Las empresas modernas confían cada vez más en los sistemas integrados en la nube de AWS (Amazon Web Services) para ofrecer soluciones sólidas y escalables. Sin embargo, garantizar un rendimiento óptimo en estos sistemas integrados puede ser una tarea compleja.
Optimizar su sistema en la nube de AWS para obtener la máxima eficiencia puede ayudarle a mejorar el rendimiento, reducir los costes y mejorar la eficacia operativa general.
En este artículo se analizarán estrategias clave, como el equilibrio de carga, el autoescalado, el almacenamiento en caché y las estrategias de carga de datos, para mejorar el rendimiento de los sistemas integrados en la nube de AWS.
Qué es la optimización en la nube de AWS
La optimización en la nube de AWS se refiere a las actividades que mejoran el rendimiento, la eficacia y los costes de funcionamiento de los sistemas y procesos basados en la nube. Debe centrarse en las áreas en las que la mejora puede realizarse con facilidad, garantizando al mismo tiempo la seguridad del sistema existente.

Si el nivel de esfuerzo necesario para la mejora resulta demasiado elevado, ya no se considera optimización. En tales casos, se habla de refactorización del sistema.
La refactorización suele ser un proceso mucho más costoso, que cambia sustancialmente la solución técnica existente porque ya no cumple los requisitos. Por eso debemos planificar las actualizaciones incrementales del sistema de forma que minimicemos esas necesidades de refactorización a lo largo del tiempo.
Así pues, el objetivo final de la optimización del sistema es aplicar estrategias para lograr mejores resultados con unos costes adicionales mínimos. También puede considerar ese proceso como la búsqueda de formas de reducir costes sin comprometer el rendimiento. Puede lograr algunas partes de este objetivo incluso sin cambiar el código fuente.
Por ejemplo, mediante estrategias como el redimensionamiento de instancias o el aprovechamiento de instancias puntuales para cargas de trabajo no críticas. También puede poner en práctica diversas estrategias de optimización de costes y herramientas proporcionadas por AWS, que le darán más pistas útiles de forma proactiva.
Además, puede examinar su utilización actual del modelo de precios de AWS en la arquitectura y realizar cambios para que sea más eficaz. AWS incluso define la optimización de los costes como uno de los pilares de la eficacia del rendimiento de un marco bien arquitecturado.
Todas estas acciones retrasarán o incluso eliminarán por completo la necesidad de refactorizar el sistema a largo plazo.
Es muy importante encontrar el equilibrio adecuado entre la optimización del uso de los recursos y la minimización de los recursos no utilizados que conllevan un ahorro potencial de costes. Ese equilibrio se implementa teniendo en cuenta los patrones de uso de recursos aplicables a su aplicación y la forma en que se utiliza.
Eso significa que siempre puede aumentar las instancias de cálculo, el almacenamiento o los servicios de red para alcanzar los niveles de rendimiento deseados. Sin embargo, siempre debe comprobar si los beneficios de la actualización que ha adquirido son inferiores a la suma de los costes que ha conseguido ahorrar con dicho cambio de arquitectura.
Principales aspectos de la optimización en AWS
Al examinar la optimización en la nube de AWS, algunos de los aspectos son más importantes que otros. Echemos un vistazo a los que, en mi opinión, suelen encabezar la lista de la mayoría de las iniciativas de optimización.
#1. Aplicar el equilibrio de carga cuando sea factible
El equilibrio de carga desempeña un papel crucial en la distribución del tráfico entrante entre múltiples recursos para garantizar un rendimiento óptimo. Al diseñar la arquitectura, debe considerar el equilibrio de carga en tantas partes del sistema como sea posible.
