Unter Web Scraping versteht man das Extrahieren von Informationen aus einer Website und deren Verwendung für einen bestimmten Anwendungsfall.
Nehmen wir an, Sie versuchen, eine Tabelle aus einer Webseite zu extrahieren, sie in eine JSON-Datei zu konvertieren und die JSON-Datei für den Aufbau einiger interner Tools zu verwenden. Mit Hilfe von Web Scraping können Sie die gewünschten Daten extrahieren, indem Sie die spezifischen Elemente einer Webseite anvisieren. Web Scraping mit Python ist eine sehr beliebte Wahl, da Python mehrere Bibliotheken wie BeautifulSoup oder Scrapy bietet, um Daten effektiv zu extrahieren.

Die Fähigkeit, Daten effizient zu extrahieren, ist auch für einen Entwickler oder Data Scientist sehr wichtig.
Informieren Sie sich über diese Python-Bibliotheken für Datenwissenschaftler.
In diesem Artikel erfahren Sie, wie Sie eine Website effektiv scrapen und die notwendigen Inhalte erhalten, um sie nach Ihren Bedürfnissen zu bearbeiten. Für dieses Tutorial verwenden wir das BeautifulSoup-Paket. Es ist ein trendiges Paket für das Scraping von Daten in Python.
Warum Python für Web Scraping verwenden?
Python ist für viele Entwickler die erste Wahl, wenn es darum geht, Web Scraper zu erstellen. Es gibt viele Gründe, warum Python die erste Wahl ist, aber für diesen Artikel wollen wir drei Hauptgründe erörtern, warum Python für Data Scraping verwendet wird.
Bibliotheken und Community-Unterstützung: Es gibt mehrere großartige Bibliotheken wie BeautifulSoup, Scrapy, Selenium usw., die großartige Funktionen für das effektive Scraping von Webseiten bieten. Es hat sich ein hervorragendes Ökosystem für Web Scraping gebildet, und auch weil viele Entwickler weltweit bereits Python verwenden, können Sie schnell Hilfe bekommen, wenn Sie nicht weiterkommen.
Automatisierung: Python ist berühmt für seine Automatisierungsmöglichkeiten. Wenn Sie versuchen, ein komplexes Tool zu erstellen, das auf Scraping basiert, ist mehr als Web Scraping erforderlich. Wenn Sie z.B. ein Tool erstellen möchten, das die Preise von Artikeln in einem Online-Shop verfolgt, müssen Sie eine Automatisierungsfunktion hinzufügen, damit es die Preise täglich verfolgen und in Ihre Datenbank einfügen kann. Python bietet Ihnen die Möglichkeit, solche Prozesse problemlos zu automatisieren.
Datenvisualisierung: Web Scraping wird häufig von Datenwissenschaftlern verwendet. Datenwissenschaftler müssen oft Daten aus Webseiten extrahieren. Mit Bibliotheken wie Pandas macht Python die Datenvisualisierung aus Rohdaten einfacher.
Bibliotheken für Web Scraping in Python
Es gibt mehrere Bibliotheken in Python, die das Web Scraping vereinfachen. Lassen Sie uns hier die drei beliebtesten Bibliotheken besprechen.
#1. BeautifulSoup
Eine der beliebtesten Bibliotheken für Web Scraping. BeautifulSoup hilft Entwicklern seit 2004 beim Scrapen von Webseiten. Sie bietet einfache Methoden zum Navigieren, Suchen und Ändern des Parse-Baums. BeautifulSoup übernimmt auch die Kodierung der ein- und ausgehenden Daten selbst. Es wird gut gewartet und hat eine große Community.
#2. Scrapy
Ein weiteres beliebtes Framework für die Datenextraktion. Scrapy hat mehr als 43000 Sterne auf GitHub. Es kann auch zum Scrapen von Daten aus APIs verwendet werden. Es hat auch einige interessante integrierte Funktionen, wie das Versenden von E-Mails.
#3. Selenium
Selenium ist nicht in erster Linie eine Bibliothek für Web Scraping. Es handelt sich vielmehr um ein Paket zur Browser-Automatisierung. Aber wir können seine Funktionalitäten für das Scraping von Webseiten leicht erweitern. Es verwendet das WebDriver-Protokoll zur Steuerung verschiedener Browser. Selenium ist nun schon seit fast 20 Jahren auf dem Markt. Aber mit Selenium können Sie ganz einfach Daten von Webseiten automatisieren und auslesen.
