
Les données sont au cœur de certaines des plus grandes décisions prises par les entreprises modernes, et le data mining est une technique efficace pour vous y aider.
Chaque entreprise traite un volume considérable de données qui, lorsqu’elles sont utilisées à bon escient, peuvent apporter de nombreux avantages à votre organisation.
C’est là que l’exploration de données est utile.
Il peut aider les entreprises à optimiser leur efficacité opérationnelle, à réduire les coûts et à prendre des décisions éclairées.
Vous pouvez effectuer l’exploration de données de manière efficace à l’aide d’un logiciel d’exploration de données. Il vous permettra d’accélérer le processus et de gagner du temps que vous pourrez consacrer à l’utilisation des données obtenues.
Parlons un peu plus du data mining et des meilleurs logiciels de data mining que vous pouvez essayer.
Qu’est-ce que le data mining ?

Le data mining est un processus de recherche, d’extraction et d’évaluation de données. Les données peuvent être des motifs graphiques textuels tels que la calligraphie, des figures littéraires et linguistiques, des statistiques, etc.
Le data mining est issu de la linguistique informatique, un sous-domaine de l’informatique, de la linguistique, des sciences de l’art et des statistiques mathématiques.
Il vise à extraire des données à l’aide de programmes informatiques, d’analyses et de méthodes intelligentes à partir d’ensembles de données, à documenter les résultats de l’analyse et à restructurer ces informations afin d’en tirer des conclusions significatives.
Outre l’analyse de texte, le data mining implique également la gestion des données, la gestion des bases de données et l’ingénierie des bases de données. La gestion des données commence par le prétraitement des données, la création de modèles de données et le traitement des données avec des inférences statistiques strictes et non strictes.
Comment cela fonctionne-t-il ?
L’exploration de données implique différents processus, à commencer par la compréhension des exigences de l’entreprise quant à la nécessité d’extraire des données et de les utiliser.
Le processus est divisé en trois phases principales : le prétraitement des données, l’exploration des données et la validation des résultats.
Prétraitement des données
Le prétraitement des données est nécessaire pour comprendre les variations dans les ensembles de données avant de procéder à l’extraction proprement dite.
Étant donné que l’exploration de données peut mettre en évidence des modèles utiles présents dans les ensembles de données, vos données cibles doivent être suffisamment volumineuses pour contenir de tels modèles. En outre, cet ensemble de données doit être suffisamment concis pour que vous puissiez exploiter les données dans les délais impartis.
Ainsi, avant de commencer à exploiter les données, vous devez rassembler un grand volume d’ensembles de données cibles que vous pouvez obtenir à partir d’un entrepôt de données. Ensuite, vous devez nettoyer ces données afin d’éliminer les éléments superflus et les informations manquantes.
Extraction de données
Une fois que vous avez rassemblé les données cibles, le processus d’exploration de données proprement dit commence. Il comporte six étapes principales : la détection des anomalies, la modélisation des dépendances, le regroupement, la classification, la régression et la synthèse.
- Détection des anomalies : Il s’agit d’identifier les ensembles de données irréguliers qui peuvent être utiles ou qui contiennent des erreurs.
- Modélisation des dépendances : À ce stade, la relation entre les différentes variables est trouvée. Elle est également connue sous le nom d’apprentissage de règles d’association ou d’analyse du panier de consommation.
- Regroupement : Il s’agit de découvrir des structures et des groupes dans des ensembles de données qui se ressemblent.
- Classification : Il s’agit de classer les données en fonction de certains paramètres.
- Régression : Elle permet de découvrir les relations entre les ensembles de données ou les données afin de trouver une fonction capable de modéliser les données avec le moins d’erreur possible.
- Synthèse : Il s’agit de visualiser les données et de générer des rapports afin de fournir une représentation compacte et plus significative des données extraites.
Validation des résultats
Il s’agit de l’étape finale de la découverte de connaissances à partir de données collectées afin de vérifier les modèles générés par l’exploration de données.
Tous les modèles découverts par les algorithmes de data mining ne sont pas nécessairement valides. Cette étape est donc cruciale. Elle est réalisée sur un ensemble de données de test où les modèles découverts sont appliqués. Ensuite, les résultats obtenus sont comparés aux résultats souhaités.
Si les modèles répondent aux normes souhaitées, les modèles appris sont interprétés et transformés en connaissances utiles. Dans le cas contraire, vous devez réévaluer les résultats en apportant les modifications nécessaires aux étapes de prétraitement et d’exploration des données.
Pourquoi avez-vous besoin du data mining ?

