
Imagine que tiene una gran infraestructura de diversos tipos de dispositivos que necesita mantener con regularidad o asegurarse de que no son peligrosos para el entorno.
Una forma de conseguirlo es enviando regularmente personal a cada punto para comprobar si todo está bien. Esto es algo factible pero también bastante costoso en tiempo y recursos. Y si la infraestructura es lo suficientemente grande, es posible que no pueda cubrirla por completo en un año.
Otra forma es automatizar ese proceso y dejar que los trabajos en la nube lo verifiquen por usted. Para ello, tendrá que hacer lo siguiente:
👉 Un proceso rápido sobre cómo obtener imágenes de los dispositivos. Esto todavía se puede hacer por las personas, ya que sigue siendo mucho más rápido para hacer sólo una foto como para hacer todos los procesos de verificación de dispositivos. También puede hacerse mediante fotos tomadas desde coches o incluso drones, en cuyo caso se convierte en un proceso de obtención de imágenes mucho más rápido y automatizado.
👉 Luego hay que enviar todas las fotos obtenidas a un lugar dedicado en la nube.
👉 En la nube, necesita un trabajo automatizado para recoger las imágenes y procesarlas a través de modelos de aprendizaje automático entrenados para reconocer daños o anomalías en los dispositivos.
👉 Por último, los resultados deben ser visibles para los usuarios requeridos, de modo que se pueda programar la reparación de los dispositivos con problemas.
Veamos cómo podemos lograr la detección de anomalías a partir de las imágenes en la nube de AWS. Amazon dispone de algunos modelos de aprendizaje automático preconstruidos que podemos utilizar para este fin.
Cómo crear un modelo para la detección visual de anomalías
Para crear un modelo para la detección visual de anomalías, deberá seguir varios pasos:
Paso 1: Defina claramente el problema que desea resolver y los tipos de anomalías que desea detectar. Esto le ayudará a determinar el conjunto de datos de prueba adecuado que necesitará para entrenar el modelo.
