Hadoop y Spark, ambos desarrollados por la Apache Software Foundation, son marcos de código abierto ampliamente utilizados para arquitecturas de big data. En estos momentos nos encontramos realmente en el corazón del fenómeno Big Data, y las empresas ya no pueden ignorar el impacto de los datos en su toma de decisiones, por lo que es necesaria una comparación cara a cara de Hadoop frente a Spark.
Como recordatorio, los datos considerados Big Data cumplen tres criterios: velocidad, rapidez y variedad. Sin embargo, no se pueden procesar los Big Data con los sistemas y tecnologías tradicionales.
Con el fin de superar este problema, la Apache Software Foundation ha propuesto las soluciones más utilizadas, a saber, Hadoop y Spark.
Sin embargo, a las personas que se inician en el procesamiento de Big Data les cuesta entender estas dos tecnologías. Para despejar todas las dudas, conozca en este artículo las diferencias clave entre Hadoop y Spark y cuándo debe elegir una u otra, o utilizarlas juntas.
Hadoop
Hadoop es una utilidad de software compuesta por varios módulos que forman un ecosistema para el procesamiento de Big Data. El principio utilizado por Hadoop para este procesamiento es la distribución distribuida de los datos para procesarlos en paralelo.
La configuración del sistema de almacenamiento distribuido de Hadoop se compone de varios ordenadores ordinarios, formando así un clúster de varios nodos. La adopción de este sistema permite a Hadoop procesar eficazmente la enorme cantidad de datos disponibles realizando múltiples tareas de forma simultánea, rápida y eficiente.
Los datos procesados con Hadoop pueden adoptar muchas formas. Pueden estar estructurados como tablas de Excel o tablas de un DBMS convencional. Estos datos también pueden presentarse de forma semiestructurada, como archivos JSON o XML. Hadoop también admite datos no estructurados como imágenes, vídeos o archivos de audio.
Componentes principales
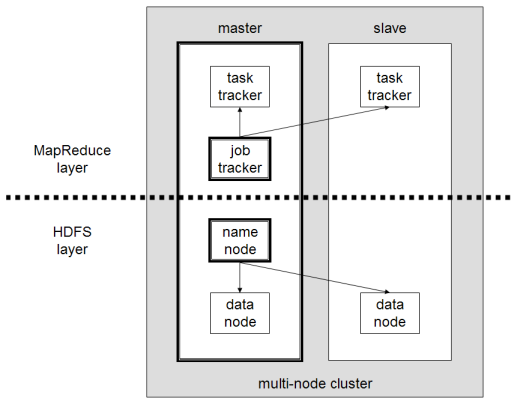
Los principales componentes de Hadoop son
- HDFS o Sistema de Archivos Distribuidos de Hadoop es el sistema utilizado por Hadoop para realizar el almacenamiento distribuido de datos. Está compuesto por un nodo maestro que contiene los metadatos del clúster y varios nodos esclavos en los que se almacenan los datos propiamente dichos;
- MapReduce es el modelo algorítmico utilizado para procesar estos datos distribuidos. Este patrón de diseño puede implementarse utilizando varios lenguajes de programación, como Java, R, Scala, Go, JavaScript o Python. Se ejecuta dentro de cada nodo en paralelo;
- Hadoop Common, en el que varias utilidades y bibliotecas dan soporte a otros componentes de Hadoop;
- YARN es una herramienta de orquestación para gestionar los recursos del clúster Hadoop y la carga de trabajo realizada por cada nodo. También soporta la implementación de MapReduce desde la versión 2.0 de este framework.
Apache Spark
Apache Spark es un marco de trabajo de código abierto creado inicialmente por el informático Matei Zaharia como parte de su doctorado en 2009. Posteriormente se unió a la Apache Software Foundation en 2010.

