¿Está buscando añadir estructuras de datos a su caja de herramientas de programación? Dé hoy los primeros pasos aprendiendo sobre estructuras de datos en Python.
Cuando está aprendiendo un nuevo lenguaje de programación, es importante comprender los tipos de datos básicos y las estructuras de datos incorporadas que admite el lenguaje. En esta guía sobre estructuras de datos en Python, cubriremos lo siguiente:
- ventajas de las estructuras de datos
- estructuras de datos incorporadas en Python, como listas, tuplas, diccionarios y conjuntos
- implementaciones de tipos de datos abstractos, como pilas y colas.
Comencemos
¿Por qué son útiles las estructuras de datos?

Antes de repasar las distintas estructuras de datos, veamos por qué puede ser útil utilizar estructuras de datos:
- Procesamiento eficiente de datos: Elegir la estructura de datos adecuada ayuda a procesar los datos de forma más eficaz. Por ejemplo, si necesita almacenar una colección de elementos del mismo tipo de datos -con tiempos de búsqueda constantes y un acoplamiento ajustado- puede elegir una matriz.
- Mejor gestión de la memoria: En proyectos de mayor envergadura, para almacenar los mismos datos, una estructura de datos puede ser más eficiente en términos de memoria que otra. Por ejemplo, en Python, tanto las listas como las tuplas pueden utilizarse para almacenar colecciones de datos del mismo tipo o de tipos diferentes. Sin embargo, si sabe que no tiene que modificar la colección, puede elegir una tupla que ocupe relativamente menos memoria que una lista.
- Código más organizado: Utilizar la estructura de datos adecuada para una funcionalidad concreta hace que su código sea más organizado. Otros desarrolladores que lean su código esperarán que utilice estructuras de datos específicas en función del comportamiento deseado. Por ejemplo: si necesita un mapeo clave-valor con tiempos de búsqueda e inserción constantes, puede almacenar los datos en un diccionario.
Listas
Cuando necesitamos crear matrices dinámicas en Python -desde entrevistas de codificación hasta casos de uso comunes- las listas son las estructuras de datos a las que recurrimos.
Las listas de Python son tipos de datos contenedores que son mutables y dinámicos, por lo que puede añadir y eliminar elementos de una lista en su lugar, sin tener que crear una copia.
Cuando utilice listas Python:
- Indexar en la lista y acceder a un elemento en un índice específico es una operación en tiempo constante.
- Añadir un elemento al final de la lista es una operación de tiempo constante.
- Insertar un elemento en un índice específico es una operación de tiempo lineal.
Existe un conjunto de métodos de lista que nos ayudan a realizar tareas comunes de forma eficiente. El fragmento de código siguiente muestra cómo realizar estas operaciones en una lista de ejemplo:
>>> nums = [5,4,3,2]
>>> nums.append(7)
>>> números
[5, 4, 3, 2, 7]
>>> números.pop()
7
>>> números
[5, 4, 3, 2]
>>> números.insertar(0,9)
>>> números
[9, 5, 4, 3, 2]Las listas de Python también admiten el troceado y la comprobación de pertenencia mediante el operador in:
>>> nums[1:4]
[5, 4, 3]
>>> 3 en números
VerdaderoLa estructura de datos lista no sólo es flexible y sencilla, sino que también nos permite almacenar elementos de distintos tipos de datos. Python también tiene una estructura de datos array dedicada para almacenar de forma eficiente elementos del mismo tipo de datos. Aprenderemos sobre esto más adelante en esta guía.
Tuplas
En Python, las tuplas son otra popular estructura de datos incorporada. Son como las listas de Python en el sentido de que puede indexarlas en tiempo constante y trocearlas. Pero son inmutables, por lo que no puede modificarlas in situ. El siguiente fragmento de código explica lo anterior con una tupla nums de ejemplo:
>>> nums = (5,4,3,2)
>>> nums<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x>
5
>>> números[0:2]
(5, 4)
>>> 5 en números
Verdadero
>>> nums<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x> = 7 # ¡no es una operación válida!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: El objeto 'tuple' no admite la asignación de elementosPor lo tanto, cuando desee crear una colección inmutable y poder procesarla de forma eficiente, debería plantearse utilizar una tupla. Si desea que la colección sea mutable, prefiera utilizar una lista en su lugar.
