
Apache Parquet ofrece varias ventajas para el almacenamiento y la recuperación de datos en comparación con métodos tradicionales como CSV.
El formato Parquet está diseñado para un procesamiento más rápido de datos de tipos complejos. En este artículo, hablamos de cómo el formato Parquet es adecuado para las necesidades actuales de datos, cada vez mayores.
Antes de profundizar en los detalles del formato Parquet, entendamos qué son los datos CSV y los retos que plantean para el almacenamiento de datos.
¿Qué es el almacenamiento CSV?
Todos hemos oído hablar mucho del formato CSV( valores separadospor comas), una de las formas más comunes de organizar y formatear datos. El almacenamiento de datos CSV se basa en filas. Los archivos CSV se almacenan con la extensión .csv. Podemos almacenar y abrir datos CSV utilizando Excel, Google Sheets o cualquier editor de texto. Los datos se pueden ver fácilmente una vez abierto el archivo.
Eso no es bueno, y menos para un formato de base de datos.
Además, a medida que aumenta el volumen de datos, resulta difícil consultarlos, gestionarlos y recuperarlos.
He aquí un ejemplo de datos almacenados en un archivo .CSV:
EmpId,Nombre,Apellido, División
2012011,Sam,Butcher,IT
2013031,Mike,Johnson,Recursos Humanos
2010052,Bill,Matthew,Arquitecto
2010079,Jose,Brian,IT
2012120,Adam,James,Soluciones
Si lo visualizamos en Excel, podemos ver una estructura fila-columna como la siguiente:
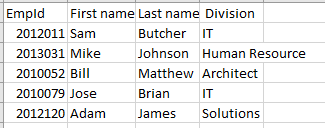
Retos del almacenamiento CSV
Los almacenamientos basados en filas como CSV son adecuados para las operaciones Crear, Actualizary Eliminar.
¿Qué ocurre entonces con la Lecturaen CRUD?
Imagine un millón de filas en el archivo .csv anterior. Tardaría un tiempo razonable en abrir el archivo y buscar los datos que busca. No es tan genial. La mayoría de los proveedores de la nube, como AWS, cobran a las empresas en función de la cantidad de datos explorados o almacenados; de nuevo, los archivos CSV consumen mucho espacio.
El almacenamiento de CSV no tiene una opción exclusiva para almacenar metadatos, lo que convierte el escaneado de datos en una tarea tediosa.
Entonces, ¿cuál es la solución rentable y óptima para realizar todas las operaciones CRUD? Exploremos.
¿Qué es el almacenamiento de datos Parquet?
Parquet es un formato de almacenamiento de código abierto para almacenar datos. Se utiliza ampliamente en los ecosistemas Hadoop y Spark. Los archivos Parquet se almacenan como extensiones .parquet.
Parquet es un formato altamente estructurado. También puede utilizarse para optimizar datos complejos en bruto presentes a granel en los lagos de datos. Esto puede reducir significativamente el tiempo de consulta.
Parquet hace que el almacenamiento de datos sea eficiente y la recuperación más rápida gracias a una mezcla de formatos de almacenamiento basados en filas y columnas (híbridos). En este formato, los datos se particionan tanto horizontal como verticalmente. El formato parquet también elimina en gran medida la sobrecarga del análisis sintáctico.
El formato restringe el número total de operaciones de E/S y, en última instancia, el coste.
Parquet también almacena los metadatos, que guardan información sobre los datos como el esquema de datos, el número de valores, la ubicación de las columnas, el valor mínimo, el valor máximo, el número de grupos de filas, el tipo de codificación, etc. Los metadatos se almacenan en distintos niveles del archivo, lo que agiliza el acceso a los datos.
En el acceso basado en filas, como el CSV, la recuperación de datos lleva tiempo, ya que la consulta tiene que navegar por cada fila y obtener los valores concretos de las columnas. Con el almacenamiento en Parquet, se puede acceder a todas las columnas necesarias de una sola vez.
