A medida que aumenta el número de empresas que utilizan big data en tiempo real para obtener información y tomar decisiones basadas en datos, también aumenta la necesidad de una herramienta resistente para procesar estos datos en tiempo real.
Apache Kafka es una herramienta utilizada en los sistemas de big data por su capacidad para manejar un alto rendimiento y el procesamiento en tiempo real de grandes cantidades de datos.
Qué es Apache Kafka
ApacheKafka es un software de código abierto que permite almacenar y procesar flujos de datos en una plataforma de streaming distribuida. Proporciona varias interfaces para escribir datos en clusters Kafka y leer, importar y exportar datos a y desde sistemas de terceros.

Apache Kafka se desarrolló inicialmente como una cola de mensajes LinkedIn. Como proyecto de la Apache Software Foundation, el software de código abierto se ha convertido en una robusta plataforma de streaming con una amplia gama de funciones.
El sistema se basa en una arquitectura distribuida centrada en un clúster que contiene múltiples temas, optimizado para procesar grandes flujos de datos en tiempo real, como se muestra en la imagen siguiente:
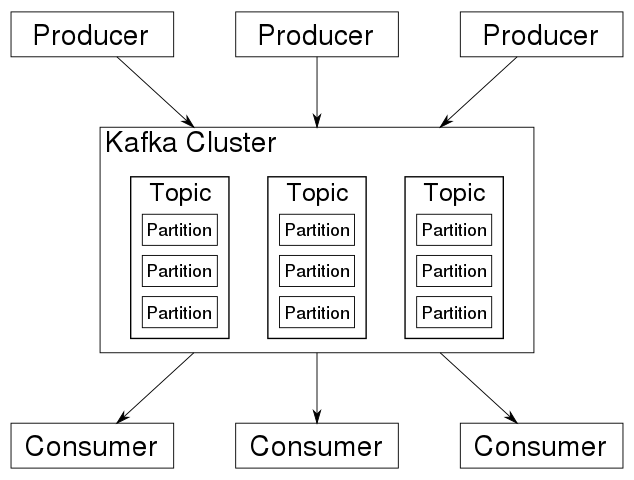
Con la ayuda de Kafka, se pueden almacenar y procesar flujos de datos. Esto hace que Kafka sea adecuado para grandes cantidades de datos y aplicaciones en el entorno de big data.
Es posible cargar flujos de datos desde sistemas de terceros o exportarlos a estos sistemas a través de las interfaces proporcionadas. El componente central del sistema es un commit distribuido o registro de transacciones.
Kafka: Función básica
Kafka resuelve los problemas que surgen cuando las fuentes y los receptores de datos se conectan directamente.
Por ejemplo, cuando los sistemas están conectados directamente, es imposible almacenar datos en el búfer si el receptor no está disponible. Además, un emisor puede sobrecargar al receptor si envía datos más rápido de lo que el receptor los acepta y procesa.
Kafka actúa como un sistema de mensajería entre el emisor y el receptor. Gracias a su registro de transacciones distribuido, el sistema puede almacenar datos y hacer que estén disponibles con alta disponibilidad. Los datos pueden procesarse a gran velocidad en cuanto llegan. Los datos pueden agregarse en tiempo real.
Arquitectura de Kafka
La arquitectura de Kafka consiste en una red de ordenadores en clúster. En esta red de ordenadores, los llamados brokers almacenan mensajes con una marca de tiempo. Esta información se denomina temas. La información almacenada se replica y distribuye en el clúster.
