
Crear un modelo de aprendizaje automático es relativamente fácil. Crear cientos o miles de modelos e iterar sobre los existentes es difícil.
Es fácil perderse en el caos. Este caos se agrava cuando se trabaja en equipo, ya que ahora hay que estar al tanto de lo que hace cada uno. Poner orden en el caos requiere que todo el equipo siga un proceso y documente sus actividades. Esta es la esencia de MLOps.
¿Qué es MLOps?
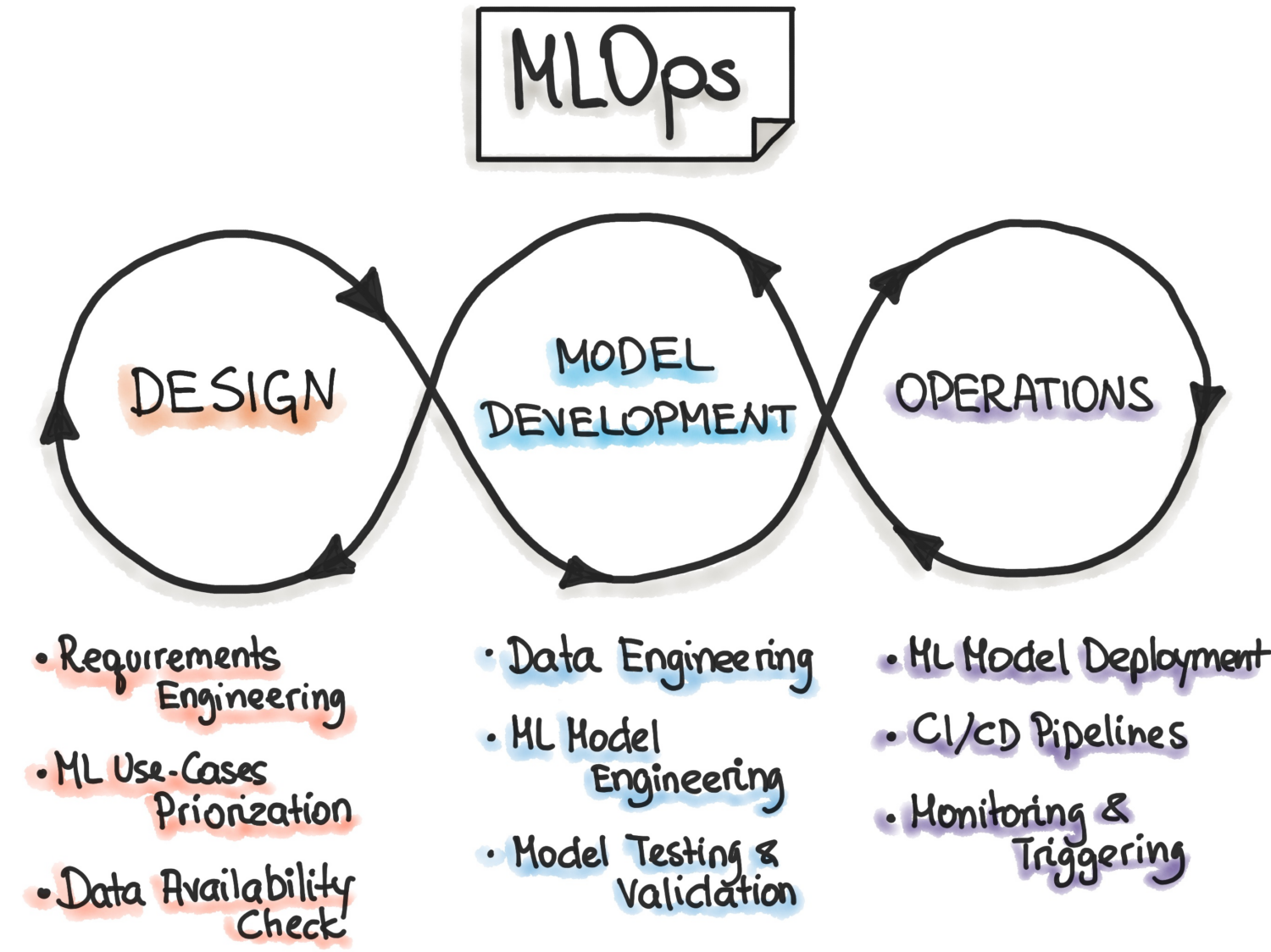
Según MLOps.org, la Operacionalización del Aprendizaje Automático trata de construir un proceso de Desarrollo del Aprendizaje Automático de extremo a extremo para diseñar, construir y gestionar software impulsado por ML reproducible, comprobable y evolucionable. Esencialmente, MLOps son los principios de DevOps aplicados al Aprendizaje Automático.
