À l’ère de l’information, les centres de données collectent de grandes quantités de données. Les données collectées proviennent de diverses sources telles que les transactions financières, les interactions avec les clients, les médias sociaux et bien d’autres, et surtout, elles s’accumulent plus rapidement.
Les données peuvent être diverses et sensibles et nécessitent les bons outils pour les rendre significatives, car elles ont un potentiel illimité pour moderniser les statistiques et les informations des entreprises et changer les vies.
Ceci étant dit, explorons les meilleurs outils de Big Data.
Apache Hadoop
Apache Hadoop est une plateforme Java open-source qui stocke et traite de grandes quantités de données.

Hadoop fonctionne en cartographiant de grands ensembles de données (de téraoctets à pétaoctets), en analysant les tâches entre les clusters et en les divisant en morceaux plus petits (64 Mo à 128 Mo), ce qui permet d’accélérer le traitement des données.
Pour stocker et traiter les données, celles-ci sont envoyées au cluster Hadoop, HDFS (Hadoop distributed file system) les stocke, MapReduce les traite et YARN (Yet another resource negotiator) divise les tâches et attribue les ressources.
Il convient aux scientifiques des données, aux développeurs et aux analystes de diverses entreprises et organisations pour la recherche et la production.
Caractéristiques
- Réplication des données : Plusieurs copies du bloc sont stockées dans différents nœuds et servent de tolérance aux pannes en cas d’erreur.
- Hautement évolutif : Offre une évolutivité verticale et horizontale
- Intégration avec d’autres modèles Apache, Cloudera et Hortonworks
Envisagez de suivre ce brillant cours en ligne pour apprendre le Big Data avec Apache Spark.
Rapidminer
Le site web de Rapidminer affirme qu’environ 40 000 organisations dans le monde utilisent leur logiciel pour augmenter les ventes, réduire les coûts et éviter les risques.

Le logiciel a reçu plusieurs récompenses : Gartner Vision Awards 2021 pour les plateformes de science des données et d’apprentissage automatique, l’analyse prédictive multimodale et les solutions d’apprentissage automatique de Forrester et Crowd’s most user-friendly machine learning and data science platform in spring G2 report 2021.
Il s’agit d’une plateforme de bout en bout pour le cycle de vie scientifique, parfaitement intégrée et optimisée pour la construction de modèles ML (machine learning). Elle documente automatiquement chaque étape de la préparation, de la modélisation et de la validation pour une transparence totale.
Il s’agit d’un logiciel payant disponible en trois versions : Préparer les données, Créer et valider, et Déployer le modèle. Il est même disponible gratuitement pour les établissements d’enseignement, et RapidMiner est utilisé par plus de 4 000 universités dans le monde.
Fonctionnalités
- Il vérifie les données pour identifier les modèles et résoudre les problèmes de qualité
- Il utilise un concepteur de flux de travail sans code avec 1 500 algorithmes
- Intégration de modèles d’apprentissage automatique dans des applications commerciales existantes
Tableau
Tableau offre la flexibilité nécessaire pour analyser visuellement les plateformes, résoudre les problèmes et responsabiliser les personnes et les organisations. Il est basé sur la technologie VizQL (langage visuel pour les requêtes de base de données), qui convertit le glisser-déposer en requêtes de données par le biais d’une interface utilisateur intuitive.
Tableau a été racheté par Salesforce en 2019. Il permet de relier des données provenant de sources telles que des bases de données SQL, des feuilles de calcul ou des applications cloud comme Google Analytics et Salesforce.
Les utilisateurs peuvent acheter ses versions Creator, Explorer et Viewer en fonction des préférences de l’entreprise ou de l’individu, car chacune possède ses propres caractéristiques et fonctions.
Il est idéal pour les analystes, les scientifiques des données, le secteur de l’éducation et les utilisateurs professionnels afin de mettre en œuvre et d’équilibrer une culture axée sur les données et de l’évaluer à travers les résultats.
