
Alors que les cyber-attaques continuent d’augmenter en volume, en diversité et en sophistication, et qu’elles sont de plus en plus perturbatrices et dommageables, les organisations doivent être préparées à y faire face de manière efficace.
Outre le déploiement de solutions et de pratiques de sécurité efficaces, elles doivent être en mesure d’identifier et de traiter rapidement les attaques, afin de minimiser les dommages, les perturbations et les coûts.
Chaque système informatique est une cible potentielle d’une cyberattaque, et la plupart des gens s’accordent à dire qu’il ne s’agit pas de savoir si, mais quand cela se produira. Cependant, l’impact varie en fonction de la rapidité et de l’efficacité avec lesquelles vous traitez le problème, d’où la nécessité d’une préparation à la réponse aux incidents.
Une réponse à un incident de cybersécurité (RI) est une série de processus qu’une organisation met en œuvre pour faire face à une attaque contre ses systèmes informatiques. Cela nécessite une combinaison d’outils matériels et logiciels appropriés ainsi que des pratiques telles qu’une planification, des procédures, une formation et un soutien adéquats de la part de tous les membres de l’organisation.
Meilleures pratiques avant, pendant et après les incidents de sécurité
Lorsqu’une cyberattaque se produit, de multiples activités peuvent avoir lieu simultanément, ce qui peut s’avérer très difficile en l’absence de coordination ou de procédures adéquates de gestion des incidents.
Cependant, en se préparant à l’avance et en établissant un plan et des politiques de réponse aux incidents clairs et faciles à comprendre, les équipes de sécurité peuvent travailler en harmonie. Elles peuvent ainsi se concentrer sur les tâches essentielles qui limitent les dommages potentiels à leurs systèmes informatiques, à leurs données et à leur réputation, tout en évitant les interruptions d’activité inutiles.
Préparer un plan de réponse aux incidents
Un plan de réponse à un incident documente les étapes à suivre en cas d’attaque ou de tout autre problème de sécurité. Bien que les étapes réelles puissent varier en fonction de l’environnement, un processus typique, basé sur le cadre SANS (SysAdmin, Audit, Network, and Security), comprendra la préparation, l’identification, l’endiguement, l’élimination, la récupération, la notification de l’incident et un examen post-incident.
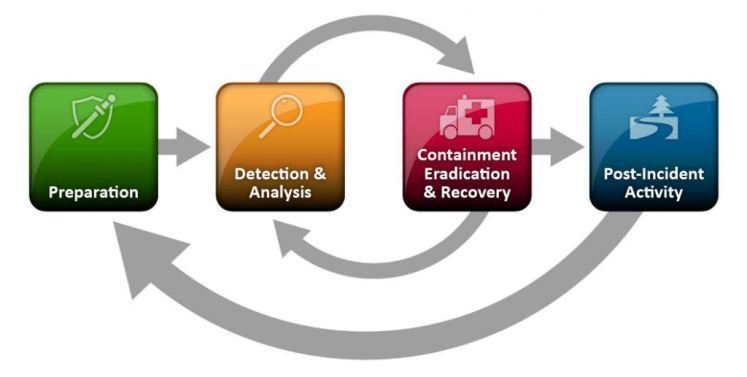
La préparation comprend l’élaboration d’un plan contenant les informations pertinentes et les procédures effectives que l’équipe de réponse aux incidents informatiques (CIRT) suivra pour traiter l’incident.
Ces procédures sont les suivantes :
- Des équipes et des personnes spécifiques responsables de chaque étape du processus de réponse à l’incident.
- La définition de ce qui constitue un incident, y compris ce qui justifie quel type de réponse.
- Les données et les systèmes critiques qui nécessitent une protection et une sauvegarde accrues.
- Un moyen de préserver les états des systèmes affectés à des fins médico-légales.