Paso 2 : Recopile un gran conjunto de datos de imágenes que representen condiciones normales y anómalas. Etiquete las imágenes para indicar cuáles son normales y cuáles contienen anomalías.
Paso3 : Elija una arquitectura de modelo adecuada para la tarea. Esto puede implicar seleccionar un modelo preentrenado y ajustarlo para su caso de uso específico o crear un modelo personalizado desde cero.
Paso 4: Entrene el modelo utilizando el conjunto de datos preparado y el algoritmo seleccionado. Esto significa utilizar el aprendizaje por transferencia para aprovechar modelos preentrenados o entrenar el modelo desde cero utilizando técnicas como las redes neuronales convolucionales (CNN).
Cómo entrenar un modelo de aprendizaje automático
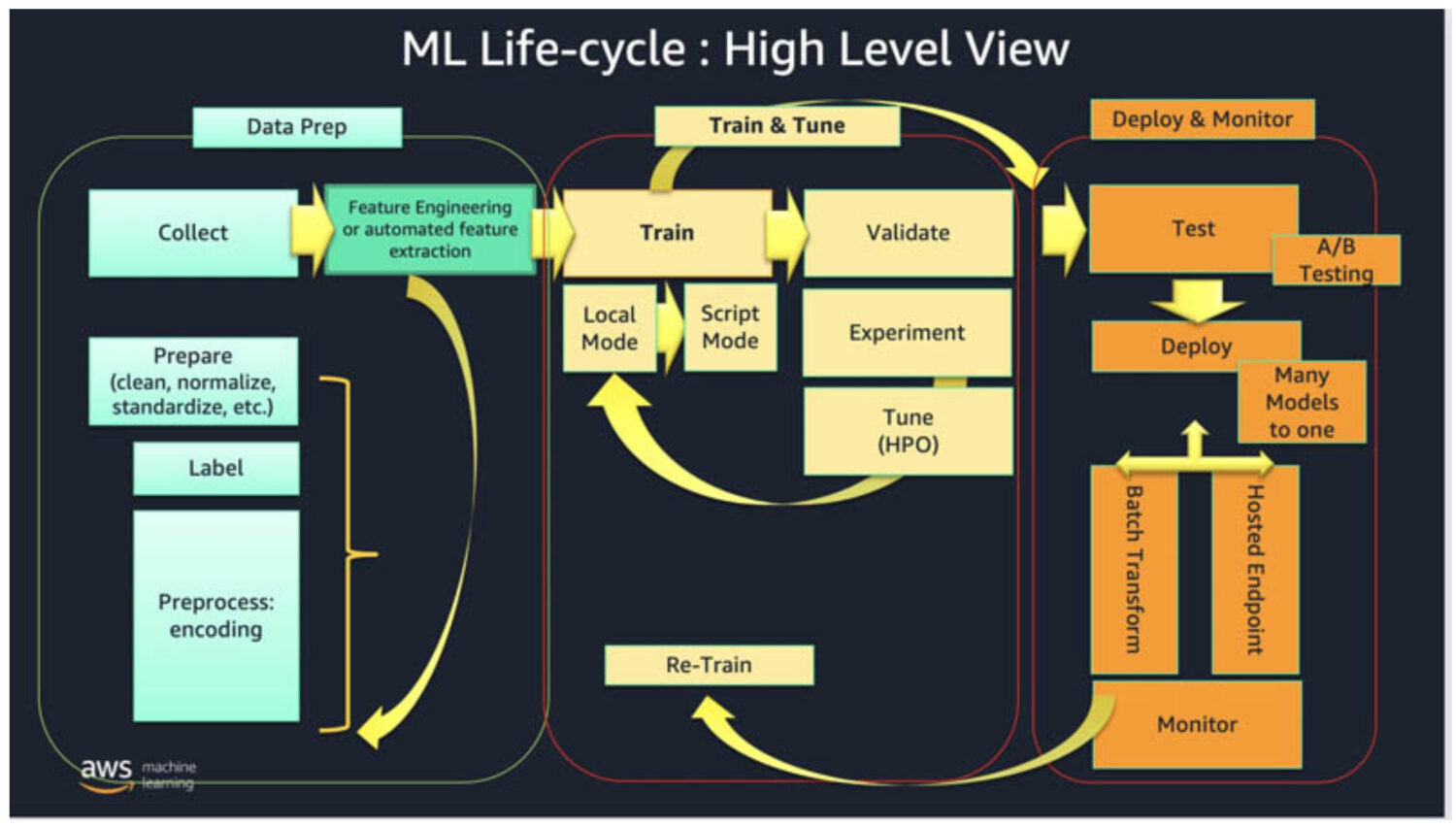
El proceso de entrenamiento de los modelos de aprendizaje automático de AWS para la detección de anomalías visuales suele implicar varios pasos importantes.
#1. Recopilar los datos
Al principio, necesita recopilar y etiquetar un gran conjunto de datos de imágenes que representen tanto las condiciones normales como las anómalas. Cuanto mayor sea el conjunto de datos, mejor y más preciso podrá entrenarse el modelo. Pero también implica dedicar mucho más tiempo al entrenamiento del modelo.
Por lo general, se desea tener alrededor de 1000 imágenes en un conjunto de pruebas para tener un buen comienzo.
#2. Preparar los datos
Primero hay que preprocesar los datos de las imágenes para que los modelos de aprendizaje automático puedan captarlos. El preprocesamiento puede significar varias cosas, como:
- Limpiar las imágenes de entrada en subcarpetas separadas, corregir los metadatos, etc.
- Redimensionar las imágenes para que cumplan los requisitos de resolución del modelo.
- Distribuirlas en trozos más pequeños de imágenes para un procesamiento más eficaz y paralelo.
#3. Seleccionar el modelo
Ahora elija el modelo adecuado para hacer el trabajo adecuado. Elija un modelo preentrenado o puede crear un modelo personalizado adecuado para la detección de anomalías visuales en el modelo.