Le data mining est utile pour l’analyse des données et l’intelligence économique afin d’aider les entreprises à acquérir des connaissances plus approfondies sur leur organisation, leurs clients, leurs concurrents et leur secteur d’activité. Voici quelques-unes des utilisations du data mining
- Ventes et marketing : Les entreprises collectent des informations sur leurs clients cibles afin d’optimiser leurs efforts de vente et de marketing ainsi que leurs produits et services.
- L’éducation : Les établissements d’enseignement peuvent utiliser le data mining pour extraire des données sur les étudiants et les utiliser pour améliorer la qualité de l’enseignement.
- Détection des fraudes : Les entreprises de SaaS, les banques et d’autres organisations peuvent utiliser le data mining pour observer les anomalies dans leur posture de sécurité et prévenir les cyberattaques.
- Opérations : Les entreprises peuvent utiliser le data mining pour optimiser leurs opérations, réduire les coûts et prendre des décisions éclairées.
Parlons maintenant des meilleurs logiciels de data mining.
RapidMiner Studio
RapidMiner Studio vous offre une plateforme complète d’exploration de données avec une automatisation complète et une conception visuelle du flux de travail. Il permet d’automatiser et d’accélérer le processus de création de modèles prédictifs à l’aide d’une interface visuelle de type glisser-déposer.
Vous disposez de plus de 1 500 fonctions et algorithmes qui garantissent le meilleur modèle dans chaque cas d’utilisation. RapidMiner Studio propose des modèles prédéfinis pour la maintenance prédictive, le taux de désabonnement des clients, la détection des fraudes, etc.
RapidMiner vous permet de créer des connexions par pointer-cliquer aux entrepôts de données d’entreprise, au stockage en nuage, aux médias sociaux, aux applications professionnelles, aux lacs de données et aux bases de données. Les débutants trouveront également des recommandations proactives à chaque étape.

Exécutez l’ETL et la préparation des données à l’intérieur de la base de données afin de conserver des données optimisées pour l’analyse. Comprenez les tendances, les distributions et les modèles à l’aide d’histogrammes, de coordonnées parallèles, de graphiques linéaires, de diagrammes en boîte, de diagrammes de dispersion, etc. pour résoudre rapidement les problèmes de qualité des données, y compris les informations manquantes et les valeurs aberrantes.
Éliminez le travail fastidieux lors de la préparation des données avec RapidMiner Turbo Prep et créez rapidement des modèles d’apprentissage automatique percutants et utiles sans écrire une seule ligne de code. Vous découvrirez ainsi les performances réelles du modèle avant de le mettre en production.
En outre, créez des flux de travail de data mining visuels faciles à expliquer et à comprendre et déployez également des modèles contenant du code ou basés sur du code dans la plateforme.
Intégrez RapidMiner à des applications existantes telles que Python et R. Téléchargez les dernières fonctionnalités fournies par la communauté et ajoutez de nouvelles capacités grâce à son mécanisme d’extension.
Teradata
Découvrez les données, les connaissances et les résultats avec Teradata Vantage. Il s’agit d’une plateforme multi-cloud connectée qui unifie tout pour l’analyse d’entreprise.
Teradata aide votre entreprise à progresser en permettant un écosystème d’analyse des données d’entreprise, une intelligence prédictive et en fournissant des réponses exploitables. Elle offre une approche hybride pour répondre aux exigences d’une entreprise moderne.
Cette plateforme multi-cloud vous offre la portabilité et la flexibilité nécessaires pour vous déployer n’importe où, sur site ou dans des clouds publics (Azure, AWS, Google Cloud). Les équipes d’experts de Teradata peuvent vous aider à exploiter les données afin d’optimiser vos opérations commerciales et d’obtenir une valeur exceptionnelle.