- Des procédures permettant de déterminer quand et qui doit être informé d’un problème de sécurité. Lorsqu’un incident se produit, il peut être nécessaire d’informer les utilisateurs, les clients, le personnel chargé de l’application de la loi, etc. concernés, mais cela diffère d’un secteur d’activité et d’un cas à l’autre.
Un plan d’intervention en cas d’incident doit être facile à comprendre et à mettre en œuvre et s’aligner sur les autres plans et politiques de l’organisation. Cependant, la stratégie et l’approche peuvent varier selon les secteurs, les équipes, les menaces et les dommages potentiels. Des tests et des mises à jour régulières garantissent la validité et l’efficacité du plan.
Étapes de la réponse à un incident en cas de cyberattaque
Lorsqu’un incident de sécurité se produit, les équipes doivent agir rapidement et efficacement pour le contenir et éviter qu’il ne se propage à des systèmes propres. Vous trouverez ci-dessous les meilleures pratiques pour traiter les problèmes de sécurité. Elles peuvent toutefois varier en fonction de l’environnement et de la structure de l’organisation.
Constituez ou engagez l’équipe d’intervention en cas d’incident informatique
Veillez à ce que l’équipe CIRT pluridisciplinaire, interne ou externalisée, soit composée de personnes possédant les compétences et l’expérience requises. Parmi ces personnes, choisissez un chef d’équipe qui sera la personne de référence pour donner des instructions et veiller à ce que l’intervention se déroule conformément au plan et aux délais prévus. Le chef d’équipe travaillera également en étroite collaboration avec la direction, en particulier lorsqu’il s’agira de prendre des décisions importantes concernant les opérations.
Identifier l’incident et déterminer le type et la source de l’attaque
Au moindre signe de menace, l’équipe RI doit agir rapidement pour vérifier s’il s’agit bien d’un problème de sécurité, qu’il soit interne ou externe, tout en veillant à le circonscrire le plus vite possible. Les moyens habituels de déterminer s’il s’agit d’un problème sont, entre autres, les suivants ;
- Alertes provenant d’outils de surveillance de la sécurité, dysfonctionnements au sein des systèmes, comportements inhabituels, modifications, copies ou téléchargements de fichiers inattendus ou inhabituels, etc
- Les rapports des utilisateurs, des administrateurs de réseau ou de système, du personnel de sécurité ou des partenaires ou clients tiers externes.
- Journaux d’audit présentant des signes de comportement inhabituel des utilisateurs ou des systèmes, tels que plusieurs tentatives de connexion infructueuses, des téléchargements de fichiers volumineux, une utilisation élevée de la mémoire et d’autres anomalies.
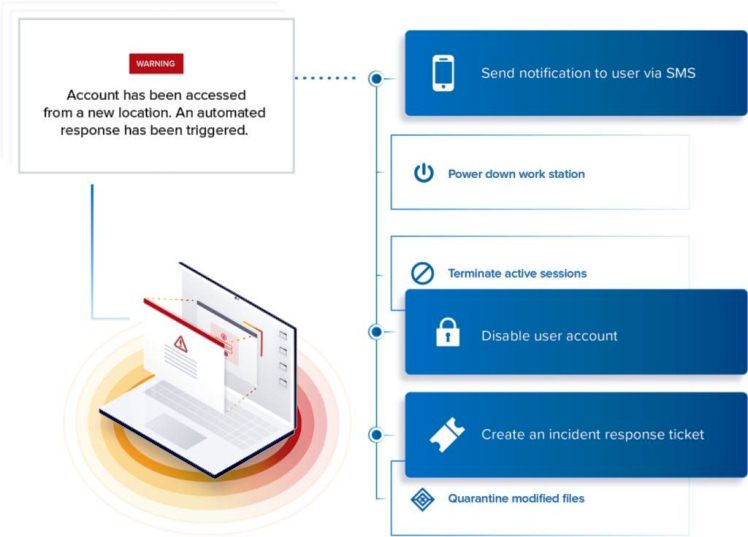
Évaluer et analyser l’impact de l’attaque
Les dommages causés par une attaque varient en fonction de son type, de l’efficacité de la solution de sécurité et de la rapidité de réaction de l’équipe. Le plus souvent, il n’est pas possible de voir l’étendue des dégâts avant d’avoir résolu complètement le problème. L’analyse doit permettre de déterminer le type d’attaque, son impact et les services qu’elle a pu affecter.