Herausforderungen beim Web Scraping mit Python
Beim Scrapen von Daten aus Webseiten kann man auf viele Herausforderungen stoßen. Es gibt Probleme wie langsame Netzwerke, Anti-Scraping-Tools, IP-basierte Sperren, Captcha-Sperren usw. Diese Probleme können beim Scraping einer Website zu massiven Schwierigkeiten führen.
Aber Sie können diese Probleme effektiv umgehen, indem Sie einige Möglichkeiten befolgen. In den meisten Fällen wird zum Beispiel eine IP-Adresse von einer Website blockiert, wenn in einem bestimmten Zeitintervall mehr als eine bestimmte Anzahl von Anfragen gesendet wird. Um die IP-Sperrung zu vermeiden, müssen Sie Ihren Scraper so programmieren, dass er sich nach dem Senden von Anfragen abkühlt.

Entwickler neigen auch dazu, Honigtopf-Fallen für Scraper aufzustellen. Diese Fallen sind normalerweise für das bloße menschliche Auge unsichtbar, können aber von einem Scraper gecrawlt werden. Wenn Sie eine Website scrapen, die eine solche Honigtopfalle enthält, müssen Sie Ihren Scraper entsprechend programmieren.
Captcha ist ein weiteres schwerwiegendes Problem bei Scrapern. Die meisten Websites verwenden heutzutage ein Captcha, um den Zugriff von Bots auf ihre Seiten zu schützen. In einem solchen Fall müssen Sie möglicherweise einen Captcha-Löser verwenden.
Scraping einer Website mit Python
Wie wir bereits besprochen haben, werden wir BeautifulSoup zum Scraping einer Website verwenden. In diesem Tutorial werden wir die historischen Daten von Ethereum von Coingecko scrapen und die Tabellendaten als JSON-Datei speichern. Lassen Sie uns mit der Erstellung des Scrapers beginnen.
Der erste Schritt ist die Installation von BeautifulSoup und Requests. Für dieses Tutorial werde ich Pipenv verwenden. Pipenv ist ein virtueller Umgebungsmanager für Python. Sie können auch Venv verwenden, wenn Sie wollen, aber ich bevorzuge Pipenv. Es würde den Rahmen dieses Tutorials sprengen, auf Pipenv einzugehen. Aber wenn Sie lernen wollen, wie Pipenv verwendet werden kann, folgen Sie dieser Anleitung. Oder, wenn Sie die virtuellen Umgebungen von Python verstehen wollen, folgen Sie dieser Anleitung.
Starten Sie die Pipenv-Shell in Ihrem Projektverzeichnis, indem Sie den Befehl pipenv shell ausführen. Dadurch wird eine Subshell in Ihrer virtuellen Umgebung gestartet. Um BeautifulSoup zu installieren, führen Sie nun den folgenden Befehl aus:
pipenv install beautifulsoup4Und um Requests zu installieren, führen Sie den Befehl ähnlich wie oben aus:
pipenv install requestsSobald die Installation abgeschlossen ist, importieren Sie die erforderlichen Pakete in die Hauptdatei. Erstellen Sie eine Datei namens main.py und importieren Sie die Pakete wie folgt:
from bs4 import BeautifulSoup
importiere Anfragen
importieren jsonDer nächste Schritt besteht darin, den Inhalt der Seite mit den historischen Daten abzurufen und ihn mit dem in BeautifulSoup verfügbaren HTML-Parser zu parsen.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')Im obigen Code wird die Seite mit der in der requests-Bibliothek verfügbaren get-Methode aufgerufen. Der geparste Inhalt wird dann in einer Variablen namens soup gespeichert.
Jetzt beginnt der eigentliche Scraping-Teil. Zunächst müssen Sie die Tabelle im DOM korrekt identifizieren. Wenn Sie diese Seite öffnen und sie mit den im Browser verfügbaren Entwicklertools untersuchen, werden Sie sehen, dass die Tabelle diese Klassen hat table table-striped text-sm text-lg-normal.
