Las bases de datos de grafos almacenan datos densos altamente conectados y procesan las consultas con eficacia. Pero, ¿sabe cuándo utilizar cada base de datos gráfica? Lea para saber más.
«Los datos son el nuevo petróleo» El crecimiento de cualquier organización se basa en cómo almacena y utiliza los datos de forma eficaz. 2.cada día se generan 5 quintillones de bytes de datos. Por lo tanto, necesitamos sistemas y almacenes tolerantes a fallos en los que los datos puedan almacenarse y gestionarse de forma eficaz. Al principio se utilizaban bases de datos relacionales.
Pero con el paso del tiempo, la cantidad y el tipo de datos cambiaron rápidamente. De ahí surgió la necesidad de almacenar vídeo, audio, imágenes, etc. Este fue el punto desencadenante del desarrollo de SQL, las bases de datos NoSQL, Hadoop, las bases de datos gráficas, etc. Cada una de ellas tiene sus propios casos de uso y trata con distintos formatos de datos. Las bases de datos de grafos se desarrollaron para simplificar las operaciones con los datos y para un almacenamiento eficaz.
Bases de datos de grafos
Un grafo es una estructura de datos representada en forma de nodos y aristas. Una base de datos es una colección de tablas que almacena datos y las relaciones entre los datos. Una base de datos de grafos es una base de datos que almacena los datos en nodos y las relaciones que existen entre los datos en forma de aristas. Las bases de datos de grafos ayudan a manejar las consultas en tiempo real y a gestionar eficazmente las relaciones de muchos a muchos entre entidades.
Entre los modelos de datos de grafos más populares se encuentran los grafos de propiedades y los grafos RDF. Los análisis y las consultas se realizan principalmente mediante grafos de propiedades. La integración de datos se realiza mediante grafos RDF. La diferencia entre los grafos de propiedades y los grafos RDF es que los grafos RDF se representan en forma de tripletas, es decir, sujeto, predicado y objeto.
Las bases de datos de grafos almacenan los datos en nodos y la relación entre los datos en forma de aristas entre los nodos. Las aristas del grafo pueden ser dirigidas (unidireccionales) o no dirigidas (bidireccionales).
El procesamiento de las consultas se realiza atravesando el grafo. Para responder eficazmente a las consultas se utilizan algoritmos de recorrido del grafo que ayudan a encontrar el camino de un nodo a otro, la distancia entre los nodos, encontrar patrones, bucles dentro del grafo y la posibilidad de formación de conglomerados, etc.

Aplicaciones de las bases de datos de grafos
Las bases de datos de grafos se utilizan en la detección de fraudes. Los nodos/entidades pueden ser nombres de personas, direcciones, fecha de nacimiento, etc., y algunos fraudulentos direcciones IP, números de dispositivos, etc. Cuando un nodo fraudulento interactúa con un nodo no fraudulento, se forman vínculos entre ellos y se marcan como sospechosos.
Los sitios web de medios sociales utilizan bases de datos de grafos para mostrar recomendaciones de las personas con las que nos gustaría conectar y los contenidos que queremos ver. Esto lo hace con la ayuda de recorridos de grafos en la base de datos.
El mapeo de redes y la gestión de infraestructuras, elementos de configuración, etc., también se almacenan y gestionan eficazmente mediante bases de datos de grafos.
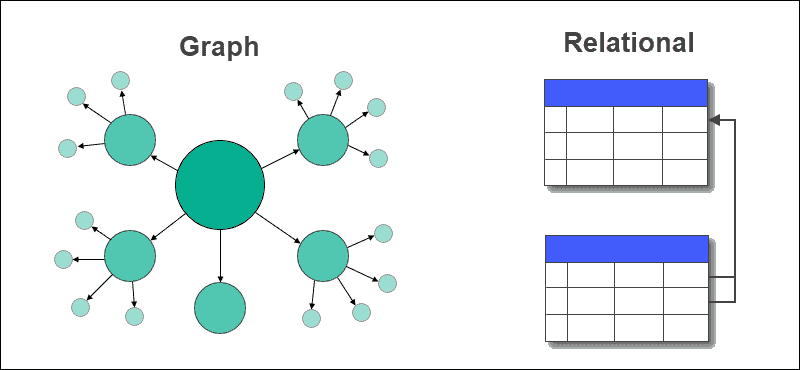
Base de datos gráfica frente a base de datos relacional
En una base de datos gráfica, las tablas con filas y columnas se sustituyen por nodos y aristas. Las relaciones entre los datos se almacenan en aristas en una base de datos gráfica.
