
A medida que las empresas generan cada vez más datos, el enfoque tradicional del almacenamiento de datos resulta cada vez más difícil y costoso de mantener. La bóveda de datos, un enfoque relativamente nuevo del almacenamiento de datos, ofrece una solución a este problema al proporcionar una forma escalable, ágil y rentable de gestionar grandes volúmenes de datos.
En este post, exploraremos cómo las Bóvedas de Datos son el futuro del almacenamiento de datos y por qué cada vez más empresas están adoptando este enfoque. También proporcionaremos recursos de aprendizaje para quienes deseen profundizar en el tema
¿Qué es Data Vault?
Data Vault es una técnica de modelado de almacenes de datos especialmente adecuada para los almacenes de datos ágiles. Ofrece un alto grado de flexibilidad para las ampliaciones, una completa historización unitario-temporal de los datos y permite una fuerte paralelización de los procesos de carga de datos. Dan Linstedt desarrolló el modelado Data Vault en la década de 1990.
Tras su primera publicación en 2000, ganó mayor atención en 2002 a través de una serie de artículos. En 2007, Linstedt obtuvo el respaldo de Bill Inmon, que lo describió como la «elección óptima» para su arquitectura Data Vault 2.0.
Cualquiera que maneje el término almacén de datos ágil acabará rápidamente con Data Vault. Lo especial de esta tecnología es que se centra en las necesidades de las empresas porque permite realizar ajustes flexibles y de bajo esfuerzo en un almacén de datos.
Data Vault 2.0 tiene en cuenta todo el proceso de desarrollo y la arquitectura y consta de los componentes método (implementación), arquitectura y modelo. La ventaja es que este enfoque considera todos los aspectos de la inteligencia empresarial con el almacén de datos subyacente durante el desarrollo.
El modelo Data Vault ofrece una solución moderna para superar las limitaciones de los enfoques tradicionales de modelado de datos. Con su escalabilidad, flexibilidad y agilidad, proporciona una base sólida para construir una plataforma de datos que pueda adaptarse a la complejidad y diversidad de los entornos de datos modernos.
La arquitectura hub-and-spoke de Data Vault y la separación de entidades y atributos permiten la integración y armonización de datos en múltiples sistemas y dominios, facilitando un desarrollo incremental y ágil.
Un papel crucial de Data Vault en la construcción de una plataforma de datos es establecer una única fuente de verdad para todos los datos. Su visión unificada de los datos y su compatibilidad con la captura y el seguimiento de los cambios históricos de los datos a través de tablas satélite permiten el cumplimiento, la auditoría, los requisitos normativos y el análisis y la elaboración de informes exhaustivos.
Las capacidades de integración de datos casi en tiempo real de Data Vault a través de la carga delta facilitan la gestión de grandes volúmenes de datos en entornos que cambian con rapidez, como las aplicaciones Big Data e IoT.
