En el mundo actual, impulsado por los datos, el método tradicional de recopilación manual de datos ha quedado obsoleto. Un ordenador con conexión a Internet en cada escritorio ha convertido la web en una enorme fuente de datos. Por lo tanto, el método moderno más eficaz y que ahorra tiempo para la recopilación de datos es el web scraping. Y cuando se trata de web scraping, Python tiene una herramienta llamada Beautiful Soup. En este post, le guiaré a través de los pasos de instalación de Beautiful Soup para empezar con el web scraping.
Antes de instalar y trabajar con Beautiful Soup, veamos por qué debería decidirse por ella.
¿Qué es Beautiful Soup?
Imaginemos que está investigando «el impacto de COVID en la salud de las personas» y ha encontrado unas cuantas páginas web que contienen datos relevantes. Pero, ¿y si no le ofrecen una opción de descarga con un solo clic para tomar prestados sus datos? Aquí entra en juego Beautiful Soup.
Beautiful Soup se encuentra entre el índice de bibliotecas Python para extraer los datos de los sitios objetivo. Se siente más cómodo recuperando datos de páginas HTML o XML.
Leonard Richardson sacó a la luz la idea de Beautiful Soup para raspar la web en 2004. Pero su contribución al proyecto continúa hasta hoy. Actualiza con orgullo cada nueva versión de Beautiful Soup en su cuenta de Twitter.
Aunque Beautiful Soup para el raspado web se desarrolló utilizando Python 3.8, funciona perfectamente tanto con Python 3 como con Python 2.4.

A menudo, los sitios web utilizan la protección captcha para rescatar sus datos de las herramientas de IA. En este caso, unos pocos cambios en la cabecera ‘user-agent ‘ de la Beautiful Soup o el uso de APIs de resolución de captchas pueden imitar a un navegador fiable y engañar a la herramienta de detección.
Sin embargo, si no tiene tiempo para explorar Beautiful Soup o desea que el raspado se realice de forma eficiente y sencilla, entonces no debería dejar de echar un vistazo a esta API de raspado web, en la que sólo tiene que proporcionar una URL y tendrá los datos en sus manos.
Si ya es programador, utilizar Beautiful Soup para el raspado no le resultará desalentador gracias a su sencilla sintaxis para navegar por páginas web y extraer los datos deseados basándose en el análisis sintáctico condicional. Al mismo tiempo, también es amigable para los novatos.
Aunque Beautiful Soup no es para el scraping avanzado, funciona mejor para scrapear los datos de archivos escritos en lenguajes de marcado.
Una documentación clara y detallada es otro punto a favor de Beautiful Soup.
Busquemos una forma fácil de instalar Beautiful Soup en su máquina.
¿Cómo instalar Beautiful Soup para Web Scraping?
Pip – Un gestor de paquetes de Python sin esfuerzo desarrollado en 2008 es ahora una herramienta estándar entre los desarrolladores para instalar cualquier biblioteca o dependencia de Python.
Pip viene por defecto con la instalación de versiones recientes de Python. Por lo tanto, si usted tiene cualquier versión reciente de Python instalada en su sistema, usted es bueno para ir.
Abra el símbolo del sistema y escriba el siguiente comando pip para instalar la sopa hermosa al instante.
pip install beautifulsoup4Verá algo similar a la siguiente captura de pantalla en su pantalla.
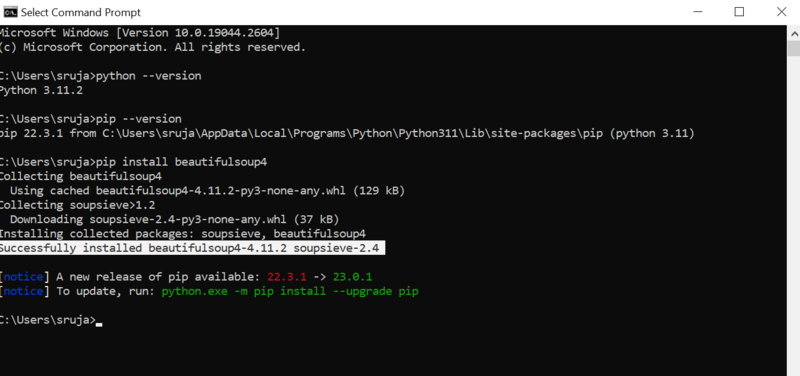
Asegúrese de que ha actualizado el instalador pip a la última versión para evitar errores comunes.