Al igual que DevOps, la idea clave de MLOps es la automatización para reducir los pasos manuales y aumentar la eficiencia. También, como DevOps, MLOps incluye tanto la Integración Continua (CI) como la Entrega Continua (CD). Además de esas dos, también incluye la Formación Continua (CT). El aspecto adicional de la CT implica volver a entrenar los modelos con nuevos datos y volver a desplegarlos.
MLOps es, por tanto, una cultura de ingeniería que promueve un enfoque metódico del desarrollo de modelos de aprendizaje automático y la automatización de varios pasos del método. El proceso implica principalmente la extracción de datos, el análisis, la preparación, el entrenamiento de modelos, la evaluación, el servicio de modelos y la supervisión.
Ventajas de MLOps
En general, las ventajas de aplicar los principios MLOps son las mismas que las de contar con procedimientos operativos estándar. Las ventajas son las siguientes:
- Un proceso bien definido proporciona una hoja de ruta de todos los pasos cruciales que hay que dar en el desarrollo del modelo. Esto garantiza que no se omita ningún paso crítico.
- Los pasos del proceso que pueden automatizarse pueden identificarse y automatizarse. Esto reduce la cantidad de trabajo repetitivo y aumenta la velocidad del desarrollo. También elimina los errores humanos a la vez que reduce la cantidad de trabajo que hay que hacer.
- Resulta más fácil evaluar el progreso en el desarrollo de un modelo sabiendo en qué fase del pipeline se encuentra el modelo.
- Es más fácil para los equipos comunicarse, ya que existe un vocabulario compartido para los pasos que hay que dar durante el desarrollo.
- El proceso puede aplicarse repetidamente al desarrollo de muchos modelos, proporcionando una forma de gestionar el caos.
Así que, en última instancia, el papel de los MLOps en el aprendizaje automático es proporcionar un enfoque metódico para el desarrollo de modelos que pueda automatizarse en la medida de lo posible.
Plataformas para construir pipelines
Para ayudarle a implementar MLOps en sus pipelines, puede utilizar una de las muchas plataformas que discutiremos aquí. Aunque las características individuales de estas plataformas pueden ser diferentes, esencialmente le ayudarán a hacer lo siguiente:
- Almacenar todos sus modelos junto con los metadatos asociados a los mismos, como configuraciones, código, precisión y experimentos. También incluye las distintas versiones de sus modelos para el control de versiones.
- Almacene los metadatos de los conjuntos de datos, como los datos que se utilizaron para entrenar los modelos.
- Supervise los modelos en producción para detectar problemas como la deriva de los modelos.
- Despliegue modelos en producción.
- Construir modelos en entornos de bajo código o sin código.
Exploremos las mejores plataformas MLOps.
MLFlow

MLFlow es quizás la plataforma de gestión del ciclo de vida del aprendizaje automático más popular. Es gratuita y de código abierto. Ofrece las siguientes características
- seguimiento para registrar sus experimentos de aprendizaje automático, código, datos, configuraciones y resultados finales;
- proyectos para empaquetar su código en un formato fácil de reproducir;
- despliegue para desplegar su aprendizaje automático;
- un registro para almacenar todos sus modelos en un repositorio central
MLFlow se integra con librerías populares de aprendizaje automático como TensorFlow y PyTorch. También se integra con plataformas como Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning y Databricks. También funciona con diferentes proveedores de nube como AWS, Google Cloud y Microsoft Azure.
Azure Machine Learning
AzureMachine Learning es una plataforma de aprendizaje automático de extremo a extremo. Gestiona las diferentes actividades del ciclo de vida de la máquina en su pipeline de MLOPs. Estas actividades incluyen la preparación de datos, la construcción y el entrenamiento de modelos, la validación y el despliegue de modelos, y la gestión y supervisión de los despliegues.
