La diferencia entre los productos mediocres y los grandes productos es la tala de árboles. Aprenda por qué es así y cómo unirlo todo.
Al igual que la seguridad, el registro es otro componente clave de las aplicaciones web (o de las aplicaciones en general) que se deja de lado debido a los viejos hábitos y a la incapacidad de ver el futuro. Lo que muchos ven como inútiles resmas de cinta digital son poderosas herramientas para mirar dentro de sus aplicaciones, corregir errores, mejorar las áreas débiles y deleitar a los clientes.
Antes de pasar al registro centralizado, veamos primero por qué el registro es tan importante.
Dos tipos (niveles) de registro
Los ordenadores son sistemas deterministas, excepto cuando no lo son.
Como desarrollador profesional, me he encontrado con muchos casos en los que el comportamiento observado de la aplicación desconcertaba a todo el mundo durante días y días, pero la clave siempre estaba en los registros. Cada pieza de software que ejecutamos produce (o al menos debería generar) registros, que nos dicen qué estaba pasando cuando se produjo la situación problemática.
Ahora bien, los registros, tal y como yo los veo, son de dos tipos: registros autogenerados y registros generados por el programador. Tenga en cuenta que esto no es ninguna diferenciación de libro de texto, y citarme en esta terminología le traerá problemas 😉
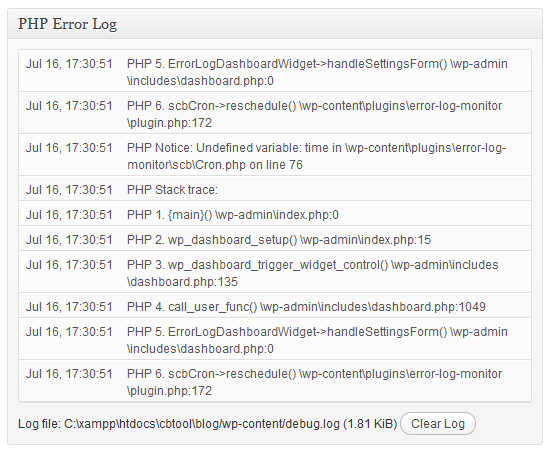
La imagen de arriba muestra lo que puede denominarse un registro autogenerado.
En este caso concreto, se trata de un sistema WordPress registrando una condición inesperada (un Aviso) al ejecutar algún código PHP. Registros como estos se generan todo el tiempo de forma incansable: por herramientas de bases de datos como MySQL, servidores web como Apache, lenguajes y entornos de programación, dispositivos móviles e incluso sistemas operativos.
Rara vez contienen mucho valor, y los programadores ni siquiera se molestan en mirarlos, excepto cuando algo va mal. En esos momentos, indagan a fondo en los registros, tratando de entender qué fue mal.
Pero los registros autogenerados sólo pueden ayudar hasta cierto punto. Si varias personas tienen acceso de administrador a un sitio, por ejemplo, y a una de ellas se le ocurre borrar una información esencial, es imposible detectar al culpable con el uso de registros autogenerados. Desde la perspectiva de los sistemas unidos como la aplicación, se trataba simplemente de un día más en el trabajo: alguien tenía la autoridad necesaria para ejecutar una tarea y el sistema la llevó a cabo.
Lo que se necesita aquí es una capa adicional de registro explícito y extenso que cree rastros para el lado humano de las cosas. Esto es lo que yo denomino registros generados por el programador, y forman la columna vertebral de industrias sensibles como la banca. He aquí un ejemplo de lo que podría ser un esquema de registro de este tipo:
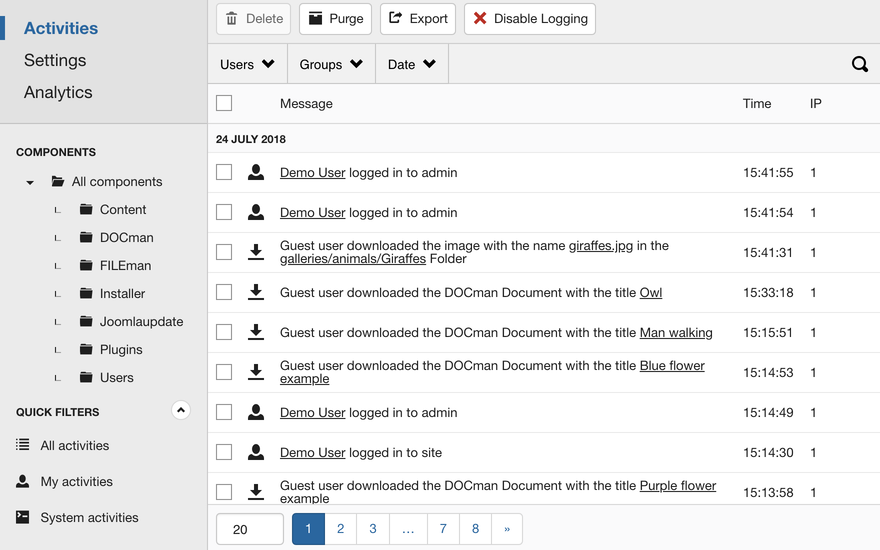
El registro es poder
Así que, teniendo en cuenta estos dos tipos de registros en un sistema, he aquí cómo puede aprovecharlos y aumentar su impacto.