Data Vault frente a los modelos tradicionales de almacén de datos
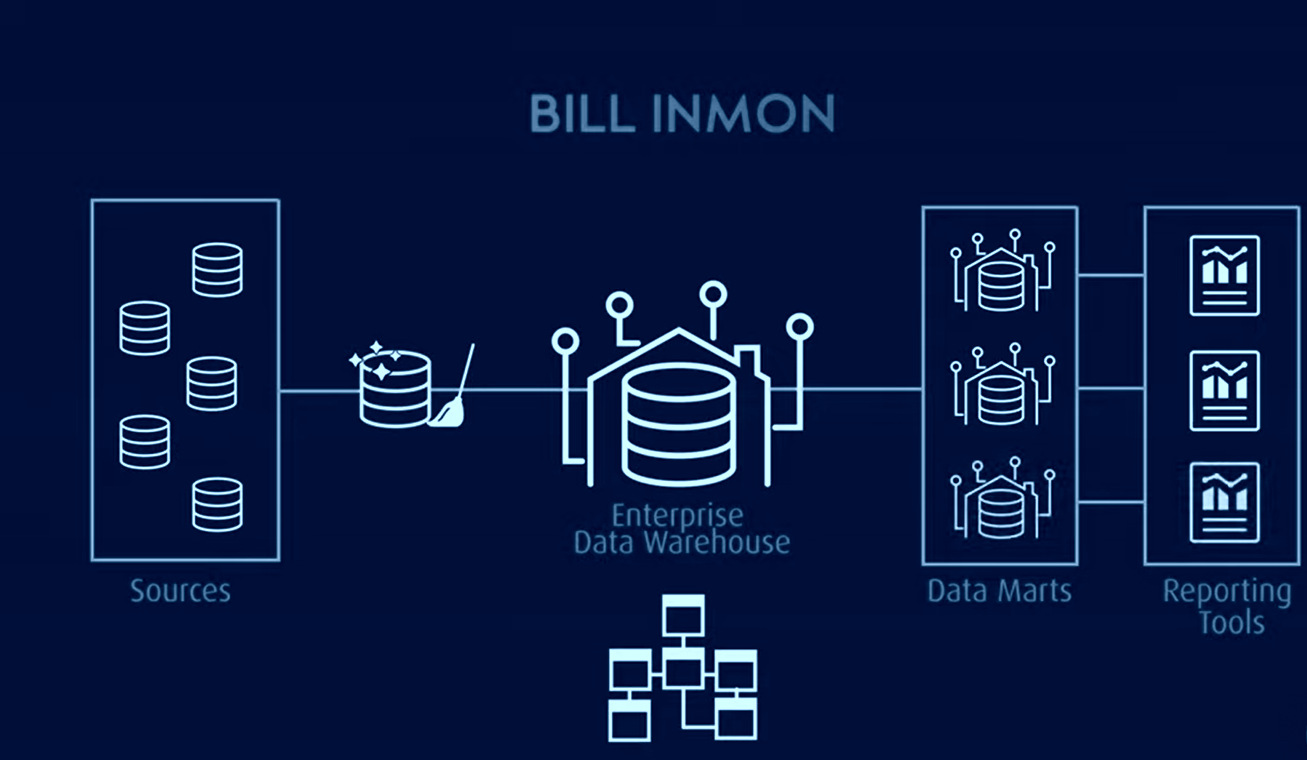
La tercera forma normal (3NF) es uno de los modelos tradicionales de almacén de datos más conocidos, a menudo preferido en muchas grandes implementaciones. Por cierto, corresponde a las ideas de Bill Inmon, uno de los «antepasados» del concepto de almacén de datos.
La arquitectura de Inmon se basa en el modelo de base de datos relacional y elimina la redundancia de datos descomponiendo las fuentes de datos en tablas más pequeñas que se almacenan en los data marts y se interconectan mediante claves primarias y foráneas. Garantiza que los datos sean coherentes y precisos aplicando reglas de integridad referencial.
El objetivo de la forma normal era construir un modelo de datos completo para toda la empresa para el almacén de datos central; sin embargo, tiene problemas de escalabilidad y flexibilidad debido a los marts de datos altamente acoplados, las dificultades de carga en modo casi en tiempo real, las solicitudes laboriosas y el diseño e implementación descendentes.
