Los datos están en el centro de algunas de las decisiones más importantes que toman las empresas modernas, y la minería de datos es una técnica eficaz para ayudarle a conseguirlo.
Todas las empresas manejan un volumen abrumador de datos que, si se utilizan de la forma adecuada, pueden aportar muchos beneficios a su organización.
Aquí es donde la minería de datos resulta útil.
Puede ayudar a las empresas a optimizar su eficacia operativa, reducir costes y tomar decisiones con conocimiento de causa.
Y usted puede realizar la minería de datos de manera eficiente utilizando el software de minería de datos. Le ayudará a acelerar el proceso y le ahorrará tiempo que podrá dedicar a utilizar los datos obtenidos.
Hablemos más sobre la minería de datos y el mejor software de minería de datos que puede probar.
¿Qué es la minería de datos?

La minería de datos se refiere a un proceso de búsqueda, extracción y evaluación de datos. Los datos pueden ser patrones gráficos textuales como la caligrafía, figuras literarias y lingüísticas, estadísticas, etc.
La minería de datos se originó en el campo de la lingüística computacional en el subcampo de la informática, la lingüística, las ciencias del arte y la estadística matemática.
Su objetivo es extraer datos mediante programas informáticos, análisis y métodos inteligentes de conjuntos de datos, documentar los resultados del análisis y reestructurar esta información para poder extraer conclusiones significativas.
Aparte del análisis de textos, la minería de datos también implica la gestión de datos, la gestión de bases de datos y la ingeniería de bases de datos. La gestión de datos comienza con el preprocesamiento de datos, la creación de modelos de datos y el procesamiento de datos con inferencias estadísticas estrictas y no estrictas.
¿Cómo funciona?
La extracción de datos implica varios procesos, empezando por la comprensión de los requisitos de la empresa en cuanto a por qué necesita extraer datos y utilizarlos.
El proceso se divide en tres fases principales: preprocesamiento de datos, extracción de datos y resultados en validación.
Preprocesamiento de datos
El preprocesamiento de los datos es necesario para comprender las variaciones en los conjuntos de datos antes de que pueda tener lugar la minería propiamente dicha.
Dado que la minería de datos puede descubrir patrones útiles presentes en los conjuntos de datos, los datos objetivo deben ser lo suficientemente masivos como para contener dichos patrones. Además, este conjunto de datos debe ser lo suficientemente conciso para que pueda realizar la minería de datos en el plazo de tiempo requerido.
Por lo tanto, antes de empezar a minar datos, debe reunir un gran volumen de conjuntos de datos objetivo que puede obtener de un almacén de datos. A continuación, debe limpiar esos datos para eliminar las pelusas innecesarias y la información que falta.
Extracción de datos
Una vez reunidos los datos de destino, comienza el proceso real de minería de datos. Implica seis pasos principales: detección de anomalías, modelado de dependencias, agrupación, clasificación, regresión y resumen.
- Detección de anomalías: Consiste en identificar conjuntos de datos irregulares que pueden ser útiles o que contienen algunos errores.
- Modelado de dependencias: En esta etapa se encuentra la relación entre diferentes variables. También se conoce como aprendizaje de reglas de asociación o análisis de la cesta de la compra.
- Agrupación: Consiste en descubrir estructuras y grupos en conjuntos de datos que parecen similares.
- Clasificación: Consiste en clasificar los datos en función de determinados parámetros.
- Regresión: Descubre relaciones entre conjuntos de datos o datos con el fin de encontrar una función que pueda modelar los datos con el menor error posible.
- Resumen: Aquí es donde se visualizan los datos y se generan informes para proporcionar una representación compacta y más significativa de los datos extraídos.
Validación de resultados
Este es el paso final del descubrimiento de conocimientos a partir de los datos recopilados para verificar los patrones generados en la minería de datos.
No todos los patrones descubiertos por los algoritmos de extracción de datos tienen por qué ser válidos. De ahí que este paso sea crucial. Se realiza sobre un conjunto de datos de prueba en el que se aplican los patrones descubiertos. A continuación, el resultado resultante se pone en comparación con el resultado deseado.
Si los patrones cumplen los estándares deseados, los patrones aprendidos se interpretan y se convierten en conocimiento significativo. Pero si no cumple los estándares, hay que reevaluar los resultados realizando los cambios necesarios en las etapas de preprocesamiento y minería de datos.
¿Por qué es necesaria la minería de datos?