Adelantarse al cliente
«Satisfacer al cliente» ha llegado a conocerse como un truco de marketing inútil, pero gracias al registro, puede hacerse muy real. Conozco productos digitales que vigilan sus registros como un halcón, y en cuanto un cliente rompe algo en la página, pueden llamarle y ofrecerle ayuda.

Piénselo: a los pocos segundos de recibir un feo error, recibe una llamada de la empresa que le dice: «Oiga, tengo entendido que estaba intentando añadir este artículo al carrito, pero no paraba de fallar. ¿Le parece bien que lo añada esta vez y complete el pedido por usted?»
¿Un cliente encantado? Por supuesto
Moral y productividad del equipo
Como he dicho antes, cuando los errores permanecen sin seguimiento durante mucho tiempo, los desarrolladores de su equipo se frustran y pierden cada vez más tiempo persiguiéndose la cola. Y esto es lo que pasa con la depuración: requiere una mente fresca y curiosa desde el principio. Si un pensamiento de WTF se le mete en la cabeza, todo el proceso se va al garete.

¿Y qué dificulta la depuración? Según mi experiencia, la falta de registro, o el desconocimiento del registro. Para empezar, puede que no se dé cuenta de que su base de datos favorita es también otra pieza de software que genera registros, o que no esté registrando extensamente en su aplicación (véase más arriba registros generados por el programador ).
Recuerdo especialmente un caso en el que la aplicación dejaba de responder y nadie sabía por qué. Unos días más tarde, el culpable era el límite de E/S del disco alcanzado debido a un tráfico excesivo. Como nadie se molestó en mirar ahí, nadie pudo averiguar por qué.
Registros de auditoría
¿Y si dos años después su cliente dice que todos esos pedidos no los hizo él, sino algún pirata informático?
¿Qué argumento tendría para atender o rechazar su petición? Si dispone de un registro exhaustivo (dirección IP, fecha y hora, tarjeta de crédito, etc.), podrá analizar todo eso y tomar una decisión. Buena o mala, al menos tendrá alguna base objetiva, en lugar de parecerse a un tiro en la oscuridad.

Lo mismo ocurre si se encuentra bajo algún prisma normativo o si debe someterse a una auditoría de terceros como parte de un proyecto nuevo e importante. No disponer de un sistema de registro sólido le dejará en mal lugar.
Mejorar los sistemas existentes
¿Cómo proceder para mejorar el sistema actual?
¿Debe limitarse a echarle más RAM e hilos de CPU? ¿Y si su aplicación es lenta a pesar de contar con suficientes recursos? ¿Dónde está el cuello de botella? La mayoría de las veces, el registro es la respuesta.
Por ejemplo, todos los principales sistemas de bases de datos disponen de una función para registrar las consultas lentas.
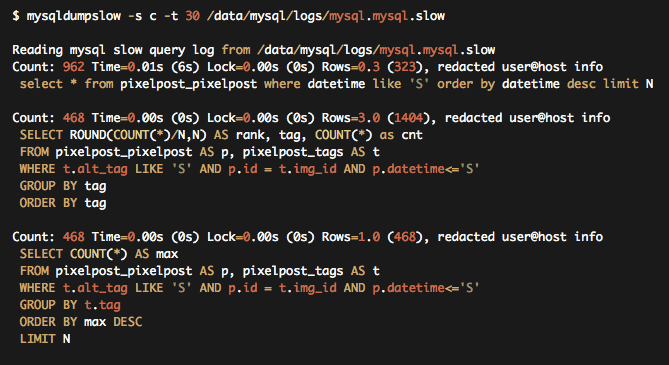
Si visita el registro de consultas lentas con regularidad, podrá saber qué operaciones están tardando más tiempo y, por lo tanto, descubrirá pequeñas pero importantes áreas que necesitan trabajo. A menudo, un pequeño cambio como éste funciona mejor que duplicar la capacidad del hardware.
