
Los DataFrames son una estructura de datos fundamental en R, que ofrece la estructura, la versatilidad y las herramientas necesarias para el análisis y la manipulación de datos. Su importancia se extiende a diversos campos, como la estadística, la ciencia de datos y la toma de decisiones basada en datos en todos los sectores.
Los DataFrames proporcionan la estructura y la organización necesarias para desbloquear perspectivas y tomar decisiones basadas en datos de forma sistemática y eficiente.
Los DataFrames en R se estructuran como tablas, con filas y columnas. Cada fila representa una observación, y cada columna representa una variable. Esta estructura facilita la organización y el trabajo con los datos. Los DataFrames pueden contener varios tipos de datos, incluyendo números, texto y fechas, lo que los hace versátiles.
En este artículo, explicaré la importancia de los marcos de datos y hablaré de su creación utilizando la función data.frame().
Además, exploraremos métodos para manipular datos y cubriremos cómo crear a partir de archivos CSV y Excel, convertir otras estructuras de datos en marcos de datos y hacer uso de la biblioteca tibble.
He aquí algunas razones clave por las que los DataFrames son cruciales en R:
Importancia de los DataFrames

- Almacenamiento estructurado de datos: Los DataFrames proporcionan una forma estructurada y tabular de almacenar datos, muy parecida a una hoja de cálculo. Este formato estructurado simplifica la gestión y organización de los datos.
- Tipos de datos mixtos: Los DataFrames pueden acomodar diferentes tipos de datos dentro de la misma estructura. Puede tener columnas con valores numéricos, cadenas de caracteres, factores, fechas y mucho más. Esta versatilidad es esencial cuando se trabaja con datos del mundo real.
- Organización de los datos: Cada columna de un DataFrame representa una variable, mientras que cada fila representa una observación o caso. Esta disposición estructurada facilita la comprensión de la organización de los datos, mejorando su claridad.
- Importación y exportación de datos: Los DataFrames permiten importar y exportar datos fácilmente desde diversos formatos de archivo como CSV, Excel y bases de datos. Esta característica agiliza el proceso de trabajo con fuentes de datos externas.
- Interoperabilidad: Los DataFrames son ampliamente compatibles con los paquetes y funciones de R, lo que garantiza la compatibilidad con otras herramientas y bibliotecas estadísticas y de análisis de datos. Esta interoperabilidad permite una integración perfecta en el ecosistema R.
- Manipulación de datos: R ofrece un rico ecosistema de paquetes, siendo
"dplyr» un ejemplo destacado. Estos paquetes facilitan el filtrado, la transformación y el resumen de datos mediante DataFrames. Esta capacidad es crucial para la limpieza y preparación de datos.
- Análisis estadístico: Los DataFrames son el formato de datos estándar para muchas funciones estadísticas y de análisis de datos en R. Puede realizar regresiones, pruebas de hipótesis y muchos otros análisis estadísticos de forma eficiente utilizando DataFrames.
- Visualización: Los paquetes de visualización de datos de R, como
ggplot2, funcionan a la perfección con DataFrames. Esto facilita la creación de tablas y gráficos informativos para la exploración y comunicación de datos.
- Exploración de datos: Los DataFrames facilitan la exploración de datos mediante estadísticas de resumen, visualización y otros métodos analíticos. Esto ayuda a los analistas y científicos de datos a comprender las características de los datos y detectar patrones o valores atípicos.
Cómo crear un DataFrame en R
Hay varias formas de crear un DataFrame en R. A continuación se indican algunos de los métodos más comunes:
#1. Utilizar la función data.frame()
# Cargue la biblioteca necesaria si no está ya cargada
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# install.packages("dplyr")
library(dplyr)
# Establecer una semilla para la reproducibilidad
set.seed(42)
# Cree un DataFrame de ventas de muestra con nombres de productos reales
datos_ventas <- data.frame(
OrderID = 1001:1010,
Producto = c("Portátil", "Smartphone", "Tableta", "Auriculares", "Cámara", "TV", "Impresora", "Lavadora", "Frigorífico", "Horno microondas"),
Cantidad = sample(1:10, 10, replace = TRUE),
Precio = round(runif(10, 100, 2000), 2),
Descuento = round(runif(10, 0, 0,3), 2),
Fecha = sample(seq(as.Fecha('2023-01-01'), as.Fecha('2023-01-10'), by="días"), 10)
)
# Visualizar el DataFrame de ventas
print(datos_ventas)
Entendamos lo que hará nuestro código:
- Primero comprueba si la biblioteca «
dplyr» está disponible en el entorno R. - Si «dplyr» no está disponible, instala y carga la biblioteca.