Una base de datos relacional almacena las relaciones entre tablas utilizando claves externas y otras tablas. Extraer datos o realizar consultas es fácil y no requiere uniones complejas en una base de datos gráfica, pero no es el caso de las bases de datos relacionales.
Las bases de datos relacionales son más adecuadas para los casos de uso que implican transacciones, mientras que las bases de datos de grafos son adecuadas para las aplicaciones con muchas relaciones y muchos datos.
Las bases de datos de grafos admiten datos estructurados, semiestructurados y no estructurados, mientras que las bases de datos relacionales necesitan tener un esquema fijo.
Las bases de datos de grafos satisfacen requisitos dinámicos, mientras que las bases de datos relacionales se utilizan generalmente para problemas conocidos y estáticos.
Veamos ahora las mejores soluciones de bases de datos de grafos.
Cayley
Cayley es una base de datos gráfica de código abierto desarrollada por Apache 2.0. Se construyó utilizando Go y funciona con datos enlazados. Cayley es la base de datos utilizada durante la construcción de Freebase y knowledge graph de Google. Soporta múltiples lenguajes de consulta como MQL y Javascript con un objeto gráfico basado en Gremlin.

Es fácil de usar, rápida y tiene un diseño modular. Puede integrarse e interactuar con varios almacenes backend como LevelDB, MongoDB y Bolt. Es compatible con varias API de terceros escritas en varios lenguajes como Java, .NET, Rust, Haskell, Ruby, PHP, Javascript y Clojure. Puede desplegarse en Docker y Kubernetes. Las áreas clave en las que se utiliza Cayley son la tecnología de la información, el software informático y los servicios financieros.
Amazon Neptune
AmazonNeptune es conocido por su rendimiento excepcional en conjuntos de datos altamente conectados. Es fiable, seguro, totalmente gestionado y compatible con API de gráficos abiertos. Puede almacenar miles de millones de relaciones y consultar datos con una latencia extremadamente baja, de algunos milisegundos.
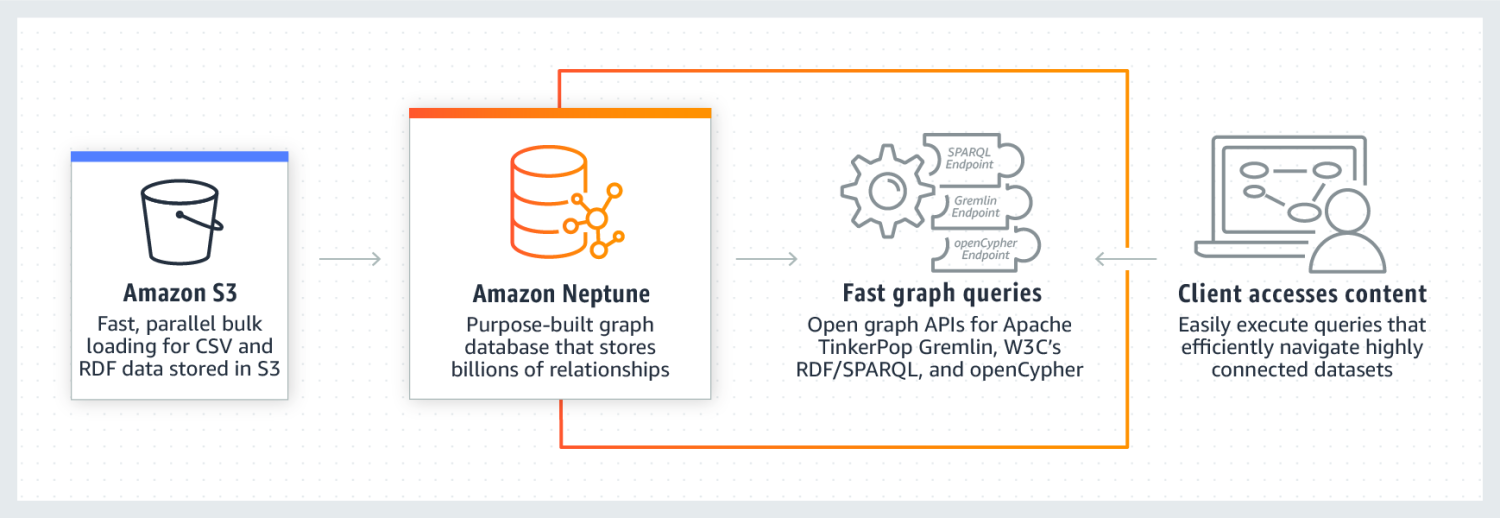
El modelo de datos de grafos Neptune consta de 4 posiciones, a saber, sujeto (S), predicado (P), objeto (O) y grafo (G). Cada una de estas posiciones se utiliza para almacenar la posición del nodo origen, el nodo destino, la relación entre ellos y sus propiedades.