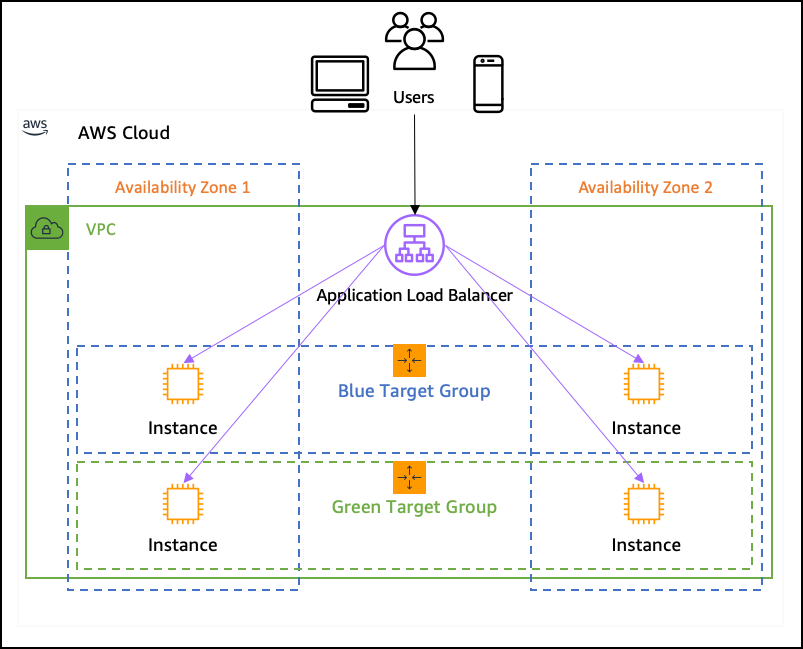
Los sistemas no hacen más que volverse más complejos con el paso del tiempo. No puede predecir cómo evolucionarán en el transcurso de los próximos años. Con las técnicas de equilibrio de la carga, puede preparar mejor la plataforma para ese crecimiento en el futuro.
AWS ofrece servicios de equilibrio de carga elástica (ELB) que distribuyen automáticamente el tráfico entrante entre varias instancias. El equilibrio de la carga ayuda a evitar que un único recurso se vea desbordado, mejorando así el rendimiento del sistema. Ni siquiera tiene por qué costar más, ya que puede permitirse instancias más pequeñas en caso de una instancia grande y potente.
Puede aplicar el equilibrio de carga incluso a nivel de red (independientemente de las propias aplicaciones) utilizando equilibradores de carga de pasarela. Esto repartirá la carga entre varios cortafuegos o componentes de la infraestructura de detección de intrusos, haciendo que toda su plataforma sea más segura.
En AWS, puede diseñar muchas instancias como serverless en lugar de ser instancias estándar de Amazon EC2 (que generan costes constantemente a menos que las apague), lo que significa que esas instancias adicionales no consumen ningún coste si no hay nada que procesar a menos que estén realmente en funcionamiento (lo que significa en caso de aumento de las cargas).
#2. Habilite el autoescalado cuando sea razonable
El autoescalado permite a su sistema ajustar automáticamente su capacidad en función del tráfico entrante. Puede ir en ambos sentidos: hacia arriba y hacia abajo. El Autoescalado de AWS es una funcionalidad específica que no todos los grandes proveedores de nubes tienen, incluso hoy en día.
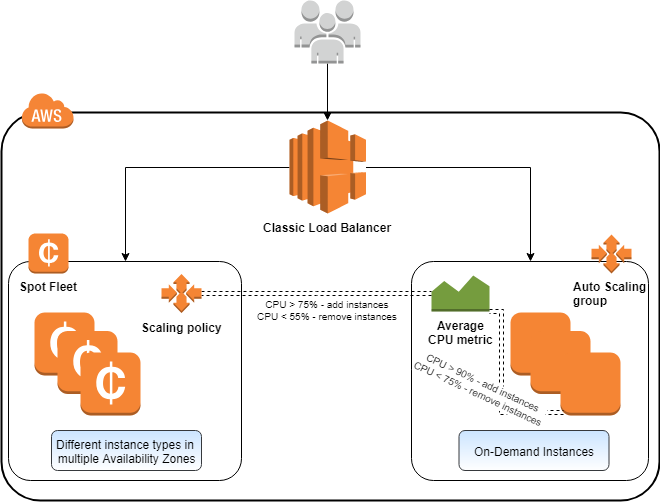
Puede definir políticas de escalado que añadan o eliminen instancias automáticamente en función de condiciones predefinidas. Esto suele referirse al escalado horizontal, cuando usted pone en marcha una o más instancias y luego la añade a la cadena de procesamiento en función de la carga actual.