Interrogez votre inventaire en temps réel avec Teradata et assurez-vous que tout fonctionne sans vous soucier du temps de fonctionnement. En outre, Teradata Vantage fournit d’innombrables informations pour vous aider à créer une entreprise de nouvelle génération.
En outre, son évolutivité multidimensionnelle et de niveau entreprise vous permet de faire évoluer les dimensions pour gérer vos charges de travail de données massives. Faites progresser votre intelligence artificielle et l’apprentissage automatique pour alimenter vos modèles avec de meilleurs résultats et une meilleure qualité.
Offrez à vos équipes un logiciel sans code sécurisé et basé sur les rôles pour tirer 100 % des données qui peuvent soutenir les objectifs clés de votre entreprise. Il prend également en charge tous les formats et types de données, tels que BSON, Avro, CSV, Parquet, XML et JSON.
Teradata Vantage ne vous surprendra pas avec des coûts supplémentaires. La console intuitive vous permet de suivre facilement l’utilisation de vos ressources afin que vous sachiez ce pour quoi vous payez.
Oracle Data Miner
Oracle Data Min er permet aux entreprises, aux analystes de données et aux data scientists de visualiser les données et de travailler directement dans la base de données à l’aide d’un simple éditeur de flux de travail par glisser-déposer.
Oracle Data Miner est une extension d’Oracle SQL Developer qui documente et capture les étapes du flux de travail analytique graphique que les utilisateurs prennent pour explorer les données. En outre, son flux de travail est simple et utile pour l’exécution des méthodologies analytiques et le partage des connaissances.

Cette plateforme génère des scripts PL/SQL et SQL et offre rapidement une API pour accélérer le déploiement des modèles dans l’entreprise. Vous disposerez également d’un outil de flux de travail interactif pour créer, évaluer, modifier, partager et déployer des méthodologies d’apprentissage automatique.
En outre, vous disposerez de nœuds graphiques pour visualiser les données, tels que des statistiques sommaires, des diagrammes en boîte, des diagrammes de dispersion et des histogrammes. Divers nœuds, tels que les nœuds de transformation, de filtrage de colonnes et de construction de modèles, vous aident à piloter votre activité.
Oracle Data Miner peut minimiser le temps entre le développement et le déploiement du modèle en éliminant les mouvements de données et en préservant la sécurité. Il responsabilisera également vos équipes en les aidant à développer un ensemble de compétences diverses en utilisant des algorithmes d’apprentissage automatique.
KNIME
Créez et produisez des données d’exploration avec KNIME qui offre un support de science des données de bout en bout pour votre entreprise et améliore la productivité.
Vous obtiendrez deux outils complémentaires avec une plateforme d’entreprise. Vous obtiendrez également KNIME Analytics, qui est une plateforme open-source permettant de créer et de déployer un serveur KNIME commercial et des modèles de science des données.

De plus, KNIME est ouvert, intuitif et peut intégrer en permanence de nouveaux développements pour comprendre et concevoir des flux de travail de science des données accessibles à tous. Le serveur KNIME est utile pour la collaboration, la gestion, le déploiement et l’automatisation des équipes.
Si vous n’êtes pas un expert, KNIME offre un accès au portail web KNIME. De nombreuses extensions sont conçues par KNIME lui-même pour que vous puissiez faire quelque chose de plus. Sa communauté et ses partenaires proposent également des extensions. KNIME s’intègre à des projets open-source pour que vous ne manquiez de rien.
KNIME Analytics Platform est disponible sur Amazon AWS et Microsoft Azure. KNIME peut vous aider à accéder, transformer et fusionner toutes les données et à les analyser à l’aide de vos outils préférés. Il soutiendra votre entreprise grâce à de vastes pratiques d’exploration de données et à des informations utiles collectées à partir des données.
Téléchargez KNIME dès maintenant et commencez à créer votre premier flux de travail.
Orange
L’exploration de données est maintenant amusante avec Orange qui fournit des outils open-source de visualisation de données et d’apprentissage automatique. Il offre une boîte à outils diversifiée pour créer des flux de travail d’analyse de données facilement et visuellement.
Vous pouvez effectuer une visualisation et une analyse simples des données et explorer les diagrammes en boîte, les diagrammes de dispersion, les distributions statistiques, etc. Orange vous permet d’aller plus loin avec le clustering hiérarchique, les cartes thermiques, les arbres de décision, les projections linéaires et le MDS.