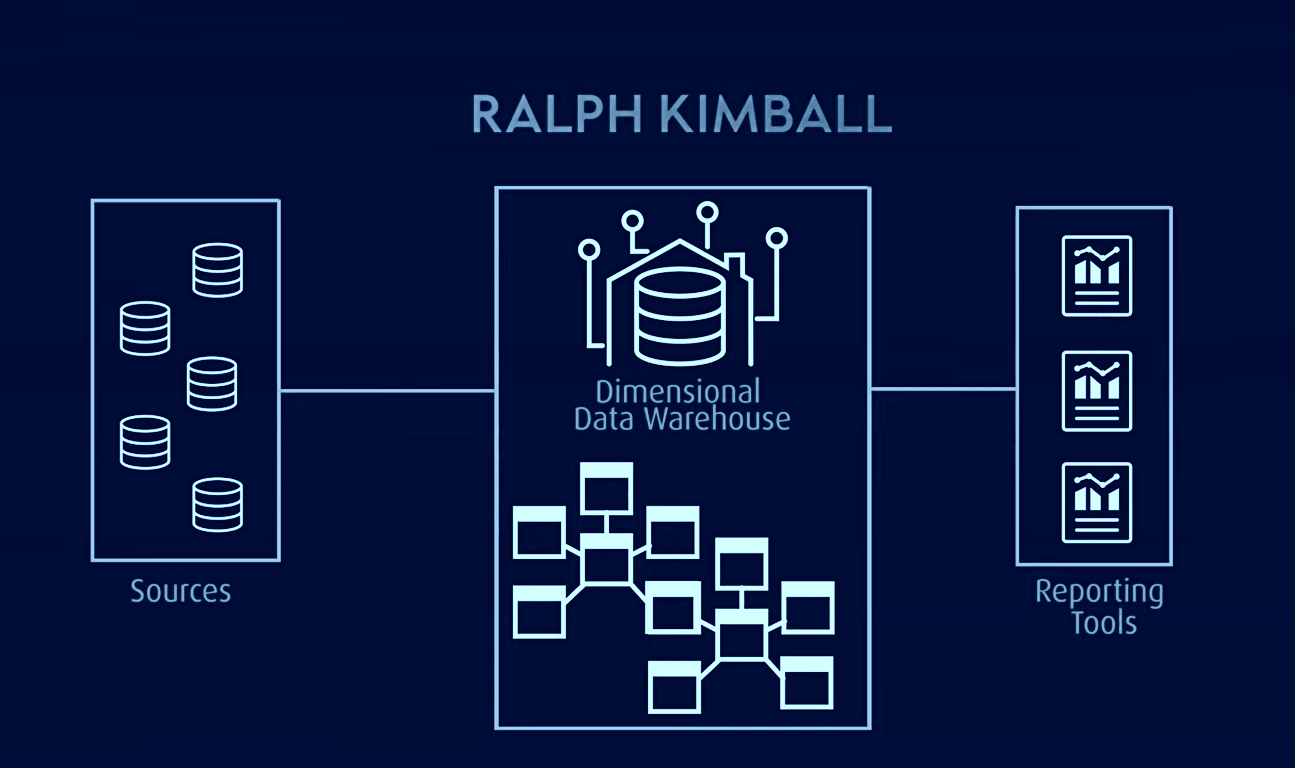
El modelo Kimbal, utilizado para el OLAP (procesamiento analítico en línea) y los data marts, es otro famoso modelo de almacén de datos en el que las tablas de hechos contienen datos agregados y las tablas de dimensiones describen los datos almacenados en un diseño de esquema de estrella o de copo de nieve. En esta arquitectura, los datos se organizan en tablas de hechos y dimensiones que se desnormalizan para simplificar la consulta y el análisis.
Kimbal se basa en un modelo dimensional optimizado para la consulta y la elaboración de informes, por lo que resulta ideal para las aplicaciones de inteligencia empresarial. Sin embargo, ha tenido problemas con el aislamiento de la información orientada a temas, la redundancia de datos, las estructuras de consulta incompatibles, las dificultades de escalabilidad, la granularidad incoherente de las tablas de hechos, los problemas de sincronización y la necesidad de un diseño descendente con una implementación ascendente.
En cambio, la arquitectura Data vault es un enfoque híbrido que combina aspectos de las arquitecturas 3NF y Kimball. Es un modelo basado en principios relacionales, normalización de datos y matemáticas de redundancia que representa las relaciones entre entidades de forma diferente y estructura los campos de las tablas y las marcas de tiempo de forma diferente.
En esta arquitectura, todos los datos se almacenan en una bóveda de datos brutos o lago de datos, mientras que los datos de uso común se almacenan en un formato normalizado en una bóveda empresarial que contiene datos históricos y específicos del contexto que pueden utilizarse para la elaboración de informes.
