
Chaque service AWS enregistre ses traitements dans des fichiers organisés en groupes de journaux CloudWatch. Les groupes de journaux sont généralement nommés d’après le service lui-même pour en faciliter l’identification. Les messages système du service ou les informations sur l’état commun sont écrits dans ces fichiers journaux par défaut.
Cependant, vous pouvez ajouter des informations personnalisées sur les messages du journal en plus des messages par défaut. Si ces journaux sont créés judicieusement, ils peuvent servir à créer des tableaux de bord CloudWatch utiles.
Avec des métriques et des informations structurées qui donnent des détails supplémentaires sur le traitement des tâches. Ils peuvent non seulement contenir des widgets standard avec des informations de type système sur le service. Vous pouvez y ajouter votre propre contenu, agrégé dans votre widget ou métrique personnalisé.
Interroger les fichiers journaux
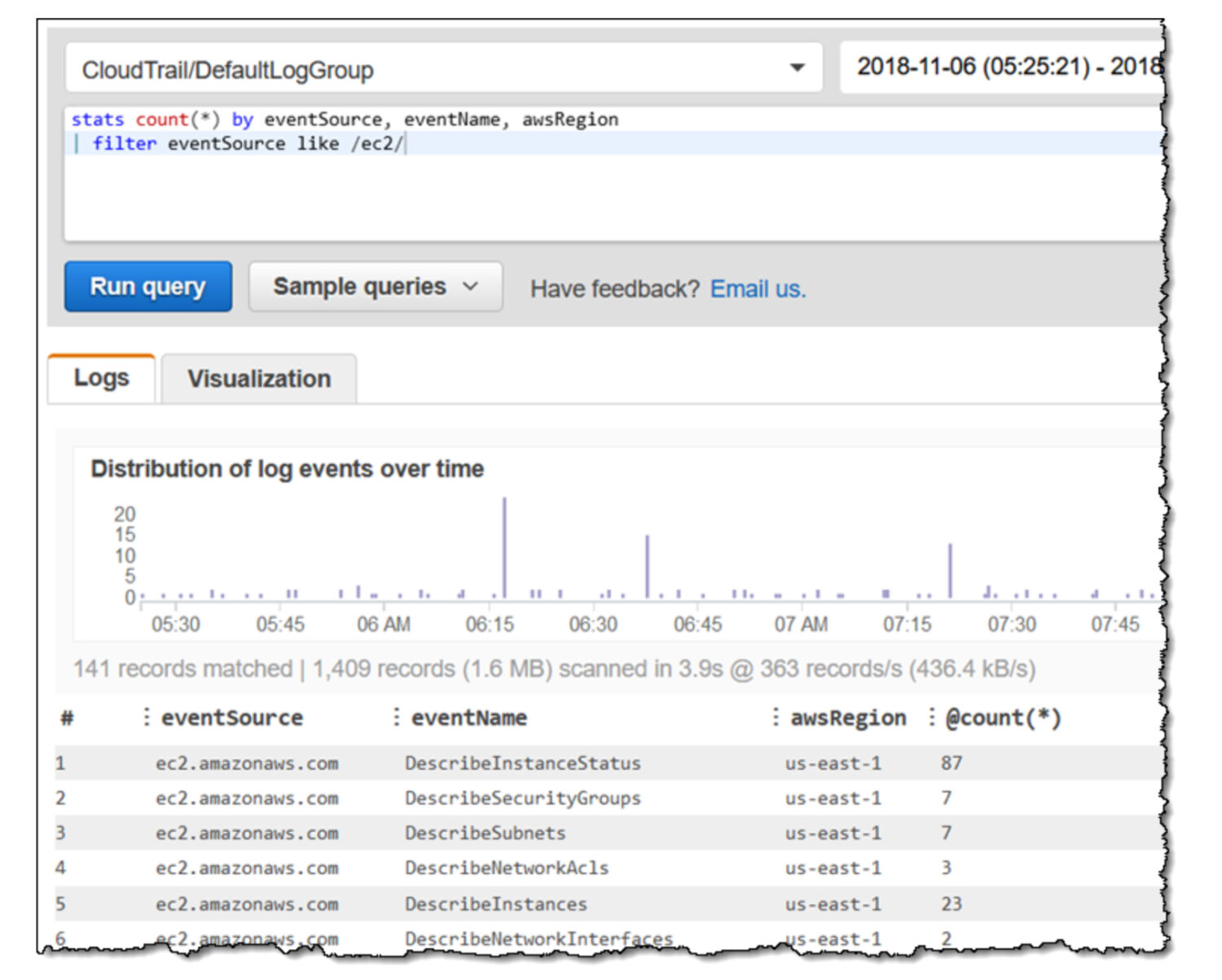
AWS CloudWatch Log Insights vous permet de rechercher et d’analyser en temps réel les données des journaux de vos ressources AWS. Vous pouvez considérer cela comme une vue de base de données. Vous définissez la requête sur le tableau de bord, et le tableau de bord la sélectionnera lorsque vous le visiterez ou à la fenêtre de temps spécifiée dans le passé, comme vous le définissez dans la vue du tableau de bord.
Il utilise un langage de requête appelé CloudWatch Logs Insights pour rechercher et analyser les données des journaux. Le langage de requête est basé sur un sous-ensemble du langage SQL. Il vous permet de rechercher et de filtrer les données du journal. Vous pouvez rechercher des événements de journal spécifiques, un texte de journal personnalisé ou des mots-clés, et filtrer les données de journal en fonction de champs spécifiques. Et surtout, vous pouvez agréger les données du journal dans un ou plusieurs fichiers journaux pour générer des métriques et des visualisations résumées.