Azure Machine Learning le permite construir modelos utilizando su IDE y marco de trabajo preferidos, PyTorch o TensorFlow.
También se integra con ONNX Runtime y Deepspeed para optimizar su entrenamiento e inferencia. Esto mejora el rendimiento. Aprovecha la infraestructura de IA en Microsoft Azure que combina las GPU NVIDIA y la red Mellanox para ayudarle a crear clústeres de aprendizaje automático. Con AML, puede crear un registro central para almacenar y compartir modelos y conjuntos de datos.
Azure Machine Learning se integra con Git y GitHub Actions para construir flujos de trabajo. También admite una configuración híbrida o multi-nube. También puede integrarlo con otros servicios de Azure como Synapse Analytics, Data Lake, Databricks y Security Center.
Google Vertex AI
Google VertexAI es una plataforma unificada de datos e IA. Le proporciona las herramientas que necesita para crear modelos personalizados y preentrenados. También sirve como solución integral para implantar MLOps. Para facilitar su uso, se integra con BigQuery, Dataproc y Spark para un acceso fluido a los datos durante el entrenamiento.
Además de la API, Google Vertex AI proporciona un entorno de herramientas de bajo código y sin código para que pueda ser utilizado por personas que no son desarrolladores, como analistas de negocio y de datos e ingenieros. La API permite a los desarrolladores integrarla con los sistemas existentes.
Google Vertex AI también permite crear aplicaciones de IA generativa mediante Generative AI Studio. Facilita y agiliza el despliegue y la gestión de la infraestructura. Los casos de uso ideales para Google Vertex AI incluyen garantizar la preparación de los datos, la ingeniería de características, la formación y el ajuste de hiperparámetros, el servicio de modelos, el ajuste y la comprensión de modelos, la supervisión de modelos y la gestión de modelos.
Lea también: Aprenda ingeniería de características para ciencia de datos y ML.
Databricks

Databricks es un lago de datos que le permite preparar y procesar datos. Con Databricks, puede gestionar todo el ciclo de vida del aprendizaje automático, desde la experimentación hasta la producción.
Esencialmente, Databricks proporciona MLFlow gestionado con funciones como el registro de datos y la versión de modelos ML, el seguimiento de experimentos, el servicio de modelos, un registro de modelos y el seguimiento de métricas de anuncios. El registro de modelos le permite almacenar modelos para su reproducibilidad, y el registro le ayuda a realizar un seguimiento de las versiones y de la fase del ciclo de vida en la que se encuentran.
El despliegue de modelos mediante Dataricks puede realizarse con un solo clic, y dispondrá de puntos finales de API REST que podrá utilizar para realizar predicciones. Entre otros modelos, se integra bien con los modelos generativos y de gran lenguaje preentrenados existentes, como los de la biblioteca de transformadores de caras abrazadas.
Dataricks proporciona cuadernos colaborativos Databricks compatibles con Python, R, SQL y Scala. Además, simplifica la gestión de la infraestructura proporcionando clústeres preconfigurados y optimizados para tareas de aprendizaje automático.
AWS SageMaker
AWS S ageMaker es un servicio en la nube de AWS que le proporciona las herramientas que necesita para desarrollar, entrenar e implementar sus modelos de aprendizaje automático. El objetivo principal de SageMaker es automatizar el tedioso y repetitivo trabajo manual que conlleva la creación de un modelo de aprendizaje automático.
Como resultado, le proporciona herramientas para construir una canalización de producción para sus modelos de aprendizaje automático utilizando diferentes servicios de AWS, como las instancias de Amazon EC2 y el almacenamiento de Amazon S3.
SageMaker funciona con Jupyter Notebooks instalados en una instancia EC2 junto con todos los paquetes y bibliotecas comunes necesarios para codificar un modelo de aprendizaje automático. Para los datos, SageMaker es capaz de extraer datos de Amazon Simple Storage Service.
Por defecto, obtiene implementaciones de algoritmos comunes de aprendizaje automático como la regresión lineal y la clasificación de imágenes. SageMaker también viene con un monitor de modelos que proporciona un ajuste continuo y automático para encontrar el conjunto de parámetros que proporcionan el mejor rendimiento para sus modelos. La implementación también se simplifica, ya que puede implementar fácilmente su modelo en AWS como un punto final HTTP seguro que puede monitorizar con CloudWatch.