📋 Obtenga más información sobre las similitudes y diferencias entre las listas y las tuplas de Python.
Arrays
Los arrays son estructuras de datos menos conocidas en Python. Son similares a las listas de Python en cuanto a las operaciones que soportan, como la indexación en tiempo constante y la inserción de un elemento en un índice específico en tiempo lineal.
Sin embargo, la diferencia clave entre las listas y las matrices es que las matrices almacenan elementos de un único tipo de datos. Por lo tanto, están estrechamente acoplados y son más eficientes en el uso de la memoria.
Para crear un array, podemos utilizar el constructor array () del módulo array incorporado. El constructor array () recibe una cadena que especifica el tipo de datos de los elementos y los elementos. Aquí creamos nums_f, una matriz de números de coma flotante:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])Puede indexar en una matriz (de forma similar a las listas de Python):
>>> nums_f<x><x><x><x><x><x><x><x><x>[</x></x></x></x></x></x></x></x></x>0]
1.5Las matrices son mutables, por lo que puede modificarlas:
>>> nums_f[0<x><x><x><x><x><x><x><x><x>]</x></x></x></x></x></x></x></x></x>=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])Pero no puede modificar un elemento para que sea de un tipo de datos diferente:
>>> nums_f<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x>='cero'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: must be real number, not strCadenas
En Python las cadenas son colecciones inmutables de caracteres Unicode. A diferencia de lenguajes de programación como C, Python no tiene un tipo de datos de caracteres dedicado. Así que un carácter es también una cadena de longitud uno.
Como se ha mencionado la cadena es inmutable:
>>> str_1 = 'python'
>>> str_1<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x> = 'c'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: El objeto 'str' no soporta la asignación de elementosLas cadenas de Python admiten el troceado de cadenas y un conjunto de métodos para darles formato. He aquí algunos ejemplos:
>>> str_1[1:4]
'yth'
>>> str_1.title()
'Python'
>>> str_1.upper()
'PYTHON'
>>> str_1.swapcase()
'PYTHON'⚠ Recuerde, todas las operaciones anteriores devuelven una copia de la cadena y no modifican la cadena original. Si está interesado, consulte la guía de programas Python sobre operaciones con cadenas.
Conjuntos
En Python, los conjuntos son colecciones de elementos únicos y hashables. Puede realizar las operaciones comunes de conjuntos como la unión, la intersección y la diferencia:
>>> conjunto_1 = {3,4,5,7}
>>> conjunto_2 = {4,6,7}
>>> conjunto_1.unión(conjunto_2)
{3, 4, 5, 6, 7}
>>> conjunto_1.intersección(conjunto_2)
{4, 7}
>>> conjunto_1.diferencia(conjunto_2)
{3, 5}Los conjuntos son mutables por defecto, por lo que puede añadir nuevos elementos y modificarlos:
>>> conjunto_1.añadir(10)
>>> conjunto_1
{3, 4, 5, 7, 10}📚 Leer conjuntos en Python: Una guía completa con ejemplos de código
Conjuntos inmutables
Si desea un conjunto inmutable, puede utilizar un conjunto congelado. Puede crear un conjunto congelado a partir de conjuntos existentes u otros iterables.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10, 11})Como frozenset_1 es un conjunto congelado, nos encontramos con errores si intentamos añadir elementos (o modificarlo de otro modo):
>>> frozenset_1.add(15)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'Diccionarios
Un diccionario Python es funcionalmente similar a un mapa hash. Los diccionarios se utilizan para almacenar pares clave-valor. Las claves del diccionario deben ser hashables. Esto significa que el valor hash del objeto no cambia.
Puede acceder a los valores mediante claves, insertar nuevos elementos y eliminar los existentes en tiempo constante. Existen métodos de diccionario para realizar estas operaciones.