No se puede contar de cuántas maneras le ayuda un buen sistema de registro. Quizá el mejor argumento sea que se trata de una actividad automatizada que, una vez puesta en marcha, no necesita ninguna supervisión y que algún día le salvará de la ruina.
Con eso fuera del camino, echemos un vistazo a algunos de los increíbles recopiladores de registros de código abierto (herramientas unificadas de registro) que existen. En caso de que se lo esté preguntando, ya cubrimos las herramientas comerciales de registro basadas en la nube en un post anterior.
Graylog
Graylog es uno de los nombres líderes en la industria cuando se trata de capacidades de registro y visualización de nivel industrial. También es único en el sentido de que escanea sus registros recopilados en busca de signos de vulnerabilidades de seguridad y se lo notifica al instante.
Aunque Graylog es un sistema de registro centralizado, tiene la flexibilidad que usted necesita, ya que le permite personalizar las alertas, los paneles y mucho más.

Graylog es de código abierto, pero existe un plan para empresas si sus necesidades son complejas.
Con clientes como SAP, Cisco y LinkedIn en su lista, Graylog es una herramienta en la que puede confiar con los ojos cerrados.
Logstash
Si es fan o usuario de la pila Elastic, merece la pena echar un vistazo a Logstash (la pila ELK ya existe, por si no lo sabía). Al igual que otras herramientas de registro de esta lista, Logstash es totalmente de código abierto, lo que le permite la libertad de desplegar y utilizar como desee.

Pero no se deje engañar: Logstash es una nave nodriza con capacidades que superan con creces a cualquier humilde herramienta de registro. Es capaz de recopilar grandes cantidades de datos de múltiples plataformas, le permite definir y ejecutar sus propias canalizaciones de datos, dar sentido a los volcados de registro no estructurados y mucho más.
Por supuesto, la única limitación es que sólo funciona con la suite de productos Elastic, pero si está empezando y busca escalar pronto, Logstash es el camino a seguir
Fluentd
Entre las herramientas de registro centralizadas que funcionan como capa intermedia para la ingestión de datos, Flutend es la primera entre iguales. Con una excelente biblioteca de plugins, Fluentd es capaz de capturar datos de prácticamente cualquier sistema de producción, amasarlos en la estructura deseada, construir una canalización personalizada y alimentarlos a su plataforma de análisis favorita, ya sea MongoDB o Elasticsearch.
Fluentd está construido sobre Ruby, es completamente de código abierto y es ampliamente popular debido a su flexibilidad y modularidad.
Con grandes empresas como Microsoft, Atlassian y Twilio utilizando la plataforma, Fluentd no tiene nada que demostrar 🙂
Flume
Si su reto son conjuntos de datos muy, muy grandes, y eventualmente quiere alimentar todo a algo como Hadoop, Flume es una de las mejores opciones que existen. Es un proyecto de código abierto «puro», en el sentido de que está mantenido por nuestra querida Fundación Apache, lo que significa que no existe un plan empresarial.
Esto puede o no ser exactamente lo que está buscando 🙂
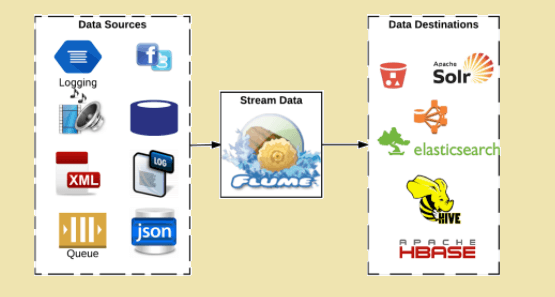
Escrito en Java (que sigue asombrándome cuando se trata de tecnología innovadora), el código fuente de Flume es totalmente abierto. Flume es lo mejor para usted si busca una plataforma de ingestión de datos distribuida y tolerante a fallos para cosas pesadas.
Octopussy
Le doy un cero sobre diez por la denominación del producto, pero Octopussy puede ser una buena opción si sus necesidades son sencillas y se pregunta de qué va todo el alboroto relacionado con las canalizaciones, la ingestión, la agregación, etc.
En mi opinión, Octopussy cubre las necesidades de la mayoría de los productos que existen (las estadísticas estimadas son inútiles, pero si tuviera que adivinar, diría que se ocupa del 80% de los casos de uso en el mundo real).