El comando para actualizar el instalador pip a la última versión es:
pip install --upgrade pipHemos cubierto con éxito la mitad del terreno en este post.
Ahora ya tiene Beautiful Soup instalado en su máquina, así que vamos a sumergirnos en cómo utilizarlo para el web scraping.
¿Cómo importar y trabajar con Beautiful Soup para Web Scraping?
Escriba el siguiente comando en su IDE de python para importar Beautiful Soup en el script de python actual.
from bs4 import BeautifulSoupAhora la Beautiful Soup está en su archivo Python para utilizarla para el scraping.
Veamos un ejemplo de código para aprender a extraer los datos deseados con beautiful Soup.
Podemos decirle a Beautiful Soup que busque etiquetas HTML específicas en el sitio web de origen y raspe los datos presentes en esas etiquetas.
En este artículo, utilizaré marketwatch.com, que actualiza en tiempo real las cotizaciones bursátiles de varias empresas. Vamos a extraer algunos datos de este sitio web para familiarizarnos con la biblioteca Beautiful Soup.
Importemos el paquete « requests» que nos permitirá recibir y responder a peticiones HTTP y «urllib » para cargar la página web desde su URL.
from urllib.request import urlopen
import requestsGuarde el enlace de la página web en una variable para poder acceder fácilmente a él más tarde.
url = 'https://www.marketwatch.com/investing/stock/amzn'Lo siguiente sería utilizar el método «urlopen» de la biblioteca«urllib» para almacenar la página HTML en una variable. Pase la URL a la función «urlopen» y guarde el resultado en una variable.
page = urlopen(url)Cree un objeto Beautiful Soup y analice la página web deseada utilizando «html.parser».
soup_obj = BeautifulSoup(page, 'html.parser')Ahora todo el script HTML de la página web deseada se almacena en la variable ‘ soup_obj ‘.
Antes de continuar, echemos un vistazo al código fuente de la página objetivo para saber más sobre el script HTML y las etiquetas.
Haga clic con el botón derecho del ratón en cualquier parte de la página web. Entonces encontrará una opción inspeccionar, como se muestra a continuación.
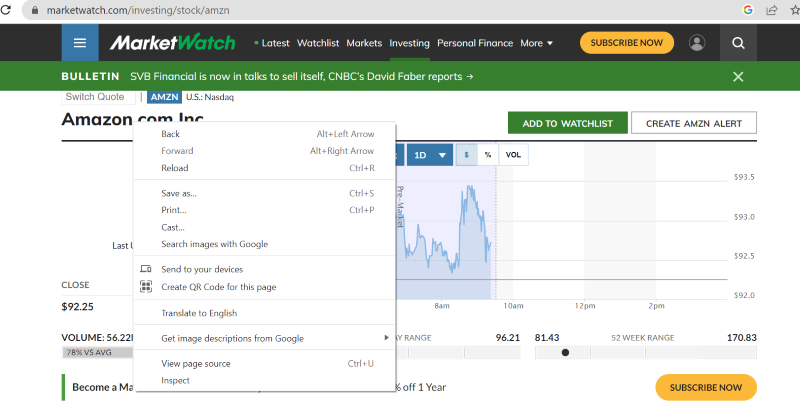
Haga clic en inspeccionar para ver el código fuente.
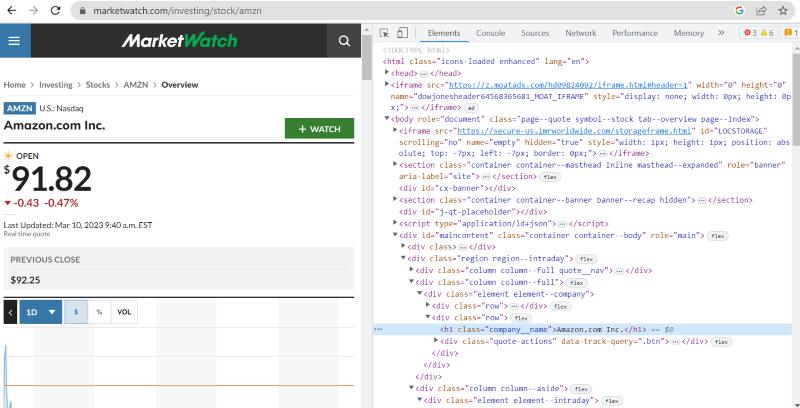
En el código fuente anterior, puede encontrar etiquetas, clases e información más específica sobre cada elemento visible en la interfaz de la página web.