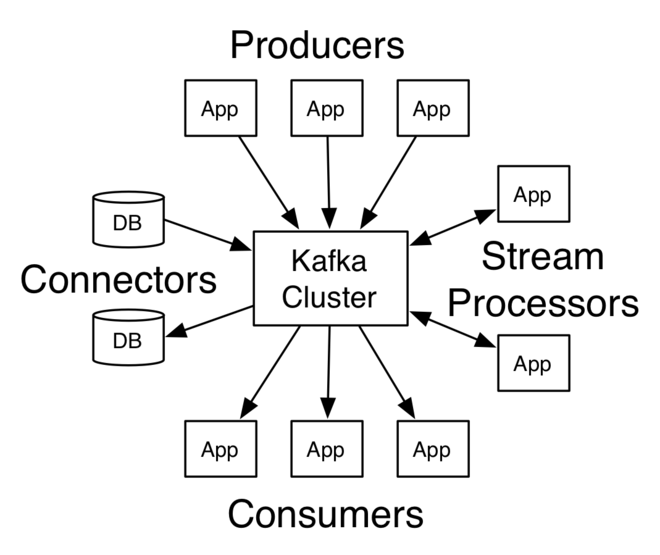
Los productores son aplicaciones que escriben mensajes o datos en un clúster Kafka. Los consumidores son aplicaciones que leen datos del clúster Kafka.
Además, una biblioteca Java llamada Kafka Streams lee datos del clúster, los procesa y escribe los resultados de nuevo en el clúster.
Kafka distingue entre «Temas normales» y «Temas compactados» Los temas normales se almacenan durante un periodo determinado y no deben superar un tamaño de almacenamiento definido. Si se supera el límite del periodo de almacenamiento, Kafka puede borrar los mensajes antiguos. Los temas compactados no están sujetos ni a un límite de tiempo ni a un límite de espacio de almacenamiento.
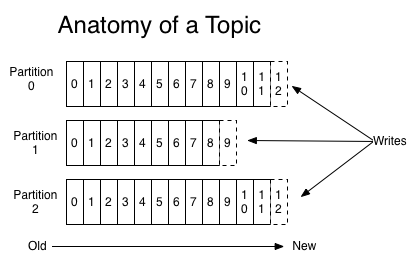
Un tema se divide en particiones. El número de particiones se establece cuando se crea el tema, y determina cómo se escala el tema. Los mensajes de un tema se distribuyen entre las particiones. El desplazamiento es por partición. Las particiones son el mecanismo fundamental a través del cual funcionan tanto el escalado como la replicación.
Escribir o leer de un tema siempre se refiere a una partición. Cada partición se ordena por su desplazamiento. Si escribe un mensaje en un tema, tiene la opción de especificar una clave.
El hash de esta clave garantiza que todos los mensajes con la misma clave acaben en la misma partición. El respeto del orden de los mensajes entrantes está garantizado dentro de una partición.
Interfaces de Kafka
En general, Kafka ofrece estas cuatro interfaces principales (API – Application Programming Interfaces):
- API de productor
- API del consumidor
- API del flujo
- API de conexión
La API del Productor permite a las aplicaciones escribir datos o mensajes en un clúster Kafka. Los datos de un clúster Kafka pueden leerse a través de la API del consumidor. Las API del Productor y del Consumidor utilizan el protocolo de mensajes Kafka. Se trata de un protocolo binario. En principio, el desarrollo de clientes productores y consumidores es posible en cualquier lenguaje de programación.
La API de flujos es una biblioteca Java. Puede procesar flujos de datos de forma tolerante a fallos y con estado. Es posible filtrar, agrupar y asignar datos mediante los operadores proporcionados. Además, puede integrar sus operadores en la API.
La API de flujos admite tablas, uniones y ventanas temporales. El almacenamiento fiable de los estados de la aplicación se garantiza mediante el registro de todos los cambios de estado en Kafka Topics. Si se produce un fallo, el estado de la aplicación puede restaurarse leyendo los cambios de estado del tema.
La API Kafka Connect proporciona las interfaces para cargar y exportar datos desde o hacia sistemas de terceros. Se basa en las API de productor y consumidor.
Conectores especiales se encargan de la comunicación con sistemas de terceros. Numerosos conectores comerciales o gratuitos conectan sistemas de terceros de distintos fabricantes a Kafka.