También utiliza una caché que acelera la ejecución de las consultas de lectura. Los datos se almacenan en forma de clusters de BD. Cada cluster comprende una instancia primaria de BD y réplicas de lectura de instancias de BD. Neptune es altamente seguro, ya que utiliza autenticación IAM, certificación SSL y supervisión de registros. También es fácil migrar datos de otras fuentes a Amazon Neptune. También garantiza la resiliencia mediante la creación de réplicas y backups periódicos. Algunas empresas que utilizan Neptune son Herren, Onedot, Juncture y Hi Platform.
Neo4j
Neo4j es una base de datos gráfica escalable, segura, bajo demanda y fiable. Neo4j se construyó con Java, utilizando Cypher como lenguaje de consulta. Utiliza el protocolo Bolt, y todas las transacciones se producen a través de un punto final HTTP. Es mucho más rápida a la hora de responder a las consultas en comparación con otras bases de datos relacionales. No tiene la sobrecarga de las uniones complejas, y sus optimizaciones funcionan bien cuando el tamaño del conjunto de datos es grande y está muy conectado. Ofrece la ventaja del almacenamiento de grafos junto con las propiedades ACID de una base de datos relacional.

Neo4j es compatible con varios lenguajes como Java, .NET, Node.js, Ruby, Python, etc., con la ayuda de controladores. También se utiliza en la ciencia de datos gráficos, análisis y flujos de trabajo de aprendizaje automático. Neo4j Aura DB es una base de datos gráfica en la nube tolerante a fallos y totalmente gestionada. Empresas como Microsoft, Cisco, Adobe, eBay, IBM, Samsung, etc., utilizan Neo4j.
ArangoDB
ArangoDB es una base de datos multimodelo de código abierto. El enfoque multimodelo permite a los usuarios consultar los datos en cualquier lenguaje de consulta de su elección. Los nodos y aristas de ArangoDB son documentos JSON. Cada documento tiene un id único. Las relaciones entre dos nodos se indican en forma de aristas y se almacenan sus id únicos. Su buen rendimiento se debe a la presencia de un índice hash.

Se mejoran los recorridos, las uniones y las búsquedas en las bases de datos. Ayuda a diseñar, escalar y adaptarse a diversas arquitecturas. Desempeña un papel importante en tareas complejas de ciencia de datos como la extracción de características y la búsqueda avanzada.
ArrangoDB puede ejecutarse en un entorno basado en la nube y es compatible con Mac Os, Linux y Windows. La autenticación LDAP, el enmascaramiento de datos y los algoritmos de encriptación garantizan la seguridad de la base de datos. Se utiliza en gestión de riesgos, IAM, detección de fraudes, infraestructura de redes, motores de recomendación, etc. Accenture, Cisco, Dish y VMware son algunas de las organizaciones que utilizan ArangoDB.
DataStax
DataStax es una base de datos NoSQL en la nube como servicio construida sobre Apache Cassandra. Es altamente escalable y utiliza una arquitectura nativa en la nube. Es fiable y segura. Cada documento almacenado en DataStax tiene un índice que ayuda en la búsqueda fácil y la recuperación rápida de datos. Sobre los datos indexados se crean shards. Se pueden utilizar varias fuentes de datos para crear aplicaciones con las herramientas Datastax Enterprise, Kafka y Docker.