Caractéristiques
- Les tableaux de bord fournissent un aperçu complet des données sous forme d’éléments visuels, d’objets et de texte.
- Large choix de graphiques de données : histogrammes, diagrammes de Gantt, diagrammes, diagrammes de mouvement, etc
- Protection par filtre au niveau des lignes pour garantir la sécurité et la stabilité des données
- Son architecture permet des analyses et des prévisions prévisibles
L’apprentissage de Tableau est facile.
Cloudera
Cloudera offre une plateforme sécurisée pour les centres de données et le cloud pour la gestion des données volumineuses. Elle utilise l’analyse des données et l’apprentissage automatique pour transformer des données complexes en informations claires et exploitables.
Cloudera propose des solutions et des outils pour les clouds privés et hybrides, l’ingénierie des données, le flux de données, le stockage des données, la science des données pour les data scientists, et plus encore.

Une plateforme unifiée et des outils d’analyse multifonctionnels améliorent le processus de découverte d’informations basées sur les données. Sa science des données offre une connectivité à tous les systèmes utilisés par l’organisation, et pas seulement à Cloudera et Hortonworks (les deux sociétés ont conclu un partenariat).
Les scientifiques des données gèrent leurs propres activités telles que l’analyse, la planification, la surveillance et les notifications par courrier électronique via des feuilles de travail interactives sur la science des données. Par défaut, il s’agit d’une plateforme conforme aux normes de sécurité qui permet aux scientifiques des données d’accéder aux données Hadoop et d’exécuter facilement des requêtes Spark.
La plateforme convient aux ingénieurs de données, aux scientifiques de données et aux professionnels de l’informatique dans divers secteurs tels que les hôpitaux, les institutions financières, les télécommunications et bien d’autres.
Caractéristiques
- Prise en charge de tous les principaux clouds privés et publics, tandis que le Data Science Workbench prend en charge les déploiements sur site
- Les canaux de données automatisés convertissent les données en formes utilisables et les intègrent à d’autres sources.
- Un flux de travail uniforme permet une construction, une formation et une mise en œuvre rapides des modèles.
- Environnement sécurisé pour l’authentification, l’autorisation et le cryptage Hadoop.
Apache Hive
Apache Hive est un projet open-source développé au-dessus d’Apache Hadoop. Il permet de lire, d’écrire et de gérer de grands ensembles de données disponibles dans divers référentiels et permet aux utilisateurs de combiner leurs propres fonctions pour une analyse personnalisée.
Hive est conçu pour des tâches de stockage traditionnelles et n’est pas destiné à des tâches de traitement en ligne. Ses cadres de traitement par lots robustes offrent une évolutivité, des performances, une modularité et une tolérance aux pannes.
Il convient à l’extraction de données, à la modélisation prédictive et à l’indexation de documents. Il n’est pas recommandé pour l’interrogation de données en temps réel, car il introduit un temps de latence dans l’obtention des résultats.
Caractéristiques
- Prise en charge des moteurs de calcul MapReduce, Tez et Spark
- Traite d’énormes ensembles de données, d’une taille de plusieurs pétaoctets
- Très facile à coder par rapport à Java
- Offre une tolérance aux pannes en stockant les données dans le système de fichiers distribués Apache Hadoop
Apache Storm
Apache Storm est une plateforme gratuite et open-source utilisée pour traiter des flux de données illimités. Elle fournit le plus petit ensemble d’unités de traitement utilisé pour développer des applications capables de traiter de très grandes quantités de données en temps réel.
Un Storm est suffisamment rapide pour traiter un million de tuples par seconde et par nœud, et il est facile à utiliser.
Apache Storm vous permet d’ajouter des nœuds à votre cluster et d’augmenter la puissance de traitement des applications. La capacité de traitement peut être doublée par l’ajout de nœuds, car l’évolutivité horizontale est maintenue.