La minería de datos es útil para el análisis de datos y la inteligencia empresarial para ayudar a las empresas a obtener un conocimiento más profundo sobre su organización, clientes, competidores e industria. Algunos de los usos de la minería de datos son
- Ventas y marketing: Las empresas recopilan información sobre sus clientes objetivo para optimizar sus esfuerzos de ventas y marketing junto con sus productos y servicios.
- Educación: Las instituciones educativas pueden utilizar la minería de datos para extraer datos de los estudiantes y utilizarlos para mejorar la calidad de la educación.
- Detección de fraudes: Las empresas de SaaS, los bancos y otras organizaciones pueden utilizar la minería de datos para observar anomalías en su postura de seguridad y prevenir ciberataques.
- Operaciones: Las empresas pueden utilizar la minería de datos para optimizar sus operaciones, reducir costes y tomar decisiones informadas.
Hablemos ahora de algunos de los mejores software de minería de datos.
RapidMiner Studio
Obtenga una plataforma completa de minería de datos con automatización total y diseño visual del flujo de trabajo de RapidMiner Studio. Ayuda a automatizar y acelerar el proceso de creación de modelos predictivos con la ayuda de una interfaz visual de arrastrar y soltar.
Obtendrá más de 1500 funciones y algoritmos que garantizan el mejor modelo en cada caso de uso. RapidMiner Studio ofrece modelos preconstruidos para el mantenimiento predictivo, la pérdida de clientes, la detección de fraudes, etc.
RapidMiner le permite crear conexiones «apuntar y hacer clic» con almacenes de datos empresariales, almacenamiento en la nube, redes sociales, aplicaciones empresariales, lagos de datos y bases de datos. Los principiantes también encontrarán recomendaciones proactivas en cada paso para proceder.

Ejecute ETL y preparación de datos dentro de la base de datos para mantener los datos optimizados para el análisis. Comprenda las tendencias, distribuciones y patrones con histogramas, coordenadas paralelas, gráficos de líneas, gráficos de cajas, gráficos de dispersión, etc., para solucionar rápidamente los problemas de calidad de los datos, incluida la información que falta y los valores atípicos.
Elimine el trabajo duro durante la preparación de los datos con RapidMiner Turbo Prep y cree modelos de aprendizaje automático impactantes y valiosos rápidamente sin escribir una sola línea de código. Revelará el rendimiento real del modelo antes de pasar a producción.
Además, cree flujos de trabajo visuales de minería de datos fáciles de explicar y de entender y también despliegue en la plataforma modelos que contengan o estén basados en código.
Integre RapidMiner con aplicaciones existentes como Python y R. Descargue las últimas funcionalidades proporcionadas por la comunidad y añada nuevas capacidades a través de su mecanismo de extensión.
Teradata
Experimente datos, perspectivas y resultados con Teradata Vantage. Es una plataforma multi-nube conectada que unifica todo para la analítica empresarial.
Teradata ayuda a impulsar su negocio permitiendo un ecosistema de análisis de datos empresariales, inteligencia predictiva y proporcionando respuestas procesables. Ofrece un enfoque híbrido para satisfacer las demandas de una empresa moderna.
Esta plataforma multi-nube le da la portabilidad y flexibilidad para desplegar en cualquier lugar, como en las instalaciones y nubes públicas (Azure, AWS, Google Cloud). Los equipos de expertos de Teradata pueden ayudarle a aprovechar los datos para optimizar sus operaciones empresariales y conseguir un valor asombroso.

Consulte su inventario con Teradata en tiempo real y asegúrese de que todo funciona correctamente sin preocuparse por el tiempo de actividad. Además, Teradata Vantage ofrece innumerable inteligencia para ayudar a construir un negocio de nueva generación.
Además, su escalabilidad multidimensional y de nivel empresarial le permite escalar las dimensiones para manejar sus enormes cargas de trabajo de datos. Haga avanzar su inteligencia artificial y aprendizaje automático para potenciar sus modelos con mejores resultados y calidad.
Ofrezca a sus equipos un software sin código seguro y basado en roles para extraer datos al 100% que puedan respaldar los objetivos clave de su empresa. También es compatible con todos los formatos y tipos de datos, como BSON, Avro, CSV, Parquet, XML y JSON.
Teradata Vantage no le sorprenderá con costes adicionales. La intuitiva consola le permite realizar un seguimiento del uso de los recursos fácilmente para que sepa por lo que está pagando.
Oracle Data Miner
Oracle DataMiner permite a las empresas, los analistas de datos y los científicos de datos ver los datos y trabajar directamente dentro de la base de datos mediante un sencillo editor de flujo de trabajo de arrastrar y soltar.
Oracle Data Miner es una extensión de Oracle SQL Developer que documenta y captura los pasos del flujo de trabajo analítico gráfico que siguen los usuarios para explorar los datos. Además, su flujo de trabajo es sencillo y útil para ejecutar metodologías analíticas y compartir perspectivas.