También es posible el escalado vertical. Es decir, cuando se cambia la configuración de las instancias existentes a especificaciones superiores, como una especificación de CPU, memoria o espacio en disco mayor. Esto es mucho más fácil de hacer en el entorno de la nube, ya que no necesita tratar con ningún hardware físico. Todo el hardware subyacente necesario para ejecutar dicho escalado vertical está gestionado por AWS, por lo que no tiene que preocuparse de ello en absoluto.
A continuación, el escalado (de acuerdo con sus políticas) se ampliará o reducirá en función de la cantidad de tráfico que deba procesarse. Lo bueno es que, una vez configurado, no necesita sentarse a vigilar los procesos de escalado.
Se ajustarán automáticamente. Si define las políticas de forma eficaz y bien adaptada a su volumen de procesamiento habitual, ahorrará en costes de infraestructura en general. Además, no pagará por instancias adicionales cuando no sean necesarias.
Además, no procesará los datos durante demasiado tiempo si se produce un pico de carga. Su sistema gestionará con eficacia las distintas cargas de trabajo informático, mejorando el rendimiento en los momentos de máxima actividad y reduciendo los costes de la nube en los periodos de baja demanda.
#3. Principios del almacenamiento en caché
El almacenamiento en caché es una técnica que almacena los datos a los que se accede con frecuencia en una caché (relacionada con algún servicio específico de la nube), reduciendo la necesidad de recuperarlos de la fuente original repetidamente.
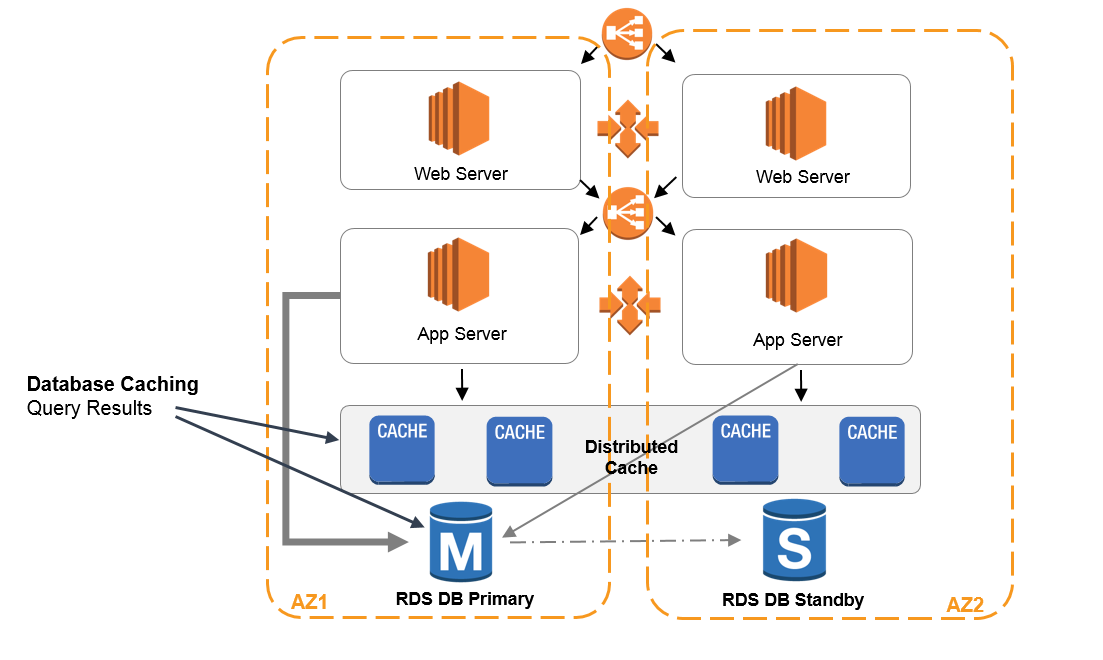
Amazon Web Services contiene el servicio web Amazon ElastiCache. Se trata de un servicio de almacenamiento en caché en memoria totalmente gestionado que admite motores de almacenamiento en caché populares como Redis y Memcached. Puede aprovecharlo e integrarlo en la arquitectura de su sistema en los lugares específicos en los que el usuario extrae los datos con mucha frecuencia.
