen gibt es in verschiedenen Formen, und die Verwendung jedes Algorithmus hängt von einer Reihe von Parametern ab, wie z.B. der Art des Attributwertes, dem Muster der Trendlinie und der Anzahl der unabhängigen Variablen. Zu den häufig verwendeten Regressionstechniken gehören:
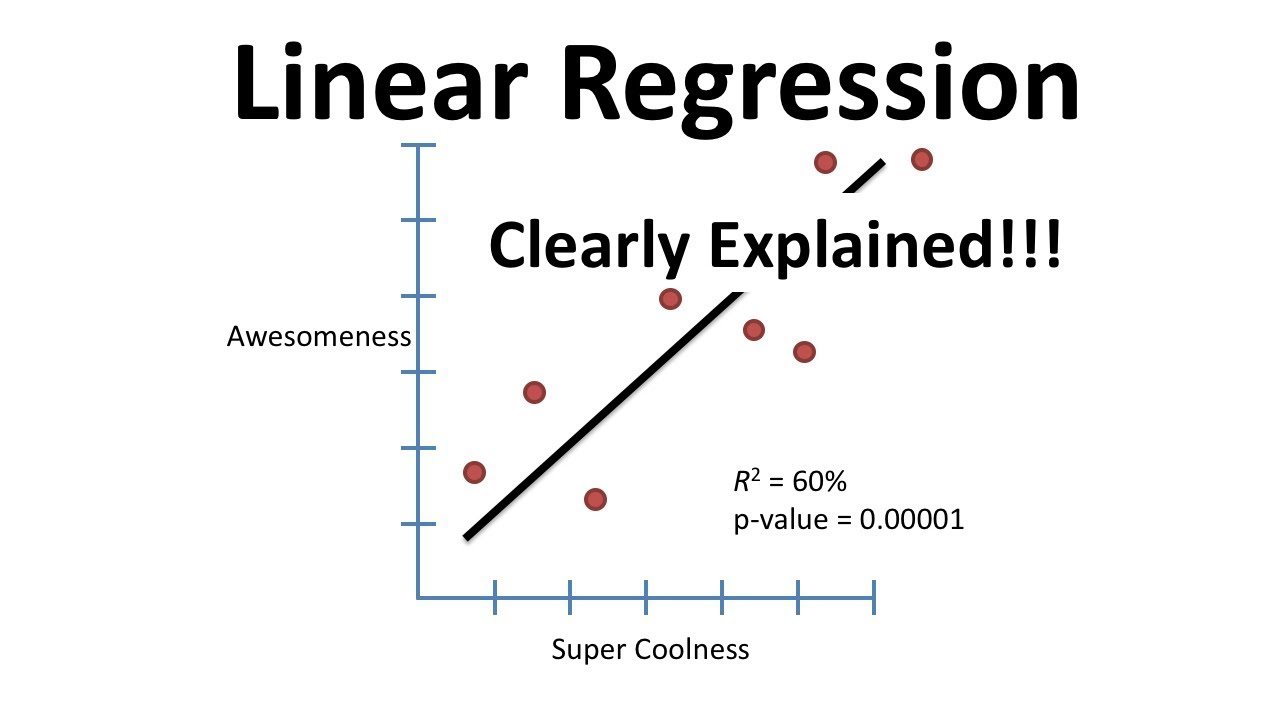
Lineare Regression
Dieses einfache lineare Modell wird verwendet, um einen kontinuierlichen Wert auf der Grundlage einer Reihe von Merkmalen vorherzusagen. Es wird verwendet, um die Beziehung zwischen den Merkmalen und der Zielvariablen zu modellieren, indem eine Linie an die Daten angepasst wird.
Polynomielle Regression
Dies ist ein nicht-lineares Modell, das zur Anpassung einer Kurve an die Daten verwendet wird. Es wird verwendet, um Beziehungen zwischen den Merkmalen und der Zielvariablen zu modellieren, wenn die Beziehung nicht linear ist. Es basiert auf der Idee, dem linearen Modell Terme höherer Ordnung hinzuzufügen, um nicht-lineare Beziehungen zwischen den abhängigen und unabhängigen Variablen zu erfassen.