Esta plataforma genera scripts PL/SQL y SQL y ofrece rápidamente una API para acelerar la implantación de modelos en toda la empresa. También obtendrá una herramienta de flujo de trabajo interactiva para crear, evaluar, modificar, compartir y desplegar metodologías de aprendizaje automático.
Además, obtendrá nodos de gráficos para visualizar datos, como estadísticas de resumen, gráficos de caja, gráficos de dispersión e histogramas. Varios nodos, como los de transformación, filtro de columnas y construcción de modelos, le ayudarán a impulsar su negocio.
Oracle Data Miner puede minimizar el tiempo entre el desarrollo del modelo y su implantación eliminando el movimiento de datos y preservando la seguridad. También capacitará a sus equipos ayudándoles a desarrollar un conjunto de habilidades diversas utilizando algoritmos de aprendizaje automático.
KNIME
Cree y produzca minería de datos con KNIME, que ofrece soporte integral de ciencia de datos para su empresa y mejora la productividad.
Obtendrá dos herramientas complementarias con una plataforma de nivel empresarial. También obtendrá KNIME Analytics, que es una plataforma de código abierto para crear y desplegar modelos comerciales de servidor KNIME y de ciencia de datos.

Además, KNIME es abierto, intuitivo y puede integrar nuevos desarrollos continuamente para comprender y diseñar flujos de trabajo de ciencia de datos accesibles para todos. El servidor KNIME es útil para la colaboración en equipo, la gestión, el despliegue y la automatización.
Si no es un experto, KNIME le ofrece acceso al portal web KNIME. Muchas extensiones han sido diseñadas por el propio KNIME para que pueda hacer algo más. Su comunidad y sus socios también ofrecen extensiones. KNIME se integra con proyectos de código abierto para que nunca le falte de nada.
La plataforma analítica KNIME está disponible en Amazon AWS y Microsoft Azure. KNIME puede ayudarle a acceder, transformar y fusionar todos los datos y analizarlos utilizando sus herramientas preferidas. Apoyará su negocio con amplias prácticas de minería de datos y perspectivas útiles recogidas de los datos.
Descargue KNIME ahora y empiece a crear su primer flujo de trabajo.
Orange
La minería de datos es ahora divertida con Orange, que proporciona visualización de datos y aprendizaje automático de código abierto. Ofrece una variada caja de herramientas para crear flujos de trabajo de análisis de datos de forma fácil y visual.
Puede realizar sencillas visualizaciones y análisis de datos y explorar gráficos de caja, de dispersión, distribuciones estadísticas, etc. Orange le permite profundizar con agrupaciones jerárquicas, mapas térmicos, árboles de decisión, proyecciones lineales y MDS.