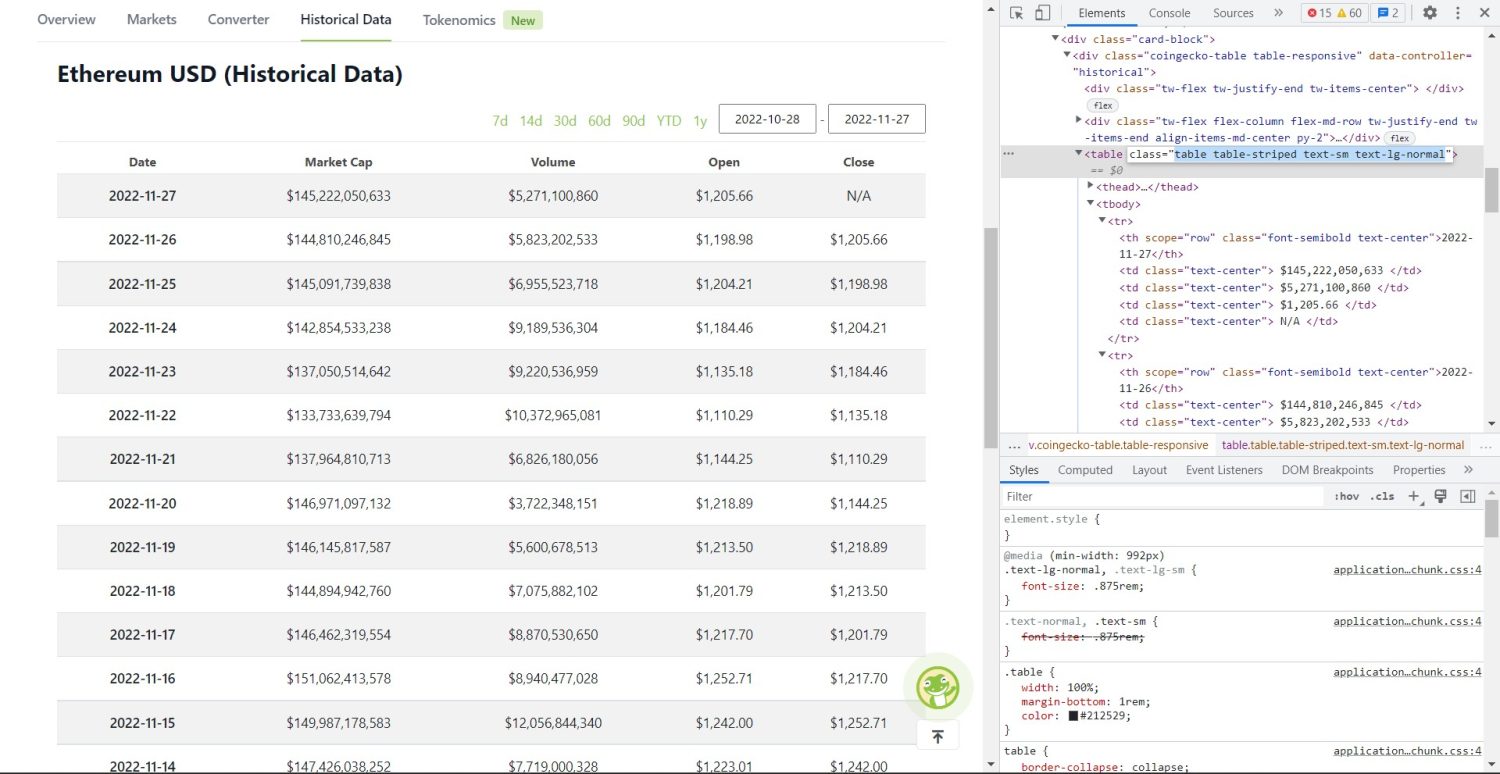
Um diese Tabelle korrekt anzusprechen, können Sie die find-Methode verwenden.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)Im obigen Code wird zunächst die Tabelle mit der Methode soup.find gefunden. Anschließend werden mit der Methode find_all alle tr-Elemente innerhalb der Tabelle gesucht. Diese tr-Elemente werden in einer Variablen namens table_data gespeichert. Die Tabelle hat ein paar th-Elemente für den Titel. Eine neue Variable namens table_headings wird initialisiert, um die Titel in einer Liste zu speichern.