Características de Kafka

Kafka es una herramienta valiosa para las organizaciones que desean crear sistemas de datos en tiempo real. Algunas de sus principales características son
Alto rendimiento
Kafka es un sistema distribuido que puede ejecutarse en múltiples máquinas y está diseñado para manejar un alto rendimiento de datos, lo que lo convierte en una opción ideal para manejar grandes cantidades de datos en tiempo real.
Durabilidad y baja latencia
Kafka almacena todos los datos publicados, lo que significa que aunque un consumidor esté desconectado, podrá seguir consumiendo los datos una vez que vuelva a estar conectado. Además, Kafka está diseñado para tener una baja latencia, por lo que puede procesar los datos rápidamente y en tiempo real.
Alta escalabilidad
Kafka puede manejar una cantidad cada vez mayor de datos en tiempo real con una degradación mínima o nula de su rendimiento, lo que lo hace adecuado para su uso en aplicaciones de procesamiento de datos a gran escala y de alto rendimiento.
Tolerancia a fallos
La tolerancia a fallos también está integrada en el diseño de Kafka, ya que replica los datos en varios nodos, de modo que si uno de ellos falla, siguen estando disponibles en los demás. Kafka garantiza que los datos estén siempre disponibles, incluso en caso de fallo.
Modelo de publicación-suscripción
En Kafka, los productores escriben datos en los temas y los consumidores leen de los temas. Esto permite un alto grado de desacoplamiento entre los productores y los consumidores de datos, lo que lo convierte en una gran opción para crear arquitecturas basadas en eventos.
API sencilla
Kafka proporciona una API sencilla y fácil de usar para producir y consumir datos, lo que la hace accesible a una amplia gama de desarrolladores.
Compresión
Kafka admite la compresión de datos, lo que puede ayudar a reducir la cantidad de espacio de almacenamiento necesario y aumentar la velocidad de transferencia de datos.
Procesamiento de flujos en tiempo real
Kafka puede utilizarse para el procesamiento de flujos en tiempo real, lo que permite a las organizaciones procesar los datos en tiempo real a medida que se generan.
Casos de uso de Kafka
Kafka ofrece una amplia gama de posibles usos. Las áreas típicas de aplicación son
Seguimiento de la actividad de un sitio web en tiempo real
Kafka puede recopilar, procesar y analizar datos de actividad de sitios web en tiempo real, lo que permite a las empresas obtener información y tomar decisiones basadas en el comportamiento de los usuarios.
Análisis de datos financieros en tiempo real
Kafka permite procesar y analizar datos financieros en tiempo real, lo que permite una identificación más rápida de tendencias y posibles rupturas.
Monitorización de aplicaciones distribuidas
Kafka puede recopilar y procesar datos de registro de aplicaciones distribuidas, lo que permite a las organizaciones supervisar su rendimiento e identificar y solucionar problemas rápidamente.
Agregación de archivos de registro de distintas fuentes
Kafka puede agregarlos desde distintas fuentes y ponerlos a disposición en una ubicación centralizada para su análisis y supervisión.
Sincronización de datos en sistemas distribuidos
Kafka permite sincronizar datos entre varios sistemas, lo que garantiza que todos ellos dispongan de la misma información y puedan trabajar juntos de forma eficaz. Por eso lo utilizan tiendas minoristas como Walmart.
Otra importante área de aplicación de Kafka es el aprendizaje automático. Kafka soporta, entre otras cosas, el aprendizaje automático:
Entrenamiento de modelos en tiempo real
Apache Kafka puede transmitir datos en tiempo real para entrenar modelos de aprendizaje automático, lo que permite realizar predicciones más precisas y actualizadas.
Derivación de modelos analíticos en tiempo real
Kafka puede procesar y analizar datos para derivar modelos analíticos, proporcionando perspectivas y predicciones que pueden utilizarse para tomar decisiones y emprender acciones.
Algunos ejemplos de aplicaciones de aprendizaje automático son la detección de fraudes mediante la vinculación de información de pagos en tiempo real con datos y patrones históricos, la venta cruzada mediante ofertas personalizadas y específicas para cada cliente basadas en datos actuales, históricos o de ubicación, o el mantenimiento predictivo mediante el análisis de datos de máquinas.