Octopussy no tiene una gran interfaz de usuario en absoluto, pero lo compensa en cuanto a velocidad y falta de hinchazón. El código fuente está disponible en GitHub, como era de esperar, y creo que merece la pena echarle un vistazo en serio.
Rsyslog
Rsyslog significa un sistema rápido como un cohete para el procesamiento de registros.
Es una utilidad para sistemas operativos tipo Unix. En términos técnicos, es un enrutador de mensajes con entradas y salidas cargables dinámicamente y altamente configurable.
Puede tomar entradas de múltiples fuentes de datos, transformarlas y enviar la salida a varios destinos. Con Rsyslog, puede enviar 1 millón de mensajes por segundo a través de destinos locales.
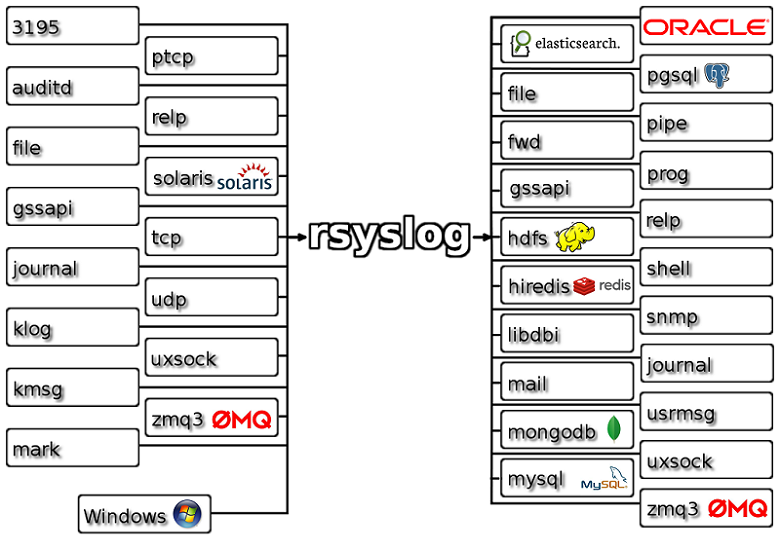
Rsyslog también proporciona un agente Windows que trabaja muy estrechamente con el agente Rsyslog Linux. Se utiliza para la integración entre los dos entornos. Este agente de Windows se utiliza para reenviar los registros de eventos de Windows y configurar el servicio de monitorización de archivos.
A continuación se detallan otras características ofrecidas por Rsyslog:
- Configuraciones flexibles
- Proporciona capacidades multihilo
- Protección contra la manipulación de archivos de registro mediante firmas de registro y cifrado.
- Soporta plataformas Big Data
- Proporciona capacidades de filtrado basadas en el contenido
Grafana Loki
Inspirada en Prometheus, Grafana Loki es una solución de agregación de registros multi-tenant.
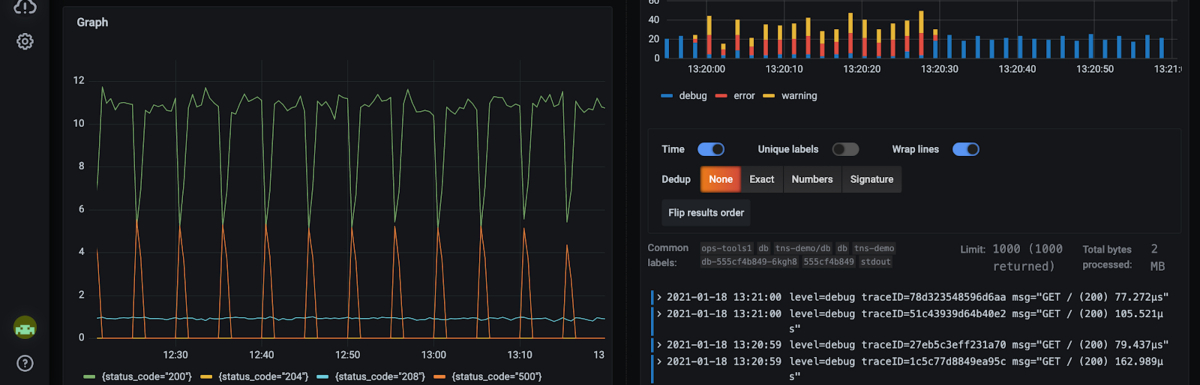
La solución Loki es rentable, sólo indexa metadatos y puede conectarse a un sistema popular como Kubernetes, Prometheus, Linux, SQL, etc. Puede consultar esta guía de inicio para instalarlo y comprobar usted mismo cómo funciona.