Con estas estrategias de almacenamiento en caché, puede reducir significativamente el tiempo de respuesta y mejorar el rendimiento general de sus sistemas integrados. Sin embargo, un aspecto que hay que tener muy en cuenta es asegurarse de que los datos que se leen están siempre actualizados con respecto al sistema de origen.
Aunque el almacenamiento en caché permitirá lecturas mucho más rápidas para los usuarios finales, no será muy beneficioso si los datos ya están obsoletos. Para evitarlo, debe tener en cuenta las siguientes propiedades de la memoria caché:
- Una forma de garantizar la frescura de los datos es establecer un tiempo de caducidad o Time-to-Live (TTL) para los datos almacenados en caché. Cuando los datos alcanzan su tiempo de caducidad, la caché se invalida y la siguiente solicitud obtendrá los datos actualizados de la fuente. Si establece el TTL adecuado, podrá equilibrar la compensación entre la frescura de los datos y el rendimiento de la caché.
- La invalidación de la caché es una técnica utilizada para mantener los datos actualizados. Cuando los datos subyacentes cambian, es necesario invalidar la caché para obtener los datos más recientes de la fuente. AWS proporciona varios mecanismos para activar la invalidación de la caché. Por ejemplo, puede programar funciones de AWS Lambda para hacerlo o integrar la invalidación de la caché con el proceso de actualización de datos de su aplicación.
- El patrón cache-aside significa recuperar datos de la caché sólo si existen. Si no, recuperarlos de la fuente y rellenar la caché. Cuando se actualizan los datos, se invalida la caché y las peticiones posteriores obtendrán los datos actualizados de la fuente. Este patrón garantiza que la caché permanezca actualizada a la vez que minimiza el impacto en el rendimiento.
- El patrón cache-through actualiza la caché siempre que hay una actualización de datos en la fuente. Cuando se produce una operación de escritura en la fuente, la caché se actualiza al mismo tiempo. Esto garantiza que la caché siempre tendrá los datos más actualizados, pero puede suponer una sobrecarga adicional debido al requisito de actualizaciones síncronas.
- Mantener la coherencia y consistencia de la caché es crucial para garantizar que los datos permanezcan actualizados. Puede lograrlo implementando mecanismos de sincronización adecuados al actualizar los datos. Así evitará incoherencias entre la caché y la fuente. AWS ofrece servicios como Amazon ElastiCache, que le proporcionará funciones listas para usar como la replicación de la caché y modelos de coherencia para garantizar la integridad de los datos.
Estrategias eficaces de carga de datos
Al integrar sistemas operativos en la nube de AWS, es esencial considerar qué estrategias de carga de datos va a aplicar. Ahora bien, no estamos hablando tanto de la rapidez con la que se actualizan los datos (ya sea en tiempo real o por lotes).
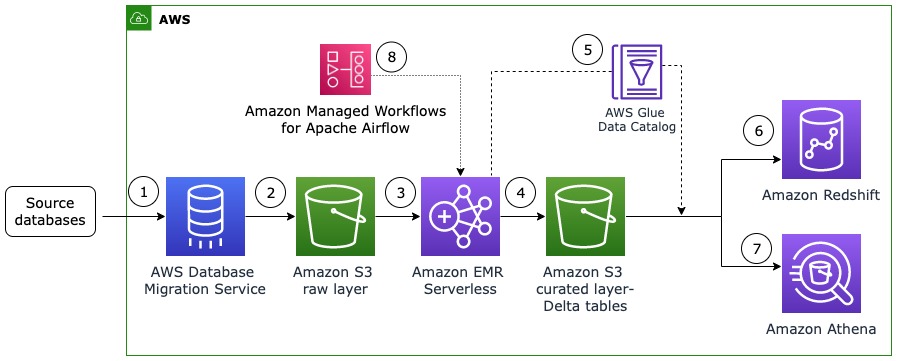
Se trata más bien de cuántos datos necesito procesar cada vez en el lado del destino para obtener resultados relevantes. Normalmente, la elección final es entre carga de datos completa y carga de datos incremental.