Lorsque vous exécutez une requête, CloudWatch Log Insights recherche les données du journal dans le groupe de journaux. Il renvoie ensuite les textes issus des fichiers qui correspondent à vos critères de requête.
Exemple de requête de fichier journal
Examinons quelques requêtes de base pour comprendre le concept.
Chaque service, par défaut, enregistre certaines erreurs de service cruciales. Même si vous ne créez pas de journal personnalisé dédié à ces erreurs. Avec une simple requête, vous pouvez compter le nombre d’erreurs dans les journaux de votre application au cours de la dernière heure :
champs @timestamp, @message
| filtre @message like /ERROR/
| stats count() by bin(1h)Ou voici comment surveiller le temps de réponse moyen de votre API au cours de la dernière journée :
champs @timestamp, @message
| filter @message like /API response time/
| stats avg(response_time) by bin(1d)Puisque, par défaut, l’utilisation du CPU est une information enregistrée par le service dans CloudWatch, vous pouvez également collecter ce type de métrique :
champs @timestamp, @message
| filtre @message comme /CPUUtilization/
| stats avg(value) by bin(1h)Ces requêtes peuvent être personnalisées pour s’adapter à votre cas d’utilisation spécifique et peuvent être utilisées pour créer des métriques et des visualisations personnalisées dans les tableaux de bord CloudWatch. La façon de procéder est de placer le widget sur le tableau de bord et de placer le code à l’intérieur du widget pour définir ce qu’il faut sélectionner.
Voici quelques-uns des widgets qui peuvent être utilisés dans les tableaux de bord CloudWatch et remplis par le contenu de Log Insights :
- Widgets de texte – affichent des informations textuelles, telles que le résultat d’une requête CloudWatch Insights.
- Widgets de requête de journal – affichent les résultats d’une requête de journal CloudWatch Insights, comme le nombre d’erreurs dans les journaux de votre application.