El método «find » de beautiful Soup nos permite buscar las etiquetas HTML solicitadas y recuperar los datos. Para ello, damos el nombre de la clase y las etiquetas al método que extrae los datos específicos.
Por ejemplo, «Amazon.com Inc.» que aparece en la página web tiene el nombre de clase: ‘company__name’ etiquetado bajo ‘h1’. Podemos introducir esta información en el método ‘find’ para extraer el fragmento HTML correspondiente en una variable.
name = soup_obj.find('h1', attrs={'class': 'company__name'})Hagamos aparecer en pantalla el fragmento HTML almacenado en la variable «nombre» y el texto requerido.
print(nombre)
print(nombre.texto)
Puede ver los datos extraídos impresos en la pantalla.
Web Scrape del sitio web IMDb
Muchos de nosotros buscamos las calificaciones de las películas en el sitio de IMBb antes de ver una película. Esta demostración le proporcionará una lista de las películas mejor valoradas y le ayudará a acostumbrarse al hermoso Soup para web scraping.
Paso 1: Importe las bibliotecas beautiful Soup y requests.
from bs4 import BeautifulSoup
import requestsPaso 2: Vamos a asignar la URL que queremos raspar a una variable llamada «url » para facilitar el acceso en el código.
El paquete«requests» se utiliza para obtener la página HTML de la URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')Paso 3: En el siguiente fragmento de código, analizaremos la página HTML de la URL actual para crear un objeto de BeautifulSopp.
soup_obj = BeautifulSoup(url.text, 'html.parser')La variable «soup_obj» contiene ahora todo el script HTML de la página web deseada, como en la siguiente imagen.
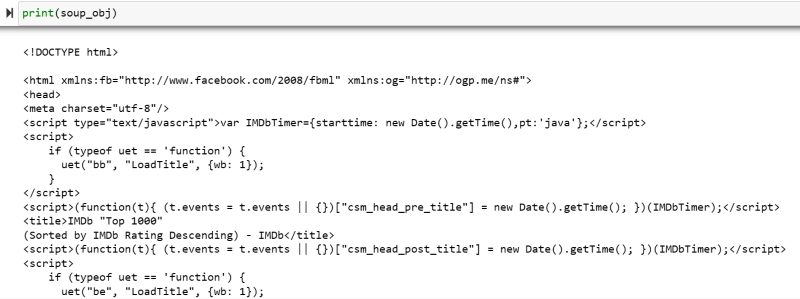
Inspeccionemos el código fuente de la página web para encontrar el script HTML de los datos que queremos raspar.
Sitúe el cursor sobre el elemento de la página web que desea extraer. A continuación, haga clic con el botón derecho del ratón sobre él y vaya a la opción inspeccionar para ver el código fuente de ese elemento específico. Las siguientes imágenes le guiarán mejor.
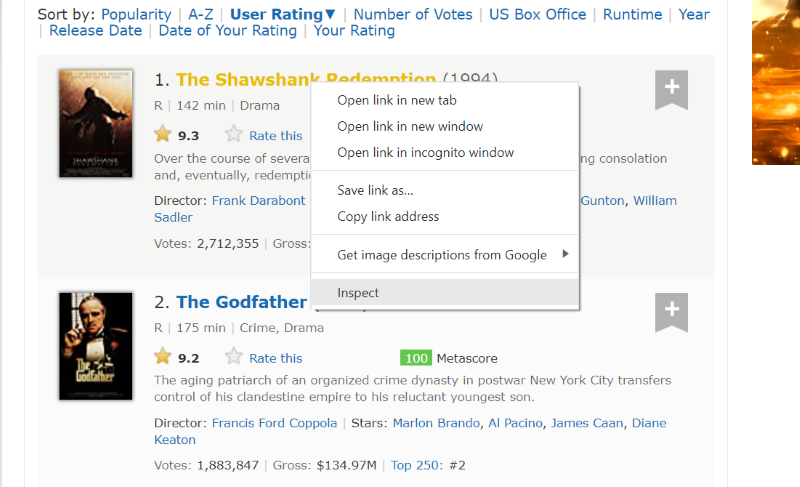
La clase «lister-list» contiene todos los datos relacionados con las películas más vistas como subdivisiones en etiquetas div sucesivas.