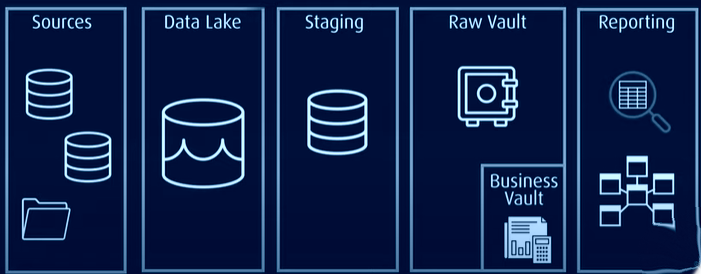
La bóveda de datos resuelve los problemas de los modelos tradicionales al ser más eficiente, escalable y flexible. Permite una carga casi en tiempo real, una mejor integridad de los datos y una fácil ampliación sin afectar a las estructuras existentes. El modelo también puede ampliarse sin necesidad de migrar las tablas existentes.
| Enfoque del modelo | Estructura de datos | Enfoque de diseño |
| modelado 3NF | Tablas en 3NF | De abajo a arriba |
| Modelado Kimbal | Esquema estrella o esquema copo de nieve | De arriba abajo |
| Bóveda de datos | Hub-and-Spoke | De abajo arriba |
Arquitectura de Data Vault
Data Vault tiene una arquitectura hub-and-spoke y consta esencialmente de tres capas:
Capa de preparación: Recoge los datos en bruto de los sistemas de origen, como CRM o ERP
Capa dealmacén de datos: Cuando se modela como un modelo Data Vault, esta capa incluye:
- Bóveda de datos brutos: almacena los datos brutos.
- Bóveda de datos empresariales: incluye los datos armonizados y transformados en función de las reglas empresariales (opcional).
- Bóveda de métricas: almacena la información en tiempo de ejecución (opcional).
- Bóveda operativa: almacena los datos que fluyen directamente de los sistemas operativos al almacén de datos (opcional.)
CapaData Mart: Esta capa modela los datos como un esquema en estrella y/u otras técnicas de modelado. Proporciona información para el análisis y la elaboración de informes.
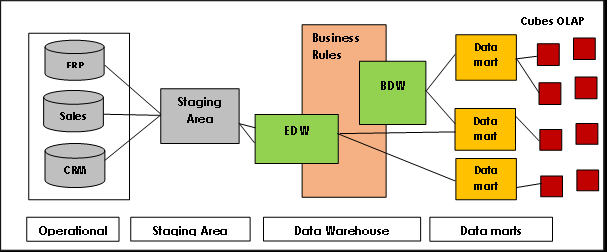
Data Vault no requiere una rearquitectura. Se pueden construir nuevas funciones en paralelo utilizando directamente los conceptos y métodos de Data Vault, y los componentes existentes no se pierden. Los marcos de trabajo pueden facilitar significativamente el trabajo: crean una capa entre el almacén de datos y el desarrollador y reducen así la complejidad de la implementación.
Componentes de Data Vault
Durante el modelado, Data Vault divide toda la información perteneciente al objeto en tres categorías, a diferencia del modelado clásico de tercera forma normal. A continuación, esta información se almacena estrictamente separada entre sí. Las áreas funcionales pueden mapearse en Data Vault en los denominados centros, enlaces y satélites:
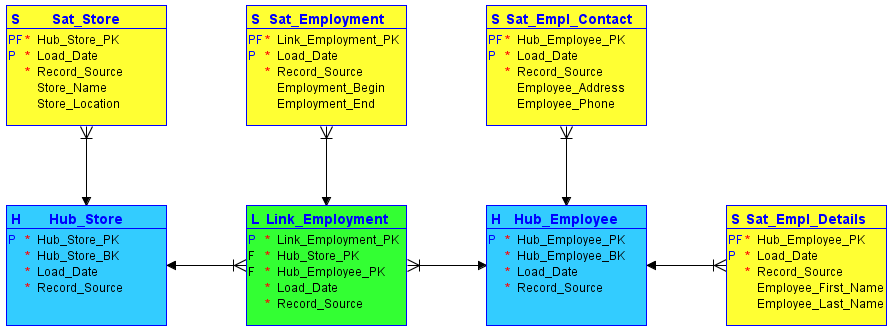
#1. Hubs
Los hubs son el corazón del concepto central del negocio, como cliente, vendedor, venta o producto. La tabla hub se forma en torno a la clave de negocio (nombre de la tienda o ubicación) cuando se introduce por primera vez en el almacén de datos una nueva instancia de esa clave de negocio.