>>> favoritos = {'libro':'Orlando'}
>>> favoritos
{'libro':'Orlando'}
>>> favoritos['autor']='Virginia Woolf'
>>> Favoritos
{'libro': 'Orlando', 'autor': 'Virginia Woolf'}
>>> favoritos.pop('autor')
'Virginia Woolf'
>>> Favoritos
{'libro': 'Orlando'}Diccionario ordenado
Aunque un diccionario Python proporciona un mapeo clave-valor, es inherentemente una estructura de datos desordenada. Desde Python 3.7, se conserva el orden de inserción de los elementos. Pero puede hacerlo más explícito utilizando OrderedDict del módulo collections.
Como se muestra, un OrderedDict preserva el orden de las claves:
>>> from colecciones import OrderedDict
>>> od = OrderedDict()
>>> od['primero']='uno'
>>> od['segundo']='dos
>>> od['tercera']='tres'
>>> od
OrderedDict([('primero', 'uno'), (('segundo', 'dos'), (('tercero', 'tres')])
>>> od.keys()
odict_claves(['primero', 'segundo', 'tercero'])Defaultdict
Los errores de clave son bastante comunes cuando se trabaja con diccionarios de Python. Siempre que intente acceder a una clave que no ha sido añadida al diccionario, se encontrará con una excepción KeyError.
Pero utilizando defaultdict del módulo collections, puede manejar este caso de forma nativa. Cuando intentamos acceder a una clave que no está presente en el diccionario, la clave se añade y se inicializa con los valores por defecto especificados por la fábrica por defecto.
>>> from colecciones import defaultdict
>>> precios = defaultdict(int)
>>> precios['zanahorias']
0Pilas