- A continuación, establece una semilla aleatoria para la reproducibilidad.
- A continuación, crea un DataFrame de ventas de muestra con nuestros datos rellenados.
- Por último, muestra el DataFrame de ventas en la consola para su visualización.
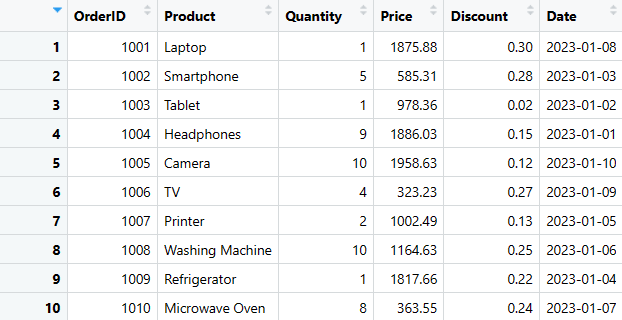
Esta es una de las formas más sencillas de crear un DataFrame en R. También exploraremos cómo extraer, añadir, eliminar y seleccionar columnas o filas específicas, así como la forma de resumir los datos.
Extraer columnas
Existen dos métodos para extraer las columnas necesarias de nuestro marco de datos:
- Para recuperar las tres últimas columnas de un DataFrame en R, puede utilizar la indexación.
- Puede extraer columnas de un DataFrame utilizando el
operador $cuando desee acceder a columnas individuales por su nombre.
Veremos ambos juntos para ahorrar tiempo:
# Extraiga las tres últimas columnas (Descuento, Precio y Fecha) del DataFrame datos_ventas
ultimas_tres_columnas <- datos_de_ventas[, c("Descuento", "Precio", "Fecha")]
# Mostrar las columnas extraídas
print(ultimas_tres_columnas)
############################################# O #########################################################
# Extraer las tres últimas columnas (Descuento, Precio y Fecha) utilizando el operador $
columna_descuento <- datos_ventas$Descuento
columna_precio <- datos_venta$Precio
date_column <- sales_data$Date
# Cree un nuevo DataFrame con las columnas extraídas
ultimas_tres_columnas <- data.frame(Descuento = columna_descuento, Precio = columna_precio, Fecha = columna_fecha)
# Mostrar las columnas extraídas
print(ultimas_tres_columnas)
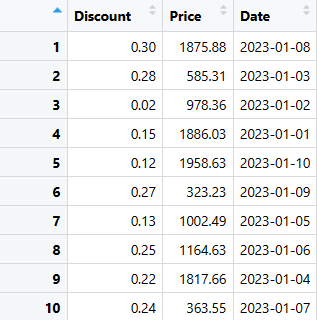
Puede extraer las columnas necesarias utilizando cualquiera de estos códigos.
Extraer filas
Puede extraer filas de un DataFrame en R utilizando varios métodos. He aquí una forma sencilla de hacerlo:
# Extraer filas específicas (filas 3, 6 y 9) del DataFrame last_three_columns
filas_seleccionadas <- ultimas_tres_columnas[c(3, 6, 9), ]
# Mostrar las filas seleccionadas
print(filas_seleccionadas)
También puede utilizar condiciones especificadas:
# Extraer y ordenar las filas que cumplan las condiciones especificadas
filas_seleccionadas <- datos_ventas %>%
filter(Descuento < 0.3, Precio > 100, format(Fecha, "%Y-%m") == "2023-01") %>%
arrange(OrderID) %>%
select(Descuento, Precio, Fecha)
# Mostrar las filas seleccionadas
print(filas_seleccionadas)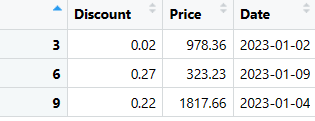
Añadir una nueva fila
Para añadir una nueva fila a un DataFrame existente en R, puede utilizar la función rbind():
# Crear una nueva fila como un marco de datos
nueva_fila <- data.frame(
OrderID = 1011,
Producto = "Cafetera
Cantidad = 2,
Precio = 75,99
Descuento = 0.1
Fecha = as.Date("2023-01-12")
)
# Utilice la función rbind() para añadir la nueva fila al DataFrame
datos_ventas <- rbind(datos_ventas, fila_nueva)
# Muestre el DataFrame actualizado
print(datos_ventas)
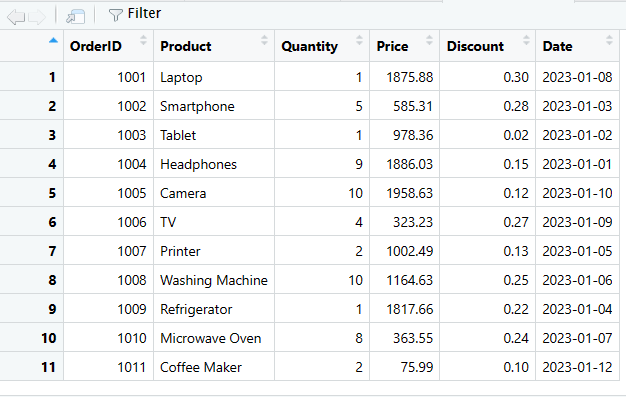
Añadir nueva columna
Puede añadir columnas en su DataFrame con un simple código. Aquí, quiero añadir la columna Método de Pago a mis Datos.