Il convient également de rechercher les traces que l’attaquant a pu laisser et de rassembler les informations qui permettront de déterminer la chronologie des activités. Cela implique d’analyser tous les composants des systèmes affectés, de capturer les informations pertinentes pour la criminalistique et de déterminer ce qui a pu se passer à chaque étape.
En fonction de l’ampleur de l’attaque et des résultats, il peut s’avérer nécessaire de transmettre l’incident à l’équipe compétente.
Confinement, élimination des menaces et récupération
La phase d’endiguement consiste à empêcher l’attaque de se propager et à rétablir les systèmes dans leur état de fonctionnement initial. Idéalement, l’équipe CIRT devrait identifier la menace et la cause première, éliminer toutes les menaces en bloquant ou en déconnectant les systèmes compromis, en nettoyant les logiciels malveillants ou les virus, en bloquant les utilisateurs malveillants et en rétablissant les services.
Elle doit également identifier et traiter les vulnérabilités exploitées par les attaquants afin d’éviter que de telles situations ne se reproduisent. Un confinement typique implique des mesures à court et à long terme ainsi qu’une sauvegarde de l’état actuel.
Avant de restaurer une sauvegarde propre ou de nettoyer les systèmes, il est important de conserver une copie de l’état des systèmes affectés. Cela est nécessaire pour préserver l’état actuel, ce qui peut être utile en cas d’analyse médico-légale. Une fois la sauvegarde effectuée, l’étape suivante consiste à restaurer les services perturbés. Les équipes peuvent y parvenir en deux phases :
- Vérifier les systèmes et les composants du réseau pour s’assurer qu’ils fonctionnent tous correctement
- Revérifier tous les composants qui ont été infectés ou compromis, puis nettoyés ou restaurés, afin de s’assurer qu’ils sont désormais sécurisés, propres et opérationnels.
Notification et rapport
L’équipe de réponse à l’incident se charge de l’analyse, de la réponse et de l’établissement de rapports. Elle doit explorer la cause première de l’incident, documenter ses conclusions sur l’impact, la manière dont elle a résolu le problème, la stratégie de récupération tout en transmettant les informations pertinentes à la direction, aux autres équipes, aux utilisateurs et aux fournisseurs tiers.
[caption id="attachment_37217" align="alignnone" width="601"]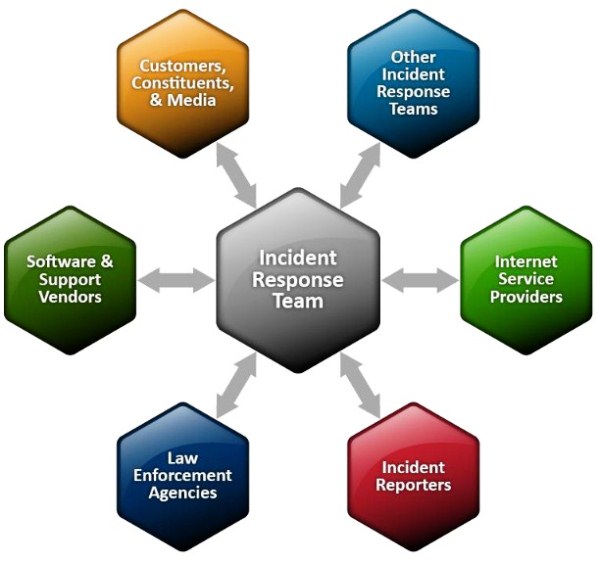 Communications avec les agences et fournisseurs externes Image NIST
Communications avec les agences et fournisseurs externes Image NIST
Si la violation porte sur des données sensibles qui doivent être notifiées aux autorités chargées de l’application de la loi, l’équipe doit prendre l’initiative de le faire et suivre les procédures établies dans sa politique informatique.
