Web scraping es la idea de extraer información de un sitio web y utilizarla para un caso de uso particular.
Digamos que está intentando extraer una tabla de una página web, convertirla en un archivo JSON y utilizar el archivo JSON para construir algunas herramientas internas. Con la ayuda del web scraping, puede extraer los datos que desee dirigiéndose a los elementos específicos de una página web. El web scraping utilizando Python es una opción muy popular ya que Python proporciona múltiples bibliotecas como BeautifulSoup, o Scrapy para extraer datos de manera eficaz.

Tener la habilidad de extraer datos de forma eficaz también es muy importante como desarrollador o científico de datos.
Infórmese sobre estas bibliotecas python para científicos de datos.
Este artículo le ayudará a entender cómo raspar un sitio web de manera eficaz y obtener el contenido necesario para manipularlo según su necesidad. Para este tutorial, utilizaremos el paquete BeautifulSoup. Se trata de un paquete de moda para el scraping de datos en Python.
¿Por qué utilizar Python para el Web Scraping?
Python es la primera opción para muchos desarrolladores a la hora de construir raspadores web. Hay muchas razones por las que Python es la primera opción, pero para este artículo, vamos a discutir tres razones principales por las que Python se utiliza para el raspado de datos.
Biblioteca y apoyo de la comunidad: Hay varias librerías estupendas, como BeautifulSoup, Scrapy, Selenium, etc., que proporcionan grandes funciones para el raspado eficaz de páginas web. Se ha construido un excelente ecosistema para el web scraping, y también porque muchos desarrolladores de todo el mundo ya utilizan Python, puede obtener ayuda rápidamente cuando esté atascado.
Automatización: Python es famoso por sus capacidades de automatización. Se necesita algo más que web scraping si está intentando crear una herramienta compleja que se base en el scraping. Por ejemplo, si quiere construir una herramienta que rastree el precio de los artículos en una tienda en línea, necesitará añadir alguna capacidad de automatización para que pueda rastrear las tarifas diariamente y añadirlas a su base de datos. Python le ofrece la posibilidad de automatizar este tipo de procesos con facilidad.
Visualización de datos: El web scraping es muy utilizado por los científicos de datos. Los científicos de datos a menudo necesitan extraer datos de páginas web. Con bibliotecas como Pandas, Python simplifica la visualización de datos a partir de datos sin procesar.
Bibliotecas para Web Scraping en Python
Existen varias bibliotecas disponibles en Python para simplificar el raspado web. Vamos a discutir aquí las tres bibliotecas más populares.
#1. BeautifulSoup
Una de las bibliotecas más populares para el web scraping. BeautifulSoup lleva ayudando a los desarrolladores a raspar páginas web desde 2004. Proporciona métodos sencillos para navegar, buscar y modificar el árbol de análisis sintáctico. La propia Beautifulsoup también se encarga de la codificación de los datos entrantes y salientes. Está bien mantenido y cuenta con una gran comunidad.
#2. Scrapy
Otro framework popular para la extracción de datos. Scrapy tiene más de 43000 estrellas en GitHub. También se puede utilizar para scrapear datos de APIs. También tiene algunas interesantes ayudas integradas, como el envío de correos electrónicos.
#3. Selenium
Selenium no es principalmente una biblioteca de web scraping. En su lugar, es un paquete de automatización del navegador. Pero podemos ampliar fácilmente sus funcionalidades para el raspado de páginas web. Utiliza el protocolo WebDriver para controlar diferentes navegadores. Selenium lleva en el mercado casi 20 años. Pero utilizando Selenium, puede automatizar y raspar fácilmente datos de páginas web.
Desafíos con Python Web Scraping
Uno puede enfrentarse a muchos retos cuando intenta raspar datos de páginas web. Hay problemas como redes lentas, herramientas anti-scraping, bloqueo basado en IP, bloqueo captcha, etc. Estas cuestiones pueden causar grandes problemas cuando se intenta raspar un sitio web.
Pero puede sortear eficazmente los desafíos siguiendo algunos caminos. Por ejemplo, en la mayoría de los casos, una dirección IP es bloqueada por un sitio web cuando hay más de una cierta cantidad de solicitudes enviadas en un intervalo de tiempo específico. Para evitar el bloqueo de IP, tendrá que codificar su raspador de forma que se enfríe después de enviar solicitudes.

Los desarrolladores también suelen colocar trampas honeypot para los raspadores. Estas trampas suelen ser invisibles a los ojos humanos pero pueden ser rastreadas por un scraper. Si está rastreando un sitio web que pone este tipo de trampas honeypot, tendrá que codificar su scraper en consecuencia.
El captcha es otro grave problema de los raspadores. Hoy en día, la mayoría de los sitios web utilizan un captcha para proteger el acceso de los robots a sus páginas. En tal caso, puede que necesite utilizar un solucionador de captchas.
Raspado de un sitio web con Python
Como ya hemos comentado, utilizaremos BeautifulSoup para raspar un sitio web. En este tutorial, rasparemos los datos históricos de Ethereum desde Coingecko y guardaremos los datos de la tabla como un archivo JSON. Pasemos a construir el scraper.