Les scientifiques des données peuvent utiliser Storm pour DRPC (Distributed Remote Procedure Calls), l’analyse ETL (Retrieval-Conversion-Load) en temps réel, le calcul continu, l’apprentissage automatique en ligne, etc. Il est conçu pour répondre aux besoins de traitement en temps réel de Twitter, Yahoo et Flipboard.
Caractéristiques
- Facile à utiliser avec n’importe quel langage de programmation
- Il est intégré à tous les systèmes de file d’attente et à toutes les bases de données
- Storm utilise Zookeeper pour gérer les clusters et s’adapte à des clusters de plus grande taille
- La protection garantie des données remplace les tuples perdus en cas de problème
Snowflake
Le plus grand défi pour les scientifiques des données est de préparer les données à partir de différentes ressources, car ils passent beaucoup de temps à récupérer, consolider, nettoyer et préparer les données. Snowflake répond à cette problématique.
Il offre une plateforme unique de haute performance qui élimine les tracas et les retards causés par l’ETL (transformation et extraction de charge). Il peut également être intégré avec les derniers outils et bibliothèques d’apprentissage automatique (ML), tels que Dask et Saturn Cloud.
Snowflake offre une architecture unique de clusters de calcul dédiés à chaque charge de travail pour effectuer ces activités de calcul de haut niveau, de sorte qu’il n’y a pas de partage des ressources entre les charges de travail de science des données et de BI (business intelligence).
Il prend en charge les types de données structurées, semi-structurées (JSON, Avro, ORC, Parquet ou XML) et non structurées. Il utilise une stratégie de lac de données pour améliorer l’accès aux données, les performances et la sécurité.
Les scientifiques et analystes de données utilisent les snowflakes dans divers secteurs, notamment la finance, les médias et le divertissement, la vente au détail, la santé et les sciences de la vie, la technologie et le secteur public.
Caractéristiques
- Compression élevée des données pour réduire les coûts de stockage
- Cryptage des données au repos et en transit
- Moteur de traitement rapide avec une faible complexité opérationnelle
- Profilage intégré des données avec des vues sous forme de tableaux, de graphiques et d’histogrammes
DataRobot
DataRobot est un leader mondial dans le domaine de l’informatique en nuage avec IA (Intelligence Artificielle). Sa plateforme unique est conçue pour servir toutes les industries, y compris les utilisateurs et les différents types de données.

L’entreprise affirme que son logiciel est utilisé par un tiers des entreprises du Fortune 50 et fournit plus d’un trillion d’estimations dans divers secteurs.
DataRobot utilise l’apprentissage automatique et est conçu pour permettre aux professionnels des données d’entreprise de créer, d’adapter et de déployer rapidement des modèles de prévision précis.
Il permet aux scientifiques d’accéder facilement à un grand nombre des derniers algorithmes d’apprentissage automatique avec une transparence totale pour automatiser le prétraitement des données. Le logiciel a développé des clients R et Python dédiés aux scientifiques pour résoudre des problèmes complexes de science des données.
Il permet d’automatiser la qualité des données, l’ingénierie des fonctionnalités et les processus de mise en œuvre afin de faciliter les activités des scientifiques des données. Il s’agit d’un produit haut de gamme, dont le prix est disponible sur demande.
Caractéristiques
- Augmentation de la valeur de l’entreprise en termes de rentabilité et de simplification des prévisions
- Processus de mise en œuvre et automatisation
- Prend en charge les algorithmes de Python, Spark, TensorFlow et d’autres sources.
- L’intégration de l’API vous permet de choisir parmi des centaines de modèles
TensorFlow
TensorFlow est une bibliothèque communautaire basée sur l’IA (intelligence artificielle) qui utilise des diagrammes de flux de données pour construire, former et déployer des applications d’apprentissage automatique (ML). Elle permet aux développeurs de créer de vastes réseaux neuronaux en couches.

Elle comprend trois modèles : TensorFlow.js, TensorFlow Lite et TensorFlow Extended (TFX). Son mode javascript est utilisé pour l’entraînement et le déploiement de modèles dans le navigateur et sur Node.js en même temps. Son mode Lite permet de déployer des modèles sur des appareils mobiles et embarqués, et le modèle TFX permet de préparer des données, de valider et de déployer des modèles.