Comment créer des informations de log utiles pour le tableau de bord
Pour utiliser efficacement les requêtes CloudWatch Insights dans les tableaux de bord CloudWatch, il est bon de suivre quelques bonnes pratiques lors de la création des journaux CloudWatch pour chacun des services que vous utilisez dans votre système. Voici quelques conseils :
#1. Utilisez une journalisation structurée
Vous devez vous en tenir à un format de journalisation qui utilise un schéma prédéfini pour enregistrer les données dans un format structuré. Cela facilite la recherche et le filtrage des données de journalisation à l’aide des requêtes CloudWatch Insights.
Cela signifie essentiellement que vous devez normaliser vos journaux dans les différents services de votre plateforme d’architecture. Le fait de le définir dans des normes de développement est d’une aide précieuse.
Par exemple, vous pouvez définir que chaque problème lié à une table de base de données spécifique sera consigné avec un message de départ comme : “[TABLE_NAME] Avertissement / Erreur :
Vous pouvez également séparer les tâches relatives aux données complètes des tâches relatives aux données delta en utilisant des préfixes tels que “[FULL/DELTA]” pour ne sélectionner que les messages relatifs aux processus de données concrets.
Vous pouvez définir que, lors du traitement de données provenant d’un système source spécifique, le nom du système sera un préfixe de chaque entrée de journal correspondante. Il est beaucoup plus facile par la suite de filtrer ces messages à partir des fichiers journaux et de construire des métriques à partir de ceux-ci.
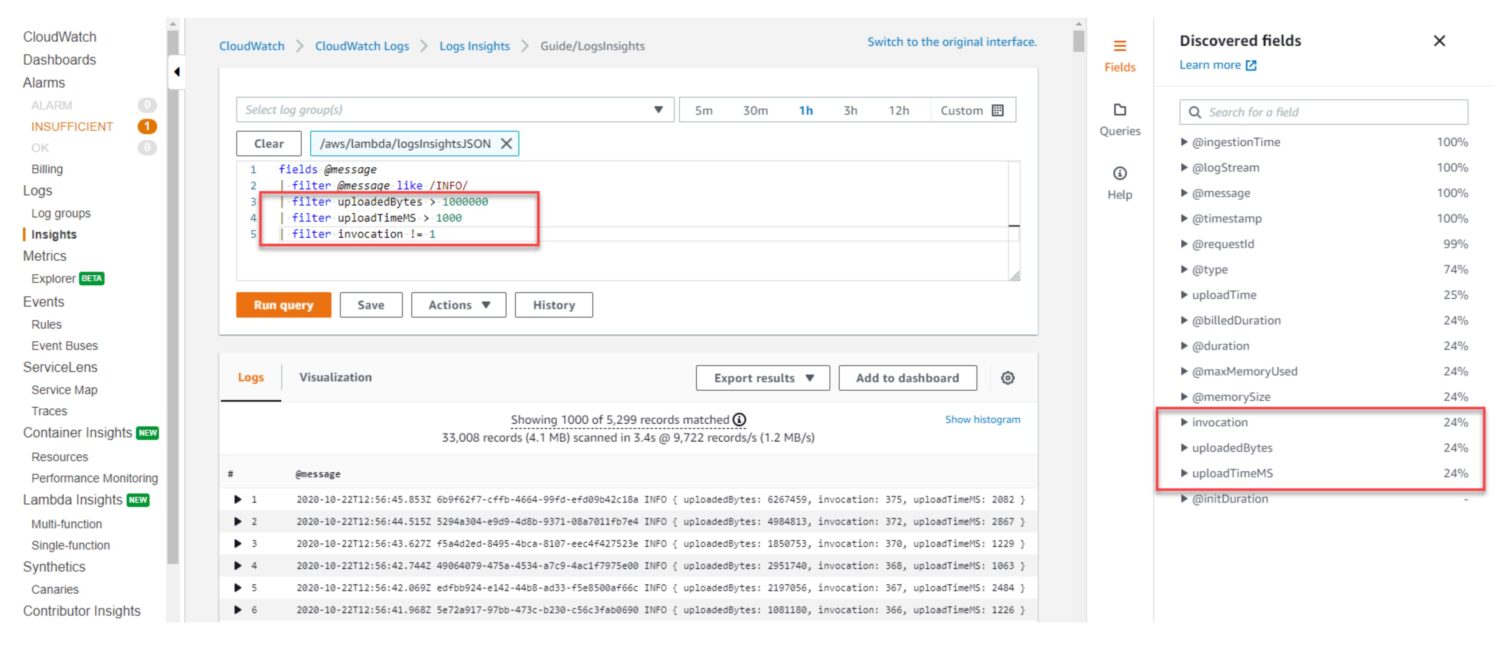
#2. Utilisez des formats de journaux cohérents
Utilisez des formats de logs cohérents pour toutes vos ressources AWS afin de faciliter la recherche et le filtrage des données de logs à l’aide des requêtes CloudWatch Insights.