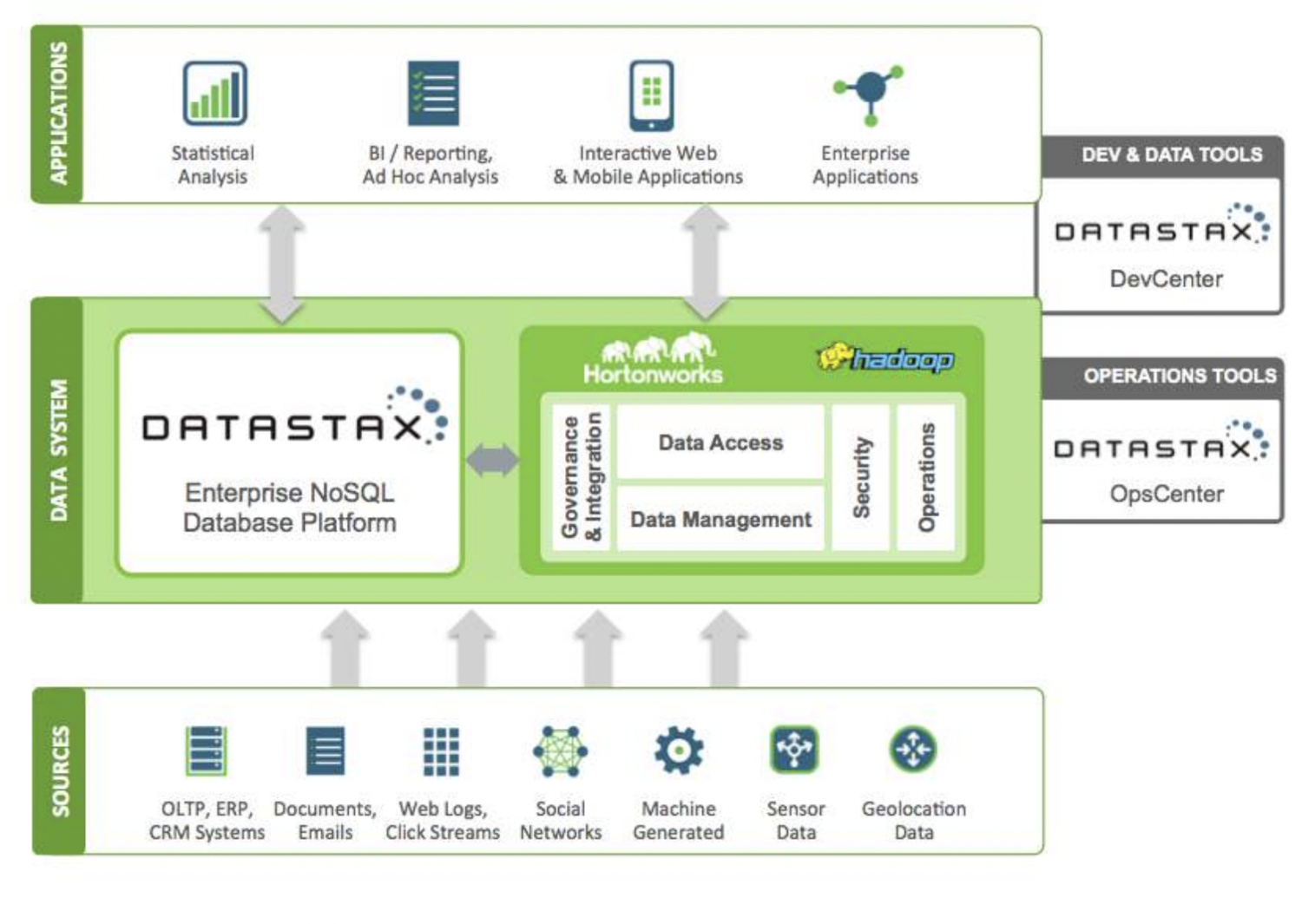
Los datos recogidos de las fuentes se envían a un ecosistema Hadoop y DataStax. Hadoop gestiona la seguridad, las operaciones, el acceso a los datos y la gestión interactuando con DataStax. Los datos se refinan utilizando las herramientas de desarrollo y operaciones de DataStax.
La información analizada se utiliza después para análisis estadísticos, aplicaciones empresariales, elaboración de informes, etc. Al estar basado en la nube, los clientes pagan por lo que utilizan, y los precios son razonables. Verizon, CapitalOne, TMobile y Overstock son algunas de las empresas que utilizan DataStax.