Dann wird eine for-Schleife für die erste Zeile der Tabelle ausgeführt. In dieser Zeile werden alle Elemente mit th durchsucht und ihr Textwert wird der Liste table_headings hinzugefügt. Der Text wird mit der Methode text extrahiert. Wenn Sie die Variable table_headings jetzt ausdrucken, sehen Sie die folgende Ausgabe:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']Der nächste Schritt besteht darin, die restlichen Elemente zu scrapen, für jede Zeile ein Wörterbuch zu erstellen und die Zeilen dann an eine Liste anzuhängen.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
daten = {}
for i in range(len(td)):
data.update({tabellen_ueberschriften[0]: td[0].text})
data.update({tabellen_ueberschriften[i 1]: td[i].text.replace('\n', '')})
wenn data.__len__() > 0:
table_details.append(data)Dies ist der wesentliche Teil des Codes. Für jedes tr in der Variable table_data werden zunächst die th-Elemente durchsucht. Die th-Elemente sind die in der Tabelle angezeigten Daten. Diese th Elemente werden in einer Variablen th gespeichert. In ähnlicher Weise werden alle td-Elemente in der Variablen td gespeichert.
Ein leeres Wörterbuch wird initialisiert. Nach der Initialisierung durchlaufen wir eine Schleife durch den Bereich der td-Elemente. Für jede Zeile aktualisieren wir zunächst das erste Feld des Wörterbuchs mit dem ersten Element von th. Der Code table_headings<x><x><x><x>[0]</x></x></x></x>: th<x><x><x><x>[0]</x></x></x></x>.text weist ein Schlüssel-Wert-Paar aus Datum und dem ersten th-Element zu.
Nach der Initialisierung des ersten Elements werden die anderen Elemente mit data.update({table_headings[i 1]: td<x>[i]</x>.text.replace('\\n', '')}) zugewiesen. Hier wird der Text der td-Elemente zunächst mit der text-Methode extrahiert und dann werden alle \\n mit der replace-Methode ersetzt. Der Wert wird dann dem i 1.Element der table_headings Liste zugewiesen, da das i. Element bereits zugewiesen ist.
Wenn die Länge des Datenwörterbuchs größer als Null ist, hängen wir das Wörterbuch an die Liste table_details an. Sie können die Liste table_details zur Überprüfung ausdrucken. Aber wir werden die Werte in eine JSON-Datei schreiben. Werfen wir einen Blick auf den Code dafür,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Daten in json-Datei gespeichert...')Wir verwenden hier die Methode json.dump, um die Werte in eine JSON-Datei namens table.json zu schreiben. Sobald der Schreibvorgang abgeschlossen ist, geben wir Data saved to json file… in der Konsole aus.
Führen Sie die Datei nun mit dem folgenden Befehl aus,
python run main.pyNach einiger Zeit werden Sie den Text Data saved to JSON file… in der Konsole sehen können. Außerdem sehen Sie eine neue Datei namens table.json im Verzeichnis der Arbeitsdatei. Die Datei wird ähnlich wie die folgende JSON-Datei aussehen:
[
{
"Datum": "2022-11-27",
"Marktkapitalisierung": "$145,222,050,633",
"Volumen": "$5,271,100,860",
"Eröffnet": "$1,205.66",
"Close": "N/A"
},
{
"Datum": "2022-11-26",
"Marktkapitalisierung": "$144,810,246,845",
"Volumen": "$5,823,202,533",
"Eröffnet": "$1,198.98",
"Close": "$1,205.66"
},
{
"Datum": "2022-11-25",
"Marktkapitalisierung": "$145,091,739,838",
"Volumen": "$6,955,523,718",
"Eröffnet": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]Sie haben erfolgreich einen Web Scraper mit Python implementiert. Um den vollständigen Code zu sehen, können Sie dieses GitHub Repo besuchen.
Schlussfolgerung
In diesem Artikel haben wir besprochen, wie Sie einen einfachen Python-Scraper implementieren können. Wir haben besprochen, wie BeautifulSoup für das schnelle Scrapen von Daten aus der Website verwendet werden kann. Wir haben auch andere verfügbare Bibliotheken besprochen und warum Python für viele Entwickler die erste Wahl für das Scrapen von Websites ist.