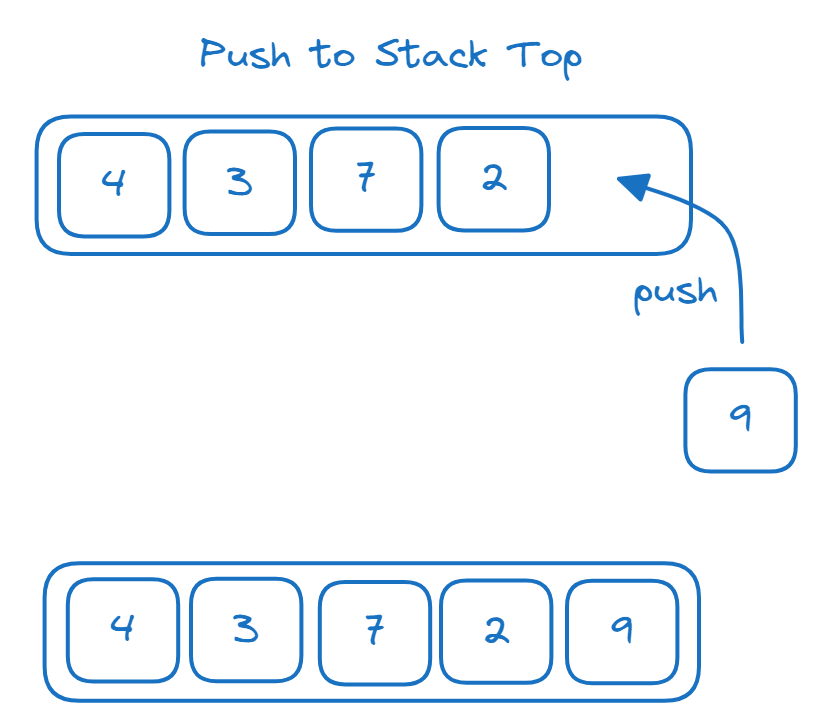
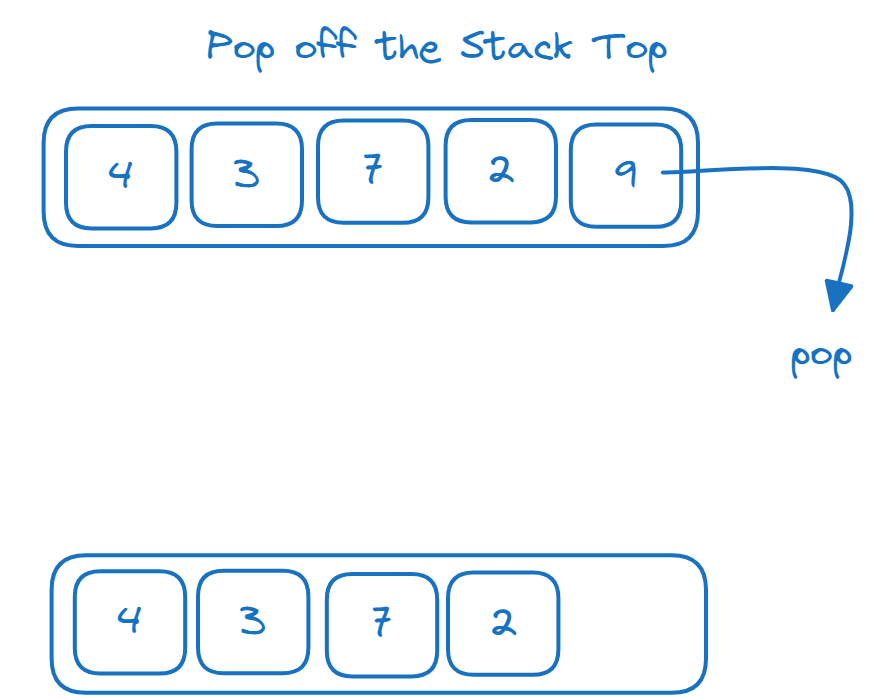
La pila es una estructura de datos de último en entrar, primero en salir (LIFO). Podemos realizar las siguientes operaciones en una pila:
- Añadir elementos a la parte superior de la pila: operación push
- Eliminar elementos de la parte superior de la pila: operación pop
Un ejemplo para ilustrar cómo funcionan las operaciones push y pop de la pila:
Cómo implementar una pila utilizando una lista
En Python, podemos implementar la estructura de datos de la pila utilizando una lista de Python.
| Operación sobre la pila | Operación equivalente en una lista |
|---|---|
| Empujar a la parte superior de la pila | Anexar al final de la lista usando el método append() |
| Retirar del tope de la pila | Eliminar y devolver el último elemento utilizando el método pop( ) |
El fragmento de código siguiente muestra cómo podemos emular el comportamiento de una pila utilizando una lista de Python:
>>> l_stk = []
>>> l_stk.append(4)
>>> l_stk.append(3)
>>> l_stk.append(7)
>>> l_stk.append(2)
>>> l_stk.append(9)
>>> l_stk
[4, 3, 7, 2, 9]
>>> l_stk.pop()
9Cómo implementar una pila utilizando un deque
Otro método para implementar una pila es utilizar deque del módulo collections. Deque significa cola de doble extremo y admite la adición y eliminación de elementos desde ambos extremos.
Para emular la pila, podemos
- añadir al final de la deque utilizando
append(), y - sacar el último elemento añadido utilizando
pop().