#4. Evalúe los resultados
Una vez que el modelo procese su conjunto de datos, deberá validar su rendimiento. Además, querrá comprobar si los resultados son satisfactorios para las necesidades. Esto puede significar, por ejemplo, que los resultados son correctos en más del 99% de los datos de entrada.
#5. Despliegue el modelo
Si está satisfecho con los resultados y el rendimiento, despliegue el modelo con una versión específica en el entorno de la cuenta de AWS para que los procesos y servicios puedan comenzar a utilizarlo.
#6. Monitorizar y mejorar
Deje que se ejecute a través de varios trabajos de prueba y conjuntos de datos de imágenes y evalúe constantemente si los parámetros necesarios para la corrección de la detección siguen estando en su sitio.
Si no es así, vuelva a entrenar el modelo incluyendo los nuevos conjuntos de datos en los que el modelo ofreció resultados erróneos.
Modelos de aprendizaje automático de AWS
Veamos ahora algunos modelos concretos que puede aprovechar en la nube de Amazon.
AWS Rekognition
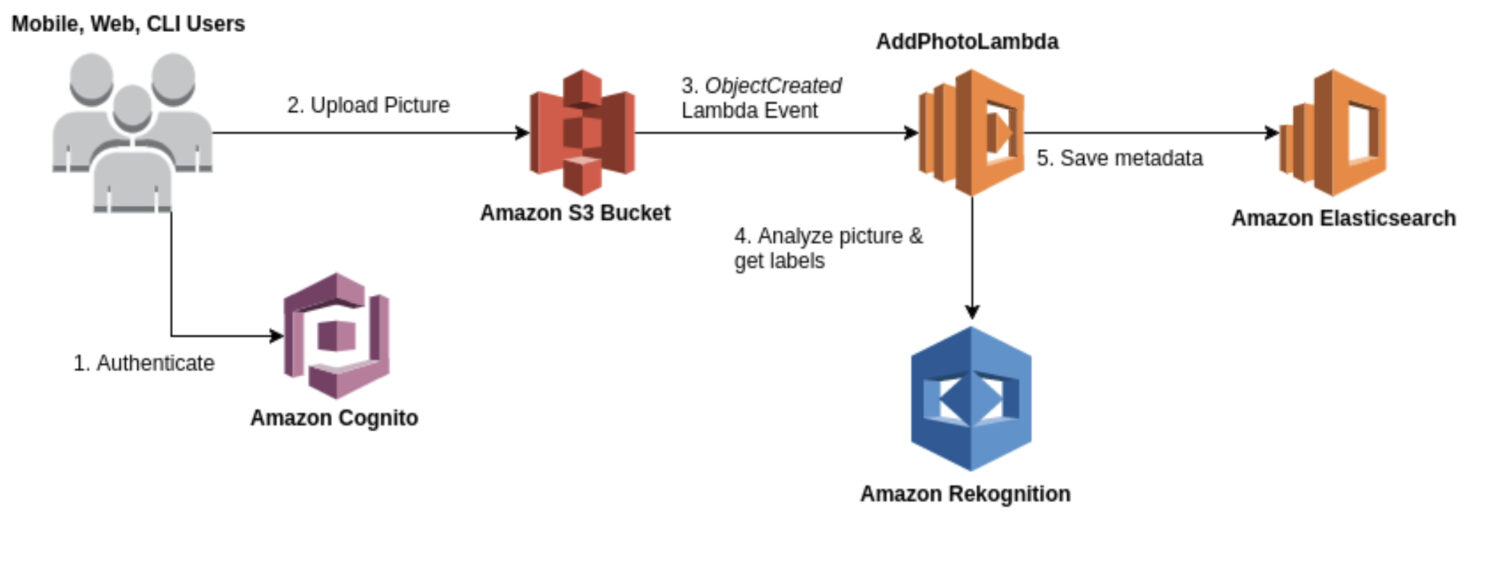
Rekognition es un servicio de análisis de imágenes y vídeos de propósito general que se puede utilizar para diversos casos de uso, como el reconocimiento facial, la detección de objetos y el reconocimiento de texto. La mayoría de las veces, utilizará el modelo Rekognition para una generación inicial en bruto de los resultados de detección para formar un lago de datos de anomalías identificadas.