Spark es un motor de cálculo y procesamiento de datos distribuido en varios nodos. La principal especificidad de Spark es que realiza el procesamiento en memoria, es decir, utiliza la memoria RAM para almacenar en caché y procesar los grandes datos distribuidos en el clúster. Esto le confiere un mayor rendimiento y una velocidad de procesamiento muy superior.
Spark admite varias tareas, como el procesamiento por lotes, el procesamiento de flujo real, el aprendizaje automático y el cálculo de gráficos. También podemos procesar datos de varios sistemas, como HDFS, RDBMS o incluso bases de datos NoSQL. La implementación de Spark puede realizarse con varios lenguajes, como Scala o Python.
Componentes principales
Los principales componentes de Apache Spark son:
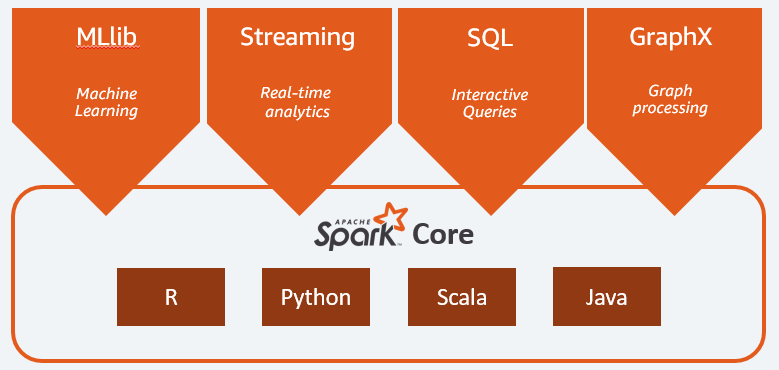
- Spark Core es el motor general de toda la plataforma. Se encarga de planificar y distribuir las tareas, coordinar las operaciones de entrada/salida o recuperarse de cualquier avería;
- Spark SQL es el componente que proporciona el esquema RDD que admite datos estructurados y semiestructurados. En concreto, permite optimizar la recopilación y el procesamiento de datos de tipo estructurado mediante la ejecución de SQL o proporcionando acceso al motor SQL;
- SparkStreaming que permite el análisis de datos en streaming. Spark Streaming admite datos procedentes de diferentes fuentes como Flume, Kinesis o Kafka;
- MLib, la biblioteca integrada de Apache Spark para el aprendizaje automático. Proporciona varios algoritmos de aprendizaje automático, así como varias herramientas para crear pipelines de aprendizaje automático;
- GraphX combina un conjunto de API para realizar modelizaciones, cálculos y análisis de gráficos dentro de una arquitectura distribuida.
Hadoop vs Spark: Diferencias
Spark es un motor de cálculo y procesamiento de datos Big Data. Así que, en teoría, es un poco como Hadoop MapReduce, que es mucho más rápido ya que se ejecuta en memoria. Entonces, ¿en qué se diferencian Hadoop y Spark? Echemos un vistazo:

- Spark es mucho más eficiente, en particular gracias al procesamiento en memoria, mientras que Hadoop procede por lotes;
- Spark es mucho más caro en términos de coste, ya que requiere una cantidad significativa de RAM para mantener su rendimiento. Hadoop, por su parte, sólo depende de una máquina ordinaria para el procesamiento de datos;
- Hadoop es más adecuado para el procesamiento por lotes, mientras que Spark es más adecuado cuando se trata de datos en flujo o flujos de datos no estructurados;
- Hadoop es más tolerante a los fallos, ya que replica continuamente los datos, mientras que Spark utiliza conjuntos de datos distribuidos resilientes (RDD), que a su vez se basan en HDFS.
- Hadoop es más escalable, ya que sólo es necesario añadir otra máquina si las existentes ya no son suficientes. Spark depende del sistema de otros marcos, como HDFS, para ampliarse.
| Factor | Hadoop | Spark |
|---|---|---|
| Procesamiento | Procesamiento por lotes | Procesamiento en memoria |
| Gestión de archivos | HDFS | Utiliza HDFS de Hadoop |
| Velocidad | Rápido | de 10 a 1000 veces más rápido |
| Soporte de lenguajes | Java, Python, Scala, R, Go y JavaScript | Java, Python, Scala y R |
| Tolerancia a fallos | Más tolerante | Menos tolerante |
| Coste | Menos caro | Más caro |
| Escalabilidad | Más escalable | Menos escalable |
Hadoop es bueno para
Hadoop es una buena solución si la velocidad de procesamiento no es crítica. Por ejemplo, si el procesamiento de datos puede realizarse de un día para otro, tiene sentido considerar el uso de MapReduce de Hadoop.
Hadoop permite descargar grandes conjuntos de datos de almacenes de datos en los que resulta comparativamente difícil procesarlos, ya que el HDFS de Hadoop ofrece a las organizaciones una forma mejor de almacenar y procesar los datos.
Spark es bueno para:
Los conjuntos de datos distribuidos resistentes (RDD) de Spark permiten múltiples operaciones de mapeo en memoria, mientras que MapReduce de Hadoop tiene que escribir los resultados intermedios en disco, lo que convierte a Spark en la opción preferida si desea realizar análisis de datos interactivos en tiempo real.
El procesamiento en memoria de Spark y su compatibilidad con bases de datos distribuidas como Cassandra o MongoDB es una solución excelente para la migración e inserción de datos, es decir, cuando los datos se recuperan de una base de datos de origen y se envían a otro sistema de destino.
Utilización conjunta de Hadoop y Spark

A menudo hay que elegir entre Hadoop y Spark; sin embargo, en la mayoría de los casos, elegir puede ser innecesario, ya que estos dos marcos pueden coexistir muy bien y trabajar juntos. De hecho, el principal motivo que impulsó el desarrollo de Spark fue mejorar Hadoop en lugar de sustituirlo.
Como hemos visto en secciones anteriores, Spark puede integrarse con Hadoop utilizando su sistema de almacenamiento HDFS. De hecho, ambos realizan un procesamiento de datos más rápido dentro de un entorno distribuido. Del mismo modo, puede asignar datos en Hadoop y procesarlos utilizando Spark o ejecutar trabajos dentro de Hadoop MapReduce.
Conclusión
¿Hadoop o Spark? Antes de elegir el marco de trabajo, debe tener en cuenta su arquitectura, y las tecnologías que la componen deben ser coherentes con el objetivo que desea alcanzar. Además, Spark es totalmente compatible con el ecosistema Hadoop y funciona a la perfección con Hadoop Distributed File System y Apache Hive.