Ce point est lié au précédent, mais le fait est que plus le format de log est standardisé, plus il est facile d’utiliser les données de log. Les développeurs peuvent alors s’appuyer sur ce format et l’utiliser même intuitivement.
Le fait est que la plupart des projets ne s’embarrassent pas de normes en matière de journalisation. Qui plus est, de nombreux projets ne créent même pas de journaux personnalisés. C’est à la fois choquant et très courant.
Je ne saurais dire combien de fois je me suis demandé comment les gens pouvaient vivre ici sans aucune approche de gestion des erreurs. Et si quelqu’un s’est efforcé de gérer les erreurs comme une exception, il l’a fait à tort.
Un format de journal cohérent est donc un atout majeur. Peu de gens en disposent.
#3. Inclure des métadonnées pertinentes
Incluez des métadonnées dans vos données de log, telles que les horodatages, les identifiants de ressources et les codes d’erreur, afin de faciliter la recherche et le filtrage des données de log à l’aide des requêtes CloudWatch Insights.
#4. Activer la rotation des journaux
Activez la rotation des journaux pour éviter que vos données ne deviennent trop volumineuses et pour faciliter la recherche et le filtrage des données de journaux à l’aide des requêtes CloudWatch Insights.
Ne pas avoir de données de logs est une chose, mais en avoir trop sans structure est tout aussi désespérant. Si vous ne pouvez pas utiliser vos données, c’est comme si vous n’aviez pas de données du tout.
#5. Utilisez les agents de logs CloudWatch
Si vous ne pouvez pas vous aider et que vous refusez de construire votre propre système de logs, utilisez au moins les agents CloudWatch Logs. Ils envoient automatiquement les données de log de vos ressources AWS vers CloudWatch Logs. Cela facilite la recherche et le filtrage des données de log à l’aide des requêtes CloudWatch Insights.
Exemples de requêtes Insights plus complexes
La requête CloudWatch Insights peut être plus complexe qu’une simple déclaration de deux lignes.
champs @timestamp, @message
| Filtre @message comme /ERROR/
| filtre @message pas comme /404/
| parse @message /.*\N[(?<timestamp>[^\N])\N].*\N"(?<method>[^\N])\N (?<path>[^\N]).*\N" (?<status>\N ) (?<response_time>\N )/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| trier count desc
| Limite 20Cette requête effectue les opérations suivantes :
- Elle sélectionne les événements du journal qui contiennent la chaîne “ERROR” mais pas “404”.
- Elle analyse le message du journal pour en extraire l’horodatage, la méthode HTTP, le chemin d’accès, le code d’état et le temps de réponse.
- Calcule le temps de réponse moyen et le nombre d’événements du journal pour chaque combinaison de méthode HTTP, de chemin d’accès, de code d’état et d’heure.
- Trie les résultats par ordre décroissant.
- Limite la sortie aux 20 premiers résultats.
Cette requête identifie les erreurs les plus courantes dans votre application et suit le temps de réponse moyen pour chaque combinaison de méthode HTTP, de chemin d’accès et de code d’état. Vous pouvez utiliser les résultats pour créer des mesures et des visualisations personnalisées dans les tableaux de bord CloudWatch afin de surveiller les performances de votre application Web et de résoudre les problèmes.