Proporciona una serie de modelos preconstruidos que puede utilizar sin necesidad de formación. Rekognition también ofrece análisis en tiempo real de imágenes y vídeos con gran precisión y baja latencia.
He aquí algunos casos de uso típicos en los que Rekognition es una buena elección para la detección de anomalías:
- Tener un caso de uso de propósito general para la detección de anomalías, como detectar anomalías en imágenes o vídeos.
- Realice la detección de anomalías en tiempo real.
- Integre su modelo de detección de anomalías con servicios de AWS como Amazon S3, Amazon Kinesis o AWSLambda.
He aquí algunos ejemplos concretos de anomalías que puede detectar con Rekognition:
- Anomalías en rostros, como la detección de expresiones faciales o emociones fuera del rango normal.
- Objetos perdidos o mal colocados en una escena.
- Palabras mal escritas o patrones de texto inusuales.
- Condiciones de iluminación inusuales u objetos inesperados en una escena.
- Contenido inapropiado u ofensivo en imágenes o vídeos.
- Cambios repentinos de movimiento o patrones de movimiento inesperados.
AWS Lookout para la visión
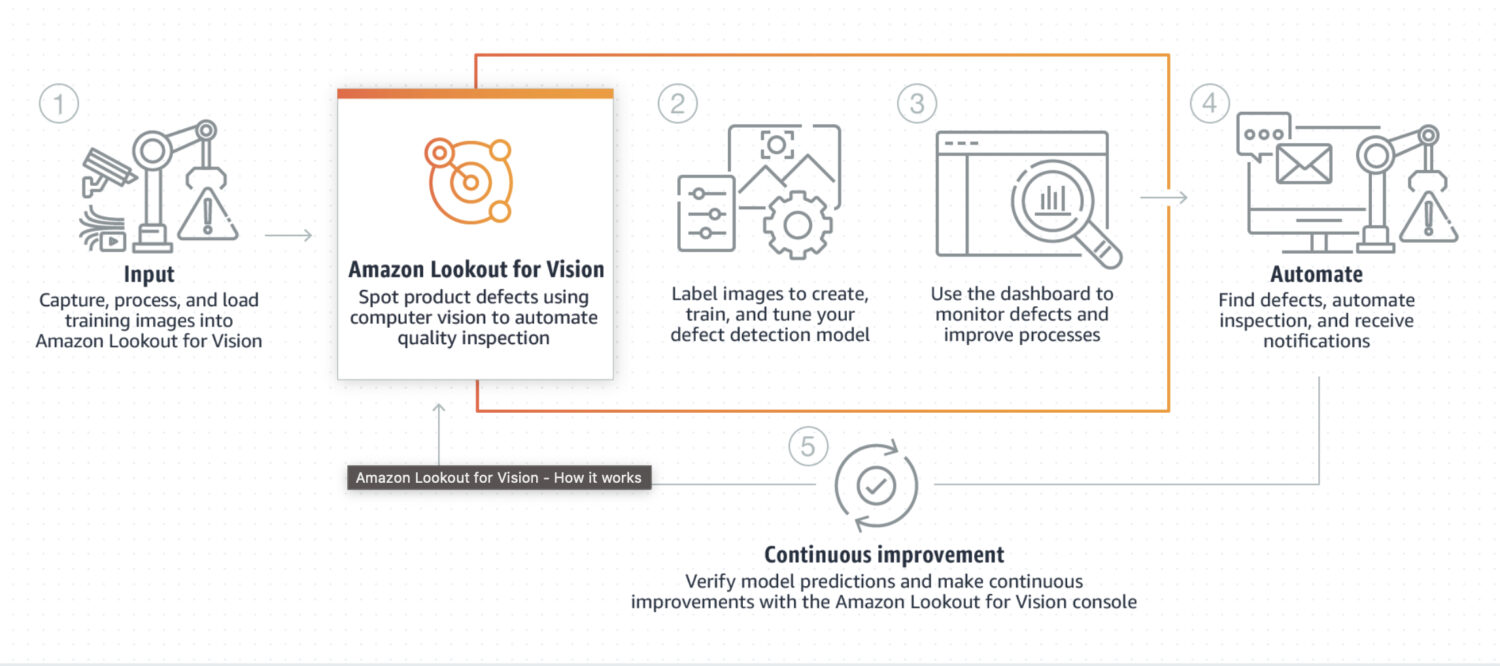
Lookout for Vision es un modelo diseñado específicamente para la detección de anomalías en procesos industriales, como las líneas de fabricación y producción. Suele requerir algún código personalizado de preprocesamiento y postprocesamiento de una imagen o algún recorte concreto de la misma, normalmente realizado con un lenguaje de programación Python. La mayoría de las veces, se especializa en algunos problemas muy especiales de la imagen.
Requiere un entrenamiento personalizado sobre un conjunto de datos de imágenes normales y anómalas para crear un modelo personalizado de detección de anomalías. No está tan enfocado al tiempo real; más bien, está diseñado para el procesamiento por lotes de imágenes, centrándose en la exactitud y la precisión.
Estos son algunos casos de uso típicos en los que Lookout for Vision es una buena opción si necesita detectar
- Defectos en productos manufacturados o identificar fallos en los equipos de una línea de producción.
- Un gran conjunto de imágenes u otros datos.