El hub no contiene información descriptiva ni FK. Consiste únicamente en la clave de negocio, con una secuencia generada por el almacén de claves ID o hash, fecha/hora de carga y fuente de registro.
#2. Enlaces
Los enlaces establecen relaciones entre las claves de negocio. Cada entrada de un enlace modela nm relaciones de cualquier número de centros. Permite a la bóveda de datos reaccionar con flexibilidad a los cambios en la lógica empresarial de los sistemas fuente, como los cambios en la cordialidad de las relaciones. Al igual que el hub, el enlace no contiene ninguna información descriptiva. Consta de los ID de secuencia de los concentradores a los que hace referencia, un ID de secuencia generado por el almacén, el sello de fecha/hora de la carga y la fuente del registro.
#3. Satélites
Los satélites contienen la información descriptiva (contexto) de una clave de negocio almacenada en un hub o de una relación almacenada en un enlace. Los satélites funcionan «sólo inserción», lo que significa que el historial de datos completo se almacena en el satélite. Varios satélites pueden describir una única clave de negocio (o relación). Sin embargo, un satélite sólo puede describir una clave (hub o enlace).
Cómo construir un modelo Data Vault
La construcción de un modelo Data Vault implica varios pasos, cada uno de los cuales es fundamental para garantizar que el modelo sea escalable, flexible y capaz de satisfacer las necesidades de la empresa:
#1. Identificar entidades y atributos
Identifique las entidades empresariales y sus atributos correspondientes. Esto implica trabajar estrechamente con las partes interesadas del negocio para comprender sus requisitos y los datos que necesitan capturar. Una vez identificadas estas entidades y atributos, sepárelos en centros, enlaces y satélites.
#2. Defina las relaciones entre entidades y cree vínculos
Una vez identificadas las entidades y los atributos, se definen las relaciones entre las entidades y se crean los enlaces para representar estas relaciones. A cada enlace se le asigna una clave de negocio que identifica la relación entre las entidades. A continuación, se añaden los satélites para capturar los atributos y las relaciones de las entidades.
#3. Establecer reglas y normas
Después de crear los vínculos, debe establecerse un conjunto de reglas y normas de modelado de la bóveda de datos para garantizar que el modelo sea flexible y pueda manejar los cambios a lo largo del tiempo. Estas reglas y normas deben revisarse y actualizarse con regularidad para garantizar que siguen siendo pertinentes y se ajustan a las necesidades de la empresa.
#4. Poblar el modelo
Una vez creado el modelo, debe poblarse con datos utilizando un enfoque de carga incremental. Se trata de cargar los datos en los nodos, enlaces y satélites utilizando cargas delta. Las cargas delta para garantizar que sólo se cargan los cambios realizados en los datos, reduciendo el tiempo y los recursos necesarios para la integración de datos.
#5. Probar y validar el modelo
Por último, el modelo debe probarse y validarse para garantizar que cumple los requisitos de la empresa y que es lo suficientemente escalable y flexible como para hacer frente a futuros cambios. Deben realizarse tareas de mantenimiento y actualizaciones periódicas para garantizar que el modelo se mantiene alineado con las necesidades empresariales y sigue proporcionando una visión unificada de los datos.
Recursos de aprendizaje de Data Vault
Dominar Data Vault puede proporcionar valiosas habilidades y conocimientos muy buscados en las industrias actuales impulsadas por los datos. He aquí una lista completa de recursos, incluidos cursos y libros, que pueden ayudar a aprender los entresijos de Data Vault:
#1. Modelado de almacenes de datos con Data Vault 2.0

Este curso de Udemy es una introducción exhaustiva al enfoque de modelado de Data Vault 2.0, la gestión ágil de proyectos y la integración de Big Data. El curso cubre las bases y fundamentos de Data Vault 2.0, incluyendo su arquitectura y capas, las bóvedas de negocio e información, y las técnicas avanzadas de modelado.