Orange puede convertir datos multidimensionales en una visualización 2D con mejores selecciones y clasificaciones de atributos. También encontrará una interfaz gráfica de usuario para centrarse más en el análisis de datos en lugar de perder el tiempo codificando.
Universidades, escuelas y cursos de formación de todo el mundo utilizan Orange por su impresionante oferta. Admite ilustraciones visuales y formación práctica de conceptos de minería de datos. También obtendrá widgets para mejorar aún más su formación.
Además, utilice diferentes complementos para extraer datos de fuentes externas, realizar procesamiento natural y minería de textos, llevar a cabo análisis de redes, inferir conjuntos de ítems y mucho más. Además, los biólogos moleculares y los bioinformáticos pueden utilizar Orange para clasificar varios genes mediante análisis de enriquecimiento y expresión diferencial.
SAS
Revele información valiosa con SAS Enterprise Miner, un sólido software de minería de datos para su empresa. Le ayuda a agilizar todo el proceso para desarrollar modelos rápidos y comprender las relaciones clave.
SAS ofrece múltiples herramientas para desarrollar mejores modelos. Mediante un diagrama de flujo de procesos autodocumentado e interactivo, puede trazar todo el proceso de minería de datos para extraer mejores resultados.
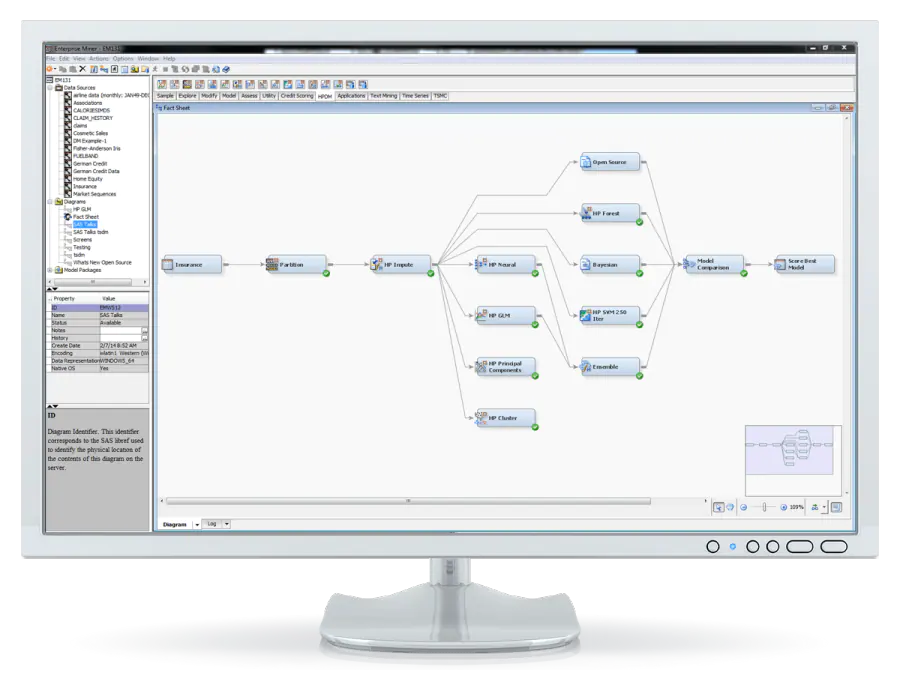
Los expertos en la materia y los usuarios empresariales con conocimientos limitados pueden generar fácilmente sus propios modelos mediante SAS Rapid Predictive Modeler. También puede mejorar la precisión de sus predicciones comparando las evaluaciones y las estadísticas de predicción de los modelos creados con distintos enfoques.
SAS elimina la reescritura manual al permitirle desplegar el modelo automáticamente y generar código de puntuación para todas las etapas. También ofrece una interfaz gráfica de usuario fácil de manejar, procesamiento por lotes, predicciones avanzadas, modelado descriptivo, alto rendimiento, integración de código abierto, opción de despliegue en la nube, procesamiento escalable, etc.
Qlik
Las plataformas de inteligencia deQlik pueden salvar la brecha entre las percepciones, los datos y la acción. Le ofrece una visualización de datos y análisis impulsada por IA, colaborativa, procesable y en tiempo real.
Qlik acelera la ingesta, la replicación de datos y el streaming a través de diversas aplicaciones heterogéneas mainframe, SAP, SaaS y bases de datos. Puede automatizar la ETL y la generación de código de diseño junto con las actualizaciones continuas.
La plataforma le ayudará a reducir el coste, el riesgo y el tiempo de entrega de un almacén de datos ágil en la nube. Puede utilizar enfoques push-down y ELT modernos para convertir, enriquecer, estandarizar, consolidar y unir datos de estructuras heterogéneas.