- Anomalía en tiempo real en un proceso industrial.
- Anomalía integrada con otros servicios de AWS, como Amazon S3 o AWS IoT.
He aquí algunos ejemplos concretos de anomalías que puede detectar con Lookout for Vision:
- Defectos en productos manufacturados, como arañazos, abolladuras u otras imperfecciones, que pueden afectar a la calidad del producto.
- Fallos del equipo en una línea de producción, como la detección de maquinaria rota o en mal funcionamiento que, puede causar retrasos o riesgos para la seguridad.
- Los problemas de control de calidad en una línea de producción incluyen la detección de productos que no cumplen las especificaciones o tolerancias requeridas.
- Los peligros para la seguridad en una línea de producción incluyen la detección de objetos o materiales que puedan suponer un riesgo para los trabajadores o el equipo.
- Las anomalías en un proceso de producción, como la detección de cambios inesperados en el flujo de materiales o productos a través de la línea de producción.
AWS Sagemaker
Sagemaker es una plataforma totalmente gestionada para crear, entrenar e implantar modelos personalizados de aprendizaje automático.
Es una solución mucho más robusta. De hecho, proporciona una forma de conectar y ejecutar varios procesos de varios pasos en una cadena de trabajos que se suceden uno tras otro, de forma muy parecida a lo que pueden hacer las funciones por pasos de AWS.
Pero como Sagemaker utiliza instancias EC2 ad-hoc para su procesamiento, no existe un límite de 15 minutos para el procesamiento de un solo trabajo, como en el caso de las funciones AWS lambda de las AWS Step Functions.
También puede realizar un ajuste automático del modelo con Sagemaker, lo que sin duda es una característica que lo convierte en una opción destacada. Por último, Sagemaker puede desplegar sin esfuerzo el modelo en un entorno de producción.
He aquí algunos casos de uso típicos en los que SageMaker es una buena opción para la detección de anomalías:
- Un caso de uso específico no cubierto por modelos o API preconstruidos, y si necesita construir un modelo personalizado a la medida de sus necesidades específicas.