Orient DB
OrientDB es una base de datos gráfica que gestiona los datos de forma eficaz y ayuda a crear representaciones visuales para mostrar los datos. Es una base de datos gráfica multimodelo y se construyó utilizando Java. Almacena datos en forma de pares clave-valor, documentos, modelos de objetos, etc. Consta de 3 componentes significativos: editor de gráficos, consulta de estudio y consola de línea de comandos.
El editor de gráficos se utiliza para visualizar los datos e interactuar con ellos. La interfaz de consulta Studio se utiliza para ejecutar consultas y proporcionar la salida inmediatamente en un formato pictórico y tabular. La consola de línea de comandos se utiliza para consultar datos de OrientDB. Tiene una arquitectura distribuida con múltiples servidores que pueden realizar operaciones de lectura y escritura. Los servidores de réplica se utilizan para realizar operaciones de lectura y consulta. Soporta la indexación y también es compatible con ACID. Algunas de las empresas que utilizan OrientDB son Comcast Corporation y Blackfriars Group.
Dgraph
Dgraph es una base de datos gráfica en la nube que soporta GraphQL. Se construyó utilizando Go. Minimiza las llamadas a la red y reduce la latencia maximizando el procesamiento concurrente de consultas. La perfecta integración de Dgraph con GraphQL ayuda en el fácil desarrollo de aplicaciones backend GraphQL.

Una mutación GraphQL se pasa a través de una función Lambda que interactúa con la base de datos y una tubería de datos. Esto simplifica el procesamiento de consultas. Es escalable horizontalmente, lo que significa que el número de recursos se incrementa con el aumento de las consultas y los datos. Proporciona varias características como autorización basada en JWT, visualizador de datos, autenticación en la nube, copias de seguridad de datos, etc. Algunas organizaciones que utilizan Dgraph son Intuit, intel y Factset.