Además, el servicio nativo en la nube sin código de Qlik agiliza y automatiza sus flujos de trabajo entre Qlik Sense y las aplicaciones SaaS para recomendar acciones a partir de los insights. También obtendrá cuadros de mando fáciles de usar con interactividad y soporte completo para la exploración y búsqueda de forma libre.
Qlik aprovecha la IA para ayudar a toda la analítica, permitiendo a más usuarios obtener un valor extremo de los datos. Con la ayuda de API abiertas, tiene la posibilidad de integrar la analítica en aplicaciones operativas y crear aplicaciones externas.
Si detecta algún cambio repentino en los datos, le indicará inmediatamente la acción pertinente. Qlik también ofrece opciones de despliegue flexibles para proteger las necesidades locales de gobernanza y la ubicación de los datos con múltiples opciones en la nube.
Rattle de Togaware
Rattle es una interfaz gráfica de usuario para la ciencia de datos que utiliza R. Utiliza un conjunto de herramientas de interfaz gráfica de usuario, es decir, RGtk2, que puede instalarse desde el repositorio CRAN de Microsoft.
Conozca las capacidades del software Rattle, que también proporciona una sólida utilización de la línea de comandos. Se
- Muestra resúmenes visuales y estadísticos de los datos
- Transforma los mismos datos para su modelización
- Construye modelos de aprendizaje automático supervisados y no supervisados
- Presenta gráficamente modelos de alto rendimiento
- Puntúa los últimos conjuntos de datos para su despliegue.
Todas las interacciones se capturan como script R, que se ejecuta de nuevo en R de forma independiente con la interfaz Rattle. Puede aprender la herramienta y utilizarla para desarrollar sus habilidades en R. Además, le ayudará en la construcción de modelos iniciales con potentes opciones.
Rattle es una plataforma gratuita de código abierto y su código está disponible en el repositorio git de Bitbucket. Tendrá la libertad de revisar el código, utilizarlo para el propósito que desee y ampliarlo.
Weka
Weka proporciona herramientas para implementar diversos algoritmos de aprendizaje automático, procesar datos y visualizarlos.
Podrá aplicar técnicas de aprendizaje automático a problemas de minería de datos en el mundo real. Sigue unos pasos sencillos:
- Obtendrá datos sin procesar que pueden contener varios campos irrelevantes y valores nulos.
- Utilice las herramientas de preprocesamiento de datos de Weka para limpiar los datos.
- Guarde los datos limpiados en el almacenamiento local para aplicar algoritmos de aprendizaje automático.
- Dependiendo del tipo o modelo de aprendizaje automático, seleccionará entre las opciones disponibles, como clasificar, agrupar o asociar.
- Automatizar el flujo de trabajo
Tiene la libertad de seleccionar cualquier algoritmo proporcionado por Weka y establecer los parámetros deseados para ejecutar el conjunto de datos. Obtenga resultados estadísticos de Weka y una herramienta de visualización para inspeccionar los datos.
Aplica varios modelos sobre el mismo conjunto de datos para comparar los resultados de los modelos y seleccionar el mejor que necesite.
Sisense
La plataforma de análisis API-first, Sisense, ofrece análisis completamente personalizables y de marca blanca siempre que lo necesite.
Transforme su anticuado estilo de trabajo y haga crecer su negocio liberando el poder de los datos. Libere los datos de las instalaciones y de la nube para su análisis y obtenga mejores resultados.