# Crear una nueva columna "PaymentMethod" con valores para cada fila
sales_data$PaymentMethod <- c("Tarjeta de crédito", "PayPal", "Efectivo", "Tarjeta de crédito", "Efectivo", "PayPal", "Efectivo", "Tarjeta de crédito", "Tarjeta de crédito", "Efectivo", "Tarjeta de crédito")
# Muestre el DataFrame actualizado
print(datos_ventas)
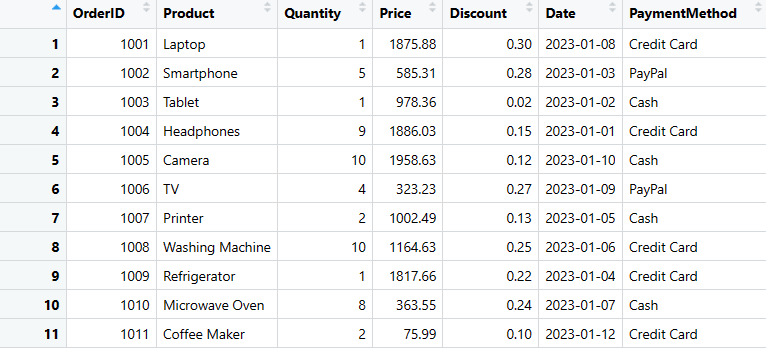
Borrar filas
Si desea eliminar filas innecesarias, este método puede serle útil:
# Identifique la fila a borrar por su OrderID
row_to_delete <- sales_data$OrderID == 1010
# Utilice la fila identificada para excluirla y crear un nuevo DataFrame
datos_ventas <- datos_ventas[!fila_a_borrar, ]
# Muestre el DataFrame actualizado sin la fila eliminada
print(datos_ventas)
Borrar columnas
Puede eliminar una columna de un DataFrame en R utilizando el paquete dplyr.
# install.packages("dplyr")
library(dplyr)
# Elimine la columna "Descuento" utilizando la función select()
datos_ventas <- datos_ventas %>% select(-Descuento)
# Muestre el DataFrame actualizado sin la columna "Descuento
print(datos_ventas)Obtener resumen
Para obtener un resumen de sus datos en R, puede utilizar la función summary(). Esta función proporciona un resumen rápido de las tendencias centrales y la distribución de las variables numéricas de sus datos.
# Obtener un resumen de los datos
resumen_datos <- resumen(datos_ventas)
# Muestre el resumen
print(resumen_datos)
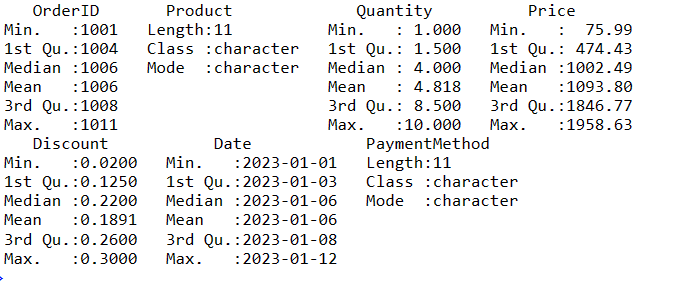
Estos son los diversos pasos que puede seguir para manipular sus datos dentro de un DataFrame.