En el script HTML de cada ficha de película, bajo la clase’ lister-item mode-advanced’, tenemos una etiqueta ‘h3’ que almacena el nombre de la película, el rango y el año de estreno, como se destaca en la imagen inferior.
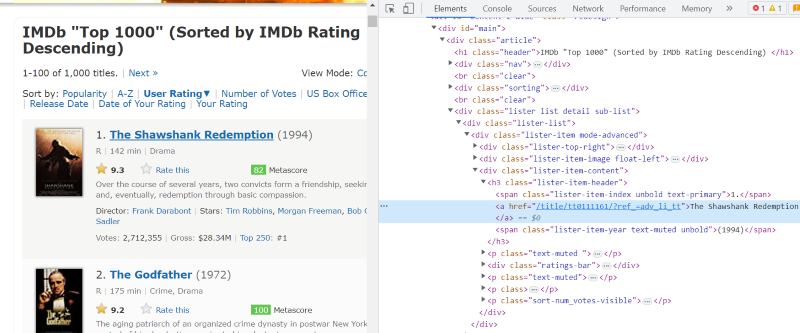
Nota: El método » find » de beautiful Soup busca la primera etiqueta que coincida con el nombre de entrada que se le ha dado. A diferencia de » find«, el método «find_all » busca todas las etiquetas que coinciden con la entrada dada.
Paso 4: Puede utilizar los métodos » find» y «find_all» para guardar el script HTML del nombre, rango y año de cada película en una variable de lista.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')Paso 5: Recorra en bucle la lista de películas almacenada en la variable «top_movies « y extraiga el nombre, el rango y el año de cada película en formato de texto de su guión HTML utilizando el código siguiente.
para película en top_películas
nombre_pelicula = pelicula.a.texto
rango = pelicula.span.text.rstrip('.')
año = movie.find('span', attrs={'class': 'lister-item-año text-muted unbold'})
año = año.text.strip('()')
print(movi_name " ", rango " ", año " ")En la captura de pantalla de salida, puede ver la lista de películas con su nombre, rango y año de estreno.
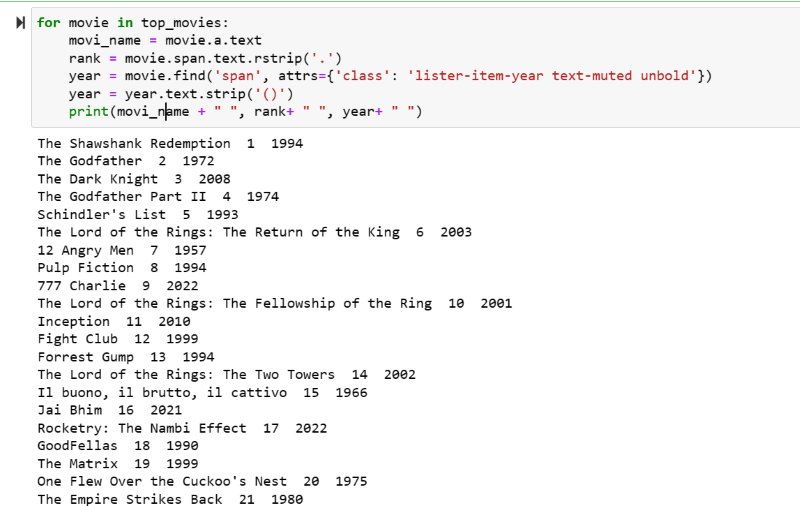
Puede trasladar sin esfuerzo los datos impresos a una hoja de Excel con algo de código python y utilizarlos para su análisis.
Palabras finales
Este post le guía en la instalación de Beautiful Soup para el web scraping. Además, los ejemplos de scraping que he mostrado deberían ayudarle a empezar a utilizar Beautiful Soup.
Si está interesado en cómo instalar Beautiful Soup para el web scraping, le recomiendo que consulte esta guía comprensible para saber más sobre el web scraping utilizando Python.