#1. Estrategia de carga completa de datos
Una estrategia de carga de datos completa le proporcionará la ventaja de una dificultad de implementación simplista y fácil. Esto es lo que los equipos de proyecto tienden a hacer a menudo.
La ventaja del menor tiempo hasta la producción (y los menores requisitos de coste para la versión inicial) es tan tentadora que tanto el cliente como los equipos de proyecto rara vez están dispuestos a explorar más opciones.
En una estrategia de carga de datos completa, lo que se pretende es transferir todos los datos del sistema de origen al sistema de destino. Este enfoque es muy adecuado para la sincronización inicial de datos o cuando simplemente necesita actualizar todo el conjunto de datos. Sin embargo, puede llevar mucho tiempo y consumir muchos recursos. A veces, sigue siendo la mejor estrategia. Por ejemplo, si los datos de la fuente cambian drásticamente con frecuencia.
Digamos que más del 50% de todos los datos se modifican antes de cada siguiente proceso de carga en su arquitectura. En este caso, tiene todo el sentido aplicar el proceso de carga de datos completo.
Sin embargo, ¿qué pasaría si el sistema fuente sólo cambiara de vez en cuando un pequeño porcentaje de todo el conjunto de datos? ¿Y si programara ejecutar el proceso de carga cada hora o incluso con más frecuencia?
Esos son los casos en los que una carga de datos completa supone una pérdida absoluta de tiempo, un elevado uso de recursos, costes de almacenamiento, potencia de cálculo y dinero, todo al mismo tiempo. Puede que aún así sea más rápido de implementar, pero a largo plazo, será significativamente más costoso de lo que sería una carga incremental.
#2. Estrategia de carga incremental de datos
En una estrategia de carga de datos incremental, lo que desea es transferir sólo los cambios o actualizaciones desde la última ejecución de sincronización. Este enfoque reduce en gran medida la cantidad de datos que deben transferirse entre los sistemas o almacenarse mientras se ejecuta la transferencia.
La estrategia de carga incremental de datos da como resultado una sincronización más rápida y una mejora de las métricas de rendimiento. Es ideal para escenarios en los que se producen actualizaciones frecuentes.
Sin embargo, la carga incremental suele requerir un enfoque mucho más sofisticado. Exige un diseño inteligente de la arquitectura y, a veces, incluso sincronizar bien todos los procesos de conexión necesarios para llevar a cabo los procesos de carga.
También hay muchas más posibilidades de que se pierda alguna parte de los cambios de datos durante los procesos. Esto ocurre sobre todo si el sistema fuente está fuera de su plataforma y de su responsabilidad directa.
En ese caso, obviamente, no puede tener un control total sobre los procesos que ocurren en el sistema fuente. Debe confiar en una buena comunicación con el proveedor externo y asegurarse de actualizar los patrones de integración cada vez que se produzca un cambio en el sistema fuente.
De lo contrario, puede que no esté recibiendo el conjunto completo de los últimos incrementos de datos. Y puede que ni siquiera lo sepa. Eso puede ocurrir si el cambio en el sistema fuente es de tal naturaleza que todas las interfaces e interconexiones existentes siguen funcionando a la perfección a pesar de obtener menos datos de los que deberían ahora.
Ejemplo práctico del proceso de optimización de AWS
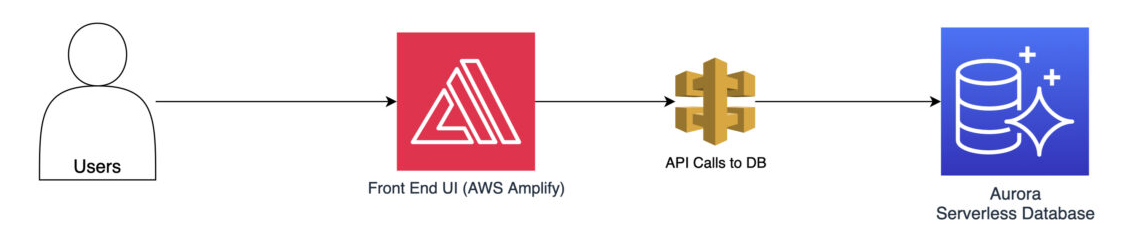
Consideremos un ejemplo del mundo real para ilustrar la aplicación práctica de estas técnicas. Imaginemos un popular sitio web de compras alojado en AWS. Durante las temporadas altas de compras, el sitio web está sometido a una carga de tráfico extremadamente pesada, lo que provoca tiempos de respuesta significativamente más lentos. Potencialmente, puede incluso provocar tiempos de inactividad esporádicos.