El primer paso es instalar BeautifulSoup y Requests. Para este tutorial, utilizaré Pipenv. Pipenv es un gestor de entorno virtual para Python. También puede utilizar Venv si lo desea, pero yo prefiero Pipenv. Discutir Pipenv está más allá del alcance de este tutorial. Pero si desea aprender cómo se puede utilizar Pipenv, siga esta guía. O, si quiere entender los entornos virtuales de Python, siga esta guía.
Lance el shell Pipenv en el directorio de su proyecto ejecutando el comando pipenv shell. Lanzará un subshell en su entorno virtual. Ahora, para instalar BeautifulSoup, ejecute el siguiente comando:
pipenv install beautifulsoup4Y, para instalar requests, ejecute el comando similar al anterior
pipenv install requestsUna vez completada la instalación, importe los paquetes necesarios en el archivo principal. Cree un archivo llamado main.py e importe los paquetes como se indica a continuación:
from bs4 import BeautifulSoup
import requests
import jsonEl siguiente paso es obtener el contenido de la página de datos históricos y analizarlo utilizando el analizador HTML disponible en BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')En el código anterior, se accede a la página utilizando el método get disponible en la biblioteca requests. A continuación, el contenido analizado se almacena en una variable llamada soup.
Ahora empieza la parte del scraping original. En primer lugar, tendrá que identificar correctamente la tabla en el DOM. Si abre esta página y la inspecciona utilizando las herramientas para desarrolladores disponibles en el navegador, verá que la tabla tiene estas clases table table-striped text-sm text-lg-normal.
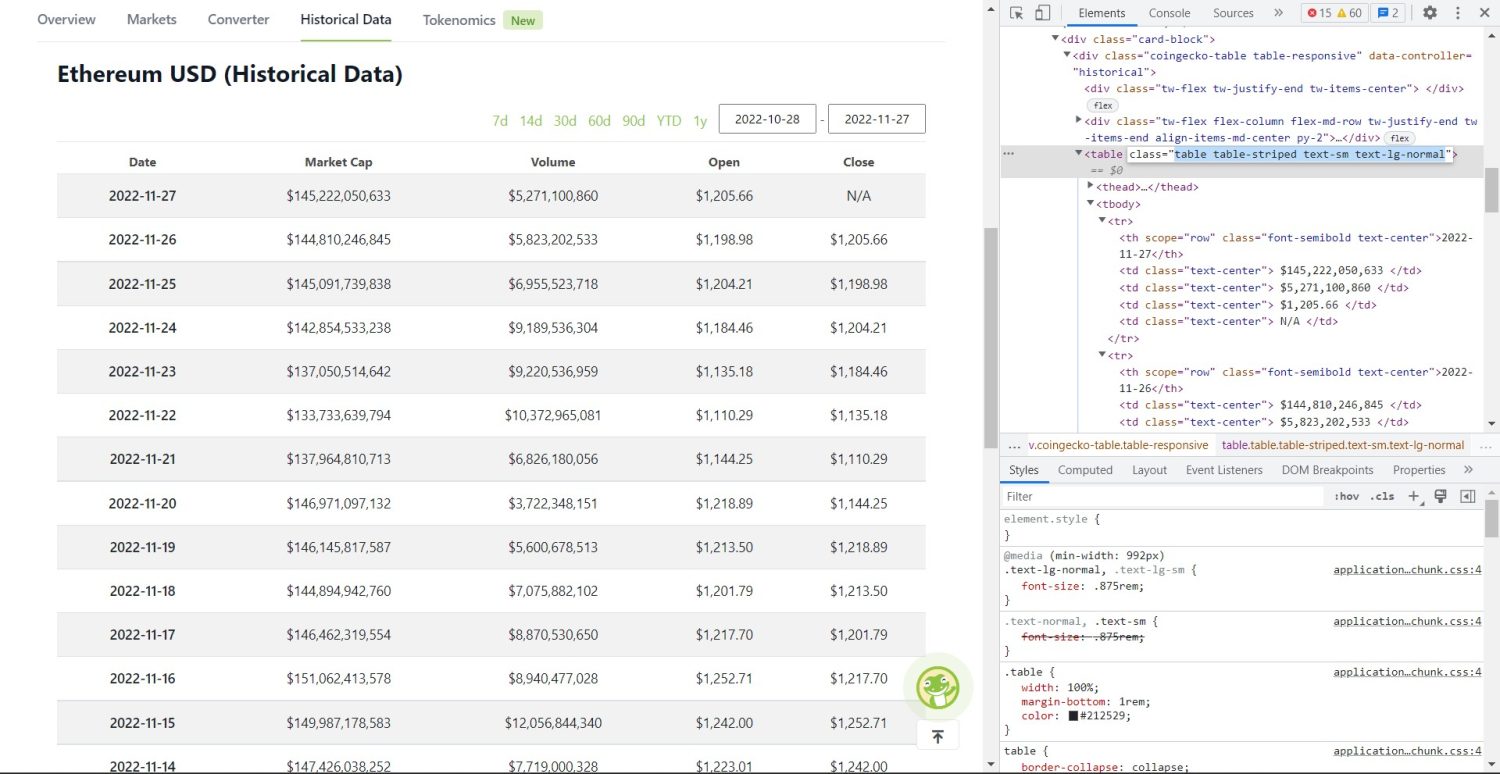
Para orientar correctamente esta tabla, puede utilizar el método find.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
datos_tabla = tabla.find_all('tr')
encabezados_tabla = []
for th in datos_tabla[0].find_all('th'):
table_headings.append(th.text)En el código anterior, primero se encuentra la tabla utilizando el método soup.find y, a continuación, utilizando el método find_all, se buscan todos los elementos tr dentro de la tabla. Estos elementos tr se almacenan en una variable llamada datos_tabla. La tabla tiene algunos elementos th para el título. Se inicializa una nueva variable llamada table_headings para guardar los títulos en una lista.