Orange peut convertir des données multidimensionnelles en visualisation 2D avec de meilleures sélections et classements d’attributs. Vous trouverez également une interface utilisateur graphique qui vous permettra de vous concentrer davantage sur l’analyse des données plutôt que de perdre du temps à coder.
Les universités, les écoles et les cours de formation du monde entier utilisent Orange pour ses offres impressionnantes. Il prend en charge les illustrations visuelles et la formation pratique des concepts de l’exploration des données. Vous obtiendrez également des widgets pour améliorer votre formation.
En outre, vous pouvez utiliser différents modules complémentaires pour extraire des données de sources externes, effectuer un traitement naturel et une exploration de texte, réaliser une analyse de réseau, déduire des ensembles d’éléments, et bien plus encore. En outre, les biologistes moléculaires et les bioinformaticiens peuvent utiliser Orange pour classer divers gènes par le biais d’une analyse d’enrichissement et d’expression différentielle.
SAS
Révéler des informations précieuses avec SAS Enterprise Miner – un logiciel robuste d’exploration de données pour votre entreprise. Il vous aide à rationaliser l’ensemble du processus pour développer des modèles rapides et comprendre les relations clés.
SAS propose de nombreux outils pour développer de meilleurs modèles. À l’aide d’un diagramme de processus interactif et auto-documenté, vous pouvez cartographier l’ensemble du processus d’exploration de données afin d’obtenir de meilleurs résultats.
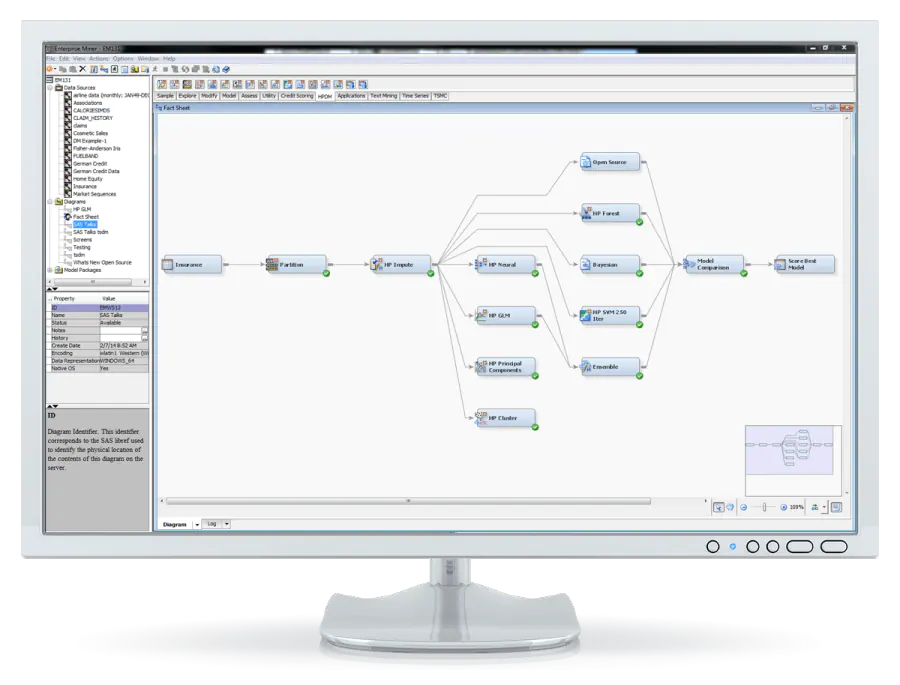
Les experts en la matière et les utilisateurs professionnels ayant des compétences limitées peuvent facilement générer leurs propres modèles via SAS Rapid Predictive Modeler. Vous pouvez également améliorer la précision de vos prédictions en comparant les évaluations et les statistiques de prédiction des modèles créés avec différentes approches.
SAS élimine la réécriture manuelle en vous permettant de déployer le modèle automatiquement et de générer un code de notation pour toutes les étapes. Il offre également une interface graphique facile à utiliser, un traitement par lots, des prédictions avancées, une modélisation descriptive, des performances élevées, une intégration open-source, une option de déploiement dans le nuage, un traitement évolutif, et bien d’autres choses encore.
Qlik
Les plateformes d’intelligenceQlik peuvent combler le fossé entre les idées, les données et l’action. Elles vous permettent de visualiser des données et des analyses en temps réel, collaboratives, exploitables et pilotées par l’IA.
Qlik accélère l’ingestion, la réplication des données et le streaming à travers diverses applications hétérogènes mainframe, SAP, SaaS et bases de données. Vous pouvez automatiser l’ETL et la génération de codes de conception, ainsi que les mises à jour permanentes.
La plateforme vous aidera à réduire les coûts, les risques et les délais de livraison d’un entrepôt de données agile dans le nuage. Vous pouvez utiliser des approches push-down et ELT modernes pour convertir, enrichir, normaliser, consolider et joindre des données provenant de structures hétérogènes.