Pasemos al segundo método para crear un DataFrame.
#2. Crear un R DataFrame a partir de un archivo CSV
Para crear un R DataFrame a partir de un archivo CSV, puede utilizar la función read.csv()
# Leer el archivo CSV en un DataFrame
df <- read.csv("mis_datos.csv")
# Ver las primeras filas del DataFrame
head(df)Esta función lee los datos de un archivo CSV y los convierte. A continuación, puede trabajar con los datos en R según sea necesario.
# Instale y cargue el paquete readr si no está ya instalado
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Leer el archivo CSV en un DataFrame
df <- read_csv("datos.csv")
# Ver las primeras filas del DataFrame
head(df)
puede utilizar el paquete readr para leer un archivo CSV en R. La función read_csv() del paquete readr se utiliza habitualmente para este fin. Es más rápida que el método normal.
#3. Uso de la función as.data.frame()
Puede crear un DataFrame en R utilizando la función as.data. frame (). Esta función le permite convertir otras estructuras de datos, como matrices o listas, en un DataFrame.
He aquí cómo utilizarla:
# Cree una lista anidada para representar los datos
lista_datos <- lista(
OrderID = 1001:1011,
Producto = c("Portátil", "Smartphone", "Tableta", "Auriculares", "Cámara", "Televisor", "Impresora", "Lavadora", "Frigorífico", "Horno microondas", "Cafetera"),
Cantidad = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Precio = c(1875,88, 585,31, 978,36, 1886,03, 1958,63, 323,23, 1002,49, 1164,63, 1817,66, 363,55, 75,99),
Descuento = c(0,3, 0,28, 0,02, 0,15, 0,12, 0,27, 0,13, 0,25, 0,22, 0,24, 0,1),
Fecha = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Tarjeta de crédito", "PayPal", "Efectivo", "Tarjeta de crédito", "Efectivo", "PayPal", "Efectivo", "Tarjeta de crédito", "Tarjeta de crédito", "Efectivo", "Tarjeta de crédito")
)
# Convierta la lista anidada en un DataFrame
datos_ventas <- as.data.frame(lista_datos)
# Visualizar el DataFrame
print(datos_ventas)
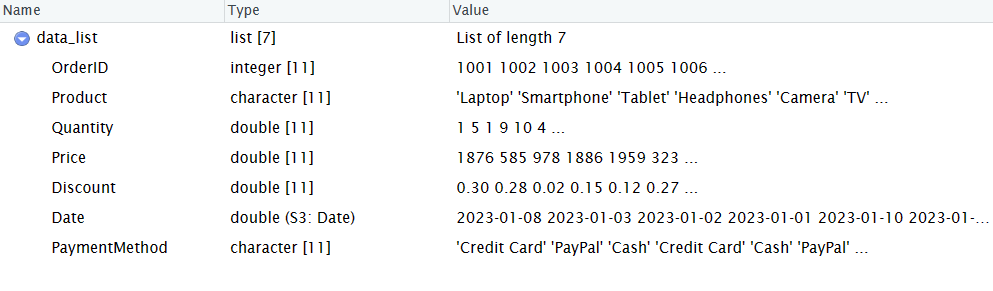
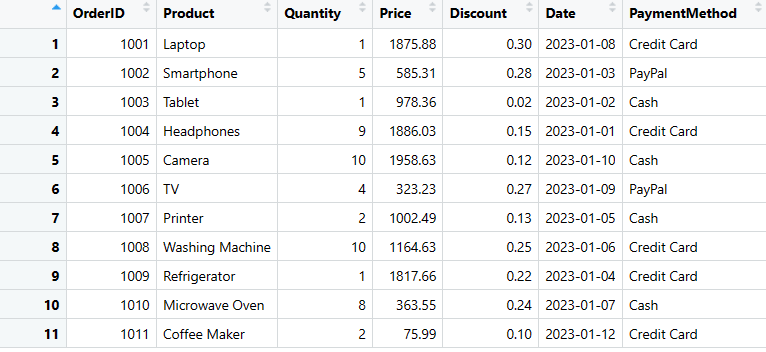
Este método le permite crear un DataFrame sin especificar cada columna una por una y es especialmente útil cuando se dispone de una gran cantidad de datos.