A continuación, se ejecuta un bucle for para la primera fila de la tabla. En esta fila, se buscan todos los elementos con th y su valor de texto se añade a la lista table_headings. El texto se extrae utilizando el método text. Si ahora imprime la variable table_headings, podrá ver la siguiente salida:
['Fecha', 'Capitalización bursátil', 'Volumen', 'Apertura', 'Cierre']El siguiente paso es raspar el resto de los elementos, generar un diccionario para cada fila y, a continuación, anexar las filas en una lista.
para tr en datos_tabla
th = tr.find_all('th')
td = tr.find_all('td')
datos = {}
for i in range(len(td)):
data.update({encabezados_tabla[0]: td[0].text})
data.update({encabezados_tabla[i 1]: td[i].text.replace('\n', '')})
si datos.__len__() > 0:
detalles_tabla.append(datos)Esta es la parte esencial del código. Para cada tr en la variable table_data, primero se buscan los th elementos. Los elementos th son la fecha que aparece en la tabla. Estos elementos th se almacenan dentro de una variable th. Del mismo modo, todos los elementos td se almacenan en la variable td.
Se inicializa un diccionario de datos vacío. Tras la inicialización, recorremos en bucle el rango de elementos td. Para cada fila, primero, actualizamos el primer campo del diccionario con el primer elemento de th. El código encabezados_tabla<x><x><x><x>[0]</x></x></x></x>: th<x><x><x><x>[0]</x></x></x></x>. text asigna un par clave-valor de fecha y el primer elemento th.
Tras inicializar el primer elemento, se asignan los demás mediante data.update({table_headings[i 1]: td<x>[i]</x>.text.replace('\\n', '')}). Aquí, el texto de los elementos td se extrae primero mediante el método text y, a continuación, se sustituye todo \n mediante el método replace. A continuación, se asigna el valor al elemento i 1de la lista table_headings porque el elemento ithya está asignado.
A continuación, si la longitud del diccionario de datos es superior a cero, anexamos el diccionario a la lista detalles_tabla. Puede imprimir la lista table_details para comprobarlo. Pero nosotros escribiremos los valores en un archivo JSON. Echemos un vistazo al código para ello,
con open('tabla.json', 'w') como f:
json.dump(detalles_tabla, f, sangría=2)
print('Datos guardados en un archivo json...')Aquí estamos utilizando el método json.dump para escribir los valores en un archivo JSON llamado tabla .json. Una vez completada la escritura, imprimimos Data saved to json file… en la consola.
Ahora, ejecute el archivo utilizando el siguiente comando,
python run main.pyDespués de algún tiempo, podrá ver el texto Data saved to JSON file… en la consola. También verá un nuevo archivo llamado table.json en el directorio de archivos de trabajo. El archivo tendrá un aspecto similar al siguiente archivo JSON:
[
{
"Fecha": "2022-11-27",
"Capitalización bursátil": "$145,222,050,633",
"Volumen": "$5,271,100,860",
"Apertura": "$1,205.66",
"Cierre": "N/A"
},
{
"Fecha": "2022-11-26",
"Capitalización bursátil": "$144,810,246,845",
"Volumen": "$5,823,202,533",
"Apertura": "$1,198.98",
"Cierre": "$1,205.66"
},
{
"Fecha": "2022-11-25",
"Capitalización bursátil": "$145,091,739,838",
"Volumen": "$6,955,523,718",
"Apertura": "$1,204.21",
"Cierre": "$1,198.98"
},
// ...
// ...
]Ha implementado con éxito un raspador web utilizando Python. Para ver el código completo, puede visitar este repositorio de GitHub.
Conclusión
En este artículo se discutió cómo se puede implementar un simple scrape en Python. Discutimos cómo se podría utilizar BeautifulSoup para raspar datos rápidamente desde el sitio web. También discutimos otras bibliotecas disponibles y por qué Python es la primera opción para muchos desarrolladores para raspar sitios web.