De plus, le service cloud-native sans code de Qlik rationalise et automatise vos flux de travail entre Qlik Sense et les applications SaaS pour recommander des actions à partir des informations. Vous obtiendrez également des tableaux de bord conviviaux et interactifs, ainsi qu’une prise en charge complète de l’exploration et de la recherche de formes libres.
Qlik exploite l’IA pour faciliter l’ensemble de l’analyse, ce qui permet à un plus grand nombre d’utilisateurs de tirer une valeur extrême des données. Grâce aux API ouvertes, vous avez la possibilité d’intégrer l’analyse dans les applications opérationnelles et de créer des applications externes.
Si vous constatez un changement soudain dans les données, l’action appropriée sera immédiatement déclenchée. Qlik offre également des options de déploiement flexibles pour protéger les besoins de gouvernance locaux et l’emplacement des données avec de multiples options de cloud.
Rattle de Togaware
Rattle est une interface utilisateur graphique pour la science des données utilisant R. Il utilise une boîte à outils GUI, à savoir RGtk2, qui peut être installée à partir du dépôt CRAN de Microsoft.
Connaissez les capacités du logiciel Rattle, qui offre également une utilisation robuste de la ligne de commande. Il
- Présente des résumés visuels et statistiques des données
- Transforme les mêmes données pour la modélisation
- Construit des modèles d’apprentissage automatique supervisés et non supervisés
- Présente des modèles performants sous forme de graphiques
- Évalue les derniers ensembles de données pour le déploiement.
Toutes les interactions sont capturées en tant que script R, qui est à nouveau exécuté en R de manière indépendante avec l’interface Rattle. Vous pouvez apprendre l’outil et l’utiliser pour développer vos compétences en R. Il vous aidera à construire des modèles initiaux avec des options puissantes.
Rattle est une plateforme gratuite et open-source dont le code est disponible dans le dépôt Bitbucket git. Vous aurez la liberté de réviser le code, de l’utiliser aux fins que vous souhaitez et de l’étendre.
Weka
Weka fournit des outils pour mettre en œuvre divers algorithmes d’apprentissage automatique, traiter les données et les visualiser.
Vous pouvez appliquer les techniques d’ apprentissage automatique à des problèmes d’exploration de données dans le monde réel. Les étapes sont simples :
- Vous obtiendrez des données brutes à partir du champ qui peut contenir divers champs non pertinents et des valeurs nulles.
- Utilisez les outils de prétraitement des données de Weka pour nettoyer les données.
- Enregistrez les données nettoyées dans le stockage local pour appliquer les algorithmes d’apprentissage automatique.
- En fonction du type ou du modèle d’apprentissage automatique, vous choisirez parmi les options disponibles, y compris la classification, le regroupement ou l’association.
- Automatiser le flux de travail
Vous avez la liberté de sélectionner n’importe quel algorithme fourni par Weka et de définir les paramètres souhaités pour exécuter l’ensemble de données. Obtenez des résultats statistiques de Weka et un outil de visualisation pour l’inspection des données.
Il applique différents modèles sur le même ensemble de données afin de comparer les résultats des modèles et de sélectionner le meilleur dont vous avez besoin.
Sisense
La plateforme d’analyse API-first, Sisense, fournit des analyses entièrement personnalisables et en marque blanche à chaque fois que vous en avez besoin.
Transformez votre mode de travail traditionnel et développez votre entreprise en libérant la puissance des données. Débloquez les données sur site et dans le nuage pour les analyser et obtenir de meilleurs résultats.