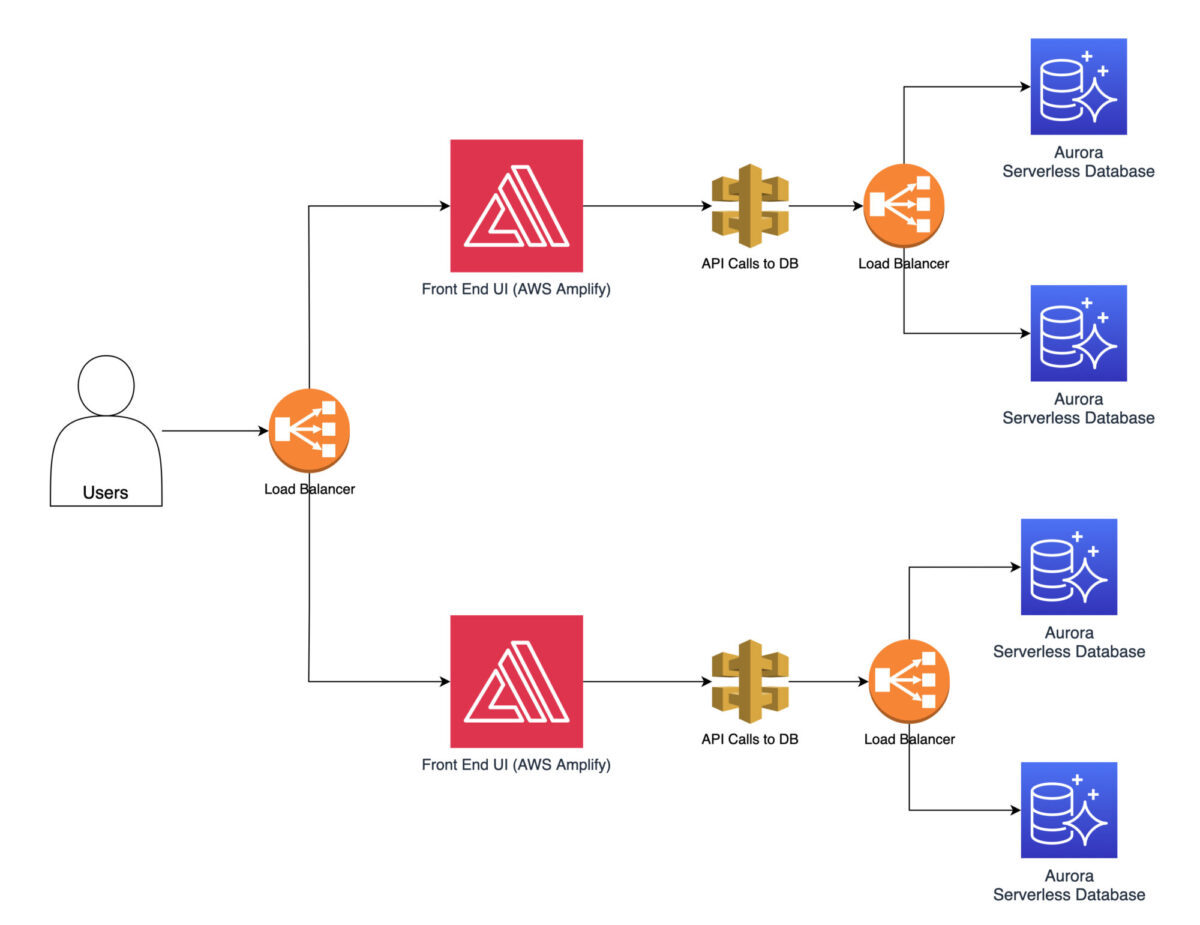
Como primer paso en la optimización del rendimiento, puede implementar el equilibrio de carga utilizando AWS Elastic Load Balancer. Esto garantiza que distribuya el tráfico entrante de manera uniforme entre varias instancias. Esto evita que las instancias se saturen.