Tigergraph
Tigergraph es una base de datos de grafos de propiedades desarrollada en C . Es altamente escalable y realiza análisis avanzados sobre datos altamente conectados. Utiliza una estructura de grafos nativa para el almacenamiento de datos y un motor de procesamiento de grafos para procesar los datos. La base de datos se almacena en disco y en memoria y también utiliza una caché de CPU para una recuperación rápida. Utiliza la función Map Reduce para el procesamiento paralelo de datos.
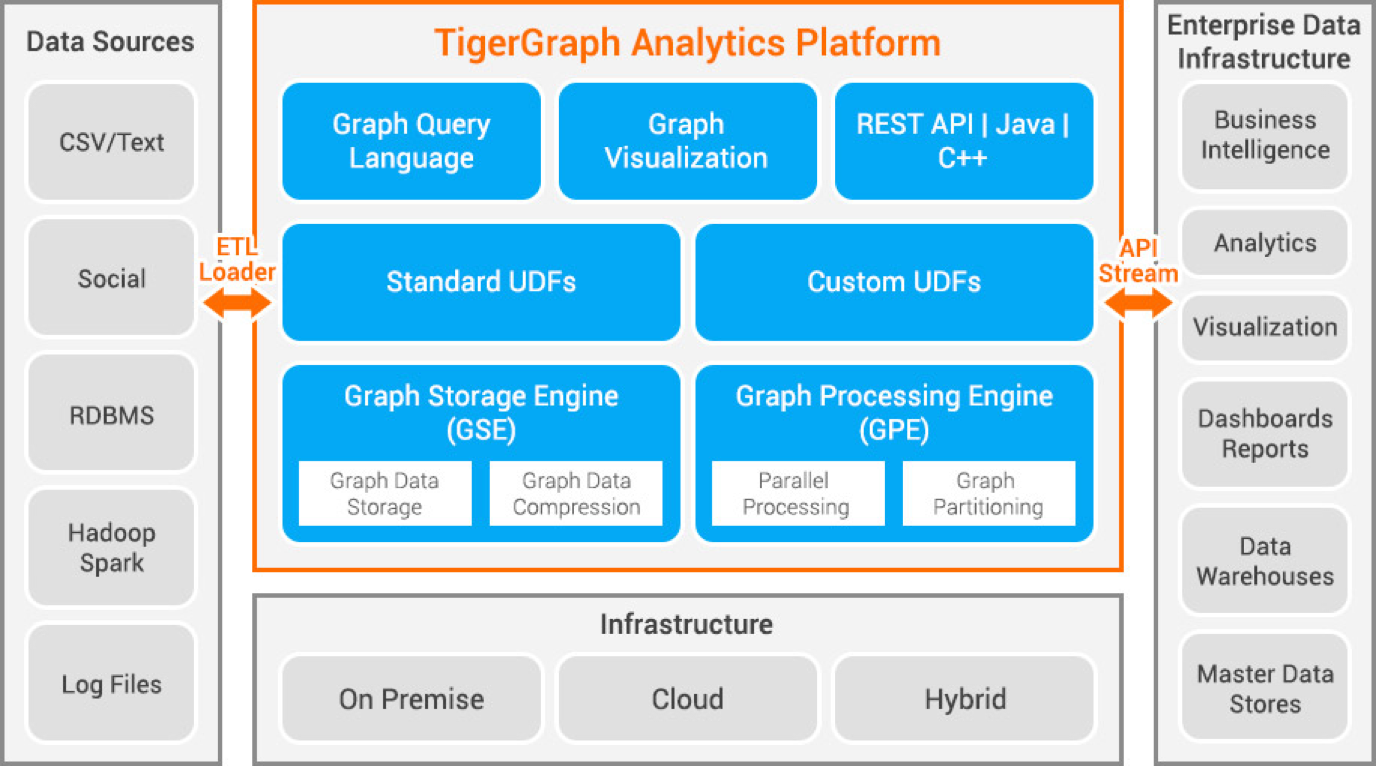
Es extremadamente rápido y escalable. Realiza cálculos en paralelo y proporciona actualizaciones en tiempo real. Utiliza técnicas de compresión de datos y los comprime 10 veces. Particiona los datos entre servidores automáticamente, ahorrando al usuario el tiempo y el esfuerzo necesarios para particionar los datos manualmente. Se utiliza para la detección del fraude en los hogares, la gestión de la cadena de suministro y la mejora de la atención sanitaria. JPMorgan Chase, Intuit y United Health Group son algunas de las organizaciones que utilizan Tigergraph.
AllegroGraph
AllegroGraph utiliza la tecnología de grafos de conocimiento entidad-evento para realizar análisis y tomar decisiones sobre datos altamente conectados, complejos y densos. Los datos se almacenan en formato JSON y JSON-LD en los nodos del grafo. Utiliza la arquitectura de protocolo REST. También se ocupa de conjuntos de datos extremadamente grandes fragmentando los datos en función de criterios específicos y distribuyéndolos en múltiples repositorios de bases de conocimiento.
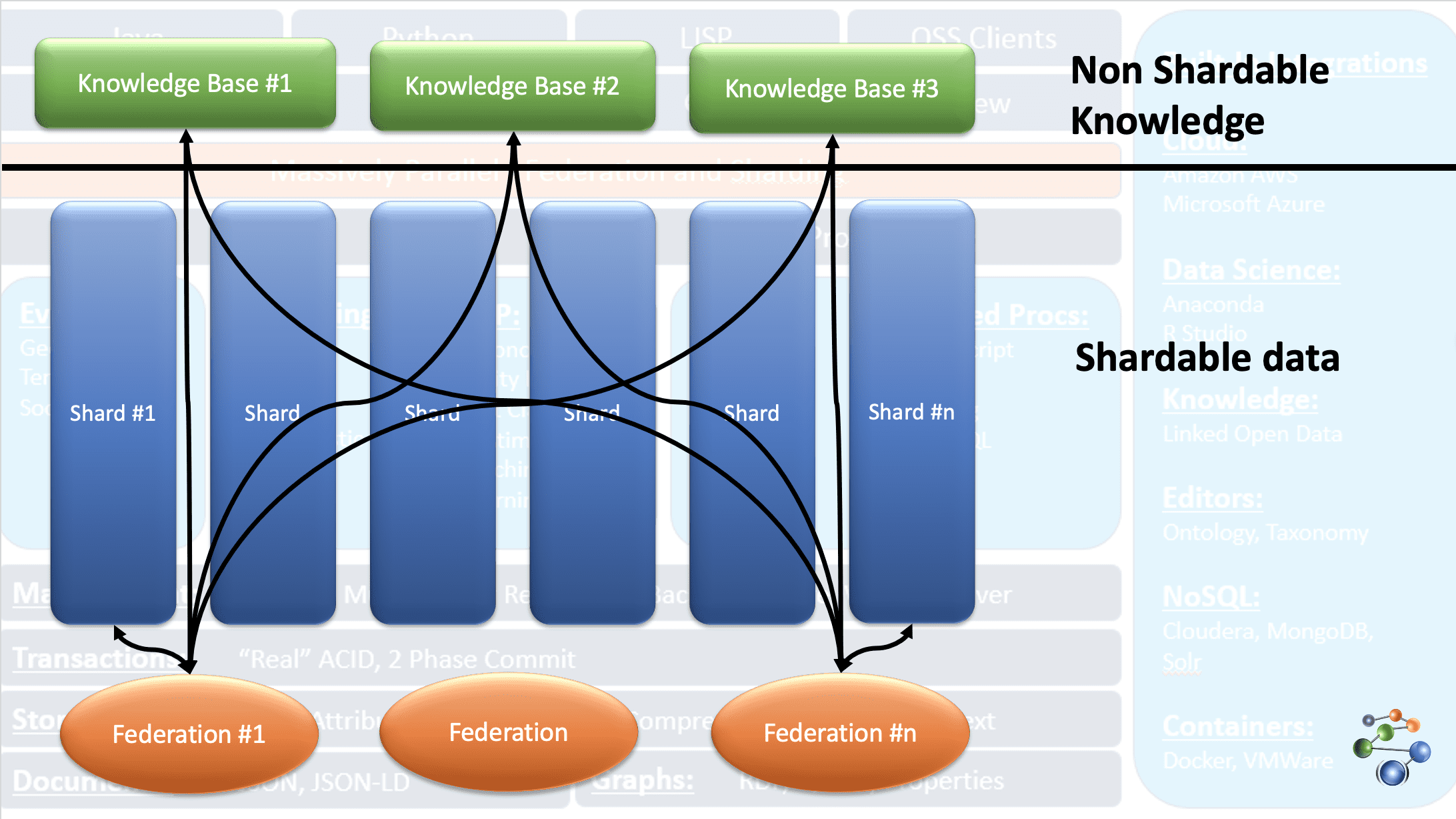