En général, une attaque entraîne le vol, l’utilisation abusive, la corruption ou d’autres activités non autorisées sur des données sensibles telles que des informations confidentielles, personnelles, privées et commerciales. C’est pourquoi il est essentiel d’informer les personnes concernées afin qu’elles puissent prendre des précautions et protéger leurs données critiques telles que les informations financières, personnelles et autres informations confidentielles.
Par exemple, si un pirate parvient à accéder à des comptes d’utilisateurs, les équipes de sécurité doivent les avertir et leur demander de changer leurs mots de passe.
Effectuez un examen post-incident
La résolution d’un incident permet également de tirer des enseignements, et les équipes peuvent analyser leur solution de sécurité et s’attaquer aux maillons faibles afin de prévenir un incident similaire à l’avenir. Parmi les améliorations possibles, citons le déploiement de meilleures solutions de sécurité et de surveillance des menaces internes et externes, l’information du personnel et des utilisateurs sur les menaces de sécurité telles que le phishing, le spam, les logiciels malveillants et d’autres qu’ils doivent éviter.
D’autres mesures de protection consistent à utiliser les outils de sécurité les plus récents et les plus efficaces, à appliquer des correctifs aux serveurs, à remédier à toutes les vulnérabilités des ordinateurs clients et serveurs, etc.
Étude de cas sur la réponse à l’incident du NIC Asia Bank au Népal
Une capacité de détection ou de réaction inadéquate peut entraîner des dommages et des pertes excessifs. Un exemple est celui de la NIC Asia Bank du Népal, qui a perdu et récupéré de l’argent après la compromission d’un processus opérationnel en 2017. Les attaquants ont compromis le SWIFT et ont transféré frauduleusement des fonds de la banque vers divers comptes au Royaume-Uni, au Japon, à Singapour et aux États-Unis.
Heureusement, les autorités ont détecté les transactions illégales, mais n’ont réussi à récupérer qu’une fraction de l’argent volé. S’il y avait eu un meilleur système d’alerte, les équipes de sécurité auraient détecté l’incident plus tôt, peut-être avant que les attaquants ne parviennent à compromettre le processus opérationnel.
Comme il s’agissait d’un problème de sécurité complexe impliquant d’autres pays, la banque a dû informer les autorités chargées de l’application de la loi et de l’enquête. En outre, la portée de l’incident dépassait celle de l’équipe interne de réponse à l’incident de la banque, d’où la présence d’équipes externes de KPMG, de la banque centrale et d’autres organismes.
Une enquête judiciaire menée par des équipes externes de la banque centrale a établi que l’incident pouvait résulter d’une malversation d’un initié ayant exposé des systèmes critiques.
Selon un rapport, les six opérateurs de l’époque avaient utilisé l’ordinateur dédié au système SWIFT pour d’autres tâches sans rapport. Cela a pu exposer le système SWIFT, permettant ainsi à des attaquants de le compromettre. Après l’incident, la banque a transféré les six employés dans d’autres départements moins sensibles.
Enseignements tirés: La banque aurait dû déployer un système de surveillance et d’alerte efficace, sensibiliser les employés à la sécurité et appliquer des politiques strictes.
Conclusion
Une réponse aux incidents bien planifiée, une bonne équipe et des outils et pratiques de sécurité pertinents donnent à votre organisation la capacité d’agir rapidement et de traiter un large éventail de problèmes de sécurité. Cela permet de réduire les dommages, les interruptions de service, le vol de données, la perte de réputation et les responsabilités potentielles.