Recursos de aprendizaje de Kafka
Ahora que ya hemos hablado de qué es Kafka y cuáles son sus casos de uso, a continuación le ofrecemos algunos recursos que le ayudarán a aprender y utilizar Kafka en el mundo real:
#1. Serie Apache Kafka – Aprenda Apache Kafka para principiantes v3
Aprenda Apache Kafka para principiantes es un curso introductorio ofrecido por Stephane Maarek en Udemy. El curso tiene como objetivo proporcionar una introducción completa a Kafka para las personas que son nuevas en esta tecnología, pero tienen algún conocimiento previo de Java y Linux CLI.
Cubre todos los conceptos fundamentales y proporciona ejemplos prácticos junto con un proyecto del mundo real que le ayuda a comprender mejor cómo funciona Kafka.

#2. Serie Apache Kafka – Kafka Streams
Kafka Streams para el procesamiento de datos es otro curso ofrecido por Stephane Maarek destinado a proporcionar una comprensión en profundidad de Kafka Streams.
El curso cubre temas como la arquitectura de Kafka Streams, la API de Kafka Streams, Kafka Streams, Kafka Connect, Kafka Streams y KSQL, e incluye algunos casos de uso del mundo real y cómo implementarlos utilizando Kafka Streams. El curso está diseñado para ser accesible a aquellos con experiencia previa con Kafka.

#3. Apache Kafka para principiantes absolutos
Kafka para principiantes absolutos es un curso para novatos que cubre los fundamentos de Kafka, incluyendo su arquitectura, conceptos básicos y características. También cubre la instalación y configuración de un cluster Kafka, la producción y consumo de mensajes y un microproyecto.

#4. La guía práctica completa de Apache Kafka
La guía práctica de Kafka tiene como objetivo proporcionar experiencia práctica trabajando con Kafka. También cubre los conceptos fundamentales de Kafka y una guía práctica sobre la creación de clusters, brokers múltiples y la escritura de productores y consolas personalizados. Este curso no requiere ningún requisito previo.

#5. Creación de aplicaciones de streaming de datos con Apache Kafka
Building Data Streaming Applications with Apache Kafka es una guía para desarrolladores y arquitectos que quieran aprender a crear aplicaciones de flujo de datos utilizando Apache Kafka.
No products found.
El libro cubre los conceptos clave y la arquitectura de Kafka y explica cómo utilizar Kafka para construir pipelines de datos en tiempo real y aplicaciones de streaming.
Abarca temas como la configuración de un clúster de Kafka, el envío y la recepción de mensajes y la integración de Kafka con otros sistemas y herramientas. Además, el libro proporciona las mejores prácticas para ayudar a los lectores a construir aplicaciones de flujo de datos escalables y de alto rendimiento.
#6. Guía de inicio rápido de Apache Kafka
La Guía de inicio rápido de Kafka cubre los aspectos básicos de Kafka, incluyendo su arquitectura, conceptos clave y operaciones básicas. También proporciona instrucciones paso a paso para configurar un cluster Kafka sencillo y utilizarlo para enviar y recibir mensajes.
No products found.
Además, la guía ofrece una visión general de funciones más avanzadas como la replicación, la partición y la tolerancia a fallos. Esta guía está pensada para desarrolladores, arquitectos e ingenieros de datos que son nuevos en Kafka y quieren ponerse en marcha con la plataforma rápidamente.
Conclusión
Apache Kafka es una plataforma de streaming distribuido que construye pipelines de datos en tiempo real y aplicaciones de streaming. Kafka desempeña un papel clave en los sistemas de big data al proporcionar una forma rápida, fiable y escalable de recopilar y procesar grandes cantidades de datos en tiempo real.
Permite a las empresas obtener información, tomar decisiones basadas en datos y mejorar sus operaciones y su rendimiento general.
También puede explorar el procesamiento de datos con Kafka y Spark.