#4. A partir del Marco de Datos existente
Para crear un nuevo DataFrame seleccionando columnas o filas específicas de un DataFrame existente en R, puede utilizar corchetes [] para indexar. Así es como funciona
# Seleccionar filas y columnas
sales_subset <- datos_de_ventas[c(1, 3, 4), c("Producto", "Cantidad")]
# Mostrar el subconjunto seleccionado
print(subconjunto_ventas)
En este código, estamos creando un nuevo DataFrame llamado sales_subset, que contiene filas específicas (1, 3 y 4) y columnas específicas («Producto» y «Cantidad») de los datos_ventas.
Puede ajustar los índices y nombres de las filas y columnas para seleccionar los datos que necesite.

#5. De vector
Un vector es una estructura de datos unidimensional en R que consta de elementos del mismo tipo de datos, incluidos lógicos, enteros, dobles, caracteres, complejos o brutos.
Por otro lado, un R DataFrame es una estructura bidimensional diseñada para almacenar datos en un formato tabular con filas y columnas. Existen varios métodos para crear un R DataFrame a partir de un vector, y a continuación se ofrece un ejemplo de ello.
# Crear vectores para cada columna
OrderID <- 1001:1011
Producto <- c("Portátil", "Smartphone", "Tableta", "Auriculares", "Cámara", "Televisor", "Impresora", "Lavadora", "Frigorífico", "Horno microondas", "Cafetera")
Cantidad <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Precio <- c(1875,88, 585,31, 978,36, 1886,03, 1958,63, 323,23, 1002,49, 1164,63, 1817,66, 363,55, 75,99)
Descuento <- c(0,3, 0,28, 0,02, 0,15, 0,12, 0,27, 0,13, 0,25, 0,22, 0,24, 0,1)
Fecha <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Tarjeta de crédito", "PayPal", "Efectivo", "Tarjeta de crédito", "Efectivo", "PayPal", "Efectivo", "Tarjeta de crédito", "Tarjeta de crédito", "Efectivo", "Tarjeta de crédito")
# Cree el marco de datos utilizando data.frame()
datos_ventas <- data.frame(
OrderID = OrderID,
Producto = Producto,
Cantidad = Cantidad
Precio = Precio,
Descuento = Descuento,
Date = Fecha,
Forma de Pago = Forma de Pago
)
# Visualizar el DataFrame
print(datos_ventas)
En este código, creamos vectores separados para cada columna y, a continuación, utilizamos la función data.frame( ) para combinar estos vectores en un DataFrame llamado sales_data.
Esto le permite crear un marco de datos tabular estructurado a partir de vectores individuales en R.
#6. Desde un archivo Excel
Para crear un DataFrame importando un archivo Excel en R, puede utilizar paquetes de terceros como readxl ya que el R base no ofrece soporte nativo para la lectura de archivos CSV. Una de estas funciones para leer archivos Excel es read_excel().
# Cargue la biblioteca readxl
library(readxl)
# Defina la ruta del archivo Excel
excel_ruta_archivo <- "su_archivo.xlsx" # Sustituir por la ruta real del archivo
# Lea el archivo Excel y cree un DataFrame
marco_datos_de_excel <- leer_excel(ruta_archivo_excel)
# Visualizar el DataFrame
print(marco_de_datos_de_excel)
Este código leerá el archivo de Excel y almacenará sus datos en un DataFrame de R, permitiéndole trabajar con los datos dentro de su entorno R.
#7. Desde archivo de texto
Puede emplear la función read.table() en R para importar un archivo de texto a un DataFrame. Esta función requiere dos parámetros esenciales: el nombre del archivo que desea leer y el delimitador que especifica cómo se separan los campos en el archivo.
# Defina el nombre del archivo y el delimitador
nombre_archivo <- "su_archivo_de_texto.txt" # Sustitúyalo por el nombre real del archivo
delimitador <- "\t" # Sustitúyalo por el delimitador real (por ejemplo, "\t" para separar por tabuladores, "," para CSV)
# Utilice la función read.table() para crear un DataFrame
data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter)
# Visualizar el DataFrame
print(marco_de_datos_de_texto)
Este código leerá el archivo de texto y lo creará en R, haciéndolo accesible para el análisis de datos dentro de su entorno R.