Grâce à sa plateforme robuste, il peut être déployé sur des serveurs, des appareils périphériques ou sur le web, quel que soit le langage de programmation.
TFX contient des mécanismes pour renforcer les pipelines de ML qui peuvent être ascendants et fournir des fonctions de performance globale robustes. Les pipelines d’ingénierie des données tels que Kubeflow et Apache Airflow prennent en charge TFX.
La plateforme Tensorflow convient aux débutants. Intermédiaire et pour les experts pour former un réseau accusatoire génératif pour générer des images de chiffres manuscrits à l’aide de Keras.
Caractéristiques
- Vous pouvez déployer des modèles de ML sur site, dans le nuage et dans le navigateur, quelle que soit la langue
- Construction facile de modèles à l’aide d’API innées pour une répétition rapide des modèles
- Ses diverses bibliothèques et modèles complémentaires soutiennent les activités de recherche et d’expérimentation
- Construction facile de modèles à l’aide de plusieurs niveaux d’abstraction
Matplotlib
Matplotlib est un logiciel communautaire complet de visualisation de données animées et de graphiques pour le langage de programmation Python. Sa conception unique est structurée de manière à ce qu’un graphique visuel de données soit généré à l’aide de quelques lignes de code.
Il existe diverses applications tierces telles que des programmes de dessin, des interfaces graphiques, des cartes de couleurs, des animations et bien d’autres encore qui sont conçues pour être intégrées à Matplotlib.
Ses fonctionnalités peuvent être étendues avec de nombreux outils tels que Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn, et d’autres.
Ses meilleures caractéristiques incluent le dessin de graphiques et de cartes avec des données structurées et non structurées.
BigML
BigML est une plateforme collective et transparente pour les ingénieurs, les scientifiques des données, les développeurs et les analystes. Elle transforme les données de bout en bout en modèles exploitables.

Il crée, expérimente, automatise et gère efficacement les flux de travail de ML, contribuant ainsi à des applications intelligentes dans un large éventail d’industries.
Cette plateforme programmable de ML (machine learning) aide au séquençage, à la prédiction de séries temporelles, à la détection d’associations, à la régression, à l’analyse de clusters, et bien plus encore.
Sa version entièrement gérable, avec un ou plusieurs locataires et un déploiement possible pour n’importe quel fournisseur de cloud, permet aux entreprises de donner facilement accès aux big data à tout le monde.
Son prix commence à 30 dollars, il est gratuit pour les petits ensembles de données et à des fins éducatives, et il est utilisé dans plus de 600 universités.
Grâce à ses algorithmes ML robustes, il convient à divers secteurs tels que l’industrie pharmaceutique, le divertissement, l’automobile, l’aérospatiale, les soins de santé, l’IoT et bien d’autres encore.
Caractéristiques
- Automatisez les flux de travail complexes et chronophages en un seul appel d’API
- Elle peut traiter de grandes quantités de données et effectuer des tâches parallèles
- La bibliothèque est prise en charge par des langages de programmation populaires tels que Python, Node.js, Ruby, Java, Swift, etc.
- Ses détails granulaires facilitent le travail d’audit et les exigences réglementaires
Apache Spark
C’est l’un des plus grands moteurs open-source largement utilisé par les grandes entreprises. Apache Spark est utilisé par 80 % des entreprises du classement Fortune 500, selon le site web. Il est compatible avec les nœuds simples et les clusters pour le big data et le ML.

Il est basé sur un langage SQL (Structured Query Language) avancé pour prendre en charge de grandes quantités de données et travailler avec des tables structurées et des données non structurées.
La plateforme Spark est connue pour sa facilité d’utilisation, sa grande communauté et sa vitesse fulgurante. Les développeurs utilisent Spark pour créer des applications et exécuter des requêtes en Java, Scala, Python, R et SQL.