DataRobot
DataRobot es una popular plataforma de MLOps que permite la gestión en diferentes etapas del ciclo de vida del aprendizaje automático, como la preparación de datos, la experimentación ML, la validación y el gobierno de modelos.
Dispone de herramientas para automatizar la ejecución de experimentos con diferentes fuentes de datos, probar miles de modelos y evaluar los mejores para desplegarlos en producción. Admite la construcción de modelos de distintos tipos de IA para resolver problemas de series temporales, procesamiento del lenguaje natural y visión por ordenador.
Con DataRobot, puede construir utilizando modelos listos para usar, por lo que no tendrá que escribir código. Alternativamente, puede optar por un enfoque «code-first» e implementar modelos utilizando código personalizado.
DataRobot viene con cuadernos para escribir y editar el código. Alternativamente, puede utilizar la API para poder desarrollar modelos en un IDE de su elección. Mediante la interfaz gráfica de usuario, puede realizar un seguimiento de los experimentos de sus modelos.
Ejecutar IA

RunAI intenta resolver el problema de la infrautilización de la infraestructura de IA, en particular de las GPU. Resuelve este problema promoviendo la visibilidad de toda la infraestructura y asegurándose de que se utiliza durante el entrenamiento.
Para ello, Run AI se sitúa entre su software MLOps y el hardware de la empresa. Mientras ocupa esta capa, todos los trabajos de formación se ejecutan utilizando Run AI. La plataforma, a su vez, programa cuándo se ejecuta cada uno de estos trabajos.
No hay ninguna limitación en cuanto a si el hardware tiene que estar basado en la nube, como AWS y Google Cloud, en las instalaciones o en una solución híbrida. Proporciona una capa de abstracción a los equipos de aprendizaje automático al funcionar como una plataforma de virtualización de GPU. Puede ejecutar tareas desde Jupyter Notebook, el terminal bash o PyCharm remoto.
H2O.ai
H2O es una plataforma de aprendizaje automático distribuido de código abierto. Permite a los equipos colaborar y crear un repositorio central de modelos donde los científicos de datos pueden experimentar y comparar diferentes modelos.
Como plataforma de MLOps, H20 ofrece una serie de características clave. En primer lugar, H2O también simplifica el despliegue de modelos en un servidor como punto final REST. Ofrece diferentes temas de despliegue, como la prueba A/B, los modelos Champoion-Challenger y el despliegue sencillo de un solo modelo.
Durante la formación, almacena y gestiona datos, artefactos, experimentos, modelos y despliegues. Esto permite que los modelos sean reproducibles. También permite la gestión de permisos a nivel de grupo y de usuario para gobernar los modelos y los datos. Mientras el modelo se está ejecutando, H2O también proporciona supervisión en tiempo real de la deriva del modelo y otras métricas operativas.