Le enseña a diseñar un modelo Data Vault desde cero, a convertir modelos tradicionales como 3NF y modelos dimensionales a Data Vault, y a comprender los principios del modelado dimensional en Data Vault. El curso requiere conocimientos básicos de bases de datos y fundamentos de SQL.
Con una alta calificación de 4,4 sobre 5 y más de 1.700 reseñas, este curso superventas es adecuado para cualquiera que busque construir una base sólida en Data Vault 2.0 y la integración de Big Data.
#2. Modelado de Data Vault explicado con casos de uso

Este curso Udemy tiene como objetivo guiarle en la construcción de un Modelo Data Vault utilizando un ejemplo práctico de negocio. Sirve como guía para principiantes en el Modelado Data Vault, cubriendo conceptos clave como los escenarios apropiados para utilizar los modelos Data Vault, las limitaciones del Modelado OLAP convencional y un enfoque sistemático para construir un Modelo Data Vault. El curso es accesible a personas con conocimientos mínimos de bases de datos.
#3. El gurú de Data Vault: una guía pragmática
El gurú de la bóveda de datos, del Sr. Patrick Cuba, es una guía completa de la metodología de la bóveda de datos, que ofrece una oportunidad única para modelar el almacén de datos de la empresa utilizando principios de automatización similares a los utilizados en la entrega de software.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
The Data Vault Guru: a pragmatic guide on building a data vault | Buy on Amazon |
El libro proporciona una visión general de la arquitectura moderna y, a continuación, ofrece una guía completa sobre cómo ofrecer un modelo de datos flexible que se adapte a los cambios en la empresa, la bóveda de datos.
Además, el libro amplía la metodología de la bóveda de datos proporcionando corrección automatizada de plazos, registros de auditoría, control de metadatos e integración con herramientas de entrega ágiles.
#4. Creación de un almacén de datos escalable con Data Vault 2.0
Este libro proporciona a los lectores una guía completa para crear un almacén de datos escalable de principio a fin utilizando la metodología Data Vault 2.0.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Building a Scalable Data Warehouse with Data Vault 2.0 | Buy on Amazon |
Este libro cubre todos los aspectos esenciales de la creación de un almacén de datos escalable, incluida la técnica de modelado Data Vault, diseñada para evitar los típicos fallos del almacén de datos.
El libro incluye numerosos ejemplos para ayudar a los lectores a comprender los conceptos con claridad. Con sus ideas prácticas y ejemplos del mundo real, este libro es un recurso esencial para cualquier persona interesada en el almacenamiento de datos.
#5. El elefante en la nevera: Pasos guiados hacia el éxito del almacén de datos
The Elephant in the Fridge (El elefante en la nevera), de John Giles, es una guía práctica que pretende ayudar a los lectores a alcanzar el éxito en Data Vault empezando por el negocio y terminando por el negocio.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
The Elephant in the Fridge: Guided Steps to Data Vault Success through Building Business-Centered… | Buy on Amazon |
El libro se centra en la importancia de la ontología empresarial y el modelado de conceptos de negocio y proporciona una guía paso a paso sobre cómo aplicar estos conceptos para crear un modelo de datos sólido.
A través de consejos prácticos y patrones de ejemplo, el autor ofrece una explicación clara y sin complicaciones de temas complicados, lo que convierte al libro en una guía excelente para los que se inician en el Data Vault.
Palabras finales
Data Vault representa el futuro del almacenamiento de datos, ya que ofrece a las empresas ventajas significativas en términos de agilidad, escalabilidad y eficacia. Es especialmente adecuado para las empresas que necesitan cargar grandes volúmenes de datos con rapidez y para aquellas que buscan desarrollar sus aplicaciones de inteligencia empresarial de forma ágil.
Además, las empresas que disponen de una arquitectura de silos pueden beneficiarse enormemente de la implantación de un almacén de datos centralizado ascendente utilizando Data Vault.
Puede que también le interese conocer el linaje de los datos.