Vous pouvez automatiser les actions à plusieurs étapes de votre flux de travail et créer des expériences personnalisées pour accélérer les flux de travail. Sisense offre une plateforme cloud ouverte qui est étendue par des partenariats technologiques pour améliorer l’évolutivité.
De plus, vous pouvez ajouter des analyses alimentées par l’IA à vos flux de travail, applications, produits et processus pour bénéficier de l’intelligence au bon endroit et au bon moment afin d’éliminer les lenteurs.
Quel que soit votre niveau de compétence, Sisense peut permettre à chacun d’utiliser efficacement l’analyse pour prendre de meilleures décisions commerciales. Vous pouvez également différencier les produits, responsabiliser vos consommateurs et créer de nouveaux flux grâce à l’analyse alimentée par l’IA.
InetSoft
La Style Intelligence d’InetSoft rend l’analyse rapide et facile. Il s’agit d’une plateforme web qui accède aux données de n’importe quelle source, quelle que soit la taille de la base de données, et qui traite les petits ensembles de données pour une analyse plus facile et plus rapide.
Il s’agit de l’un des meilleurs logiciels d’exploration de données pour votre entreprise, qui vous permet d’explorer un large éventail de caches de données et d’obtenir de nouveaux outils d’étude de marché.
Style Intelligence peut gérer des projets de big data et est conçu à l’aide d’une technologie propriétaire de cache de grille de données basée sur les principes MapReduce qui facilitent le big data.
Apache Mahout
Apache Mahout est un DSL Scala mathématiquement expressif et un cadre d’algèbre linéaire distribuée spécialement conçu pour les scientifiques des données, les statisticiens et les mathématiciens afin de mettre en œuvre leurs algorithmes.

Il s’agit d’un projet open-source de science des données qui aide à créer des algorithmes d’apprentissage automatique. Il y a beaucoup de choses qui se passent à différents niveaux. Il met en œuvre des techniques d’apprentissage populaires, notamment la recommandation, la classification et le regroupement.
Les algorithmes d’Apache Mahout sont écrits sur Hadoop. Ils fonctionnent donc bien et utilisent la bibliothèque Hadoop pour évoluer dans le nuage. Vous obtiendrez un cadre prêt à l’emploi et facile à utiliser pour vos tâches d’exploration de données. Il permet également aux applications d’analyser les Big Data rapidement et efficacement.
H2O
Obtenez l’IA de mutation génétique qui apporte des décisions intelligentes directement aux cliniciens avec H2O. Il vous aidera à suivre, gérer et prédire les admissions liées au COVID-19 dans les hôpitaux.
H2O résout de nombreux problèmes complexes dans votre entreprise et accélère les idées innovantes avec des résultats exploitables. Elle peut transformer la façon dont l’IA est construite et consommée et dispose d’une IA intégrée qui rend le travail plus rapide et plus facile.

De plus, H2O maintient la vitesse, la transparence et la précision afin que vous puissiez construire des modèles sans aucune limite. Rationalisez vos flux de travail en fonction de la performance en surveillant les données pour prendre une décision actuelle.
Grâce à un AppStore AI intuitif, vous pouvez facilement fournir des solutions innovantes aux utilisateurs finaux. Plus de 20 000 organisations utilisent H2O pour leur technologie d’exploration de données. H2O peut vous aider à optimiser vos opérations en vous fournissant des informations exploitables, des opérations rationalisées, des risques réduits et des expériences personnalisées.
Commencez dès aujourd’hui un essai gratuit de 90 jours et bénéficiez d’une expérience pratique avec son nuage d’IA pour créer des applications et des modèles de classe mondiale sur site et dans le nuage.
Conclusion
L’exploration de données est un moyen efficace de collecter des informations significatives et de les mettre au service de votre entreprise. Il vous aidera à optimiser vos opérations et vos coûts, et à prendre de meilleures décisions.
Pour ce faire, utilisez le meilleur logiciel de data mining et continuez à obtenir des informations précieuses pour votre entreprise.