Gradient de Paperspace
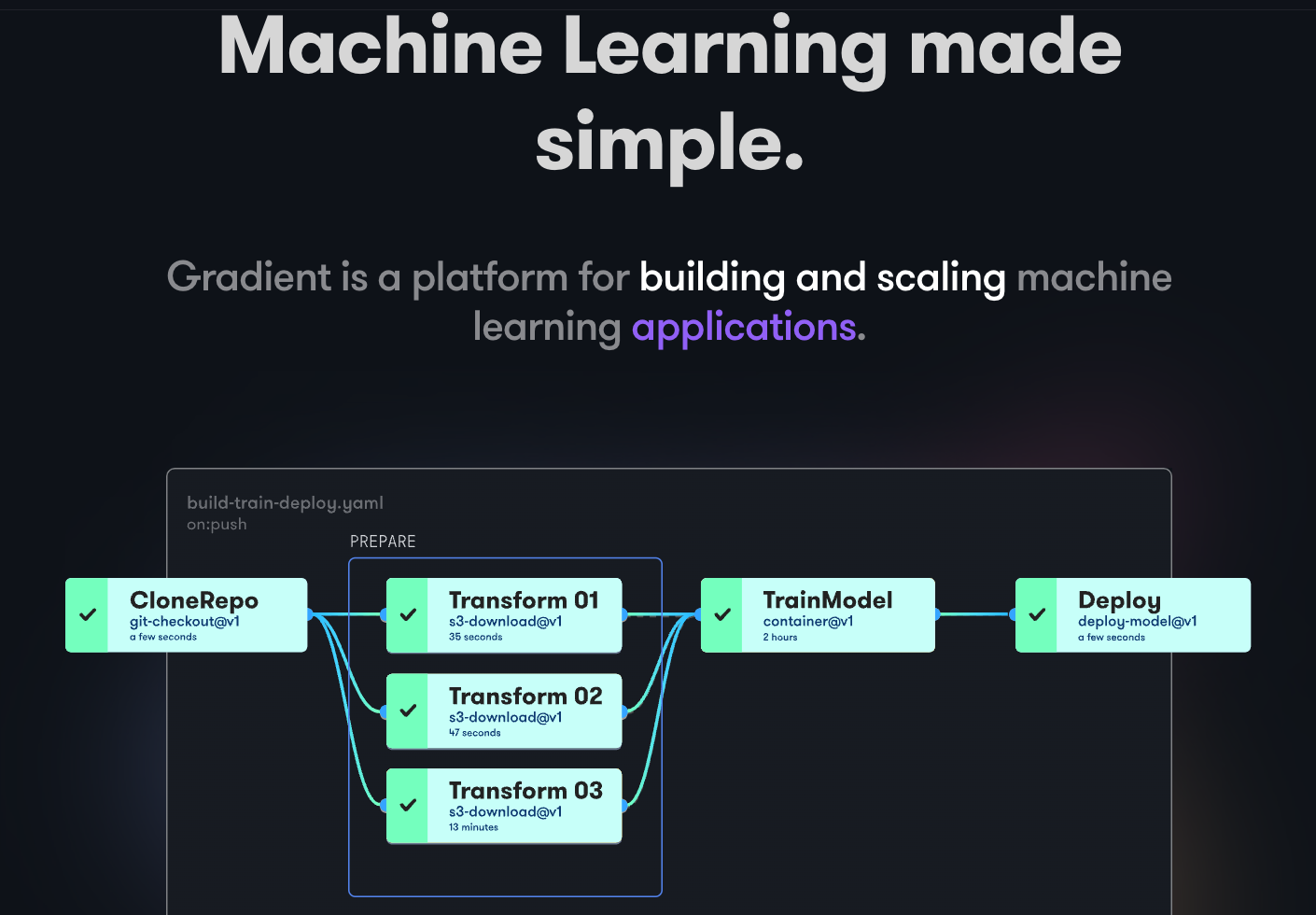
Gradient ayuda a los desarrolladores en todas las fases del ciclo de desarrollo del aprendizaje automático. Proporciona cuadernos basados en el código abierto Jupyter para el desarrollo y el entrenamiento de modelos en la nube utilizando potentes GPU. Esto permite explorar y crear prototipos de modelos rápidamente.
Los pipelines de despliegue pueden automatizarse creando flujos de trabajo. Estos flujos de trabajo se definen describiendo tareas en YAML. El uso de flujos de trabajo hace que la creación de despliegues y el servicio de modelos sean fáciles de replicar y, en consecuencia, escalables.
En conjunto, Gradient proporciona Contenedores, Máquinas, Datos, Modelos, Métricas, Registros y Secretos para ayudarle a gestionar las diferentes etapas del pipeline de desarrollo de modelos de Aprendizaje Automático. Sus pipelines se ejecutan en clusters Gradiet. Estos clusters se encuentran en Paperspace Cloud, AWS, GCP, Azure, o en cualquier otro servidor. Puede interactuar con Gradient usando CLI o SDK programáticamente.
Palabras finales
MLOps es un enfoque potente y versátil para construir, desplegar y gestionar modelos de aprendizaje automático a escala. MLOps es fácil de usar, escalable y seguro, por lo que es una buena opción para organizaciones de todos los tamaños.
En este artículo, cubrimos los MLOPs, por qué es importante implementarlos, qué implica y las diferentes plataformas MLOps populares.
A continuación, puede que desee leer nuestra comparación de Dataricks frente a Snowflake.