>>> from colecciones import deque
>>> stk = deque()
>>> stk.append(4)
>>> stk.append(3)
>>> stk.append(7)
>>> stk.append(2)
>>> stk.append(9)
>>> stk
deque([4, 3, 7, 2,9])
>>> stk.pop()
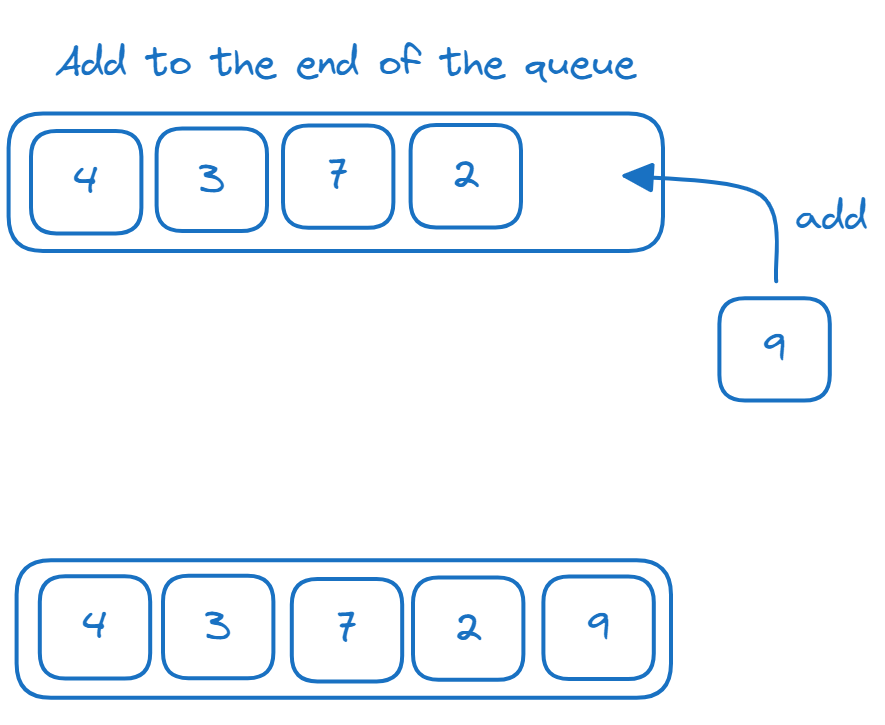
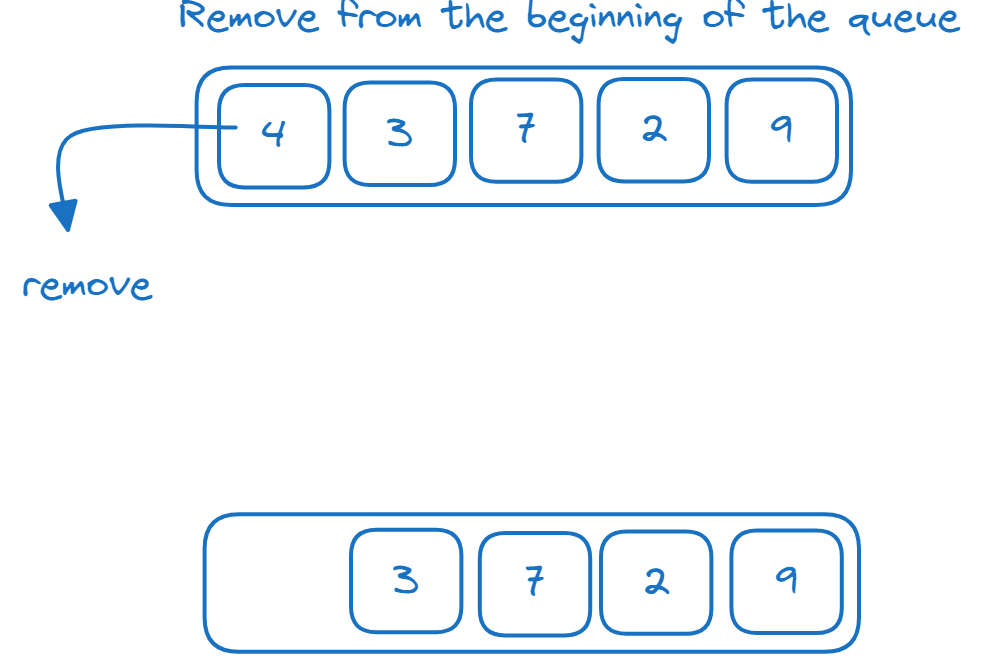
9Colas
La cola es una estructura de datos FIFO (primero en entrar, primero en salir ). Los elementos se añaden al final de la cola y se eliminan del principio de la cola (cabecera de la cola) como se muestra:
Podemos implementar la estructura de datos de la cola utilizando un deque:
- añadir elementos al final de la cola utilizando
append() - utilizar el método
popleft() para eliminar elementos del principio de la cola
>>> from colecciones import deque
>>> q = deque()
>>> q.append(4)
>>> q.append(3)
>>> q.append(7)
>>> q.append(2)
>>> q.append(9)
>>> q.popleft()
4Montones
En esta sección hablaremos de los montones binarios. Nos centraremos en los miniapilamientos.