Logwatch
Estoy seguro de que hay algunos entre nosotros que no quieren toda la ceremonia asociada a un sistema de registro «unificado», «centralizado». Su negocio proviene de servidores individuales, y buscan algo rápido y eficaz para vigilar sus archivos de registro. Pues bien, salude a Logwatch.
Una vez instalado, LogWatch puede escanear los registros de su sistema y crear un informe del tipo que desee. Es una pieza de software algo anticuada (léase «fiable»), sin embargo, y fue escrita en Perl. Por lo tanto, necesitará Perl 5.6 en su servidor para ejecutarlo. No tengo capturas de pantalla para compartir ya que es un proceso puramente de línea de comandos, daemonizado.
Si es un adicto a la CLI y le gusta la forma de hacer las cosas de la vieja escuela, ¡le encantará Logwatch!
Syslog-ng
La herramienta Syslog-ng se desarrolló como una forma de procesar archivos de datos Syslog (un protocolo cliente-servidor establecido para el registro de sistemas) en tiempo real. Con el tiempo, sin embargo, ha llegado a soportar otros formatos de datos: no estructurados, SQL y NoSQL. El funcionamiento del protocolo Syslog se resume de forma bastante clara en la siguiente ilustración.
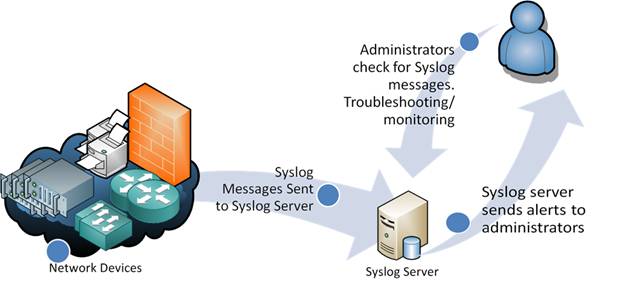
syslog-ng es una herramienta de recopilación y clasificación de registros fiable y de nivel de producción que fue escrita en C y lleva mucho tiempo siendo un nombre consolidado en la industria. Lo mejor es su extensibilidad, que le permite escribir complementos en C, Python, Java, Lua o Perl.
Abreviatura de (Log Navigator), lnav es una herramienta de terminal pura que funciona en una sola máquina, un solo directorio. Es para aquellos que tienen sus logs unificados en un único directorio o quieren filtrar y mostrar logs en tiempo real desde una única fuente.
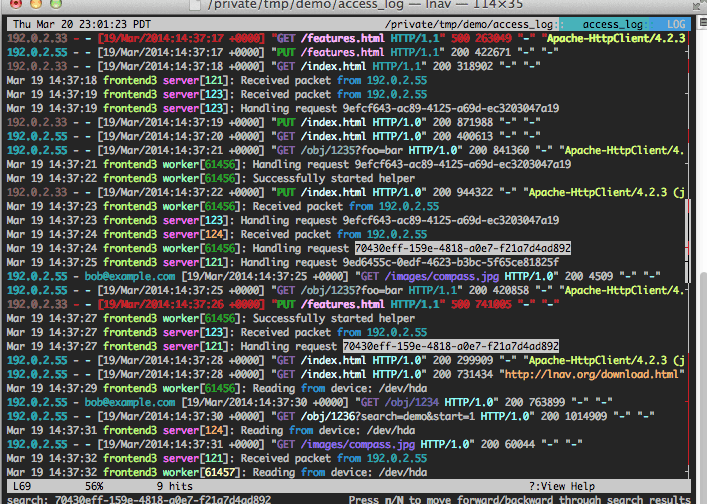
Si pensaba que lnav no era más que un tailf|grep glorificado se equivocaría. Hay varias características que harán que se enamore de él: vista de series temporales, impresión bonita (para JSON y otros formatos), fuentes de registro codificadas por colores, potentes filtros, capacidad para entender varios protocolos de registro y mucho más.
Es sólo que a veces uno quiere una capa de registro sin complicaciones, sin configuración y tal vez temporal, ¡y lnav encaja a la perfección!
Conclusión
¡Y ahí lo tiene!
Fue una lista difícil de compilar, para ser francos, ya que el registro no es tan popular como, por ejemplo, la gestión de contenidos, y todo el mindshare parece haber sido acaparado por tres o cuatro herramientas. Aun así, las necesidades de cada uno son diferentes, y he intentado cubrirlas ampliamente.
Desde herramientas tontas de línea de comandos y sin configuración hasta auténticos monstruos de los datos, ¡todo está aquí!
A continuación, explore algunos de los mejores programas de creación de perfiles para optimizar la aplicación.