- Si dispone de un gran conjunto de imágenes u otros datos. Los modelos preconstruidos requieren cierto procesamiento previo en estos casos, pero Sagemaker puede hacerlo sin él.
- Si necesita realizar una detección de anomalías en tiempo real.
- Si necesita integrar su modelo con otros servicios de AWS, como Amazon S3, Amazon Kinesis o AWS Lambda.
He aquí algunas detecciones de anomalías típicas que Sagemaker es capaz de realizar:
- Detección de fraudes en transacciones financieras, por ejemplo, patrones de gasto inusuales o transacciones fuera de lo normal.
- Ciberseguridad en el tráfico de red, como patrones inusuales de transferencia de datos o conexiones inesperadas a servidores externos.
- Diagnóstico médico en imágenes médicas, como la detección de tumores.
- Anomalías en el rendimiento de los equipos, como la detección de cambios en las vibraciones o la temperatura.
- Control de calidad en los procesos de fabricación, como la detección de defectos en los productos o la identificación de desviaciones de los estándares de calidad previstos.
- Patrones inusuales de uso de la energía.
Cómo incorporar los modelos a la arquitectura sin servidor
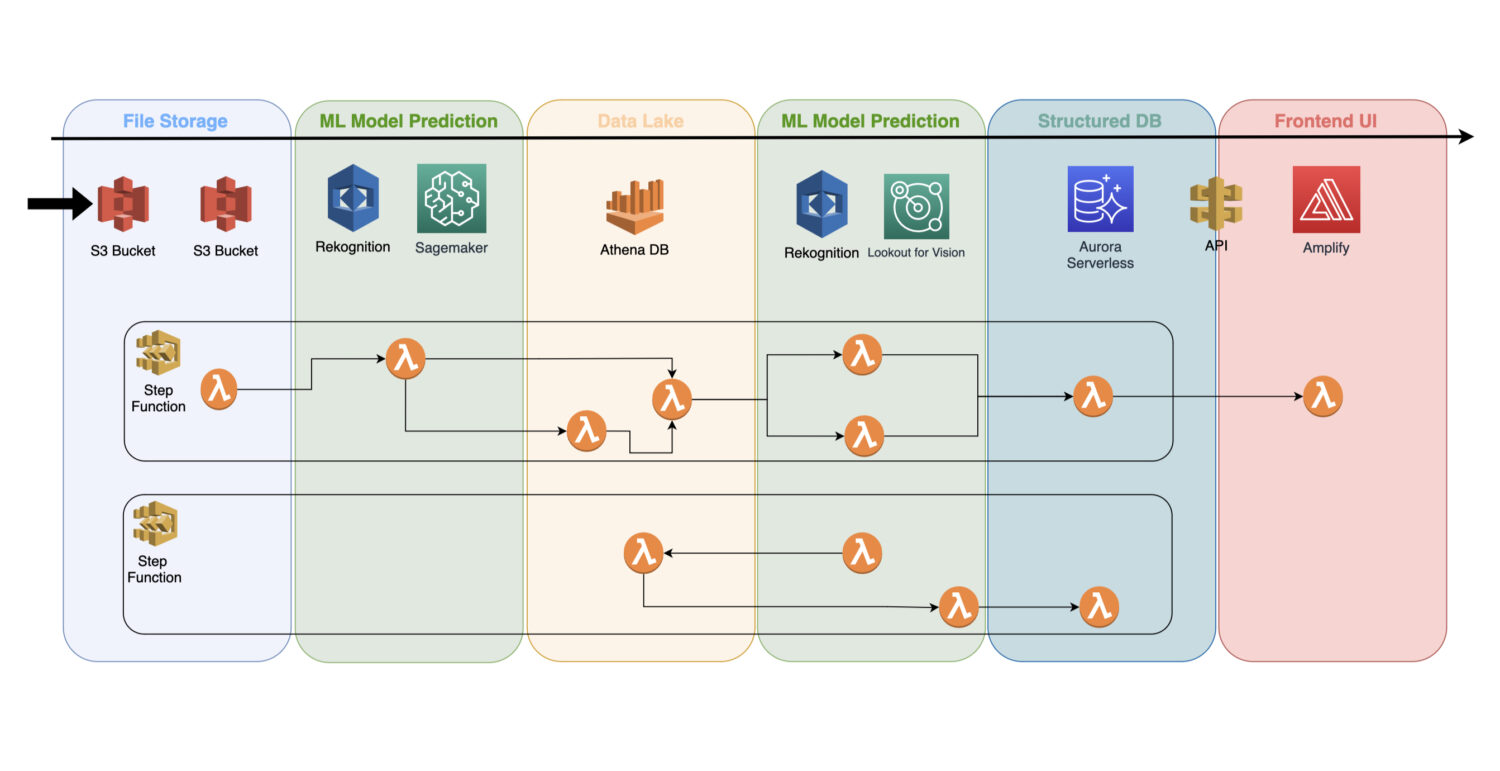
Un modelo de aprendizaje automático entrenado es un servicio en la nube que no utiliza ningún servidor de clúster en segundo plano; por lo tanto, puede incluirse fácilmente en una arquitectura sin servidor existente.
La automatización se realiza a través de funciones AWS lambda, conectadas en un trabajo de múltiples pasos dentro de un servicio AWS Step Functions.
Normalmente, necesitará una detección inicial justo después de recopilar las imágenes y su preprocesamiento en el bucket de S3. Ahí es donde generará la detección atómica de anomalías en las imágenes de entrada y guardará los resultados en un lago de datos, por ejemplo, representado por la base de datos Athena.
En algunos casos, esta detección inicial no es suficiente para su caso de uso concreto. Es posible que necesite otra detección más detallada. Por ejemplo, el modelo inicial (por ejemplo, el de reconocimiento) puede detectar algún problema en el dispositivo, pero no es posible identificar con fiabilidad de qué tipo de problema se trata.