En resumen,
- Parquet se basa en la estructura columnar para el almacenamiento de datos
- Es un formato de datos optimizado para almacenar datos complejos en bloque en sistemas de almacenamiento
- El formato Parquet incluye varios métodos de compresión y codificación de datos
- Reduce significativamente el tiempo de escaneo de datos y el tiempo de consulta y ocupa menos espacio en disco en comparación con otros formatos de almacenamiento como CSV
- Minimiza el número de operaciones de E/S, reduciendo el coste de almacenamiento y de ejecución de consultas
- Incluye metadatos que facilitan la búsqueda de datos
- Ofrece soporte de código abierto
Formato de datos Parquet
Antes de entrar en un ejemplo, vamos a entender cómo se almacenan los datos en el formato Parquet con más detalle:
Podemos tener múltiples particiones horizontales conocidas como grupos de Filas en un archivo. Dentro de cada grupo de Filas, se aplica una partición vertical. Las columnas se dividen en varios grupos de columnas. Los datos se almacenan como páginas dentro de los chunks de columna. Cada página contiene los valores de los datos codificados y los metadatos. Como hemos mencionado antes, los metadatos de todo el archivo también se almacenan en el pie del archivo a nivel del grupo de filas.
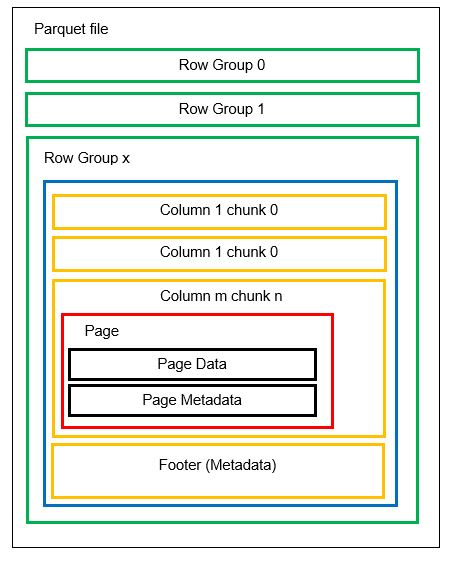
Como los datos se dividen en trozos de columnas, añadir nuevos datos codificando los nuevos valores en un nuevo trozo y archivo también es fácil. A continuación, se actualizan los metadatos de los archivos y grupos de filas afectados. Así pues, podemos decir que Parquet es un formato flexible.
Parquet soporta de forma nativa la compresión de datos mediante técnicas de compresión de páginas y codificación de diccionarios. Veamos un ejemplo sencillo de compresión de diccionario:

Observe que en el ejemplo anterior, vemos la división IT 4 veces. Así que, mientras se almacena en el diccionario, el formato codifica los datos con otro valor fácil de almacenar (0,1,2…) junto con el número de veces que se repite continuamente: IT, IT se cambia a 0,2 para ahorrar más espacio. La consulta de datos comprimidos requiere menos tiempo.
Comparación cara a cara
Ahora que ya tenemos una idea de cómo son los formatos CSV y Parquet, es hora de realizar algunas estadísticas para comparar ambos formatos:
| CSV | Parquet |
| Formato de almacenamiento basado en filas. | Es un híbrido de los formatos de almacenamiento basado en filas y basado en columnas. |
| Consume mucho espacio ya que no dispone de ninguna opción de compresión por defecto. Por ejemplo, un archivo de 1 TB ocupará el mismo espacio si se almacena en Amazon S3 o en cualquier otra nube. | Comprime los datos mientras los almacena, por lo que consume menos espacio. Un archivo de 1 TB almacenado en formato Parquet ocupará sólo 130 GB de espacio. |
| El tiempo de ejecución de las consultas es lento debido a la búsqueda basada en filas. Para cada columna, hay que recuperar cada fila de datos. | El tiempo de consulta es unas 34 veces más rápido debido al almacenamiento basado en columnas y a la presencia de metadatos. |
| Hay que escanear más datos por consulta. | Se escanean alrededor de un 99% menos de datos para la ejecución de la consulta, lo que optimiza el rendimiento. |
| La mayoría de los dispositivos de almacenamiento cobran en función del espacio de almacenamiento, por lo que el formato CSV supone un elevado coste de almacenamiento. | Menor coste de almacenamiento ya que los datos se almacenan en formato comprimido y codificado. |
| El esquema del archivo tiene que inferirse (lo que da lugar a errores) o suministrarse (tedioso). | El esquema del archivo se almacena en los metadatos. |
| El formato es adecuado para tipos de datos sencillos. | Parquet es adecuado incluso para tipos complejos como esquemas anidados, matrices, diccionarios. |
Conclusión 👩💻
Hemos visto a través de ejemplos que Parquet es más eficiente que CSV en términos de coste, flexibilidad y rendimiento. Es un mecanismo eficaz para almacenar y recuperar datos, especialmente cuando el mundo entero se está moviendo hacia el almacenamiento en la nube y la optimización del espacio. Las principales plataformas como Azure, AWS y BigQuery soportan el formato Parquet.