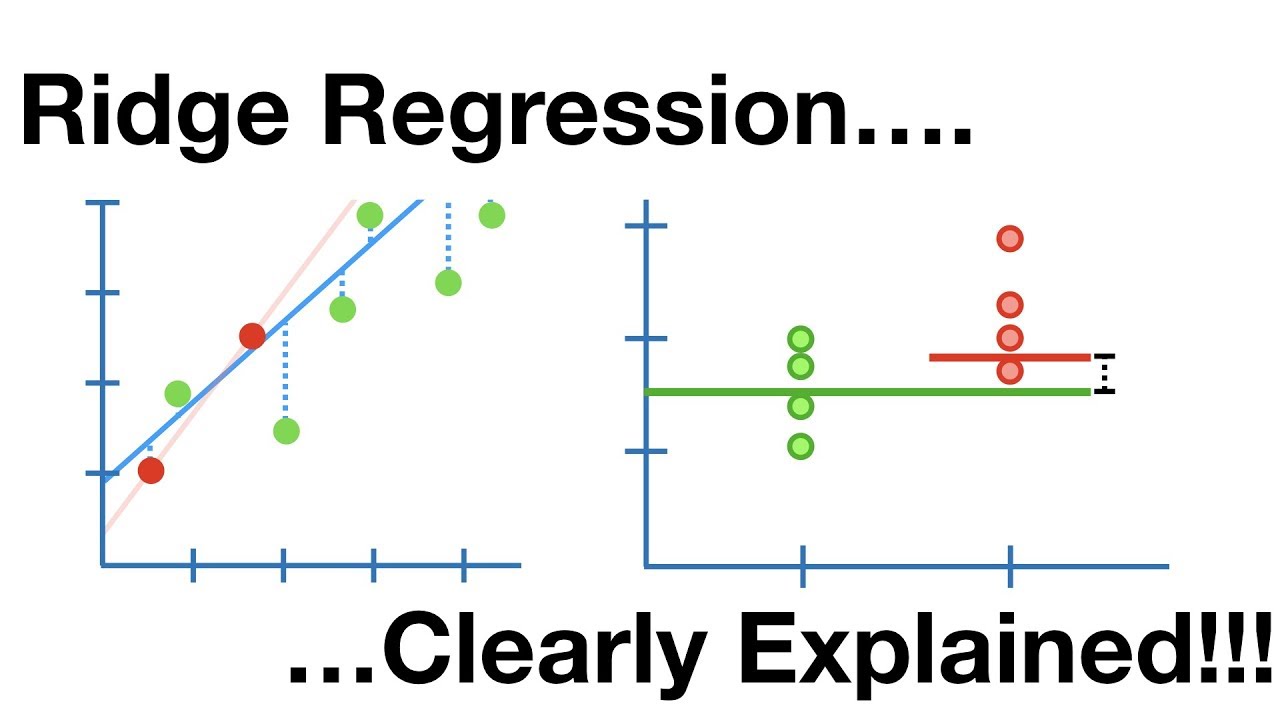
Ridge-Regression
Dies ist ein lineares Modell, das die Überanpassung bei der linearen Regression behandelt. Es handelt sich um eine regularisierte Version der linearen Regression, die der Kostenfunktion einen Strafterm hinzufügt, um die Komplexität des Modells zu verringern.
Support-Vektor-Regression
Wie SVMs ist auch die Support Vector Regression ein lineares Modell, das versucht, die Daten anzupassen, indem es die Hyperebene findet, die die Spanne zwischen den abhängigen und unabhängigen Variablen maximiert.
Im Gegensatz zu SVMs, die zur Klassifizierung verwendet werden, wird SVR jedoch für Regressionsaufgaben verwendet, bei denen das Ziel darin besteht, einen kontinuierlichen Wert und nicht eine Klassenbezeichnung vorherzusagen.
Lasso-Regression
Dies ist ein weiteres regularisiertes lineares Modell, das dazu dient, eine Überanpassung bei der linearen Regression zu verhindern. Es fügt der Kostenfunktion einen Strafterm hinzu, der auf dem absoluten Wert der Koeffizienten basiert.
Bayes’sche lineare Regression
Die Bayes’sche lineare Regression ist ein probabilistischer Ansatz für die lineare Regression, der auf dem Bayes’schen Theorem basiert, einer Methode zur Aktualisierung der Wahrscheinlichkeit eines Ereignisses auf der Grundlage neuer Erkenntnisse.
Dieses Regressionsmodell zielt darauf ab, die posteriore Verteilung der Modellparameter anhand der Daten zu schätzen. Dazu wird eine vorherige Verteilung der Parameter definiert und dann das Bayes’sche Theorem verwendet, um die Verteilung auf der Grundlage der beobachteten Daten zu aktualisieren.