Caractéristiques
- Traite les données par lots et en temps réel
- Prise en charge de grandes quantités de données (pétaoctets) sans déséchantillonnage
- Il est facile de combiner plusieurs bibliothèques comme SQL, MLib, Graphx et Stream dans un seul flux de travail.
- Fonctionne sur Hadoop YARN, Apache Mesos, Kubernetes, et même dans le cloud et a accès à de multiples sources de données
KNIME
KNIME est une plateforme open-source intuitive pour les applications de science des données. Un data scientist et un analyste peuvent créer des flux de travail visuels sans codage avec une simple fonctionnalité de glisser-déposer.

La version serveur est une plateforme commerciale utilisée pour l’automatisation, la gestion de la science des données et l’analyse de gestion. KNIME rend les flux de travail de la science des données et les composants réutilisables accessibles à tous.
Caractéristiques
- Grande flexibilité pour l’intégration de données à partir d’Oracle, SQL, Hive, etc
- Accédez à des données provenant de sources multiples telles que SharePoint, Amazon Cloud, Salesforce, Twitter, etc
- L’utilisation de ml se fait sous la forme de construction de modèles, d’optimisation des performances et de validation de modèles.
- L’analyse des données sous forme de visualisation, de statistiques, de traitement et de rapports
Ensuite, nous discuterons de l’importance des outils de big data.
Les outils Big Data et les Data Scientists occupent une place prépondérante dans de tels scénarios.
Une telle quantité de données diverses rend difficile leur traitement à l’aide d’outils et de techniques traditionnels tels qu’Excel. Excel n’est pas vraiment une base de données et a une limite (65 536 lignes) pour le stockage des données.
L’analyse des données dans Excel montre une mauvaise intégrité des données. À long terme, les données stockées dans Excel ont une sécurité et une conformité limitées, des taux de reprise après sinistre très faibles et aucun contrôle de version adéquat.
Pour traiter des ensembles de données aussi vastes et diversifiés, un ensemble unique d’outils, appelés outils de données, est nécessaire pour examiner, traiter et extraire des informations précieuses. Ces outils vous permettent de creuser en profondeur dans vos données afin de trouver des informations plus significatives et des modèles de données.
La gestion d’outils technologiques et de données aussi complexes exige naturellement un ensemble de compétences uniques, et c’est la raison pour laquelle le data scientist joue un rôle essentiel dans le domaine du big data.
L’importance des outils de big data
Les données sont la pierre angulaire de toute organisation et sont utilisées pour extraire des informations précieuses, effectuer des analyses détaillées, créer des opportunités et planifier les nouvelles étapes et visions de l’entreprise.
De plus en plus de données sont créées chaque jour et doivent être stockées de manière efficace et sécurisée, puis rappelées en cas de besoin. La taille, la variété et l’évolution rapide de ces données nécessitent de nouveaux outils de big data, ainsi que des méthodes de stockage et d’analyse différentes.
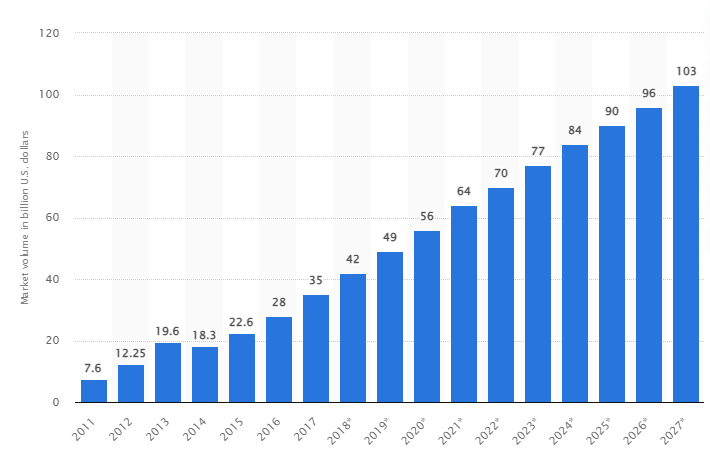
Selon une étude, le marché mondial des big data devrait atteindre 103 milliards de dollars américains d’ici 2027, soit plus du double de la taille du marché prévue en 2018.