Un min montón es un árbol binario completo. Desglosemos lo que significa un árbol binario completo:
- Un árbol binario es una estructura de datos en forma de árbol en la que cada nodo tiene como máximo dos nodos hijos, de forma que cada nodo es menor que su hijo.
- El término completo significa que el árbol está completamente lleno, excepto, quizás, el último nivel. Si el último nivel está parcialmente lleno, se llena de izquierda a derecha.
Porque cada nodo tiene como máximo dos nodos hijos. Y también satisface la propiedad de que es menor que su hijo, la raíz es el elemento mínimo de un min montón.
He aquí un ejemplo de min montón:
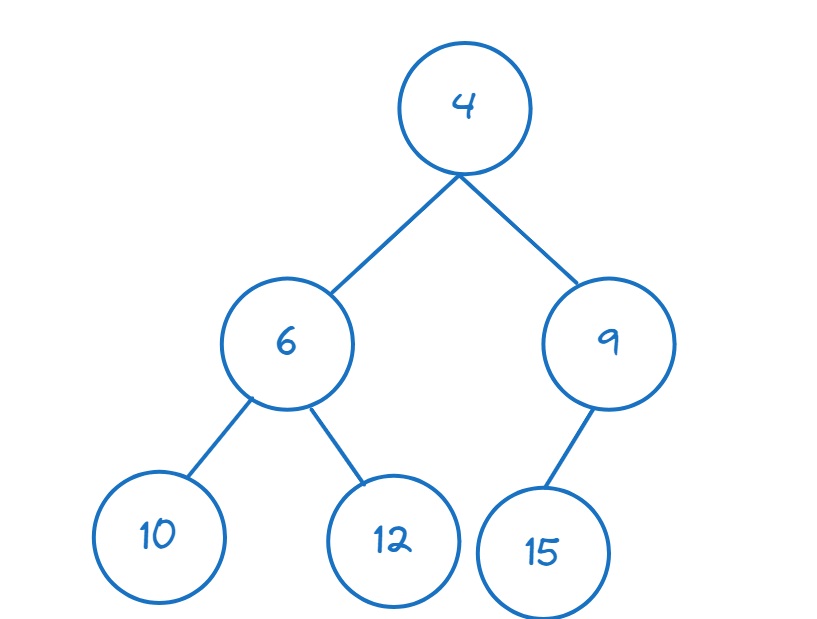
En Python, el módulo heapq nos ayuda a construir montones y a realizar operaciones sobre el montón. Importemos las funciones necesarias de heapq:
>>> from heapq import heapify, heappush, heappopSi tiene una lista u otro iterable, puede construir un montón a partir de él llamando a heapify():
>>> nums = [11,8,12,3,7,9,10]
>>> heapify(nums)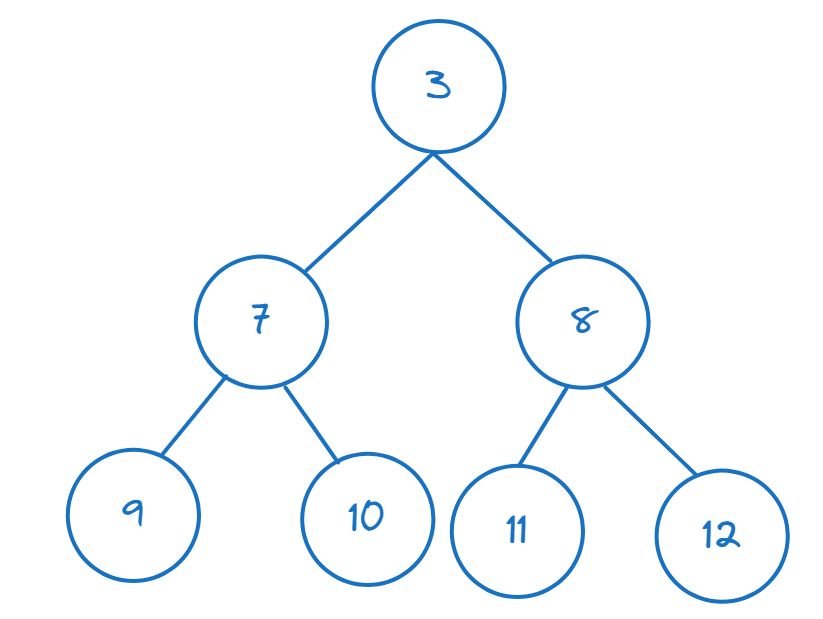
Puede indexar el primer elemento para comprobar que es el elemento mínimo:
>>> nums<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x>
3Ahora, si inserta un elemento en el montón, los nodos se reordenarán de forma que satisfagan la propiedad de montón mínimo.