Regression vs. Klassifizierung
Regression und Klassifizierung sind zwei Arten des überwachten Lernens, d.h. sie werden verwendet, um eine Ausgabe auf der Grundlage einer Reihe von Eingabemerkmalen vorherzusagen. Es gibt jedoch einige wichtige Unterschiede zwischen den beiden:
| Regression | Klassifizierung | |
| Definition | Eine Art des überwachten Lernens, die einen kontinuierlichen Wert vorhersagt | Eine Art des überwachten Lernens, die einen kategorischen Wert vorhersagt |
| Typ der Ausgabe | Kontinuierlich | Diskret |
| Bewertungsmetriken | Mittlerer quadratischer Fehler (MSE), mittlerer quadratischer Fehler (RMSE) | Genauigkeit, Präzision, Wiedererkennung, F1-Score |
| Algorithmen | Lineare Regression, Lasso, Ridge, KNN, Entscheidungsbaum | Logistische Regression, SVM, Naïve Bayes, KNN, Entscheidungsbaum |
| Komplexität der Modelle | Weniger komplexe Modelle | Komplexere Modelle |
| Annahmen | Lineare Beziehung zwischen Merkmalen und Ziel | Keine spezifischen Annahmen über die Beziehung zwischen Merkmalen und Ziel |
| Ungleichgewicht der Klassen | Nicht zutreffend | Es kann ein Problem sein |
| Ausreißer | Können die Leistung des Modells beeinträchtigen | Normalerweise kein Problem |
| Bedeutung von Merkmalen | Merkmale sind nach Wichtigkeit geordnet | Merkmale sind nicht nach Wichtigkeit geordnet |
| Anwendungsbeispiele | Vorhersage von Preisen, Temperaturen, Mengen | Vorhersage, ob E-Mail-Spam, Vorhersage der Kundenabwanderung |
Lernressourcen
Es kann schwierig sein, die besten Online-Ressourcen für das Verständnis von Konzepten des maschinellen Lernens auszuwählen. Wir haben die beliebten Kurse, die von zuverlässigen Plattformen angeboten werden, untersucht, um Ihnen unsere Empfehlungen für die besten ML-Kurse zu Regression und Klassifizierung zu präsentieren.
#1. Maschinelles Lernen Klassifizierung Bootcamp in Python
Dies ist ein Kurs, der auf der Udemy-Plattform angeboten wird. Er deckt eine Vielzahl von Klassifizierungsalgorithmen und -techniken ab, darunter Entscheidungsbäume, logistische Regression und unterstützende Vektormaschinen.

Sie können auch etwas über Themen wie Overfitting, Bias-Varianz-Abgleich und Modellbewertung lernen. Der Kurs verwendet Python-Bibliotheken wie sci-kit-learn und pandas, um Modelle für maschinelles Lernen zu implementieren und zu bewerten. Sie benötigen also grundlegende Python-Kenntnisse, um mit diesem Kurs zu beginnen.
#2. Machine Learning Regression Masterclass in Python
In diesem Udemy-Kurs behandelt der Trainer die Grundlagen und die zugrundeliegende Theorie verschiedener Regressionsalgorithmen, einschließlich linearer Regression, polynomialer Regression und Lasso & Ridge Regressionstechniken.
Am Ende dieses Kurses werden Sie in der Lage sein, Regressionsalgorithmen zu implementieren und die Leistung trainierter Machine Learning-Modelle anhand verschiedener Key Performance Indicators zu bewerten.
Zusammenfassung
Algorithmen des maschinellen Lernens können in vielen Anwendungen sehr nützlich sein und helfen, viele Prozesse zu automatisieren und zu rationalisieren. ML-Algorithmen verwenden statistische Techniken, um Muster in Daten zu erkennen und auf der Grundlage dieser Muster Vorhersagen oder Entscheidungen zu treffen.
Sie können auf großen Datenmengen trainiert werden und können für Aufgaben eingesetzt werden, die für Menschen manuell nur schwer oder zeitaufwändig zu erledigen wären.
Jeder ML-Algorithmus hat seine Stärken und Schwächen, und die Wahl des Algorithmus hängt von der Art der Daten und den Anforderungen der Aufgabe ab. Es ist wichtig, den richtigen Algorithmus oder die richtige Kombination von Algorithmen für das spezifische Problem zu wählen, das Sie zu lösen versuchen.
Es ist wichtig, die richtige Art von Algorithmus für Ihr Problem zu wählen, da die Verwendung des falschen Algorithmus zu schlechter Leistung und ungenauen Vorhersagen führen kann. Wenn Sie sich nicht sicher sind, welchen Algorithmus Sie verwenden sollen, kann es hilfreich sein, sowohl Regressions- als auch Klassifizierungsalgorithmen auszuprobieren und deren Leistung mit Ihrem Datensatz zu vergleichen.
Ich hoffe, Sie haben diesen Artikel zum Thema Regression vs. Klassifizierung beim maschinellen Lernen hilfreich gefunden. Vielleicht interessieren Sie sich auch für die besten Modelle des maschinellen Lernens.