Esto es posible gracias a la función FedShard de la base de datos AllegroGraph. La ejecución de las consultas tiene lugar combinando las federaciones con los repositorios de bases de conocimiento. Admite tipos de esquema XML y utiliza índices triples. Almacena datos geoespaciales como latitudes y longitudes y datos temporales como fecha, marca de tiempo, etc. También es compatible con Windows, Mac y Linux. Se utiliza en la detección de fraudes, la atención sanitaria, la identificación de entidades, la predicción de riesgos, etc.
Stardog
Stardog es una base de datos gráfica que realiza la virtualización de datos gráficos y enlaza datos de almacenes y lagos de datos sin copiar físicamente los datos en una nueva ubicación de almacenamiento. Stardog se basa en estándares abiertos RDF. Admite datos estructurados, semiestructurados y no estructurados. Este tipo de materialización realizada por Stardog ofrece flexibilidad. Es la única base de datos gráfica que combina grafos de conocimiento y virtualización.

Stardog utiliza un motor de inferencia basado en IA para procesar y proporcionar resultados de consulta de forma eficiente. Es una base de datos de grafos compatible con ACID. Admite lecturas y escrituras concurrentes. Maneja consultas complejas con facilidad gracias a su arquitectura de «última generación». Se utiliza en la gestión de activos informáticos, la gestión y el análisis de datos y proporciona alta disponibilidad. Algunas empresas que utilizan Stardog son Cisco, eBay, la NASA y Finra.
Palabras finales
Las bases de datos gráficas ayudan a consultar fácilmente relaciones de muchos a muchos y a almacenar datos de forma eficaz. Son escalables, seguras y pueden integrarse con muchas herramientas, API y lenguajes de terceros. En los últimos años, se han integrado con la nube y ofrecen el mejor rendimiento.
Simplifican las uniones complejas en consultas sencillas, lo que facilita la tarea de los desarrolladores. Las tareas intensivas en datos como IoT y Big Data también son bases de datos gráficas. Éstas seguirán evolucionando y seguramente se ampliarán a otros casos de uso en el futuro.