>>> heappush(nums,1)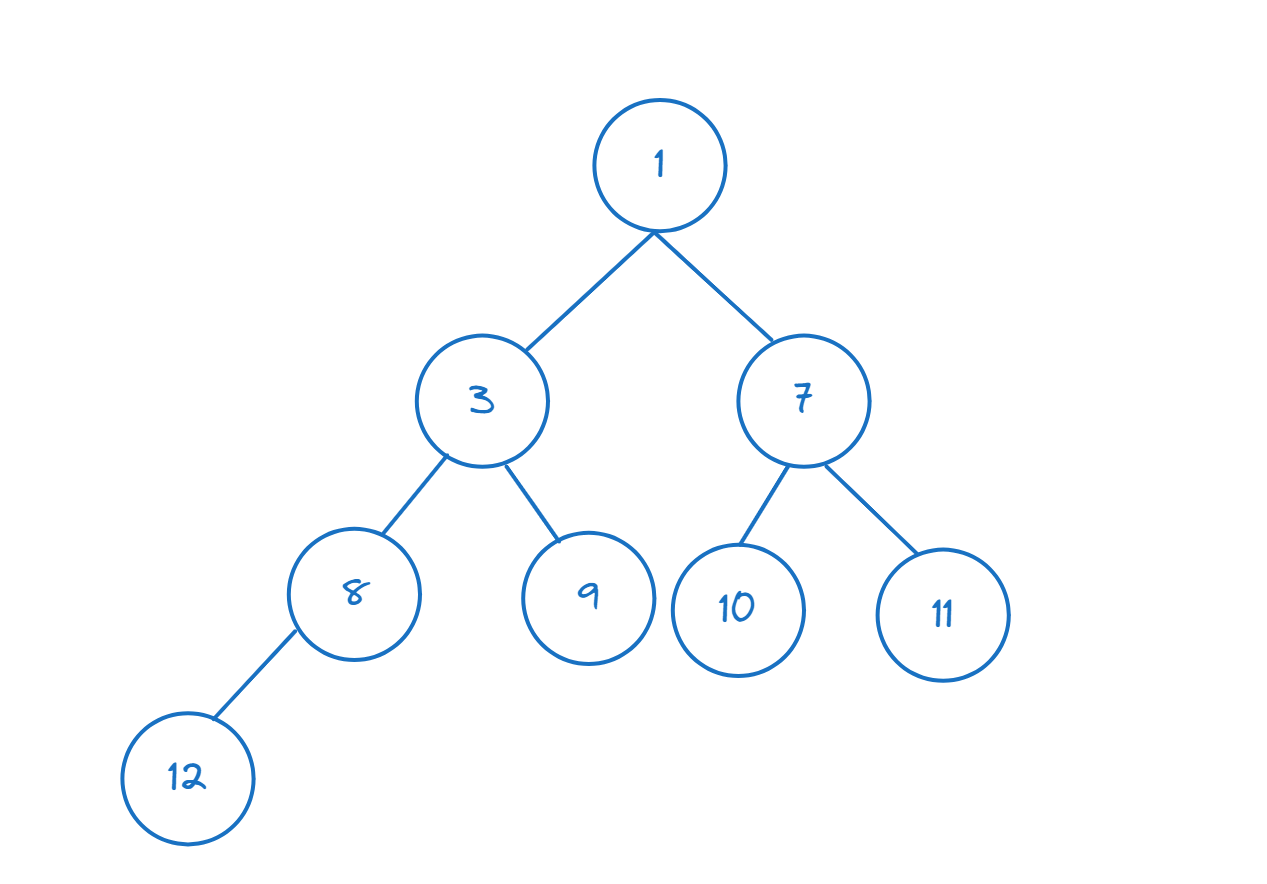
Como hemos insertado 1 (1 < 3), vemos que nums <x><x><x><x><x><x><x><x><x>[</x></x></x></x></x></x></x></x></x> 0] devuelve 1, que es ahora el elemento mínimo (y el nodo raíz).