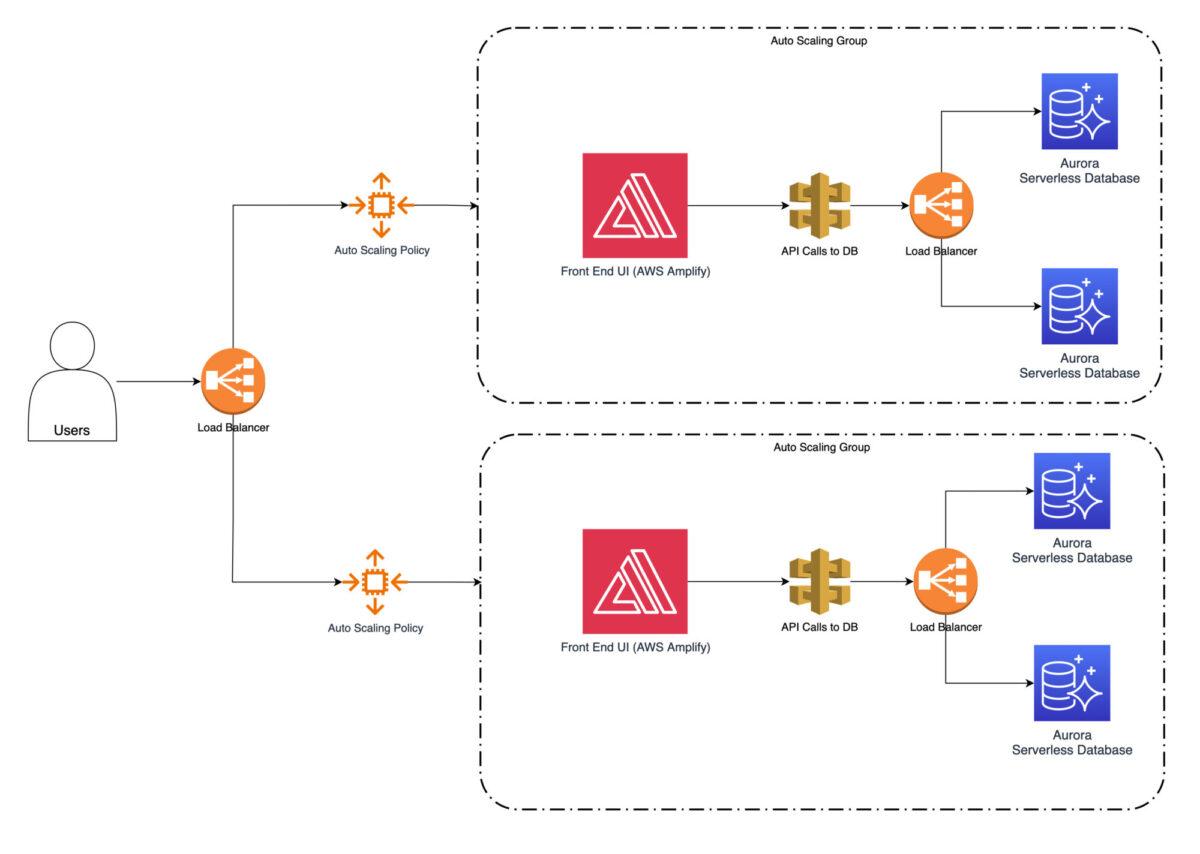
Como siguiente paso, puede configurar el autoescalado para añadir automáticamente más instancias durante las horas punta y eliminarlas durante los periodos de baja demanda. Esto garantiza que el sitio web pueda soportar el aumento de tráfico y mantener un rendimiento óptimo.