#8. Utilizar Tibble
Para crearlo utilizando los vectores proporcionados y utilizar la biblioteca tidyverse, puede seguir estos pasos:
# Cargar la biblioteca tidyverse
library(tidyverse)
# Cree un tibble utilizando los vectores proporcionados
datos_ventas <- tibble(
OrderID = 1001:1011,
Producto = c("Portátil", "Smartphone", "Tableta", "Auriculares", "Cámara", "Televisor", "Impresora", "Lavadora", "Frigorífico", "Horno microondas", "Cafetera"),
Cantidad = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Precio = c(1875,88, 585,31, 978,36, 1886,03, 1958,63, 323,23, 1002,49, 1164,63, 1817,66, 363,55, 75,99),
Descuento = c(0,3, 0,28, 0,02, 0,15, 0,12, 0,27, 0,13, 0,25, 0,22, 0,24, 0,1),
Fecha = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Tarjeta de crédito", "PayPal", "Efectivo", "Tarjeta de crédito", "Efectivo", "PayPal", "Efectivo", "Tarjeta de crédito", "Tarjeta de crédito", "Efectivo", "Tarjeta de crédito")
)
# Mostrar el tibble de ventas creado
print(datos_ventas)
Este código utiliza la función tibble() de la biblioteca tidyverse para crear un DataFrame tibble llamado sales_data. El formato tibble proporciona una impresión más informativa en comparación con el marco de datos predeterminado de R, como ha mencionado.
Cómo utilizar DataFrames eficientemente en R
Utilizar DataFrames eficientemente en R es esencial para la manipulación y el análisis de datos. Los DataFrames son una estructura de datos fundamental en R y normalmente se crean y manipulan utilizando la función data.frame. He aquí algunos consejos para trabajar de forma eficiente:
- Antes de crear, asegúrese de que sus datos están limpios y bien estructurados. Elimine las filas o columnas innecesarias, gestione los valores que faltan y asegúrese de que los tipos de datos son apropiados.
- Establezca tipos de datos apropiados para sus columnas (por ejemplo, numérico, carácter, factor, fecha). Esto puede mejorar el uso de la memoria y la velocidad de cálculo.
- Utilice la indexación y el subconjunto para trabajar con porciones más pequeñas de sus datos. Los operadores
subset()y[ ]son útiles para este fin.
- Aunque
attach()ydetach() pueden resultar convenientes, también pueden dar lugar a ambigüedades y comportamientos inesperados.
- R está altamente optimizado para operaciones vectorizadas. Siempre que sea posible, utilice funciones vectorizadas en lugar de bucles para la manipulación de datos.
- Los bucles anidados pueden ser lentos en R. En lugar de bucles anidados, intente utilizar operaciones vectorizadas o aplicar funciones como
lapplyosapply.
- Los DataFrames grandes pueden consumir mucha memoria. Considere la posibilidad de utilizar los paquetes
data.tableodtplyr, que son más eficientes en memoria para conjuntos de datos más grandes.
- R dispone de una amplia gama de paquetes para la manipulación de datos. Utilice paquetes como
dplyr,tidyrydata.table para realizar transformaciones de datos eficientes.
- Minimice el uso de variables globales, especialmente cuando trabaje con múltiples DataFrames. Utilice funciones y pase los DataFrames como argumentos.
- Cuando trabaje con datos agregados, utilice las funciones
group_by()ysummarize()dedplyrpara realizar cálculos de forma eficiente.
- Para grandes conjuntos de datos, considere la posibilidad de utilizar el procesamiento paralelo con paquetes como
paralleloforeachpara acelerar las operaciones.
- Cuando lea datos en R, utilice funciones como
readrodata.table::freaden lugar de funciones básicas de R comoread.csvpara importar datos más rápidamente.
- Para conjuntos de datos muy grandes, considere la posibilidad de utilizar sistemas de bases de datos o formatos de almacenamiento especializados como Feather, Arrow o Parquet.
Siguiendo estas prácticas recomendadas, podrá trabajar eficazmente con DataFrames en R, haciendo que sus tareas de manipulación y análisis de datos sean más manejables y rápidas.
Reflexiones finales
Crear dataframes en R es sencillo, y existen varios métodos a su disposición. He destacado la importancia de los marcos de datos y he discutido su creación utilizando la función data.frame().
Además, hemos explorado métodos para manipular datos y hemos cubierto cómo crear a partir de archivos CSV y Excel, convertir otras estructuras de datos en marcos de datos y hacer uso de la biblioteca tibble.
Puede que le interese saber cuáles son los mejores IDE para la programación en R.