Para ello, es posible que necesite otro modelo con capacidades diferentes. En tal caso, puede ejecutar el otro modelo (por ejemplo, Lookout for Vision) en el subconjunto de imágenes en las que el modelo inicial identificó el problema.
Esta es también una buena manera de ahorrar algunos costes, ya que no necesita ejecutar el segundo modelo en todo un conjunto de imágenes. En su lugar, lo ejecuta sólo en el subconjunto significativo.
Las funciones Lambda de AWS cubrirán todo ese procesamiento utilizando código Python o Javascript en su interior. Sólo depende de la naturaleza de los procesos y de cuántas funciones AWS lambda necesitará incluir dentro de un flujo. El límite de 15 minutos para la duración máxima de una llamada a AWS lambda determinará cuántos pasos debe contener un proceso de este tipo.
Lea también: Cómo automatizar la orquestación de derechos de acceso dentro de los buckets S3 de AWS
Palabras finales
Trabajar con modelos de aprendizaje automático en la nube es un trabajo muy interesante. Si lo mira desde la perspectiva de las habilidades y las tecnologías, descubrirá que necesita tener un equipo con una gran variedad de habilidades.
El equipo necesita entender cómo entrenar un modelo, ya sea pre-construido o creado desde cero. Esto significa que intervienen muchas matemáticas o álgebra para equilibrar la fiabilidad y el rendimiento de los resultados.
También se necesitan algunos conocimientos avanzados de codificación en Python o Javascript, bases de datos y SQL. Y una vez realizado todo el trabajo de contenido, necesita habilidades de DevOps para conectarlo a una canalización que lo convierta en un trabajo automatizado listo para su despliegue y ejecución.
Definir la anomalía y entrenar el modelo es una cosa. Pero es un reto integrarlo todo en un equipo funcional que pueda procesar los resultados de los modelos y guardar los datos de forma eficaz y automatizada para servirlos a los usuarios finales.
A continuación, consulte todo sobre el reconocimiento facial para empresas.