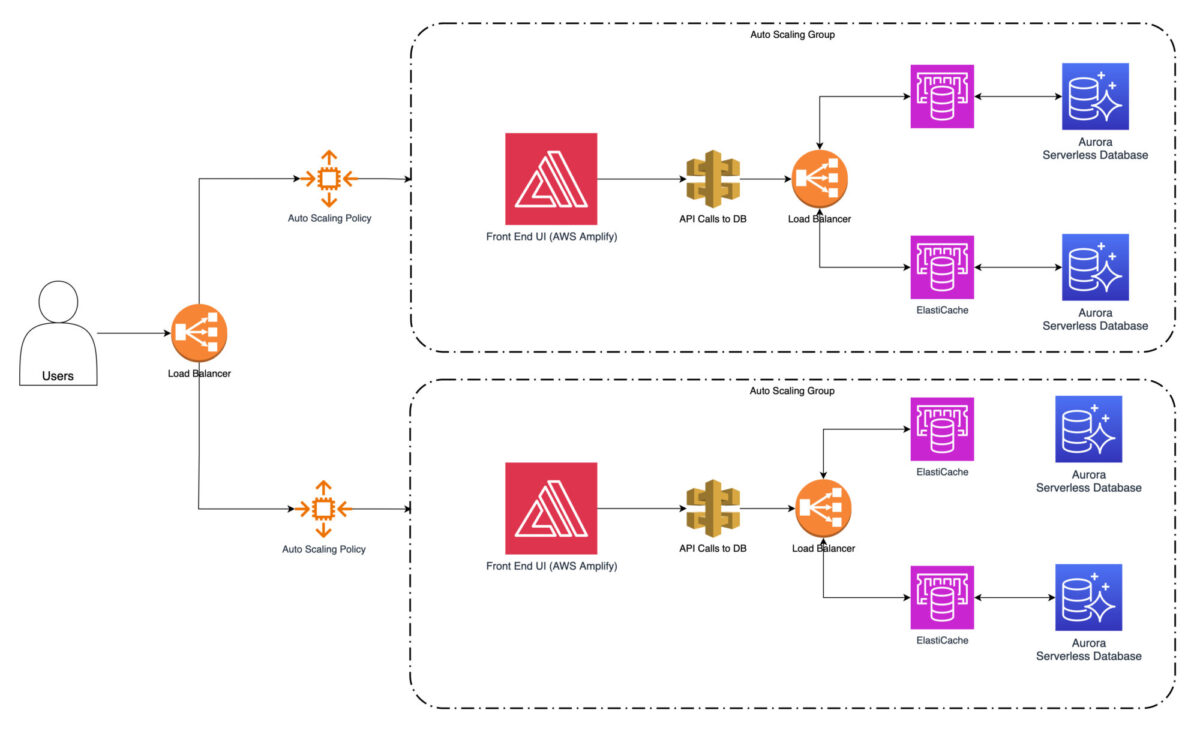
Por último, aún hay lugar para implementar estrategias de almacenamiento en caché mediante Amazon ElastiCache, que reducirán aún más el tiempo necesario para obtener los datos de la fuente. Los datos a los que se accede con frecuencia, como la información sobre productos o las preferencias de los usuarios, pueden almacenarse en caché.
No existe un gran riesgo ni siquiera con los datos actualizados, ya que dicha información sólo cambia muy raramente. Reducirá en gran medida la necesidad de recuperarla repetidamente de los servicios de base de datos. Esto mejora significativamente los tiempos de respuesta y el rendimiento general del sistema operativo.
Reflexiones finales: Cómo maximizar la eficiencia de la integración en la nube de AWS
Optimizar el rendimiento en la integración de sistemas en la nube de AWS y superar los problemas de rendimiento es una tarea continua. A medida que evolucione su plataforma, deberá revisar la arquitectura de AWS con regularidad.
Para mantener un rendimiento óptimo, es aconsejable revisar periódicamente la arquitectura de AWS e implementar técnicas como el equilibrio de carga, el autoescalado, las estrategias de almacenamiento en caché y la selección de la estrategia de carga de datos adecuada.
Las estrategias y técnicas de optimización de AWS comentadas aquí no son sólo teóricas, sino que pueden ponerse en práctica en proyectos del mundo real. Puede utilizar estas estrategias de optimización de AWS para conseguir sistemas integrados de alto rendimiento que cumplan los requisitos del panorama digital en el mundo empresarial actual.