>>> nums[0<x><x><x><x><x><x><x><x><x>]</x></x></x></x></x></x></x></x></x>
1Puede eliminar elementos del montón mínimo llamando a la función heappop( ) como se muestra:
>>> while números
... print(heappop(nums))
...# Salida
1
3
7
8
9
10
11
12Max Heaps en Python
Ahora que conoce los montículos mínimos, ¿puede adivinar cómo podemos implementar un montículo máximo?
Bien, podemos convertir una implementación de un montón min en un montón max multiplicando cada número por -1. Los números negados dispuestos en un min montón son equivalentes a los números originales dispuestos en un max montón.
En la implementación de Python, podemos multiplicar los elementos por -1 al añadir un elemento al montón utilizando heappush():
>>> maxHeap = []
>>> heappush(maxHeap,-2)
>>> heappush(maxHeap,-5)
>>> heappush(maxHeap,-7)El nodo raíz -multiplicado por -1- será el elemento máximo.
>>> -1*maxHeap<x><x><x><x><x><x><x><x><x>[0]</x></x></x></x></x></x></x></x></x>
7Al eliminar los elementos del montón, utilice heappop() y multiplique por -1 para recuperar el valor original:
>>> while maxHeap
... print(-1*heappop(maxHeap))
...# Salida
7
5
2Colas de prioridad
Terminemos la discusión aprendiendo sobre la estructura de datos de colas de prioridad en Python.
Lo sabemos: En una cola los elementos se eliminan en el mismo orden en que entran en la cola. Pero una cola de prioridad sirve los elementos por prioridad, algo muy útil para aplicaciones como la programación. Así, en cualquier momento se devuelve el elemento con la prioridad más alta.
Podemos utilizar claves para definir la prioridad. Aquí utilizaremos pesos numéricos para las claves.
Cómo implementar colas de prioridad utilizando Heapq
He aquí la implementación de la cola de prioridad utilizando heapq y la lista de Python:
>>> from heapq import heappush,heappop
>>> pq = []
>>> heappush(pq,(2,'escribir'))
>>> heappush(pq,(1,'leer'))
>>> heappush(pq,(3,'codificar'))
>>> while pq
... print(heappop(pq))
...Al eliminar elementos, la cola sirve primero el elemento de mayor prioridad ( 1,’read’), seguido de (2,'write') y luego (3,'code').
# Salida
(1, 'leer')
(2, 'escribir')
(3, 'code')Cómo implementar colas de prioridad utilizando PriorityQueue
Para implementar una cola de prioridad, también podemos utilizar la clase PriorityQueue del módulo de colas. Ésta también utiliza internamente el heap.
He aquí la implementación equivalente de la cola de prioridad utilizando PriorityQueue:
>>> from cola import PriorityQueue
>>> pq = PriorityQueue()
>>> pq.put((2,'escribir'))
>>> pq.put((1,'leer'))
>>> pq.put((3,'código'))
>>> pq
<objetoqueue.PriorityQueue en 0x00BDE730>
>>> while not pq.empty():
... print(pq.get())
...# Salida
(1, 'leer')
(2, 'escribir')
(3, 'code')Resumiendo
En este tutorial, usted aprendió acerca de las diversas estructuras de datos incorporadas en Python. También repasamos las diferentes operaciones soportadas por estas estructuras de datos-y los métodos incorporados para hacer lo mismo.
Después, repasamos otras estructuras de datos como pilas, colas y colas de prioridad-y su implementación en Python utilizando la funcionalidad del módulo de colecciones.
A continuación, consulte la lista de proyectos Python para principiantes.