Les défis actuels de l’industrie
Le terme “big data” a récemment été utilisé pour désigner des ensembles de données qui ont pris une telle ampleur qu’ils sont difficiles à utiliser avec les systèmes de gestion de base de données (SGBD) traditionnels.
La taille des données augmente constamment et varie aujourd’hui de plusieurs dizaines de téraoctets (TB) à plusieurs pétaoctets (PB) dans un seul ensemble de données. La taille de ces ensembles de données dépasse la capacité des logiciels courants à les traiter, les gérer, les rechercher, les partager et les visualiser au fil du temps.
La formation de big data entraînera les conséquences suivantes :
- La gestion et l’amélioration de la qualité
- Gestion de la chaîne d’approvisionnement et de l’efficacité
- Renseignements sur les clients
- Analyse des données et prise de décision
- Gestion des risques et détection des fraudes
Dans cette section, nous examinons les meilleurs outils de big data et la manière dont les data scientists utilisent ces technologies pour filtrer, analyser, stocker et extraire les données lorsque les entreprises souhaitent une analyse plus approfondie afin d’améliorer et de développer leurs activités.
Quelle est l’importance des 5 V du big data ?
Les 5 V du big data aident les data scientists à comprendre et à analyser les big data pour en tirer davantage d’informations. Cela permet également de fournir plus de statistiques utiles aux entreprises pour prendre des décisions éclairées et obtenir un avantage concurrentiel.
👉 Volume : Le big data est basé sur le volume. Le volume quantique détermine la taille des données. Il contient généralement une grande quantité de données en téraoctets, pétaoctets, etc. En fonction de la taille du volume, les scientifiques des données planifient divers outils et intégrations pour l’analyse des ensembles de données.
👉 Vélocité : La vitesse de collecte des données est essentielle car certaines entreprises ont besoin d’informations sur les données en temps réel, et d’autres préfèrent traiter les données par paquets. Plus le flux de données est rapide, plus les data scientists peuvent évaluer et fournir des informations pertinentes à l’entreprise.
👉 Variété : Les données proviennent de différentes sources et, ce qui est important, ne se présentent pas sous un format fixe. Les données sont disponibles dans des formats structurés (format de base de données), semi-structurés (XML/RDF) et non structurés (données binaires). Basés sur les structures de données, les outils big data sont utilisés pour créer, organiser, filtrer et traiter les données.
👉 Véracité : L’exactitude des données et les sources crédibles définissent le contexte du big data. L’ensemble des données provient de diverses sources telles que les ordinateurs, les appareils de réseau, les appareils mobiles, les médias sociaux, etc. En conséquence, les données doivent être analysées pour être envoyées à leur destination.
👉 Valeur : Enfin, quelle est la valeur des big data d’une entreprise ? Le rôle du data scientist est d’utiliser au mieux les données pour démontrer comment les connaissances sur les données peuvent ajouter de la valeur à une entreprise.
Conclusion
La liste des big data ci-dessus comprend des outils payants et des outils open-source. Des informations succinctes et des fonctions sont fournies pour chaque outil. Si vous recherchez des informations plus détaillées, vous pouvez consulter les sites web correspondants.
Les entreprises qui cherchent à acquérir un avantage concurrentiel utilisent les big data et les outils connexes tels que l’IA (intelligence artificielle), le ML (machine learning) et d’autres technologies pour prendre des mesures tactiques afin d’améliorer le service à la clientèle, la recherche, le marketing, la planification future, etc.
Les outils de big data sont utilisés dans la plupart des industries, car de petits changements dans la productivité peuvent se traduire par des économies significatives et des profits importants. Nous espérons que l’article ci-dessus vous a donné un aperçu des outils de big data et de leur importance.