Autre exemple d’interrogation des messages du service Amazon S3 :
champs @timestamp, @message
| filtre @message comme /REST\.API\.REQUEST/
| parse @message /.*\"(?<method>[^\s] )\s (?<path>[^\s] ).*\" (?<status>\d ) (?<response_time>\d )/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| trier count desc
| Limite 20- La requête sélectionne les événements du journal qui contiennent la chaîne “REST.API.REQUEST”.
- Elle analyse ensuite le message du journal pour en extraire la méthode HTTP, le chemin d’accès, le code d’état et le temps de réponse.
- Elle calcule le temps de réponse moyen et le nombre d’événements de journal pour chaque combinaison de méthode HTTP, de chemin d’accès et de code d’état, puis trie les résultats par ordre décroissant.
- Limite la sortie aux 20 premiers résultats.
Vous pouvez utiliser la sortie de cette requête pour créer un graphique linéaire dans un tableau de bord CloudWatch qui montre le temps de réponse moyen pour chaque combinaison de méthode HTTP, de chemin et de code d’état au fil du temps.
Création du tableau de bord
Pour remplir les métriques et les visualisations dans les tableaux de bord CloudWatch à partir de la sortie des requêtes de journal CloudWatch Insights, vous pouvez naviguer vers la console CloudWatch et suivre l’assistant de tableau de bord pour construire votre contenu.
Après cela, voici à quoi ressemble le code d’un tableau de bord CloudWatch qui contient des métriques remplies par les données de la requête CloudWatch Insights :
{
"widgets" : [
{
"type" : "métrique",
"x" : 0,
"y" : 0,
"width" : 12,
"height" : 6,
"properties" : {
"metrics" : [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label" : "CPU Utilization",
"stat" : "Average",
"période" : 300
}
]
],
"view" : "timeSeries",
"stacked" : faux,
"region" : "us-east-1",
"title" : "EC2 CPU Utilization"
}
},
{
"type" : "log",
"x" : 0,
"y" : 6,
"width" : 12,
"height" : 6,
"properties" : {
"query" : "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region" : "us-east-1",
"title" : "Erreurs d'application"
}
}
]
}Ce tableau de bord CloudWatch contient deux widgets :
- Un widget métrique qui affiche l’utilisation moyenne du CPU d’une instance EC2 au fil du temps. CloudWatch Insights Query alimente le widget. Il sélectionne les données d’utilisation du CPU pour une instance EC2 spécifique et les agrège à intervalles de 5 minutes.
- Un widget de journal qui affiche le nombre d’erreurs d’application au fil du temps. Il sélectionne les événements du journal qui contiennent la chaîne “ERROR” et les agrège par heure.
Il s’agit d’un fichier au format JSON contenant une définition du tableau de bord et des métriques. Il contient également (en tant que propriété) la requête insight elle-même.
Vous pouvez prendre le code et le déployer sur n’importe quel compte AWS dont vous avez besoin. En supposant que les services et les messages de journal soient cohérents sur tous vos comptes et étapes AWS, le tableau de bord fonctionnera sur tous les comptes sans qu’il soit nécessaire de modifier le code source du tableau de bord.
Le mot de la fin
La mise en place d’une structure de journalisation solide a toujours été un bon investissement pour l’avenir de la fiabilité du système. Aujourd’hui, elle peut servir un objectif encore plus important. Vous pouvez avoir des tableaux de bord utiles avec des métriques et des visualisations juste comme un effet secondaire de cela.
Comme il n’est nécessaire de le faire qu’une seule fois, avec seulement un peu de travail supplémentaire, l’équipe de développement, l’équipe de test et les utilisateurs de la production peuvent tous bénéficier de la même solution.
Découvrez ensuite les meilleurs outils de surveillance AWS.