Puede automatizar las acciones de varios pasos en su flujo de trabajo y crear experiencias personalizadas para acelerar los flujos de trabajo. Sisense ofrece una plataforma en la nube abierta que se amplía mediante asociaciones tecnológicas para mejorar la escalabilidad.
Además, puede añadir análisis impulsados por IA en sus flujos de trabajo, aplicaciones, productos y procesos para experimentar la inteligencia en el lugar adecuado y en el momento oportuno para eliminar el flujo lento.
Sea cual sea su nivel de conocimientos, Sisense puede capacitar a todo el mundo para infundir analítica de forma eficaz para tomar mejores decisiones empresariales. También puede diferenciar los productos, capacitar a sus consumidores y crear nuevos flujos con la analítica impulsada por la IA.
InetSoft
La inteligencia de estilo deInetSoft hace que el análisis sea rápido y sencillo. Se trata de una plataforma basada en web que accede a datos de cualquier fuente independientemente del tamaño de la base de datos y maneja conjuntos de datos pequeños para facilitar y agilizar el análisis.
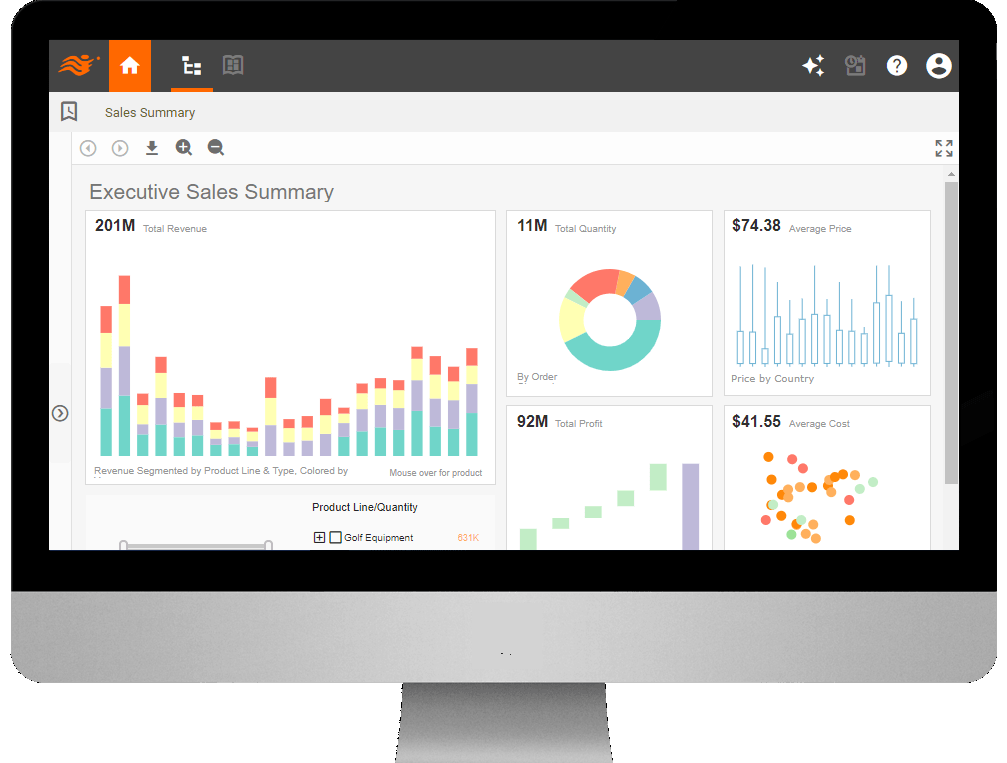
Se trata de uno de los mejores software de minería de datos para que su empresa escarbe en una amplia gama de cachés de datos y obtenga nuevas herramientas de investigación de mercado.
Style Intelligence puede manejar proyectos de big data y está diseñado utilizando una tecnología propia de caché de rejilla de datos basada en los principios de MapReduce que facilitan el Big Data.
Apache Mahout
Apache Mahout es un DSL Scala matemáticamente expresivo y un marco de álgebra lineal distribuida especialmente diseñado para que científicos de datos, estadísticos y matemáticos implementen sus algoritmos.

Se trata de un proyecto de ciencia de datos de código abierto que ayuda a crear algoritmos de aprendizaje automático. Tiene muchas cosas en marcha a varios niveles. Implementa técnicas populares de aprendizaje, como la recomendación, la clasificación y la agrupación.
Los algoritmos de Apache Mahout están escritos sobre Hadoop. Por lo tanto, funciona bien y utiliza la biblioteca de Hadoop para escalar en la nube. Obtendrá un marco de trabajo listo y fácil de usar para sus tareas de minería de datos. También permite que las aplicaciones analicen Big Data de forma rápida y eficaz.
H2O
Consiga la IA de mutaciones genéticas que aporta decisiones inteligentes directamente a los médicos con H2O. Le ayudará a seguir, gestionar y predecir los ingresos relacionados con la COVID-19 en los hospitales.
H2O resuelve muchos problemas complejos de su empresa y acelera las ideas innovadoras con resultados procesables. Puede transformar la forma en que se construye y consume la IA y cuenta con una IA integrada que agiliza y facilita el trabajo.

Además, H2O mantiene la velocidad, la transparencia y la precisión para que pueda construir modelos sin limitaciones. Racionalice sus flujos de trabajo en función del rendimiento monitorizando los datos para tomar una decisión actual.
Con una AppStore de IA intuitiva, puede ofrecer soluciones innovadoras fácilmente a los usuarios finales. Más de 20.000 organizaciones utilizan la tecnología de extracción de datos de H2O. Puede ayudar a optimizar sus operaciones proporcionando perspectivas procesables, operaciones racionalizadas, riesgos reducidos y experiencias personalizadas.
Inicie hoy mismo una prueba gratuita de 90 días y obtenga experiencia práctica con su nube de IA para crear aplicaciones y modelos de primera clase en las instalaciones y en la nube.
Conclusión
La minería de datos es una forma eficaz de recopilar información significativa y ponerla al servicio de su negocio. Le ayudará a optimizar sus operaciones y costes y a tomar mejores decisiones empresariales.
Para ello, utilice el mejor software de minería de datos y siga obteniendo maravillosas perspectivas para su negocio.